Har du svært ved SQL UNION? Det sker, hvis de resultater, du kombinerede, sætter din SQL Server i stå. Eller en rapport, der har virket før, dukker en boks op med et rødt X-ikon. En "Operand type clash" fejl opstår, der peger på en linje med UNION. "Ilden" starter. Lyder det bekendt?
Uanset om du har brugt SQL UNION i et stykke tid eller bare starter det, vil et snydeark eller et kortfattet sæt noter ikke skade. Dette er, hvad du får i dag i dette indlæg. Denne liste giver 10 nyttige tips til både nybegyndere og veteraner. Der vil også være eksempler og nogle avancerede diskussioner.

[sendpulse-form id="11900″]
Men før vi kommer ind på det første punkt, lad os præcisere vilkårene.
UNION er en af sætoperatorerne i SQL, der kombinerer 2 eller flere resultatsæt. Det kan være nyttigt, når du skal kombinere navne, månedlige statistikker og mere fra forskellige kilder. Og uanset om du bruger SQL Server, MySQL eller Oracle, vil formålet, adfærden og syntaksen være meget ens. Men hvordan virker det?
1. Brug SQL UNION til at kombinere Unik Optegnelser
Brug af UNION til at kombinere resultatsæt fjerner dubletter.
Hvorfor er dette vigtigt?
Det meste af tiden ønsker du ikke resultater med dubletter. En rapport med dublerede linjer spilder blæk og papir i papirkopier. Og dette vil gøre dine brugere vrede.
Sådan bruges det
Du kombinerer resultaterne af SELECT-sætningerne med UNION imellem.
Før vi begynder med eksemplet, lad os forberede vores eksempeldata.
BRUG AdventureWorksGOIF OBJECT_ID ('dbo.Customer1', 'U') ER IKKE NULL DROP-TABEL dbo.Customer1; GÅ HVIS OBJECT_ID ('dbo.Customer2', 'U') IKKE ER NULL DROP TABEL dbo.Customer2; GÅ HVIS OBJECT_ID ('dbo.Customer3', 'U') IKKE ER NULL DROP TABEL dbo.Customer3; GO -- Hent 3 kundenavne med Andersen efternavn VÆLG TOP 3 p.LastName, p.FirstName, c.AccountNumberINTO dbo.Customer1 FROM Person.Person AS PINNER JOIN Sales.Customer c ON c.PersonID =p.BusinessEntityIDWHERE =p.LastName 'Andersen'; -- Sørg for, at vi har en dublet i en anden tabel.VÆLG c.Efternavn ,c.Fornavn ,c.KontoNumberINTO dbo.Kunde2FRA Kunde1 c-- Det lader til, at det ikke er nok. Lad os få en 3. kopiSELECT c.LastName ,c.FirstName ,c.AccountNumberINTO dbo.Customer3FROM Customer1 c Vi bruger dataene genereret af ovenstående kode indtil det tredje tip. Nu hvor vi er klar, er eksemplet nedenfor:
SELECT c.LastName,c.FirstName,c.AccountNumberFROM dbo.Customer1 cUNION SELECT c2.LastName,c2.FirstName,c2.AccountNumberFROM dbo.Customer2 c2UNIONSELECT c3.LastName,c3.FirstcountNumber,c3.FROMAccountNumber. .Customer3 c3 Vi har 3 kopier af de samme kunders navne og forventer, at unikke optegnelser forsvinder. Se resultaterne:
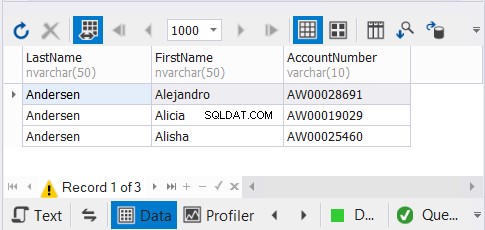
Den dbForge Studio til SQL Server-løsning, vi bruger til vores eksempler, viser kun 3 poster. Det kunne have været 9. Ved at anvende UNION fjernede vi dubletterne.
Hvordan virker det?
Plandiagrammet i dbForge Studio afslører, hvordan SQL Server producerer resultatet vist i figur 1. Tag et kig:
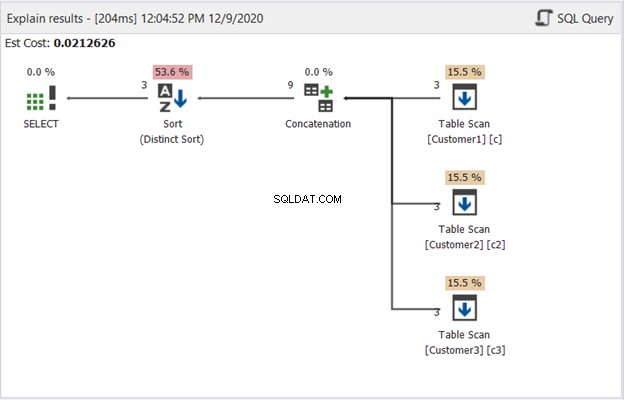
For at fortolke figur 2, start fra højre mod venstre:
- Vi hentede 3 poster fra hver tabelscanningsoperatør. Det er de 3 SELECT-udsagn fra eksemplet ovenfor. Hver linje, der går ud af den, viser '3', hvilket betyder 3 poster hver.
- Konkatenationsoperatoren kombinerer resultater. Linjen, der går ud af den, viser '9' – et output på 9 poster fra kombinationen af resultater.
- Distinct Sort-operatoren sikrer, at unikke poster er det endelige output. Linjen, der går ud af den, viser '3', hvilket stemmer overens med antallet af poster i figur 1.
Ovenstående diagram viser, hvordan UNION behandles af SQL Server. Antallet og typen af anvendte operatorer kan variere afhængigt af forespørgslen og den underliggende datakilde. Men sammenfattende fungerer en UNION som følger:
- Hent resultaterne af hver SELECT-sætning.
- Kombiner resultaterne med en sammenkædningsoperator.
- Hvis de kombinerede resultater ikke er unikke, vil SQL Server filtrere dubletterne fra.
Alle vellykkede eksempler med UNION følger disse grundlæggende trin.
2. Brug SQL UNION ALL til at kombinere poster med dubletter
Ved at bruge UNION ALL kombineres resultatsæt med dubletter inkluderet.
Hvorfor er dette vigtigt?
Du vil måske kombinere resultatsæt og derefter få posterne med dubletter til senere behandling. Denne opgave er nyttig til at rydde op i dine data.
Sådan bruges det
Du kombinerer resultaterne af SELECT-sætningerne med UNION ALL imellem. Tag et kig på eksemplet:
SELECT c.LastName,c.FirstName,c.AccountNumberFROM dbo.Customer1 cUNION ALL SELECT c2.LastName,c2.FirstName,c2.AccountNumberFROM dbo.Customer2 c2UNION ALL SELECT c3.LastName,c3.FirstName,c3.FirstName,c3.FirstName .AccountNumberFROM dbo.Customer3 c3 Ovenstående kode udsender 9 poster som vist i figur 3:
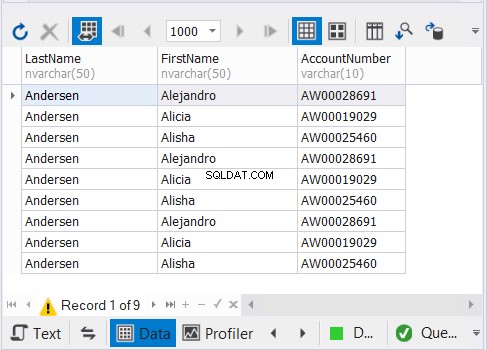
Hvordan virker det?
Som før bruger vi Plan-diagrammet til at vide, hvordan dette fungerer:
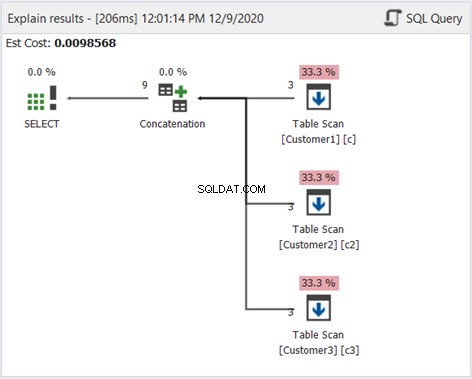
Bortset fra sorteringsforskellen i figur 2 er diagrammet ovenfor det samme. Det er passende, fordi vi ikke ønsker at filtrere dubletterne fra.
Ovenstående diagram viser, hvordan UNION ALL fungerer. Sammenfattende er disse trin, som SQL Server vil følge:
- Hent resultaterne af hver SELECT-sætning.
- Kombiner derefter resultaterne med en sammenkædningsoperator.
Succesfulde eksempler med UNION ALL følger dette mønster.
3. Du kan blande SQL UNION og UNION ALLE undtagen gruppere dem med parenteser
Du kan blande brugen af UNION og UNION ALL i mindst tre SELECT-sætninger.
Hvordan bruges det?
Du kombinerer resultaterne af SELECT-sætningerne med enten UNION eller UNION ALL imellem. En parentes samler resultaterne. Lad os bruge de samme data til det næste eksempel:
VÆLG c.LastName,c.FirstName,c.AccountNumberFROM dbo.Customer1 cUNION ALL ( SELECT c2.LastName ,c2.FirstName ,c2.AccountNumber FROM dbo.Customer2 c2 UNION SELECT c3.LastName ,c3.FirstName ,c3.Kontonummer FRA dbo.Kunde3 c3) Ovenstående eksempel kombinerer resultaterne af de sidste to SELECT-sætninger uden dubletter. Derefter kombinerer den det med resultatet af den første SELECT-sætning. Resultatet er i figur 5 nedenfor:
4. Kolonner i hver SELECT-erklæring skal have kompatible datatyper
Kolonner i hver SELECT-sætning, der bruger UNION, kan have forskellige datatyper. Det er acceptabelt, så længe de er kompatible og tillader implicit konvertering over dem. Den endelige datatype for de kombinerede resultater vil bruge datatypen med den højeste prioritet. Grundlaget for den endelige datastørrelse er også dataene med den største størrelse. I tilfælde af strenge, vil den bruge dataene med det største antal tegn.
Hvorfor er dette vigtigt?
Hvis du har brug for at indsætte resultatet af UNIONs i en tabel, vil den endelige datatype og størrelse afgøre, om den passer til måltabelkolonnen eller ej. Hvis ikke, vil der opstå en fejl. For eksempel har en af kolonnerne i UNION en endelig type NVARCHAR(50). Hvis måltabelkolonnen er VARCHAR(50), kan du ikke indsætte den i tabellen.
Hvordan virker det?
Der er ingen bedre måde at forklare det på end et eksempel:
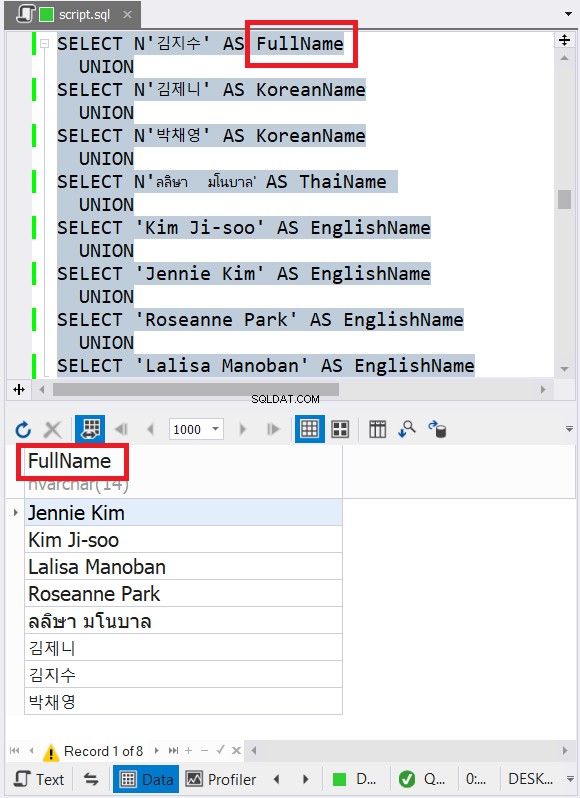
SELECT N'김지수' AS FullName UNIONSELECT N'김제니' AS KoreanName UNIONSELECT N'박채영' AS KoreanName UNIONSELECT N'ลลิษา มโนON's SELECT Thai UNION Name 'SELECT thai Jennie Kim' AS EnglishName UNIONSELECT 'Roseanne Park' AS EnglishName UNIONSELECT 'Lalisa Manoban' AS EnglishName Eksemplet ovenfor indeholder data med engelske, koreanske og thailandske tegnnavne. Thai og koreansk er Unicode-tegn. Engelske tegn er ikke. Så hvad tror du vil den endelige datatype og størrelse være? dbForge Studio viser det i resultatsættet:
Lagde du mærke til den endelige datatype i figur 6? Det kan ikke være VARCHAR på grund af Unicode-tegnene. Så det skal være NVARCHAR. I mellemtiden kan størrelsen ikke være mindre end 14, fordi dataene med det største antal tegn har 14 tegn. Se billedteksterne i rødt i figur 6. Det er godt at inkludere datatypen og størrelsen i kolonneoverskriften i dbForge Studio.
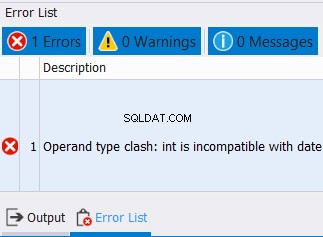
Det er ikke kun tilfældet for strengdatatyper. Det gælder også tal og datoer. I mellemtiden, hvis du prøver at kombinere data med inkompatible datatyper, vil der opstå en fejl. Se eksemplet nedenfor:
SELECT CAST('12/25/2020' AS DATE) AS col1 UNIONSELECT CAST('10' AS INT) AS col1 Vi kan ikke kombinere datoer og heltal i én kolonne. Så forvent en fejl som den nedenfor:
5. Kolonnenavnene for de kombinerede resultater vil bruge kolonnenavnene for den første SELECT-sætning
Dette problem vedrører det forrige tip. Læg mærke til kolonnenavnene i koden i tip #4. Der er forskellige kolonnenavne i hver SELECT-sætning. Vi så dog det sidste kolonnenavn i det kombinerede resultat i figur 6 tidligere. Grundlaget er således kolonnenavnet på den første SELECT-sætning.
Hvorfor er dette vigtigt?
Dette kan være praktisk, når du skal dumpe resultatet af UNION i en midlertidig tabel. Hvis du skal henvise til dens kolonnenavne i de efterfølgende udsagn, skal du være sikker på navnene. Medmindre du bruger en avanceret kodeeditor med IntelliSense, er du klar til endnu en fejl i din T-SQL-kode.
Hvordan virker det?
Se figur 8 for klarere resultater af brugen af dbForge Studio:
6. Tilføj ORDER BY i den sidste SELECT-sætning med SQL UNION for at sortere resultaterne
Du skal sortere de kombinerede resultater. I en række SELECT-sætninger med UNION imellem, kan du gøre det med ORDER BY-sætningen i den sidste SELECT-sætning.
Hvorfor er dette vigtigt?
Brugere ønsker at sortere dataene, som de foretrækker i apps, websider, rapporter, regneark og mere.
Sådan bruges det
Brug ORDER BY i den sidste SELECT-sætning. Her er et eksempel:
VÆLG e.BusinessEntityID,p.FirstName,p.MiddleName,p.LastName,'Employee' AS PersonTypeFROM HumanResources.Employee eINNER JOIN Person.Person p PÅ e.BusinessEntityID =p.BusinessEntity,pIDUNIONID.PID. .FirstName,p.MiddleName,p.LastName,'Customer' AS PersonTypeFROM Sales.Customer CINNER JOIN Person.Person p ON c.PersonID =p.BusinessEntityIDORDER BY p.LastName, p.FirstName Eksemplet ovenfor får det til at se ud som om sorteringen kun sker i den sidste SELECT-sætning. Men det er det ikke. Det vil virke for det kombinerede resultat. Du vil være i problemer, hvis du placerer den i hver SELECT-sætning. Se resultatet:
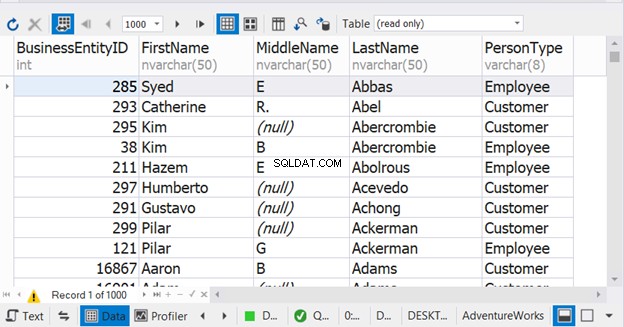
Uden ORDER BY vil resultatsættet have alle Employee PersonType først efterfulgt af alle Customer PersonType . Figur 9 viser dog, at navne bliver sorteringsrækkefølgen af det kombinerede resultat.
Hvis du forsøger at placere ORDER BY i hver SELECT-sætning for at sortere, er der her, hvad der vil ske:
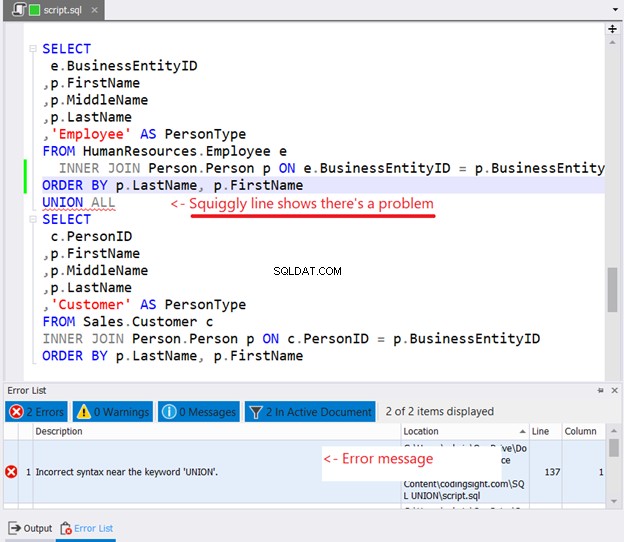
Så du den snoede linje i figur 10? Det er en advarsel. Hvis du ikke lagde mærke til det og fortsatte, vises en fejl i vinduet med fejlliste i dbForge Studio.
7. WHERE og GROUP BY-klausuler kan bruges i hver SELECT-sætning med SQL UNION
ORDER BY-klausulen virker ikke i hver SELECT-sætning med UNION imellem. Men WHERE og GROUP BY-klausulerne virker.
Hvorfor er dette vigtigt?
Du vil måske kombinere resultaterne af forskellige forespørgsler, der filtrerer, tæller eller opsummerer data. Du kan f.eks. gøre dette for at få de samlede salgsordrer for januar 2012 og sammenligne dem med januar 2013, januar 2014 og så videre.
Sådan bruges det
Placer WHERE- og/eller GROUP BY-sætningerne i hver SELECT-sætning. Se eksemplet nedenfor:
BRUG AdventureWorksGO-- Få antallet af ordrer for januar 2012, 2013, 2014 til sammenligning. VÆLG ÅR(soh.OrderDate) AS OrderYear,COUNT(*) AS NumberOfJanuaryOrdersFROM Sales.SalesOrderHeader sohWHERE BETWEEN '0OrderDate'0 01/2012' OG '01/31/2012'GRUPPER EFTER ÅR(soh.OrderDate)UNIONSELECT YEAR(soh.OrderDate) AS OrderYear,COUNT(*) AS NumberOfJanuaryOrdersFROM Sales.SalesOrderHeader sohWHERE soh.OrderDate BETWEEN/'01/1301 ' OG '01/31/2013'GRUPPER EFTER ÅR(soh.OrderDate)UNIONSELECT YEAR(soh.OrderDate) AS OrderYear,COUNT(*) AS NumberOfJanuaryOrdersFROM Sales.SalesOrderHeader sohWHERE soh.OrderDate MELLEM '01/4'01/2 31/01/2014'GRUPPER EFTER ÅR(soh.OrderDate) Koden ovenfor kombinerer antallet af januarordrer i tre på hinanden følgende år. Tjek nu outputtet:
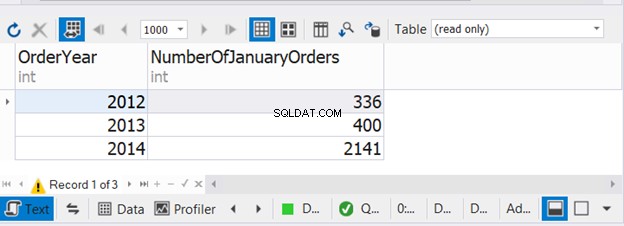
Dette eksempel viser, at det er muligt at bruge WHERE og GROUP BY i hver af de tre SELECT-sætninger med UNION.
8. SELECT INTO Fungerer med SQL UNION
Når du skal indsætte resultaterne af en forespørgsel med SQL UNION i en tabel, kan du gøre det ved at bruge SELECT INTO.
Hvorfor er dette vigtigt?
Der vil være tidspunkter, hvor du har brug for at lægge resultaterne af en forespørgsel med UNION i en tabel til yderligere behandling.
Sådan bruges det
Placer INTO-sætningen i den første SELECT-sætning. Her er et eksempel:
VÆLG ÅR(soh.OrderDate) AS OrderYear,COUNT(*) AS NumberOfJanuaryOrdersINTO JanuaryOrdersFROM Sales.SalesOrderHeader sohWHERE soh.OrderDate MELLEM '01/01/2012' OG '01/31/2012'GROUP( soh.OrderDate)UNIONSELECT YEAR(soh.OrderDate) AS OrderYear,COUNT(*) AS NumberOfJanuaryOrdersFROM Sales.SalesOrderHeader sohWHERE soh.OrderDate MELLEM '01/01/2013' OG '01/31/2013'Dato 01/01/2013'Dato. )UNIONSELECT YEAR(soh.OrderDate) AS OrderYear,COUNT(*) AS NumberOfJanuaryOrdersFROM Sales.SalesOrderHeader sohWHERE soh.OrderDate MELLEM '01/01/2014' OG '01/31/2014'GROUP BY YEAR(s)oh. Husk kun at placere én INTO-sætning i den første SELECT-sætning.
Hvordan virker det
SQL Server følger mønsteret for behandling af UNION. Derefter indsætter den resultatet i tabellen specificeret i INTO-sætningen.
9. Differentier SQL UNION fra SQL JOIN
Både SQL UNION og SQL JOIN kombinerer tabeldataene, men forskellen i syntaks og resultater er som nat og dag.
Hvorfor er dette vigtigt?
Hvis din rapport eller ethvert krav har brug for en JOIN, men du gjorde en UNION, vil outputtet være forkert.
Sådan bruges SQL UNION og SQL JOIN
Det er SQL UNION vs. JOIN. Dette er en af de relaterede søgeforespørgsler og spørgsmål, som en nybegynder stiller i Google, når han lærer om SQL UNION. Her er tabellen over forskelle:
| SQL UNION | SQL JOIN | |
| Hvad er kombineret | Rækker | Kolonner (ved hjælp af en nøgle) |
| Antal kolonner pr. tabel | Det samme for alle tabeller | Variabel (Nul til alle kolonner/tabel) |
I alle projekter, jeg har været med, gælder SQL JOIN det meste af tiden. Jeg havde kun et par tilfælde, der brugte SQL UNION. Men som du har set indtil videre, er SQL UNION langt fra ubrugelig.
10. SQL UNION ALL er hurtigere end UNION
Plandiagrammerne i figur 2 og figur 4 tidligere tyder på, at UNION kræver en ekstra operatør for at sikre unikke resultater. Derfor er UNION ALL hurtigere.
Hvorfor er dette vigtigt?
Du, dine brugere, dine kunder, din chef, ønsker alle hurtige resultater. At vide, at UNION ALL er hurtigere end UNION, får dig til at spekulere på, hvad du skal gøre, hvis du har brug for unikke kombinerede resultater. Der er én løsning, som du vil se senere.
SQL UNION ALL vs. UNION Performance
Figur 2 og figur 4 gav dig allerede en idé om, hvad der er hurtigere. Men de anvendte kodeeksempler er enkle med et lille resultatsæt. Lad os tilføje nogle flere sammenligninger ved hjælp af millioner af poster for at gøre det overbevisende.
Til at begynde med, lad os forberede dataene:
SELECT TOP (2000000) val =ROW_NUMBER() OVER (ORDER BY sod.SalesOrderDetailID)INTO dbo.TestNumbersFROM AdventureWorks.Sales.SalesOrderDetail sodCROSS JOIN AdventureWorks.Sales.SalesOrderDetail sod2code> Det er 2 millioner poster. Jeg håber, det er overbevisende nok. Lad os nu have de næste to forespørgselseksempler nedenfor.
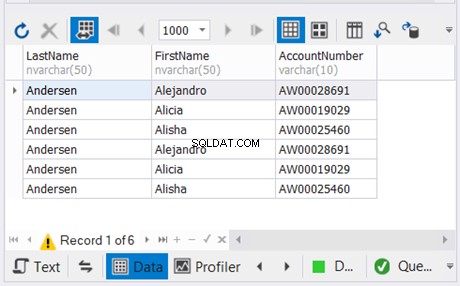
-- Brug af UNION ALLSELECT valFROM TestNumbers tnUNION ALLSELECT valFROM TestNumbers tn-- Brug af UNIONSELECT valFROM TestNumbers tnUNIONSELECT valFROM TestNumbers tn Lad os undersøge de processer, der er involveret i disse forespørgsler, begyndende med den hurtigere.
Plandiagramanalyse
Diagrammet i figur 12 ser typisk ud for en UNION ALL-proces. Men resultatet er 4 millioner samlede resultater. Se pilen, der går ud af sammenkædningsoperatoren. Alligevel er det typisk fordi den ikke håndterer dubletterne.
Lad os nu have diagrammet over UNION-forespørgslen i figur 13:
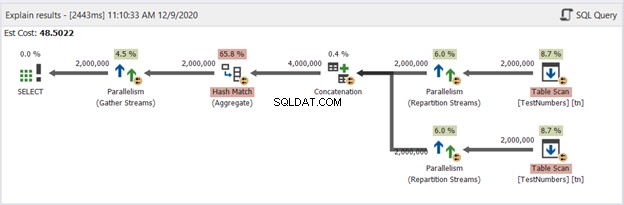
Denne er ikke længere typisk. Planen bliver en parallel forespørgselsplan til at håndtere fjernelse af dubletter i fire millioner rækker. Den parallelle forespørgselsplan betyder, at SQL Server skal dividere processen med antallet af tilgængelige processorkerner.
Lad os fortolke det, startende fra de højre operatorer, der går til venstre:
- Da vi kombinerer en tabel til sig selv, skal SQL Server hente den to gange. Se de to tabelscanninger med hver to millioner poster.
- Ompartitionsstrømoperatører vil kontrollere fordelingen af hver række til den næste tilgængelige tråd.
- Forbindelse fordobler resultatet til fire millioner. Dette tager stadig antallet af processorkerner i betragtning.
- Et Hash Match gælder for at fjerne dubletterne. Dette er en dyr proces med en operatøromkostning på 65,8 %. Som et resultat blev to millioner poster kasseret.
- Gather Streams rekombinerer resultaterne udført i hver processorkerne eller tråd til én.
Det er for meget arbejde, selvom processen er opdelt i flere tråde. Derfor vil du konkludere, at det vil køre langsommere. Men hvad nu hvis der er en løsning til at få unikke poster med UNION ALL men hurtigere end dette?
Unikke resultater, men hurtigere løsning med UNION ALL – hvordan?
Jeg vil ikke få dig til at vente. Her er koden:
VÆLG DISTINCTvalFROM ( SELECT val FROM TestNumbers tn UNION ALL SELECT val FROM TestNumbers tn ) AS uniqtn Dette kan være en dårlig løsning. Men tjek dets plandiagram i figur 14:
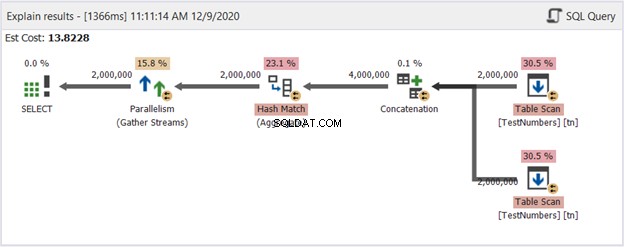
Så hvad gjorde det bedre? Hvis du sammenligner det med figur 13, ser du, at opdelingsstrømoperatørerne er væk. Det bruger dog stadig flere tråde til at få arbejdet gjort. På den anden side indebærer det, at forespørgselsoptimeringsværktøjet anser denne proces for at være enklere at udføre end forespørgslen, der bruger UNION.
Kan vi med sikkerhed konkludere, at vi bør undgå at bruge UNION og bruge denne tilgang i stedet? Slet ikke! Tjek altid udførelsesplandiagrammet! Det afhænger altid af, hvad du vil have SQL Server til at give dig. Denne viser kun, at hvis du støder ind i en ydeevnevæg, skal du ændre din forespørgselstilgang.
Hvad med I/O-statistik?
Vi kan ikke afvise, hvor mange ressourcer SQL Server har brug for til at behandle vores forespørgselseksempler. Derfor skal vi også undersøge deres STATISTICS IO. Ved at sammenligne de tre forespørgsler ovenfor får vi de logiske læsninger nedenfor:
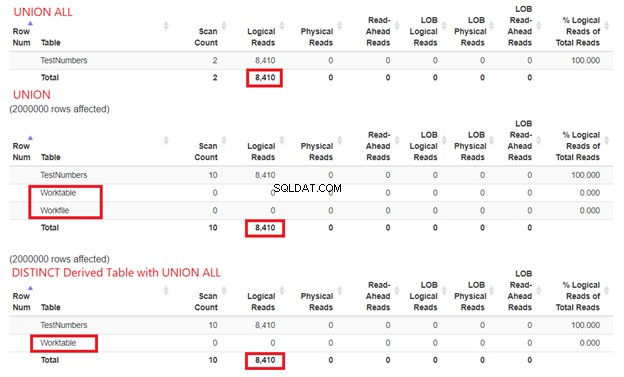
Fra figur 15 kan vi stadig konkludere, at UNION ALL er hurtigere end UNION, selvom de logiske læsninger er de samme. Tilstedeværelsen af Worktable og Arbejdsfil viser ved hjælp af tempdb at få arbejdet gjort. I mellemtiden, når vi bruger SELECT DISTINCT fra en afledt tabel med UNION ALL, er tempdb forbruget er mindre sammenlignet med UNION. Dette bekræfter yderligere, at vores analyse fra Plandiagrammerne tidligere er korrekt.
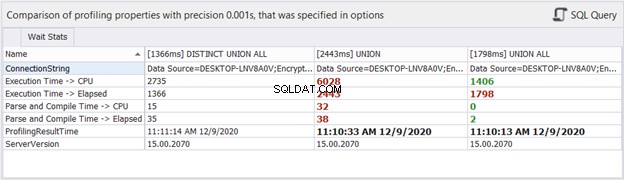
Hvad med tidsstatistik?
Selvom den forløbne tid kan ændre sig i hver udførelse, vi udfører for de samme forespørgsler, kan det give os en idé og tilføje mere bevis til vores analyse. dbForge Studio viser tidsforskellene for de tre forespørgsler ovenfor. Denne sammenligning stemmer overens med den tidligere analyse, vi lavede.
Konklusion
Vi dækkede en masse baggrund for at give det, du skal bruge for at bruge SQL UNION og UNION ALL. Du husker måske ikke alt efter at have læst dette indlæg, så sørg for at bogmærke denne side.
Hvis du kan lide opslaget, er du velkommen til at dele det på sociale medier.