Den relationelle model for datastyring blev først udviklet af Dr. Edgar F. Codd i 1969. Moderne relationelle databasestyringssystemer (RDBMS'er) er tilpasset paradigmet. Nøglestrukturen identificeret med RDBMS er den logiske struktur kaldet en "tabel". Tabeller er primært sammensat af rækker og kolonner (også kaldet poster og attributter eller tupler og felter). I en streng matematisk forstand, udtrykket tabel omtales faktisk som en relation og står for udtrykket "Relationel Model". I matematik er en relation en repræsentation af en mængde.
Udtryksattributten giver en god beskrivelse af formålet med en kolonne – den karakteriserer rækkerne forbundet med den. Hver kolonne skal være af en bestemt datatype, og hver række skal have nogle unikke identificerende egenskaber kaldet "nøgler". Dataændring er typisk mere effektiv, når den udføres ved hjælp af den relationelle model, mens datahentning kan være hurtigere med den ældre hierarkiske model, som er blevet omdefineret i model NoSQL-systemer.
Datanormalisering er en matematisk proces med modellering af forretningsdata til en form, der sikrer, at hver enhed er repræsenteret af en enkelt relation (tabel). De tidlige fortalere for den relationelle model foreslog et begreb om normale former. Edgar Codd definerede den første, anden og tredje Normalform. Han fik derefter selskab af Raymond F. Boyce. Sammen definerede de Boyce-Codd Normal Form. Efterhånden er seks normale former defineret teoretisk, men i de fleste praktiske anvendelser udvider vi typisk normalisering op til den tredje normale form. Hver normal formular stræber efter at undgå uregelmæssigheder under dataændringer, reducere redundansen og afhængigheden af data i en tabel. Hvert niveau af normalisering har en tendens til at introducere flere tabeller, reducere redundans, øge enkeltheden af hver tabel, men øger også kompleksiteten af hele det relationelle databasestyringssystem. Så strukturelt har RDBM-systemer en tendens til at være mere komplekse end hierarkiske systemer.
Hvorfor databasenormalisering:Fire anomalier
Datalagring uden normalisering forårsager en række problemer med dataforbrug. Fortalerne for normalisering kaldte sådanne problemer anomalier. For at beskrive disse anomalier, lad os se på dataene præsenteret i fig. 1.

Fig. 1 personalebord
Fortegnelse 1. Grundlæggende tabel til demonstration af databasenormalisering.
1.1. Opret tabel
use privatework go create table staffers ( staffID int identity (1,1) ,StaffName varchar(50) ,Role varchar(50) ,Department varchar (100) ,Manager varchar (50) ,Gender char(1) ,DateofBirth datetime2 )
1.2. Indsæt rækker
insert into staffers values ('John Doe','Engineering','Kweku Amarh','M','06-Oct-1965');
insert into staffers values ('Henry Ofori','Engineering','Kweku Amarh','M','06-Mar-1982');
insert into staffers values ('Jessica Yuiah','Engineering','Kweku Amarh','F','06-Oct-1965');
insert into staffers values ('Ahmed Assah','Engineering','Kweku Amarh','M','06-Oct-1965'); 1.3. Forespørg i tabellen
select * from staffers;
Denne tabel repræsenterer i det væsentlige to sæt data, der er blevet kombineret ved et uheld:personalenavne og afdelinger. Bemærk, at alle medarbejdere er fra samme afdeling:Engineering. Det blev gjort for enkelheds skyld og for at demonstrere normalisering. Der er tre hovedproblemer forbundet med at manipulere denne struktur:
Indsættelsesanomalien
For at indsætte en ny post skal vi blive ved med at gentage afdelingens og ledernes navne.
Sletningsanomalien
For at slette en medarbejders post skal vi også slette den tilknyttede leder og afdeling. Hvis der er behov for at fjerne ALLE medarbejderes registreringer, skal vi også fjerne alle afdelinger og alle ledere.
Opdateringsanomalien
Hvis der er behov for at ændre lederen af en afdeling, skal vi foretage ændringen i hver enkelt række i denne tabel, da værdierne er duplikeret for hver medarbejder.
Normale databaseformularer
I de følgende afsnit af artiklen vil vi forsøge at beskrive den 1., 2. og 3. Normale Form, som er meget mere tilbøjelige til at blive observeret i rigtige RDBM-systemer. Der er andre udvidelser af teorien, såsom den fjerde, femte og Boyce-Codd normalform, men i denne artikel vil vi begrænse os til tre normale former.
Den første normale form
Den 1. Normalform er defineret af fire regler:
Hver kolonne skal indeholde værdier af samme datatype.
Tabellen Staffers opfylder allerede denne regel.
Hver kolonne i en tabel skal være atomare.
Dette betyder i bund og grund, at du skal opdele indholdet af en kolonne, indtil de ikke længere kan opdeles. Bemærk, at rollen kolonnen i Medarbejdere tabel bryder regel 2 for rækken med StaffID=3.
Hver række i en tabel skal være unikke.
Unikhed i normaliserede tabeller opnås typisk ved hjælp af primære nøgler. En primær nøgle definerer hver række i en tabel unikt. Det meste af tiden er en primær nøgle kun defineret af én kolonne. En primær nøgle, der består af mere end én kolonne, kaldes en sammensat nøgle.
Rækkefølgen, som poster gemmes i, er ligegyldig.
At justere dataene i medarbejderne tabel med principperne i den første normale form, skal vi opdele tabellen som vist i figur 2, 3 og 4.
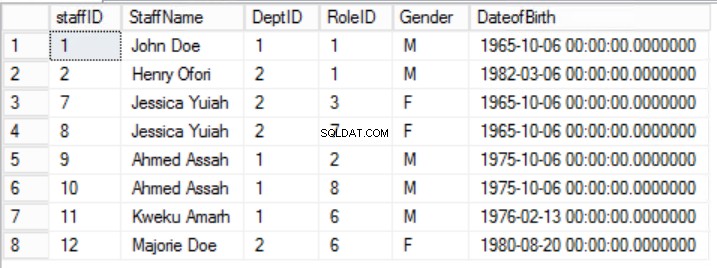
Fig. 2 ansatte bord
Vi har indsnævret dataene i Medarbejdere tabel og implementerede en sammensat primærnøgle for at garantere unikhed. Vi har også oprettet to ekstra tabeller Roller og afdelinger som har relationer til de centrale medarbejdere tabel implementeret ved hjælp af fremmednøgler. Gennemgå DDL i liste 2.
Liste 2. DDL af nye medarbejdere Tabel for den første normale form.
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID] [int] NOT NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC, [RoleID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([RoleID]) REFERENCES [dbo].[Roles] ([RoleID]) GO
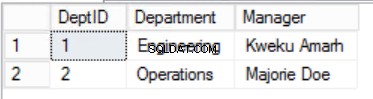
Fig. 3 afdelinger Tabel
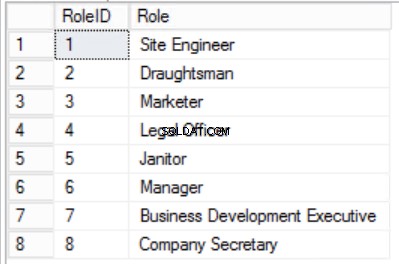
Fig. 4 Rolle Tabel
Den anden normale form
Formularen 1. Normal skal allerede være på plads.
Hver ikke-nøglekolonne må ikke have delvis afhængighed af den primære nøgle.
Formålet med den anden regel er, at alle kolonner i tabellen skal afhænge af alle kolonner, der omfatter den primære nøgle tilsammen. Når vi ser tilbage på tabellerne i figur 2, 3 og 4, finder vi, at vi har opfyldt alle kravene i den første normalform. Vi har også opnået kravene i den anden normalformular for to tabeller roller og afdelinger . Men i tilfældet med medarbejderne tabel, har vi stadig et problem. Vores primære nøgle er sammensat af kolonnerne StaffID og RolleID.
Regel 2 i den anden normalformular er her brudt af det faktum, at personalets køn og fødselsdato ikke afhænger af RolleID'et. Der er en delvis afhængighed.
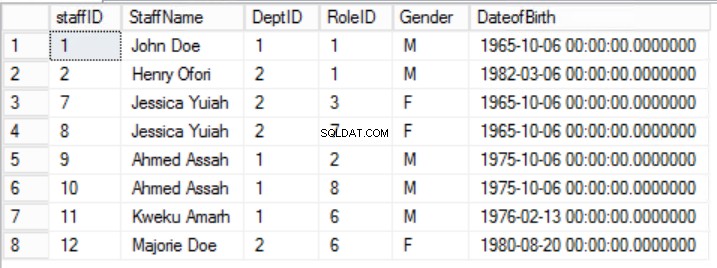
Fig. 5 ansatte til den første normale form
I det givne eksempel kan vi forsøge at løse dette ved at fjerne RolleID fra den primære nøgle, men hvis vi gør dette, vil vi bryde en anden regel:rollen som unikhed angivet i den første normale form. Vi må tage en anden tilgang. Vi ændrer medarbejderne tabel med den forståelse, at en medarbejder kan spille mere end én rolle. Se fig. 6.
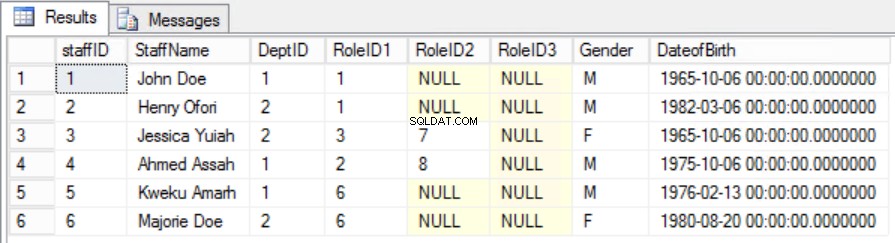
Fig. 6 Staffers Tabel for den anden normalform
Det er lykkedes os at bevare unikhed såvel som at fjerne delvis afhængighed.
Liste 3. DDL af New Staffers Tabel for den anden normalform.
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers2NF]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID1] [int] NOT NULL, [RoleID2] [int] NULL, [RoleID3] [int] NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID1]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID2]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID3]) REFERENCES [dbo].[Roles] ([RoleID]) GO
Den tredje normale form
Den anden normalform skal allerede være på plads.
Hver ikke-nøglekolonne må ikke have transitiv afhængighed af den primære nøgle.
Tanken i den tredje normale form er, at der ikke må være nogen kolonner, der afhænger af ikke-nøglekolonner, selvom de ikke-nøglekolonner allerede afhænger af den primære nøgle.
Antag som et eksempel, at vi besluttede at tilføje en ekstra kolonne til Medarbejdere tabel som vist i fig. 7 for tydeligt at se medarbejderens leder. Ved at gøre det ville vi have brudt den anden tredje normalform-regel, fordi Manager-navnet afhænger af DeptID'et og DeptID'et afhænger til gengæld af StaffID'et. Dette er en transitiv afhængighed.
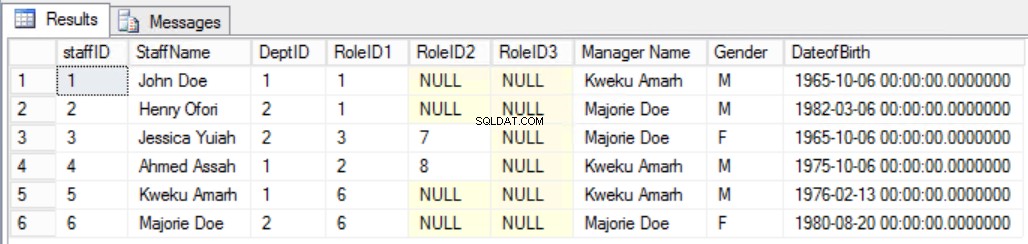
Fig. 7 Staffers Tabel for den tredje normalform (brudt regel)
Det ville være bedre at beholde den gamle formular og vise de nødvendige oplysninger ved hjælp af en sammenføjning mellem Staffers-tabellen og afdelingstabellen.
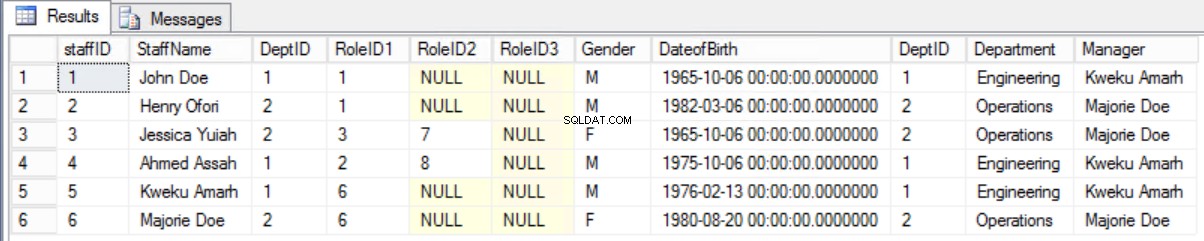
Fig. 8 Deltag mellem medarbejder og afdeling
Fortegnelse 4. Forespørgsel til displaymedarbejdere og ledere.
select * from staffers2NF s join Department d on s.DeptID=d.DeptID;
Praktisk anvendelse
De fleste modne applikationer implementerer reglerne for normalisering i rimeligt omfang. Vi ser, at implementering af datanormalisering giver anledning til brugen af Primary Key Constraints og Foreign Key Constraints. Derudover dukker sådanne problemer som Foreign Keys-indeksering også op, når vi dykker dybere ned i emnet. Tidligere nævnte vi, hvordan manglen på normalisering kan påvirke den gnidningsløse manipulation af data som beskrevet i Anomalierne Indsættelse, Sletning og Opdatering. En mangel på korrekt normalisering kan også indirekte påvirke forespørgselsydelsen.
Jeg er for nylig stødt på en tabel, som havde den form, der er vist i tabel 1, som vi vil kalde Customer_Accounts.
S/Nej | Navn | Account_No | Telefonnr |
1 | Kenneth Igiri | 9922344592 | 2348039988456, 2348039988456, 2348039988456 |
2 | Ernest Doe | 6677554897 | 2348022887546, 2348039988456 |
Tabel 1 Kundekonti
Hovedproblemet med denne tabel er, at den bryder den anden regel i First Normal Form. Resultatet i vores tilfælde var, at søgning efter kunder baseret på deres telefonnumre krævede brugen af et LIKE i WHERE-klausulen og en førende %.
Select account_no from Customer_Accounts where Phone_No like ‘%2348039988456%’;
Betydningen af ovenstående konstruktion var, at optimeringsværktøjet aldrig nogensinde brugte et indeks, hvilket var et stort ydeevneproblem.
Konklusion
Datanormalisering ligger inden for databasedesign, og både udviklere og DBA'er bør være opmærksomme på reglerne, der er skitseret i denne artikel. Det er altid bedre at få gennemført normaliseringen, før databasen går i produktion. Fordelene ved et korrekt designet Relational Database Management System er simpelthen besværet værd.