Grupperet sammenkædning er et almindeligt problem i SQL Server, uden direkte og tilsigtede funktioner til at understøtte det (såsom XMLAGG i Oracle, STRING_AGG eller ARRAY_TO_STRING(ARRAY_AGG()) i PostgreSQL og GROUP_CONCAT i MySQL). Det er blevet anmodet om, men endnu ingen succes, som det fremgår af disse Connect-elementer:
- Forbind #247118:SQL kræver version af MySQL group_Concat-funktionen (udskudt)
- Forbind #728969:Ordnede sætfunktioner – INDEN FOR GRUPPE-klausul (lukket, da det ikke løses)
** OPDATERING januar 2017 ** :STRING_AGG() vil være i SQL Server 2017; læs om det her, her og her.
Hvad er grupperet sammenkædning?
For den uinitierede, er grupperet sammenkædning, når du vil tage flere rækker af data og komprimere dem til en enkelt streng (normalt med skilletegn som kommaer, tabulatorer eller mellemrum). Nogle vil måske kalde dette en "vandret sammenføjning". Et hurtigt visuelt eksempel, der viser, hvordan vi ville komprimere en liste over kæledyr, der tilhører hvert familiemedlem, fra den normaliserede kilde til det "fladede" output:
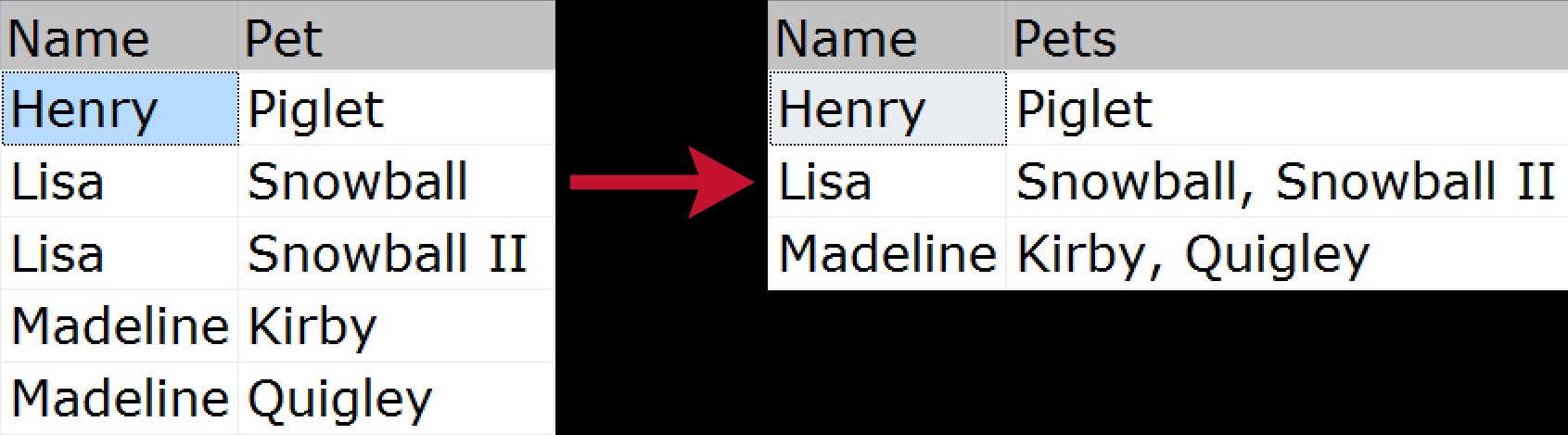
Der har været mange måder at løse dette problem på gennem årene; her er blot nogle få, baseret på følgende eksempeldata:
CREATE TABLE dbo.FamilyMemberPets ( Name SYSNAME, Pet SYSNAME, PRIMARY KEY(Name,Pet) ); INSERT dbo.FamilyMemberPets(Name,Pet) VALUES (N'Madeline',N'Kirby'), (N'Madeline',N'Quigley'), (N'Henry', N'Piglet'), (N'Lisa', N'Snowball'), (N'Lisa', N'Snowball II');
Jeg vil ikke demonstrere en udtømmende liste over alle grupperede sammenkædningstilgange, der nogensinde er udtænkt, da jeg ønsker at fokusere på nogle få aspekter af min anbefalede tilgang, men jeg vil gerne påpege et par af de mere almindelige:
Skalær UDF
CREATE FUNCTION dbo.ConcatFunction
(
@Name SYSNAME
)
RETURNS NVARCHAR(MAX)
WITH SCHEMABINDING
AS
BEGIN
DECLARE @s NVARCHAR(MAX);
SELECT @s = COALESCE(@s + N', ', N'') + Pet
FROM dbo.FamilyMemberPets
WHERE Name = @Name
ORDER BY Pet;
RETURN (@s);
END
GO
SELECT Name, Pets = dbo.ConcatFunction(Name)
FROM dbo.FamilyMemberPets
GROUP BY Name
ORDER BY Name; Bemærk:der er en grund til, at vi ikke gør dette:
SELECT DISTINCT Name, Pets = dbo.ConcatFunction(Name) FROM dbo.FamilyMemberPets ORDER BY Name;
Med DISTINCT , funktionen køres for hver enkelt række, derefter fjernes dubletter; med GROUP BY , fjernes dubletterne først.
Common Language Runtime (CLR)
Dette bruger GROUP_CONCAT_S funktion fundet på https://groupconcat.codeplex.com/:
SELECT Name, Pets = dbo.GROUP_CONCAT_S(Pet, 1) FROM dbo.FamilyMemberPets GROUP BY Name ORDER BY Name;
Rekursiv CTE
Der er flere variationer af denne rekursion; denne trækker et sæt adskilte navne frem som anker:
;WITH x as
(
SELECT Name, Pet = CONVERT(NVARCHAR(MAX), Pet),
r1 = ROW_NUMBER() OVER (PARTITION BY Name ORDER BY Pet)
FROM dbo.FamilyMemberPets
),
a AS
(
SELECT Name, Pet, r1 FROM x WHERE r1 = 1
),
r AS
(
SELECT Name, Pet, r1 FROM a WHERE r1 = 1
UNION ALL
SELECT x.Name, r.Pet + N', ' + x.Pet, x.r1
FROM x INNER JOIN r
ON r.Name = x.Name
AND x.r1 = r.r1 + 1
)
SELECT Name, Pets = MAX(Pet)
FROM r
GROUP BY Name
ORDER BY Name
OPTION (MAXRECURSION 0); Markør
Ikke meget at sige her; markører er normalt ikke den optimale tilgang, men dette kan være dit eneste valg, hvis du sidder fast på SQL Server 2000:
DECLARE @t TABLE(Name SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name));
INSERT @t(Name, Pets)
SELECT Name, N''
FROM dbo.FamilyMemberPets GROUP BY Name;
DECLARE @name SYSNAME, @pet SYSNAME, @pets NVARCHAR(MAX);
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR SELECT Name, Pet
FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
OPEN c;
FETCH c INTO @name, @pet;
WHILE @@FETCH_STATUS = 0
BEGIN
UPDATE @t SET Pets += N', ' + @pet
WHERE Name = @name;
FETCH c INTO @name, @pet;
END
CLOSE c; DEALLOCATE c;
SELECT Name, Pets = STUFF(Pets, 1, 1, N'')
FROM @t
ORDER BY Name;
GO Quirky Update
Nogle mennesker *elsker* denne tilgang; Jeg forstår slet ikke tiltrækningen.
DECLARE @Name SYSNAME, @Pets NVARCHAR(MAX);
DECLARE @t TABLE(Name SYSNAME, Pet SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name, Pet));
INSERT @t(Name, Pet)
SELECT Name, Pet FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
UPDATE @t SET @Pets = Pets = COALESCE(
CASE COALESCE(@Name, N'')
WHEN Name THEN @Pets + N', ' + Pet
ELSE Pet END, N''),
@Name = Name;
SELECT Name, Pets = MAX(Pets)
FROM @t
GROUP BY Name
ORDER BY Name; TIL XML-STI
Ganske nemt min foretrukne metode, i det mindste delvist fordi det er den eneste måde at *garanti* bestille uden at bruge en markør eller CLR. Når det er sagt, er dette en meget rå version, der ikke løser et par andre iboende problemer, som jeg vil diskutere videre på:
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N'')), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
Jeg har set mange mennesker fejlagtigt antage, at den nye CONCAT() funktion introduceret i SQL Server 2012 var svaret på disse funktionsanmodninger. Denne funktion er kun beregnet til at fungere mod kolonner eller variabler i en enkelt række; det kan ikke bruges til at sammenkæde værdier på tværs af rækker.
Mere om FOR XML PATH
FOR XML PATH('') i sig selv er ikke godt nok - den har kendte problemer med XML-entitisering. For eksempel, hvis du opdaterer et af kæledyrsnavnene til at inkludere en HTML-parentes eller et og-tegn:
UPDATE dbo.FamilyMemberPets SET Pet = N'Qui>gle&y' WHERE Pet = N'Quigley';
Disse bliver oversat til XML-sikre enheder et eller andet sted hen ad vejen:
Qui>gle&y
Så jeg bruger altid PATH, TYPE).value() , som følger:
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
Jeg bruger også altid NVARCHAR , fordi du aldrig ved, hvornår en underliggende kolonne vil indeholde Unicode (eller senere ændres til at gøre det).
Du kan muligvis se følgende varianter inde i .value() , eller endda andre:
... TYPE).value(N'.', ... ... TYPE).value(N'(./text())[1]', ...
Disse er udskiftelige, alle repræsenterer i sidste ende den samme streng; præstationsforskellene mellem dem (mere nedenfor) var ubetydelige og muligvis fuldstændig ikke-deterministiske.
Et andet problem, du kan støde på, er visse ASCII-tegn, som ikke er mulige at repræsentere i XML; for eksempel hvis strengen indeholder tegnet 0x001A (CHAR(26) ), får du denne fejlmeddelelse:
FOR XML kunne ikke serialisere dataene for noden 'NoName', fordi den indeholder et tegn (0x001A), som ikke er tilladt i XML. For at hente disse data ved hjælp af FOR XML skal du konvertere dem til binære, varbinære eller billeddatatyper og bruge BINARY BASE64-direktivet.
Dette virker ret kompliceret for mig, men forhåbentlig behøver du ikke bekymre dig om det, fordi du ikke gemmer data som denne, eller i det mindste forsøger du ikke at bruge det i grupperet sammenkædning. Hvis du er det, skal du muligvis falde tilbage til en af de andre tilgange.
Ydeevne
Ovenstående eksempeldata gør det nemt at bevise, at disse metoder alle gør, hvad vi forventer, men det er svært at sammenligne dem meningsfuldt. Så jeg fyldte tabellen med et meget større sæt:
TRUNCATE TABLE dbo.FamilyMemberPets; INSERT dbo.FamilyMemberPets(Name,Pet) SELECT o.name, c.name FROM sys.all_objects AS o INNER JOIN sys.all_columns AS c ON o.[object_id] = c.[object_id] ORDER BY o.name, c.name;
For mig var det 575 objekter med 7.080 rækker i alt; det bredeste objekt havde 142 søjler. Nu igen, indrømmet, satte jeg mig ikke for at sammenligne hver enkelt tilgang, der er udtænkt i SQL Servers historie; blot de få højdepunkter, jeg postede ovenfor. Her var resultaterne:
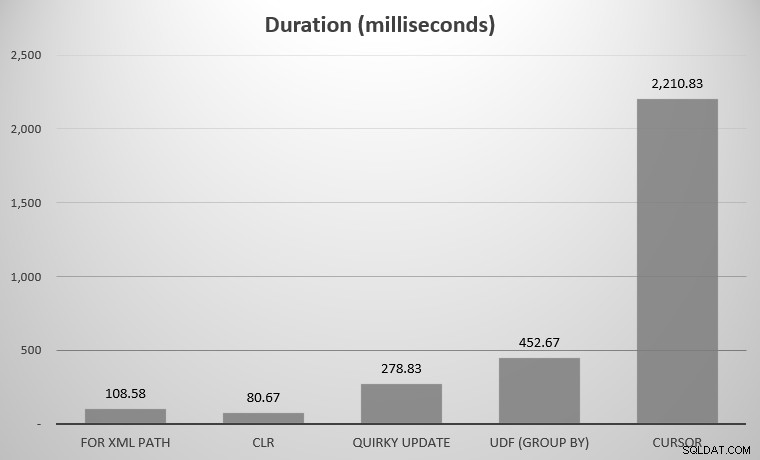
Du bemærker måske, at et par kandidater mangler; UDF ved hjælp af DISTINCT og den rekursive CTE var så off the charts, at de ville skæve skalaen. Her er resultaterne af alle syv tilgange i tabelform:
| Tilgang | Varighed (millisekunder) |
|---|---|
| TIL XML-STI | 108.58 |
| CLR | 80,67 |
| Quirky Update | 278,83 |
| UDF (GROUP BY) | 452,67 |
| UDF (DISTINCT) | 5.893,67 |
| Markør | 2.210,83 |
| Rekursiv CTE | 70.240,58 |
Gennemsnitlig varighed i millisekunder for alle tilgange
Bemærk også, at variationerne på FOR XML PATH blev testet uafhængigt, men viste meget små forskelle, så jeg kombinerede dem bare for gennemsnittet. Hvis du virkelig vil vide det, kan du bruge .[1] notation fungerede hurtigst i mine tests; YMMV.
Konklusion
Hvis du ikke er i en butik, hvor CLR er en vejspærring på nogen måde, og især hvis du ikke kun har med simple navne eller andre strenge at gøre, bør du bestemt overveje CodePlex-projektet. Forsøg ikke at genopfinde hjulet, prøv ikke uintuitive tricks og hacks for at få CROSS APPLY til at eller andre konstruktioner virker bare lidt hurtigere end ikke-CLR-metoderne ovenfor. Bare tag det, der virker, og sæt det i. Og for pokker, da du også får kildekoden, kan du forbedre den eller udvide den, hvis du vil.
Hvis CLR er et problem, så FOR XML PATH er sandsynligvis din bedste mulighed, men du skal stadig passe på vanskelige karakterer. Hvis du sidder fast på SQL Server 2000, er din eneste mulige mulighed UDF (eller lignende kode, der ikke er pakket ind i en UDF).
Næste gang
Et par ting, jeg vil udforske i et opfølgende indlæg:fjernelse af dubletter fra listen, bestilling af listen efter noget andet end selve værdien, tilfælde, hvor det kan være smertefuldt at sætte nogen af disse tilgange ind i en UDF, og praktiske use cases for denne funktionalitet.