Når du udvikler en applikation eller skriver en kode i SQL-databasesystemet, er det afgørende at forstå, hvordan data vil blive sorteret og sammenlignet. Du kan gemme dine data på et bestemt sprog, eller du vil måske have, at SQL Server behandler store og små bogstaver og data separat. Microsoft har leveret en SQL Server-indstilling kaldet Samling at kontrollere og imødekomme sådanne krav.
Hvad er Collation i SQL Server?
Vi kan indstille sorteringen på forskellige niveauer i SQL Server som angivet nedenfor.
- Serverniveau
- Databaseniveau
- Kolonneniveau
- Udtryksniveau
Serverniveausorteringen kan nogle gange kaldes SQL Server Instance Level Collation .
Databaseniveausorteringen vil blive nedarvet fra serverniveausorteringsindstillingen, hvis du ikke vælger nogen specifik sortering under oprettelsen af databasen. Du kan også ændre sorteringen på databaseniveau senere. Bemærk, at ændring af databasesortering kun vil blive anvendt for kommende eller nye objekter, som vil blive oprettet efter sorteringsændringen.
Ny sortering vil ikke ændre eksisterende data gemt i tabeller, der blev sorteret med den sidste sorteringstype. Applikationsteamet har brug for yderligere planlægning for at håndtere denne lagrede datakonvertering på grund af den nye sorteringsindstilling.
Der er flere måder at gøre det på. Den ene er at kopiere dataene fra den eksisterende tabel til en ny tabel oprettet med den nye sortering og derefter erstatte den gamle tabel med den nye. Du kan også flytte dine tabeldata til en ny database ved at have en ny sortering og erstatte den gamle database med den nye.
BEMÆRK :Ændring af sortering er en kompleks opgave, og du bør undgå det, medmindre du har en obligatorisk business case.
Hvordan finder og ændres databasesortering i SQL Server?
Lad os gå videre og tjekke sammenstillingen af SQL Server Instance og alle databaser, der er hostet på den instans. Du kan kontrollere sortering ved at få adgang til database- eller instansniveauets egenskaber vindue ved hjælp af SQL Server Management Studio eller ved blot at udføre nedenstående T-SQL-sætning. Sorteringen for hver database er gemt i systemobjektet sys.databases – vi får adgang til det for at få disse oplysninger.
--Check Database Collation
SELECT name, collation_name
FROM sys.databases
GO
--Check Server or Instance level Collation
SELECT SERVERPROPERTY('Collation') As [Instance Level Collation]
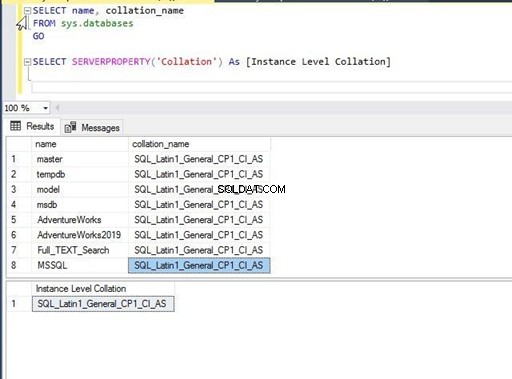
Jeg har udført ovenstående T-SQL-sætning og fik nedenstående output. Vi kan se, at alle databaser og sortering på serverniveau har de samme indstillinger som SQL_Latin1_General_CP1_CI_AS . Det betyder, at databasesorteringer er blevet nedarvet af sorteringen på serverniveau, mens de blev oprettet, og standardværdien er ikke blevet ændret.
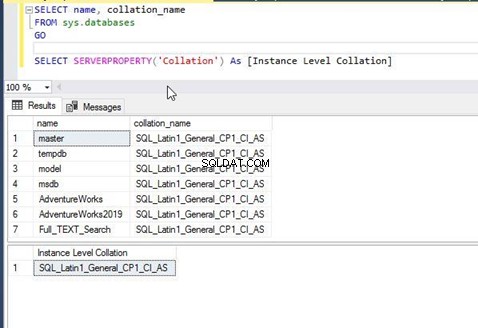
Lad mig nu vise dig, hvordan du kontrollerer databasesorteringen ved hjælp af GUI i SQL Server Management Studio.
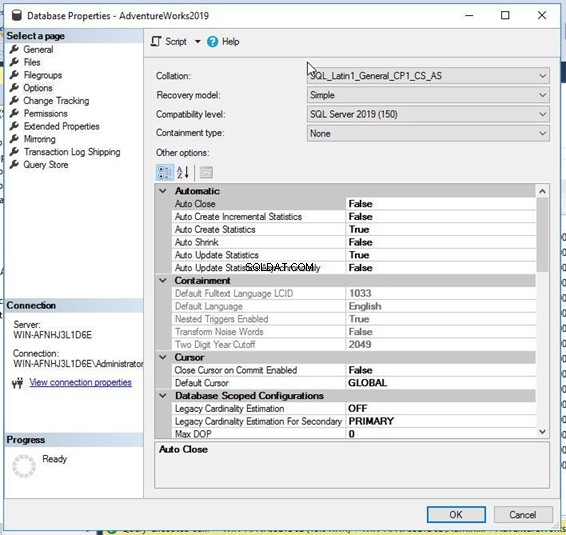
Først skal du oprette forbindelse til din SQL Server-instans ved hjælp af SQL Server Management Studio. Udvid instansnoden efterfulgt af databaserne folder. Højreklik på måldatabasen, og vælg Egenskaber :
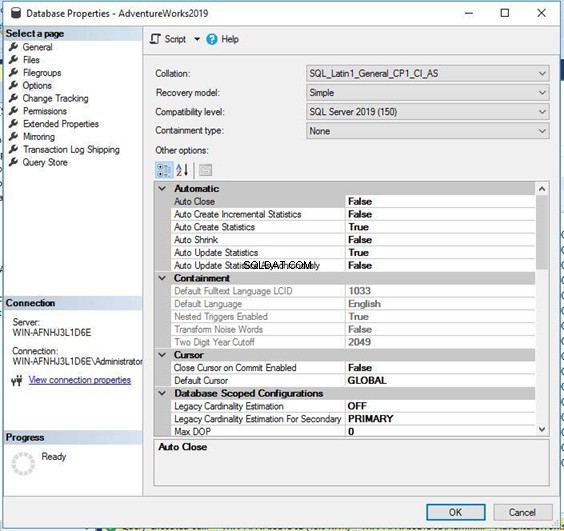
Du får nedenstående Databaseegenskaber vindue.
Klik nu på Indstillinger fanen fra panelet til venstre. Du får flere egenskabsindstillinger i panelet til højre. Samling er den første egenskab på denne side – du kan se, at den er den samme, som den var i ovenstående T-SQL-script.
På samme måde kan du klikke på SQL Server-instansnoden og højreklikke på egenskaberne på instansniveauet. for at se sorteringen på serverniveau.
Hvis du vil ændre denne sortering til en ny sortering, skal du blot klikke på Samling dropdown og vælg den mulighed, du har brug for. Sørg for, at du har lavet en fuld backup af din database, før du gør det.
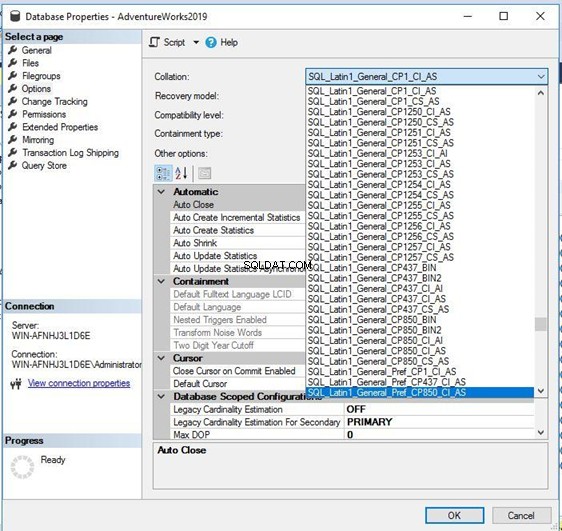
Jeg har valgt en lignende sortering med store og små bogstaver SQL_Latin1_General_CP1_CS _AS for denne database og klikkede på OK at anvende det. Bemærk:Sørg for, at ingen er forbundet til måldatabasen under denne procedure, ellers bliver du nødt til at skifte tilstanden til enkeltbruger én og ændre denne konfiguration.
Du kan også ændre denne databasesortering ved hjælp af T-SQL-sætningen. Til det skal du bruge SAMLER klausul i ALTER DATABASE-sætningen.
Først har vi skiftet databasen til enkeltbruger tilstand, ændrede derefter sorteringen og flyttede til sidst databasen til multi-user tilstand.
--Change Database Collation using T-SQL
USE master;
GO
Alter DATABASE [AdventureWorks2019] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
GO
ALTER DATABASE [AdventureWorks2019]
COLLATE SQL_Latin1_General_CP1_CI_AS;
GO
Alter DATABASE [AdventureWorks2019] SET MULTI_USER
Læs alle understøttede sorteringer i SQL Server
Dette afsnit viser dig, hvordan du finder alle tilgængelige sorteringer i SQL Server. Lad mig først vise dig, hvordan du får listen over alle understøttede sorteringer for SQL Server-forekomsten.
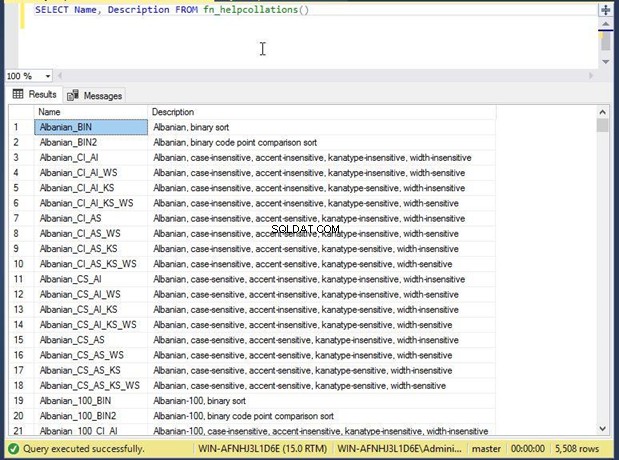
SQL Server har en systemfunktion kaldet fn_helpcollations() som du kan bruge til at hente alle sorteringer.
Kør nedenstående kommando for at få vist listen.
--Display the list of all collations
SELECT name, description FROM fn_helpcollations()
Vi kan se alle 5508 understøttede sorteringer i outputsektionen. Hvis du ikke er sikker på, hvilken sortering du skal vælge, kan du bruge WHERE-sætningen i nedenstående script til at bortfiltrere alle mulige sorteringer, der kan indstilles til databasen.
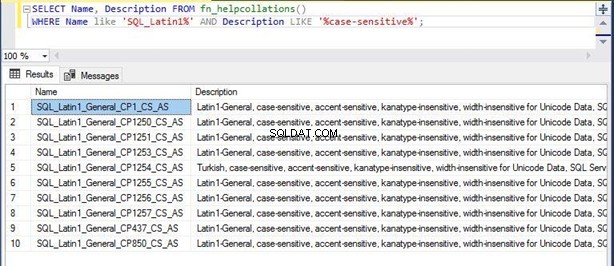
Lad os sige, at du skal gemme dine data på amerikansk engelsk og ønsker, at SQL Server skal håndtere dem i et format, der skelner mellem store og små bogstaver. Du kan bruge nedenstående kommando til at hente listen over mulige og understøttede sorteringer til din forespørgsel:
--Display the list of all collations with WHERE clause
SELECT Name, Description FROM fn_helpcollations()
WHERE Name like 'SQL_Latin1%' AND Description LIKE '%case-sensitive%’
Outputtet viser kun 10 sorteringer, der opfylder din forespørgsel. Du kan bruge ovenstående script til at filtrere forskellige sorteringer fra.
Konsekvens af ændring af databasesortering på forespørgselsoutput
I dette afsnit vil jeg vise dig forskellen mellem de to output af den samme forespørgsel, når de udføres med forskellige sorteringer.
Først vil jeg oprette en database med navnet MSSQL med en sortering (SQL_Latin1_General_CP1_CS _AS ). Så vil jeg køre den samme forespørgsel to gange for at få outputtet. Senere vil jeg ændre sorteringen til SQL_Latin1_General_CP1_CI _AS og kør igen de samme forespørgsler for at få deres output. Du kan sammenligne begge output og forstå virkningen af at ændre en databasesortering. Så lad os starte med databaseoprettelse.
Start vinduet til oprettelse af nye databaser som vist på billedet nedenfor. Du kan også oprette denne database ved hjælp af T-SQL. Derefter kan du se databasenavnet og dets datafiler. Klik nu på den anden fane i panelet til venstre for at skifte til vinduet med sorteringsegenskaber.
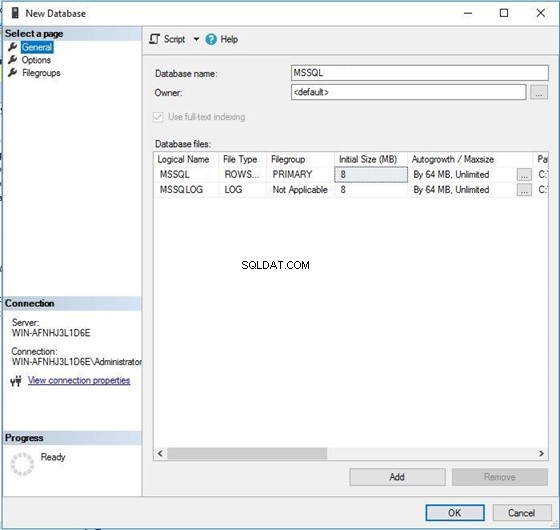
Du kan se, at sorteringsnavnet for denne database er standard . Det betyder, at denne database vil arve sortering fra sorteringstypen på serverniveau. Klik på Samling dropdown for at vælge din nye sortering.
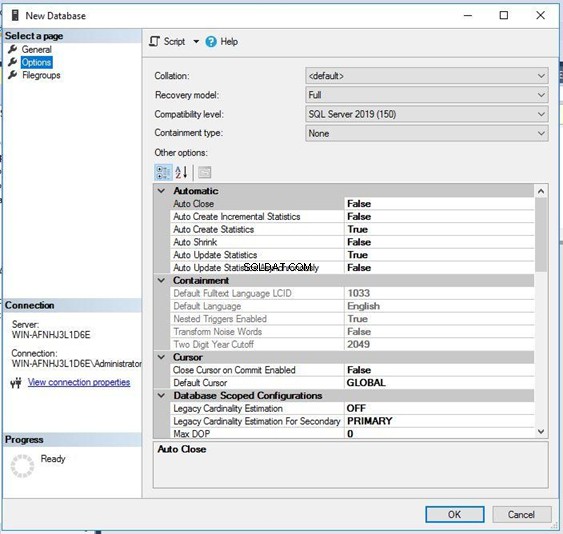
Jeg har valgt nedenstående sortering SQL_Latin1_General_CP1_CS _AS for denne database – ikke standarden. Klik på OK for at fortsætte med oprettelsen af databasen.
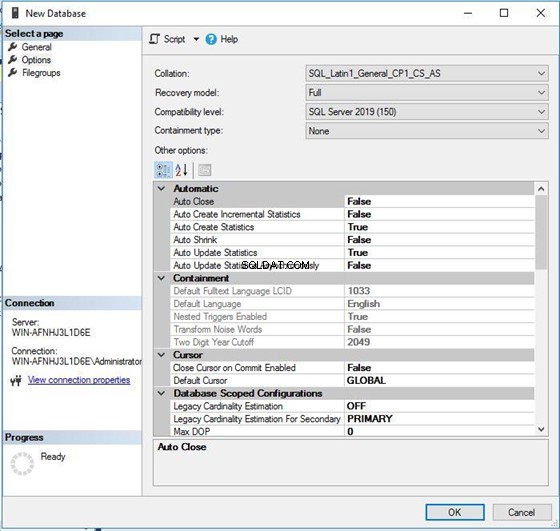
Tjek nu databasesorteringen for en nyoprettet database. Vi kan se, at det er SQL_Latin1_General_CP1_CS _AS som vi har valgt i det foregående trin.
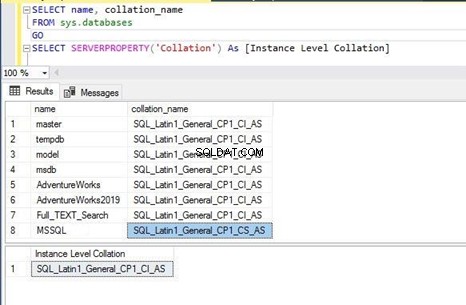
I SQL_Latin1_General_CP1_CS _AS , CS står for store og store bogstaver tilstand og CI står for uafhængig af store og små bogstaver mode. Nu kan du køre enten nedenstående T-SQL-kode eller en hvilken som helst kode for at få outputtet.
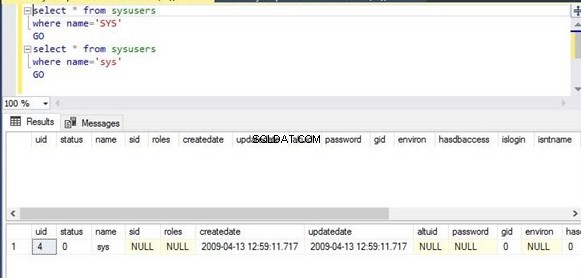
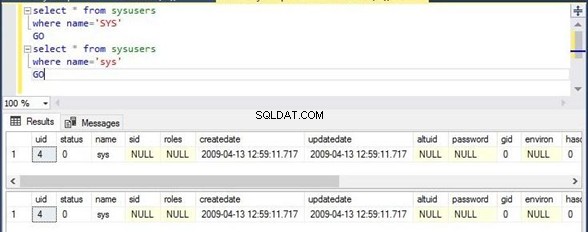
Jeg har udført den samme kommando to gange. Det første script filtrerer kolonnenavnene med en værdi SYS i kapital bogstaver, hvorimod det andet script vil filtrere den samme kolonne med den samme værdi sys i lille bogstaver. Outputsektionen viser, at det første script ikke har vist noget output, hvorimod det andet script har vist outputtet på grund af dets store og små bogstaver.
Select * from sysusers
Where name=’SYS’
Go
Select * from sysusers
Where name=’sys’
GO
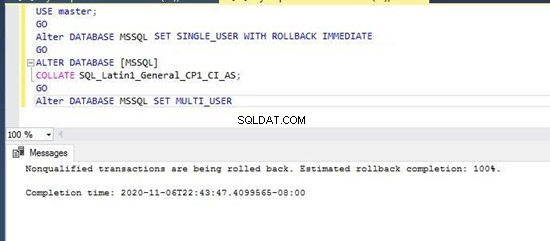
Nu vil vi ændre sorteringen af denne database til den uafhængige af store og små bogstaver sortering SQL_Latin1_General_CP1_CI _AS ved at udføre nedenstående T-SQL-sætninger. Du kan også ændre det via GUI ved at åbne vinduet Database Properties i SQL Server Management Studio.
--Change database collation to SQL_Latin1_General_CP1_CI_AS
USE master;
GO
Alter DATABASE [MSSQL] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
GO
ALTER DATABASE [MSSQL]
COLLATE SQL_Latin1_General_CP1_CI_AS;
GO
Alter DATABASE [MSSQL] SET MULTI_USER
Jeg har udført ovenstående script på én gang, og databasesorteringen blev med succes ændret til en ny sortering med understøttelse af store og små bogstaver.
Du kan bekræfte denne ændring ved at køre nedenstående scripts for at kontrollere sammenstillingen af den nyoprettede database MSSQL. Vi kan se, at den nye sortering er indstillet for denne database i billedet nedenfor.
Vi vil igen køre den samme T-SQL-sætning, før vi ændrer sammenstillingen for at se virkningen af denne ændring. Som vi kan se nu, er begge T-SQL-sætninger i outputtet.
Konklusion
Jeg håber, det er tydeligt, at sammenstillingen i SQL Server er afgørende. Vi har defineret, hvilken påvirkning det giver, hvis du foretager ændringer i sorteringen på et hvilket som helst niveau i SQL Server. Foretag altid ordentlig planlægning og test ændringerne i dit miljø med lavere livscyklus først.
Hold øje med min næste artikel, hvor jeg vil vise dig en trin-for-trin metode til at ændre sortering på serverniveau.
Del venligst denne artikel og giv din feedback, det hjælper os med at blive bedre.