Dette indlæg har "strenge knyttet:af en god grund. Vi skal gå på opdagelse i SQL VARCHAR, datatypen, der beskæftiger sig med strenge.
Dette er også "kun for dine øjne", fordi uden strenge vil der ikke være nogen blogindlæg, websider, spilinstruktioner, bogmærkede opskrifter og meget mere for vores øjne at læse og nyde. Vi beskæftiger os med en gazillion strenge hver dag. Så som udviklere er du og jeg ansvarlige for at gøre denne slags data effektiv at gemme og få adgang til.
Med dette i tankerne vil vi dække, hvad der betyder mest for opbevaring og ydeevne. Indtast do's og don'ts for denne datatype.
Men før det er VARCHAR kun en af strengtyperne i SQL. Hvad gør det anderledes?
Hvad er VARCHAR i SQL? (Med eksempler)
VARCHAR er en streng- eller tegndatatype af varierende størrelse. Du kan gemme bogstaver, tal og symboler med det. Fra og med SQL Server 2019 kan du bruge hele rækken af Unicode-tegn, når du bruger en sortering med UTF-8-understøttelse.
Du kan erklære VARCHAR-kolonner eller variabler ved hjælp af VARCHAR[(n)], hvor n står for strengstørrelsen i bytes. Værdiintervallet for n er 1 til 8000. Det er mange tegndata. Men endnu mere, du kan erklære det ved hjælp af VARCHAR(MAX), hvis du har brug for en gigantisk streng på op til 2 GB. Det er stort nok til din liste over hemmeligheder og private ting i din dagbog! Bemærk dog, at du også kan erklære den uden størrelsen, og den er som standard 1, hvis du gør det.
Lad os tage et eksempel.
DECLARE @actor VARCHAR(20) ='Robert Downey Jr.';DECLARE @movieCharacter VARCHAR(10) ='Iron Man';DECLARE @movie VARCHAR ='Avengers';SELECT @actor, @movieCharacter, @film 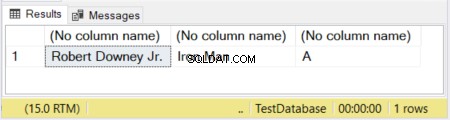
I figur 1 har de første 2 kolonner deres størrelse defineret. Den tredje kolonne efterlades uden en størrelse. Så ordet "Avengers" er afkortet, fordi en VARCHAR uden en størrelse erklæret som standard er 1 tegn.
Lad os nu prøve noget stort. Men bemærk, at denne forespørgsel vil tage et stykke tid at køre – 23 sekunder på min bærbare computer.
-- Dette vil tage et stykke tidDECLARE @giganticString VARCHAR(MAX);SET @giganticString =REPLICATE(CAST('kage bunshin no jutsu' AS VARCHAR(MAX)),100000000)SELECT DATALENGTH(@giganticString) 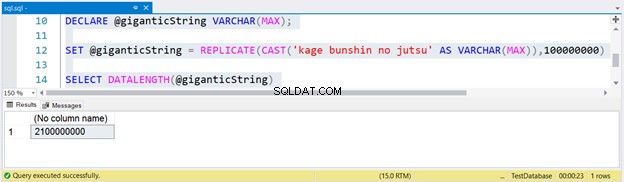
For at generere en enorm streng replikerede vi kage bunshin no jutsu 100 millioner gange. Bemærk CAST i REPLICATE. Hvis du ikke CAST strengudtrykket til VARCHAR(MAX), vil resultatet kun blive afkortet til op til 8000 tegn.
Men hvordan er SQL VARCHAR sammenlignet med andre strengdatatyper?
Forskel mellem CHAR og VARCHAR i SQL
Sammenlignet med VARCHAR er CHAR en karakterdatatype med fast længde. Uanset hvor lille eller stor en værdi du sætter til en CHAR-variabel, er den endelige størrelse størrelsen af variablen. Tjek sammenligningerne nedenfor.
DECLARE @tvSeriesTitle1 VARCHAR(20) ='The Mandalorian';DECLARE @tvSeriesTitle2 CHAR(20) ='The Mandalorian';SELECT DATALENGTH(@tvSeriesTitle1) AS VarcharValue, DATALENGTH(@tvSeriesTitle2) AS CharValue kode> 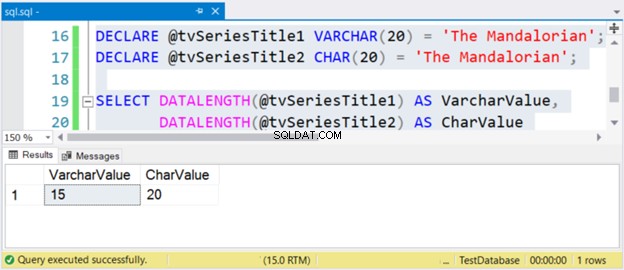
Størrelsen på strengen "The Mandalorian" er 15 tegn. Så VarcharValue kolonnen afspejler det korrekt. Dog CharValue beholder størrelsen 20 – den er polstret med 5 mellemrum til højre.
SQL VARCHAR vs NVARCHAR
To grundlæggende ting kommer til at tænke på, når man sammenligner disse datatyper.
For det første er det størrelsen i bytes. Hver karakter i NVARCHAR har dobbelt størrelse af VARCHAR. NVARCHAR(n) er kun fra 1 til 4000.
Derefter de tegn, den kan gemme. NVARCHAR kan gemme flersprogede tegn som koreansk, japansk, arabisk osv. Hvis du planlægger at gemme koreanske K-Pop-tekster i din database, er denne datatype en af dine muligheder.
Lad os få et eksempel. Vi kommer til at bruge K-pop-gruppen 세븐틴 eller Seventeen på engelsk.
DECLARE @kpopGroupKorean NVARCHAR(5) =N'세븐틴';SELECT @kpopGroupKorean AS KPopGroup, DATALENGTH(@kpopGroupKorean) AS SizeInBytes, LEN(@kpopGroupKorean) AS [NoOcode> Ovenstående kode vil udlæse strengværdien, dens størrelse i bytes og antallet af tegn. Hvis disse ikke er Unicode-tegn, er antallet af tegn lig med størrelsen i bytes. Men dette er ikke tilfældet. Se figur 4 nedenfor.
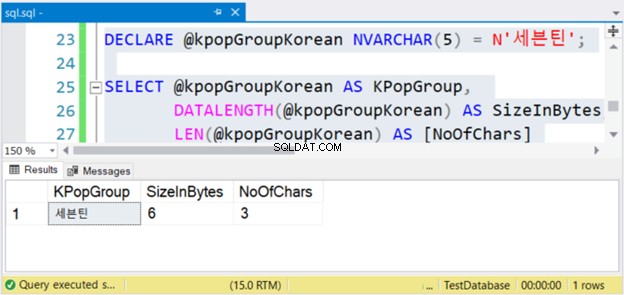
Se? Hvis NVARCHAR har 3 tegn, er størrelsen i bytes to gange. Men ikke med VARCHAR. Det samme gælder også, hvis du bruger engelske tegn.
Men hvad med NCHAR? NCHAR er modstykket til CHAR for Unicode-tegn.
SQL-server VARCHAR med UTF-8-understøttelse
VARCHAR med UTF-8-understøttelse er mulig på serverniveau, databaseniveau eller tabelkolonneniveau ved at ændre sorteringsoplysningerne. Den sortering, der skal bruges, bør understøtte UTF-8.
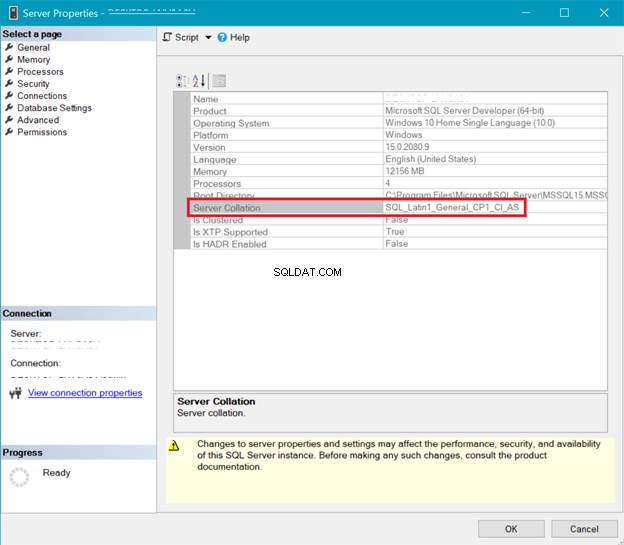
SQL SERVER SAMLING
Figur 5 viser vinduet i SQL Server Management Studio, der viser serversortering.
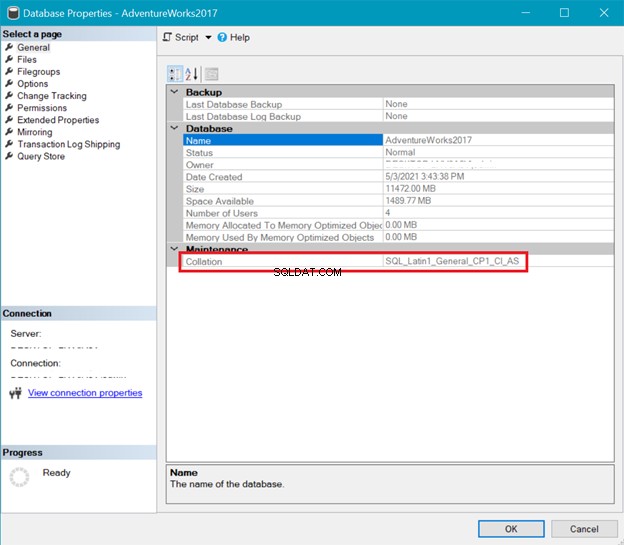
DATABASESAMLING
I mellemtiden viser figur 6 sammenstillingen af AdventureWorks database.
TABELKOLONNESAMLING
Både server- og databasesorteringen ovenfor viser, at UTF-8 ikke understøttes. Sorteringsstrengen skal have en _UTF8 i sig for UTF-8-understøttelse. Men du kan stadig bruge UTF-8-understøttelse på kolonneniveauet i en tabel. Se eksemplet.
CREATE TABLE SeventeenMemberList( id INT NOT NULL IDENTITY(1,1) PRIMARY KEY, KoreanName VARCHAR(20) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL, EnglishName VARCHAR(20) NOT NULL) NULL) Ovenstående kode har Latin1_General_100_BIN2_UTF8 samling for KoreanName kolonne. Selvom VARCHAR og ikke NVARCHAR, vil denne kolonne acceptere koreanske sprogtegn. Lad os indsætte nogle poster og derefter se dem.
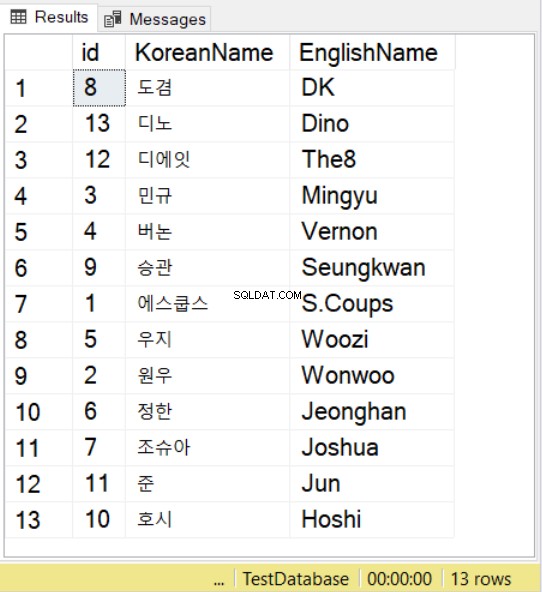
INSERT INTO SeventeenMemberList(KoreanName, EnglishName)VALUES (N'에스쿱스','S.Coups'),(N'원우','Wonwoo'),(N'민규','Mingyu') ,(N'버논','Vernon'),(N'우지','Woozi'),(N'정한','Jeonghan'),(N'조슈아','Joshua'),(N'도겸' ,'DK'),(N'승관','Seungkwan'),(N'호시','Hoshi'),(N'준','Jun'),(N'디에잇','The8') ,(N'디노','Dino')VÆLG * FRA SeventeenMemberList BESTIL EFTER KoreanNameCOLLATE Latin1_General_100_BIN2_UTF8 Vi bruger navne fra Seventeen K-pop-gruppen, der bruger koreanske og engelske modstykker. For koreanske tegn skal du bemærke, at du stadig skal præfikse værdien med N , ligesom hvad du gør med NVARCHAR-værdier.
Derefter, når du bruger SELECT med ORDER BY, kan du også bruge sortering. Du kan observere dette i eksemplet ovenfor. Dette vil følge sorteringsregler for den angivne sortering.
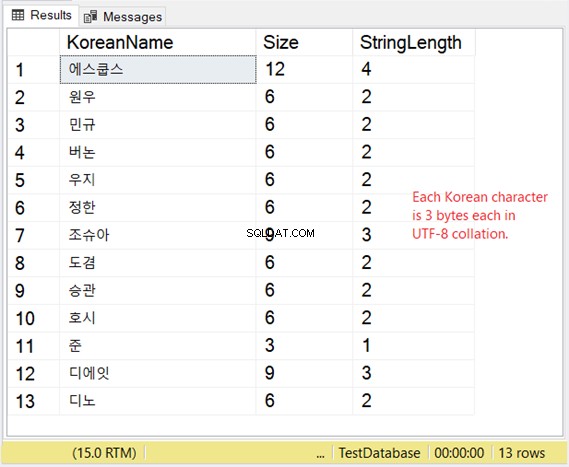
LAGRING AF VARCHAR MED UTF-8-SUPPORT
Men hvordan er opbevaringen af disse karakterer? Hvis du forventer 2 bytes pr. tegn, får du en overraskelse. Se figur 8.
Så hvis opbevaring betyder meget for dig, skal du overveje nedenstående tabel, når du bruger VARCHAR med UTF-8-understøttelse.
| Tegn | Størrelse i bytes |
| Ascii 0 – 127 | 1 |
| Det latinske skrift, og græsk, kyrillisk, koptisk, armensk, hebraisk, arabisk, syrisk, Tāna og N'Ko | 2 |
| Østasiatisk skrift som kinesisk, koreansk og japansk | 3 |
| Tegner i området 010000–10FFFF | 4 |
Vores koreanske eksempel er et østasiatisk script, så det er 3 bytes pr. tegn.
Nu hvor vi er færdige med at beskrive og sammenligne VARCHAR med andre strengtyper, lad os nu dække hvad der må og ikke må
Gøremål ved brug af VARCHAR i SQL Server
1. Angiv størrelsen
Hvad kunne gå galt uden at angive størrelsen?
TRUNCERING
Hvis du bliver doven med at angive størrelsen, vil strengen trunkeres. Du har allerede set et eksempel på dette tidligere.
LAGRING OG YDEEVNE
En anden overvejelse er opbevaring og ydeevne. Du skal kun indstille den rigtige størrelse til dine data, ikke mere. Men hvordan kunne du vide det? For at undgå trunkering i fremtiden kan du måske bare indstille den til den største størrelse. Det er VARCHAR(8000) eller endda VARCHAR(MAX). Og 2 bytes vil blive gemt som de er. Det samme med 2GB. Betyder det noget?
Et svar, der vil tage os til konceptet om, hvordan SQL Server gemmer data. Jeg har en anden artikel, der forklarer dette i detaljer med eksempler og illustrationer.
Kort sagt, data gemmes i 8KB-sider. Når en række data overstiger denne størrelse, flytter SQL Server den til en anden sideallokeringsenhed kaldet ROW_OVERFLOW_DATA.
Antag, at du har 2-byte VARCHAR-data, der kan passe til den originale sideallokeringsenhed. Når du gemmer en streng større end 8000 bytes, flyttes dataene til rækkeoverløbssiden. Krymp det derefter igen til en lavere størrelse, og det vil blive flyttet tilbage til den oprindelige side. Frem-og-tilbage-bevægelsen forårsager en masse I/O og en præstationsflaskehals. Hentning af dette fra 2 sider i stedet for 1 kræver også ekstra I/O.
En anden grund er indeksering. VARCHAR(MAX) er et stort NEJ som indeksnøgle. I mellemtiden vil VARCHAR(8000) overskride den maksimale indeksnøglestørrelse. Det er 1700 bytes for ikke-klyngede indekser og 900 bytes for klyngede indekser.
PÅVIRKNING AF DATAKONVERTERING
Alligevel er der en anden overvejelse:datakonvertering. Prøv det med en CAST uden størrelsen som koden nedenfor.
SELECT SYSDATETIMEOFFSET() AS DateTimeInput,CAST(SYSDATETIMEOFFSET() AS VARCHAR) AS ConvertedDateTime,DATALENGTH(CAST(SYSDATETIMEOFFSET() AS VARCHAR)) AS ConvertedLength Denne kode vil foretage en konvertering af en dato/tid med tidszoneoplysninger til VARCHAR.
Så hvis vi bliver dovne med at angive størrelsen under CAST eller KONVERT, er resultatet begrænset til kun 30 tegn.
Hvad med at konvertere NVARCHAR til VARCHAR med UTF-8-understøttelse? Der er en detaljeret forklaring på dette senere, så fortsæt med at læse.
2. Brug VARCHAR, hvis strengstørrelsen varierer betydeligt
Navne fra AdventureWorks databasen varierer i størrelse. Et af de korteste navne er Min Su, mens det længste navn er Osarumwense Uwaifiokun Agbonile. Det er mellem 6 og 31 tegn inklusive mellemrum. Lad os importere disse navne til 2 tabeller og sammenligne mellem VARCHAR og CHAR.
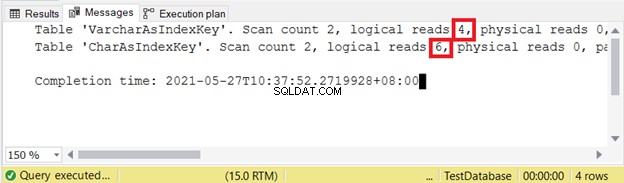
-- Tabel ved hjælp af VARCHARCREATE TABLE VarcharAsIndexKey( id INT NOT NULL IDENTITY(1,1) PRIMARY KEY, varcharName VARCHAR(50) NOT NULL)GOCREATE INDEX IX_VarcharAsIndexKey_varcharName ONGOKeycharAs TX CharAsIndexKey( id INT NOT NULL IDENTITY(1,1) PRIMÆR NØGLE, charName CHAR(50) NOT NULL)GOCREATE INDEX IX_CharAsIndexKey_charName ON CharAsIndexKey(charName)GOINSERT INTO VarcharAsIndexNøgle (MiddleName,'')FRA AdventureWorks.Person.Person INSERT INTO CharAsIndexKey (charName)SELECT DISTINCTLastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')FRA AdventureWorks.Person.Person GO Hvilken af de 2 er bedre? Lad os tjekke de logiske læsninger ved at bruge koden nedenfor og inspicere outputtet fra STATISTICS IO.
INDSTIL NOCOUNT ONSET STATISTICS IO ONSELECT id, varcharNameFROM VarcharAsIndexKeySELECT id, charNameFROM CharAsIndexKeySET STATISTICS IO FRA Logisk lyder:
Jo mindre logisk læsning jo bedre. Her brugte CHAR-kolonnen mere end det dobbelte af VARCHAR-modstykket. Således vinder VARCHAR i dette eksempel.
3. Brug VARCHAR som indeksnøgle i stedet for CHAR, når værdier varierer i størrelse
Hvad skete der, når de blev brugt som indeksnøgler? Vil CHAR klare sig bedre end VARCHAR? Lad os bruge de samme data fra forrige afsnit og besvare dette spørgsmål.
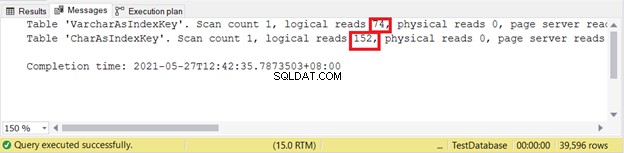
Vi forespørger nogle data og kontrollerer de logiske læsninger. I dette eksempel bruger filteret indeksnøglen.
SET NOCOUNT ONSET STATISTICS IO ONSELECT varcharName FROM VarcharAsIndexKey WHERE varcharName ='Sai, Adriana A' OR varcharName ='Rogers, Caitlin D'SELECT charName FROM CharAsIndexKey WHERE charName ='Sai, Adriana A =' ELLER charName Rogers, Caitlin D'SET STATISTICS IO OFF Logisk lyder:
Derfor er VARCHAR-indeksnøgler bedre end CHAR-indeksnøgler, når nøglen har forskellige størrelser. Men hvad med INSERT og UPDATE, der vil ændre indeksposterne?
NÅR DU BRUGER INSERT AND UPDATE
Lad os teste 2 tilfælde og derefter kontrollere de logiske læsninger, som vi plejer.
INDSTIL STATISTIK IO ONINSERT INTO VarcharAsIndexKey (varcharName)VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')INSERT INTO CharAsIndexKey (charName)VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')SET STATISTICS IO OFF Logisk lyder:
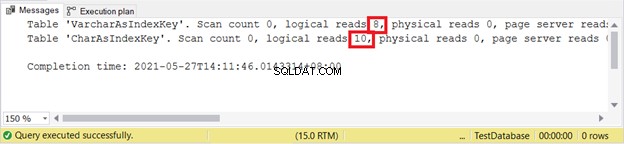
VARCHAR er stadig bedre, når du indsætter poster. Hvad med OPDATERING?
SET STATISTICS IO ONUPDATE VarcharAsIndexKeySET varcharName ='Hulk'WHERE varcharName ='Ruffalo, Mark'UPDATE CharAsIndexKeySET charName ='Hulk'WHERE charName ='Ruffalo, Mark'SET STATISTICS IO OFF Logisk lyder:
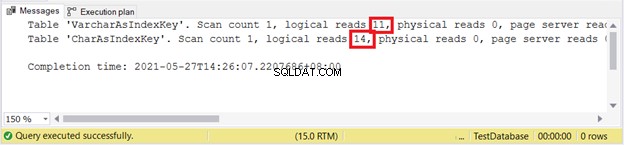
Det ser ud til, at VARCHAR vinder igen.
Til sidst vinder den vores test, selvom den måske er lille. Har du en større testcase, der beviser det modsatte?
4. Overvej VARCHAR med UTF-8-understøttelse af flersprogede data (SQL Server 2019+)
Hvis der er en blanding af Unicode- og ikke-Unicode-tegn i din tabel, kan du overveje VARCHAR med UTF-8-understøttelse over NVARCHAR. Hvis de fleste tegn er inden for området ASCII 0 til 127, kan det give pladsbesparelser sammenlignet med NVARCHAR.
Lad os få en sammenligning for at se, hvad jeg mener.
NVARCHAR TIL VARCHAR MED UTF-8-SUPPORT
Har du allerede migreret dine databaser til SQL Server 2019? Planlægger du at migrere dine strengdata til UTF-8-sortering? Vi har et eksempel på en blandet værdi af japanske og ikke-japanske tegn for at give dig en idé.
CREATE TABLE NVarcharToVarcharUTF8(NVarcharValue NVARCHAR(20) NOT NULL, VarcharUTF8 VARCHAR(45) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL)GOINSERT INTO NVarcharToVarchUT' NARUTO-ナルト- 疾風伝'); -- NARUTO ShippûdenSELECT NVarcharValue,LEN(NVarcharValue) AS nvarcharNoOfChars ,DATALENGTH(NVarcharValue) AS nvarcharSizeInBytes,VarcharUTF8,LEN(VarcharUTF8) AS varcharNoOfChars,DATALARUTF8)Barchy Nu hvor dataene er indstillet, vil vi inspicere størrelsen i bytes af de 2 værdier:

Overraskelse! Med NVARCHAR er størrelsen 30 bytes. Det er 15 gange mere end 2 tegn. Men når den konverteres til VARCHAR med UTF-8-understøttelse, er størrelsen kun 27 bytes. Hvorfor 27? Tjek, hvordan dette beregnes.

Således er 9 af tegnene 1 byte hver. Det er interessant, fordi engelske bogstaver med NVARCHAR også er 2 bytes. Resten af de japanske tegn er på 3 bytes hver.
Hvis dette har været alle japanske tegn, ville 15-tegns strengen være 45 bytes og også forbruge den maksimale størrelse af VarcharUTF8 kolonne. Bemærk, at størrelsen af NVarcharValue kolonne er mindre end VarcharUTF8 .
Størrelserne kan ikke være ens ved konvertering fra NVARCHAR, ellers kan dataene ikke passe. Du kan henvise til den foregående tabel 1.
Overvej indvirkningen på størrelsen, når du konverterer NVARCHAR til VARCHAR med UTF-8-understøttelse.
Don'ts ved brug af VARCHAR i SQL Server
1. Når strengstørrelsen er fast og ikke kan nulstilles, skal du bruge CHAR i stedet.
Den generelle tommelfingerregel, når der kræves en streng i fast størrelse, er at bruge CHAR. Jeg følger dette, når jeg har et datakrav, der har brug for højrepolstrede mellemrum. Ellers bruger jeg VARCHAR. Jeg havde et par use cases, hvor jeg skulle dumpe strenge med fast længde uden afgrænsninger i en tekstfil til en klient.
Yderligere bruger jeg kun CHAR-kolonner, hvis kolonnerne ikke kan nulstilles. Hvorfor? Fordi størrelsen i bytes af CHAR-kolonner, når NULL er lig med den definerede størrelse af kolonnen. Men VARCHAR, når NULL har en størrelse på 1, uanset hvor meget den definerede størrelse er. Kør koden nedenfor, og se den selv.
DECLARE @charValue CHAR(50) =NULL;DECLARE @varcharValue VARCHAR(1000) =NULL;SELECT DATALENGTH(ISNULL(@charvalue,0)) AS CharSize,DATALENGTH(ISNULL(@varcharvalue,0)) AS VarcharSize 2. Brug ikke VARCHAR(n) hvis n Vil overstige 8000 bytes. Brug VARCHAR(MAX) i stedet.
Har du en streng, der vil overstige 8000 bytes? Det er tid til at bruge VARCHAR(MAX). Men for de mest almindelige former for data som navne og adresser er VARCHAR(MAX) overdreven og vil påvirke ydeevnen. I min personlige erfaring kan jeg ikke huske et krav om, at jeg brugte VARCHAR(MAX).
3. Når du bruger flersprogede tegn med SQL Server 2017 og derunder. Brug NVARCHAR i stedet.
Dette er et oplagt valg, hvis du stadig bruger SQL Server 2017 og derunder.
Bundlinjen
VARCHAR-datatypen har tjent os godt for så mange aspekter. Det gjorde det for mig siden SQL Server 7. Alligevel træffer vi nogle gange stadig dårlige valg. I dette indlæg er SQL VARCHAR defineret og sammenlignet med andre strengdatatyper med eksempler. Og igen, her er do's and don'ts for en hurtigere database:
Gøre:
- Angiv størrelsen n i VARCHAR[(n)], selvom det er valgfrit.
- Brug den, når strengstørrelsen varierer betydeligt.
- Betragt VARCHAR-kolonner som indeksnøgler i stedet for CHAR.
- Og hvis du nu bruger SQL Server 2019, så overvej VARCHAR for flersprogede strenge med UTF-8-understøttelse.
Lad være med:
- Brug ikke VARCHAR, når strengstørrelsen er fast og ikke kan nulstilles.
- Brug ikke VARCHAR(n), når strengstørrelsen vil overstige 8000 bytes.
- Og brug ikke VARCHAR til flersprogede data, når du bruger SQL Server 2017 og tidligere.
Har du andet at tilføje? Fortæl os det i kommentarfeltet. Hvis du tror, at dette vil hjælpe dine udviklervenner, så del venligst dette på dine foretrukne sociale medieplatforme.