Sidste oktober udfordrede vi vores PyBites' publikum til at lave en webapp for bedre at kunne navigere i Daily Python Tip-feedet. I denne artikel vil jeg dele, hvad jeg byggede og lærte undervejs.
I denne artikel lærer du:
- Sådan klones projektets repos og konfigurerer appen.
- Sådan bruger du Twitter API via Tweepy-modulet til at indlæse tweets.
- Sådan bruger du SQLAlchemy til at gemme og administrere dataene (tip og hashtags).
- Sådan bygger du en simpel webapp med Bottle, et mikroweb-framework, der ligner Flask.
- Sådan bruger du pytest-rammeværket til at tilføje test.
- Hvordan Better Code Hubs vejledning førte til mere vedligeholdelig kode.
Hvis du vil følge med, læse koden i detaljer (og muligvis bidrage), foreslår jeg, at du fordeler repoen. Lad os komme i gang.
Projektopsætning
For det første er Navnerum en dybt god idé så lad os gøre vores arbejde i et virtuelt miljø. Ved at bruge Anaconda opretter jeg det sådan:
$ virtualenv -p <path-to-python-to-use> ~/virtualenvs/pytip
Opret en produktions- og en testdatabase i Postgres:
$ psql
psql (9.6.5, server 9.6.2)
Type "help" for help.
# create database pytip;
CREATE DATABASE
# create database pytip_test;
CREATE DATABASE
Vi skal bruge legitimationsoplysninger for at oprette forbindelse til databasen og Twitter API (opret en ny app først). I henhold til bedste praksis skal konfigurationen gemmes i miljøet, ikke koden. Sæt følgende env-variabler i slutningen af ~/virtualenvs/pytip/bin/activate , scriptet, der håndterer aktivering/deaktivering af dit virtuelle miljø, og sørg for at opdatere variablerne for dit miljø:
export DATABASE_URL='postgres://postgres:password@localhost:5432/pytip'
# twitter
export CONSUMER_KEY='xyz'
export CONSUMER_SECRET='xyz'
export ACCESS_TOKEN='xyz'
export ACCESS_SECRET='xyz'
# if deploying it set this to 'heroku'
export APP_LOCATION=local
I deaktiveringsfunktionen af det samme script deaktiverer jeg dem, så vi holder tingene uden for shell-omfanget, når vi deaktiverer (forlader) det virtuelle miljø:
unset DATABASE_URL
unset CONSUMER_KEY
unset CONSUMER_SECRET
unset ACCESS_TOKEN
unset ACCESS_SECRET
unset APP_LOCATION
Nu er et godt tidspunkt at aktivere det virtuelle miljø:
$ source ~/virtualenvs/pytip/bin/activate
Klon repoen, og med det virtuelle miljø aktiveret, installer kravene:
$ git clone https://github.com/pybites/pytip && cd pytip
$ pip install -r requirements.txt
Dernæst importerer vi samlingen af tweets med:
$ python tasks/import_tweets.py
Bekræft derefter, at tabellerne blev oprettet, og tweets blev tilføjet:
$ psql
\c pytip
pytip=# \dt
List of relations
Schema | Name | Type | Owner
--------+----------+-------+----------
public | hashtags | table | postgres
public | tips | table | postgres
(2 rows)
pytip=# select count(*) from tips;
count
-------
222
(1 row)
pytip=# select count(*) from hashtags;
count
-------
27
(1 row)
pytip=# \q
Lad os nu køre testene:
$ pytest
========================== test session starts ==========================
platform darwin -- Python 3.6.2, pytest-3.2.3, py-1.4.34, pluggy-0.4.0
rootdir: realpython/pytip, inifile:
collected 5 items
tests/test_tasks.py .
tests/test_tips.py ....
========================== 5 passed in 0.61 seconds ==========================
Og til sidst kør Bottle-appen med:
$ python app.py
Gå til https://localhost:8080 og voilà:du bør se tipsene sorteret faldende efter popularitet. Ved at klikke på et hashtag-link til venstre eller bruge søgefeltet, kan du nemt filtrere dem. Her ser vi pandaerne tips for eksempel:
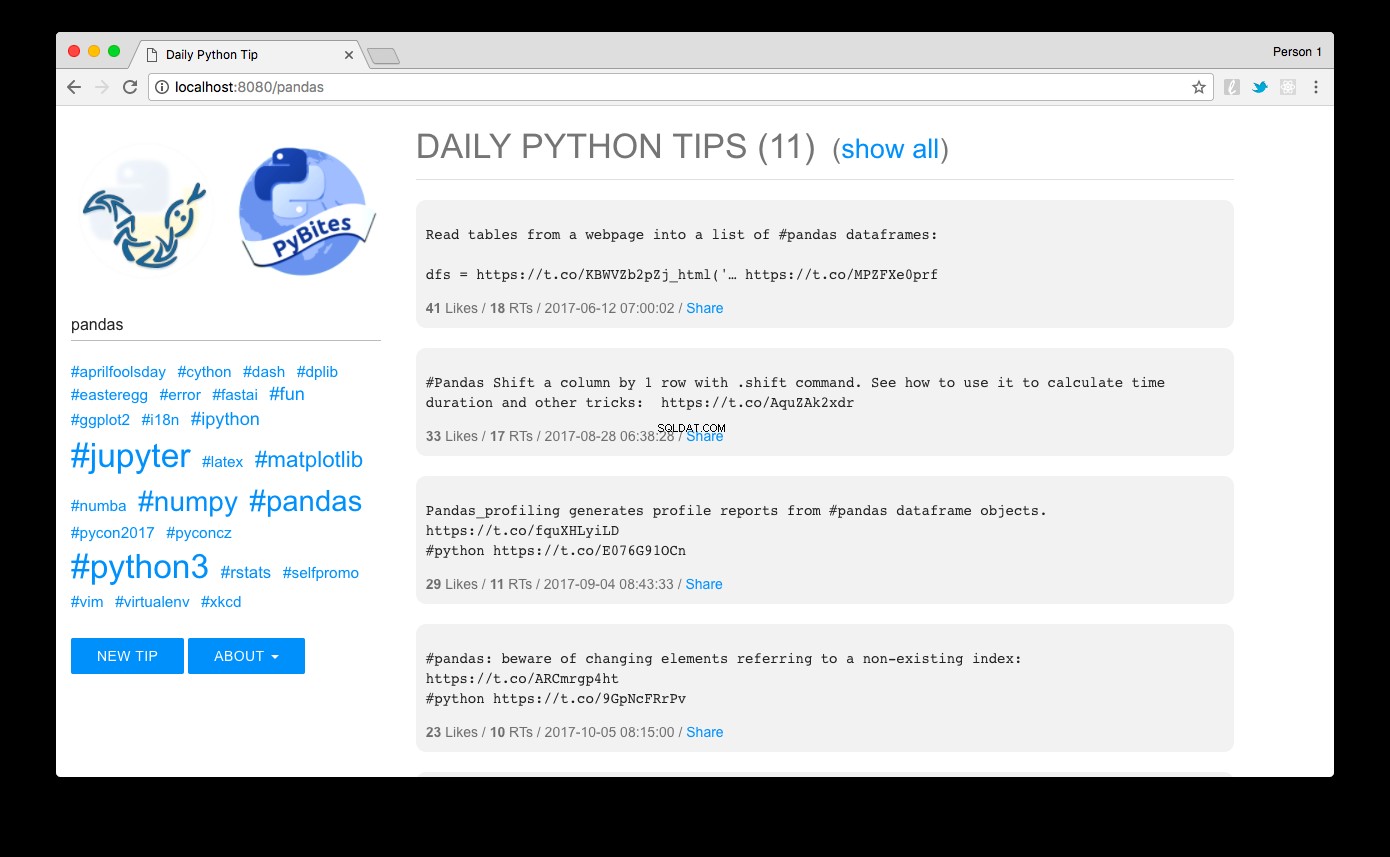
Designet, jeg lavede med MUI - en letvægts CSS-ramme, der følger Googles retningslinjer for materialedesign.
Implementeringsdetaljer
DB og SQLAlchemy
Jeg brugte SQLAlchemy til at interface med DB'en for at undgå at skulle skrive en masse (redundant) SQL.
I tips/models.py , definerer vi vores modeller - Hashtag og Tip - at SQLAlchemy vil mappe til DB-tabeller:
from sqlalchemy import Column, Sequence, Integer, String, DateTime
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Hashtag(Base):
__tablename__ = 'hashtags'
id = Column(Integer, Sequence('id_seq'), primary_key=True)
name = Column(String(20))
count = Column(Integer)
def __repr__(self):
return "<Hashtag('%s', '%d')>" % (self.name, self.count)
class Tip(Base):
__tablename__ = 'tips'
id = Column(Integer, Sequence('id_seq'), primary_key=True)
tweetid = Column(String(22))
text = Column(String(300))
created = Column(DateTime)
likes = Column(Integer)
retweets = Column(Integer)
def __repr__(self):
return "<Tip('%d', '%s')>" % (self.id, self.text)
I tips/db.py , vi importerer disse modeller, og nu er det nemt at arbejde med DB, for eksempel at interface med Hashtag model:
def get_hashtags():
return session.query(Hashtag).order_by(Hashtag.name.asc()).all()
Og:
def add_hashtags(hashtags_cnt):
for tag, count in hashtags_cnt.items():
session.add(Hashtag(name=tag, count=count))
session.commit()
Forespørg efter Twitter API
Vi skal hente dataene fra Twitter. Til det oprettede jeg tasks/import_tweets.py . Jeg har pakket dette under opgaver fordi det skal køres i et dagligt cronjob at lede efter nye tips og opdatere statistik (antal likes og retweets) på eksisterende tweets. For nemheds skyld får jeg tabellerne genskabt dagligt. Hvis vi begynder at stole på FK-relationer med andre tabeller, bør vi helt klart vælge opdateringsudsagn frem for delete+add.
Vi brugte dette script i projektopsætningen. Lad os se, hvad det gør mere detaljeret.
Først opretter vi et API-sessionsobjekt, som vi videregiver til tweepy.Cursor. Denne funktion i API'en er virkelig rar:den beskæftiger sig med paginering, iteration gennem tidslinjen. For mængden af drikkepenge - 222 på det tidspunkt, jeg skriver dette - er det virkelig hurtigt. exclude_replies=True og include_rts=False argumenter er praktiske, fordi vi kun vil have Daily Python Tip's egne tweets (ikke re-tweets).
At udtrække hashtags fra tipsene kræver meget lidt kode.
Først definerede jeg et regex for et tag:
TAG = re.compile(r'#([a-z0-9]{3,})')
Derefter brugte jeg findall for at få alle tags.
Jeg sendte dem til collections.Counter som returnerer et dikt-lignende objekt med tags som nøgler og tæller som værdier, ordnet i faldende rækkefølge efter værdier (mest almindelige). Jeg udelukkede det for almindelige python-tag, som ville skævvride resultaterne.
def get_hashtag_counter(tips):
blob = ' '.join(t.text.lower() for t in tips)
cnt = Counter(TAG.findall(blob))
if EXCLUDE_PYTHON_HASHTAG:
cnt.pop('python', None)
return cnt
Til sidst, import_* funktioner i tasks/import_tweets.py udfører den faktiske import af tweets og hashtags ved at kalde add_* DB-metoder for tip bibliotek/pakke.
Lav en simpel webapp med Bottle
Med dette forarbejde udført er det overraskende nemt at lave en webapp (eller ikke så overraskende, hvis du har brugt Flask før).
Først og fremmest mød Flaske:
Bottle er en hurtig, enkel og letvægts WSGI mikro web-ramme til Python. Det distribueres som et enkelt filmodul og har ingen andre afhængigheder end Python Standard Library.
Pæn. Den resulterende webapp består af <30 LOC og kan findes i app.py.
For denne simple app er en enkelt metode med et valgfrit tag-argument alt, der skal til. I lighed med Flask håndteres routingen med dekoratører. Hvis det kaldes med et tag, filtrerer det tipsene på tagget, ellers viser det dem alle. Visningsdekoratøren definerer den skabelon, der skal bruges. Ligesom Flask (og Django) returnerer vi en diktat til brug i skabelonen.
@route('/')
@route('/<tag>')
@view('index')
def index(tag=None):
tag = tag or request.query.get('tag') or None
tags = get_hashtags()
tips = get_tips(tag)
return {'search_tag': tag or '',
'tags': tags,
'tips': tips}
I henhold til dokumentationen, for at arbejde med statiske filer, tilføjer du dette uddrag øverst efter importen:
@route('/static/<filename:path>')
def send_static(filename):
return static_file(filename, root='static')
Endelig vil vi sikre os, at vi kun kører i fejlretningstilstand på localhost, derfor APP_LOCATION env variabel, vi definerede i Project Setup:
if os.environ.get('APP_LOCATION') == 'heroku':
run(host="0.0.0.0", port=int(os.environ.get("PORT", 5000)))
else:
run(host='localhost', port=8080, debug=True, reloader=True)
Skabeloner til flasker
Flasken kommer med en hurtig, kraftfuld og nem at lære indbygget skabelonmotor kaldet SimpleTemplate.
I visningsunderbiblioteket definerede jeg en header.tpl , index.tpl , og footer.tpl . Til tagskyen brugte jeg en simpel inline CSS, der øgede tagstørrelsen efter antal, se header.tpl :
% for tag in tags:
<a style="font-size: {{ tag.count/10 + 1 }}em;" href="/{{ tag.name }}">#{{ tag.name }}</a>
% end
I index.tpl vi går gennem tipsene:
% for tip in tips:
<div class='tip'>
<pre>{{ !tip.text }}</pre>
<div class="mui--text-dark-secondary"><strong>{{ tip.likes }}</strong> Likes / <strong>{{ tip.retweets }}</strong> RTs / {{ tip.created }} / <a href="https://twitter.com/python_tip/status/{{ tip.tweetid }}" target="_blank">Share</a></div>
</div>
% end
Hvis du er bekendt med Flask og Jinja2, burde dette se meget bekendt ud. Indlejring af Python er endnu nemmere med mindre indtastning—(% ... vs {% ... %} ).
Alle css, billeder (og JS, hvis vi ville bruge det) går ind i den statiske undermappe.
Og det er alt, hvad der er for at lave en grundlæggende webapp med Bottle. Når først du har defineret datalaget korrekt, er det ret ligetil.
Tilføj test med pytest
Lad os nu gøre dette projekt en smule mere robust ved at tilføje nogle tests. At teste DB'en krævede lidt mere gravning i pytest-rammen, men jeg endte med at bruge dekoratoren pytest.fixture til at oprette og rive ned en database med nogle test-tweets.
I stedet for at kalde Twitter API, brugte jeg nogle statiske data, der blev leveret i tweets.json .Og i stedet for at bruge live DB i tips/db.py , jeg tjekker, om pytest er den, der ringer (sys.argv[0] ). Hvis ja, bruger jeg test-DB. Jeg vil sandsynligvis ændre dette, fordi Bottle understøtter arbejde med konfigurationsfiler.
Hashtag-delen var nemmere at teste (test_get_hashtag_counter ), fordi jeg bare kunne tilføje nogle hashtags til en flerlinjet streng. Der er ikke behov for inventar.
Kodekvalitet er vigtig – Bedre kodehub
Better Code Hub guider dig til at skrive, ja, bedre kode. Inden testen blev skrevet, fik projektet 7:
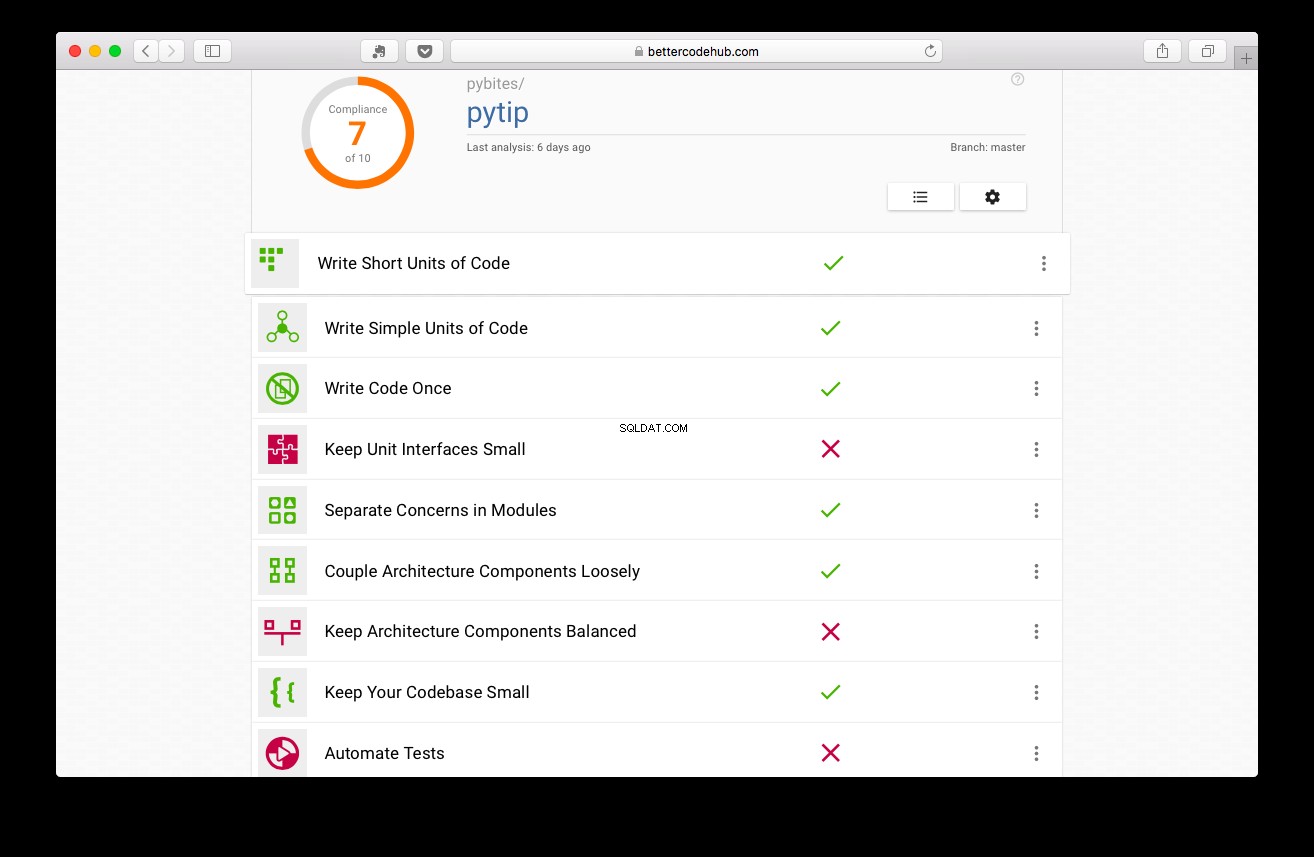
Ikke dårligt, men vi kan gøre det bedre:
-
Jeg stødte det til en 9 ved at gøre koden mere modulær, tage DB-logikken ud af app.py (webapp), sætte den i tipsmappen/pakken (refaktorering 1 og 2)
-
Så med testene på plads fik projektet 10:
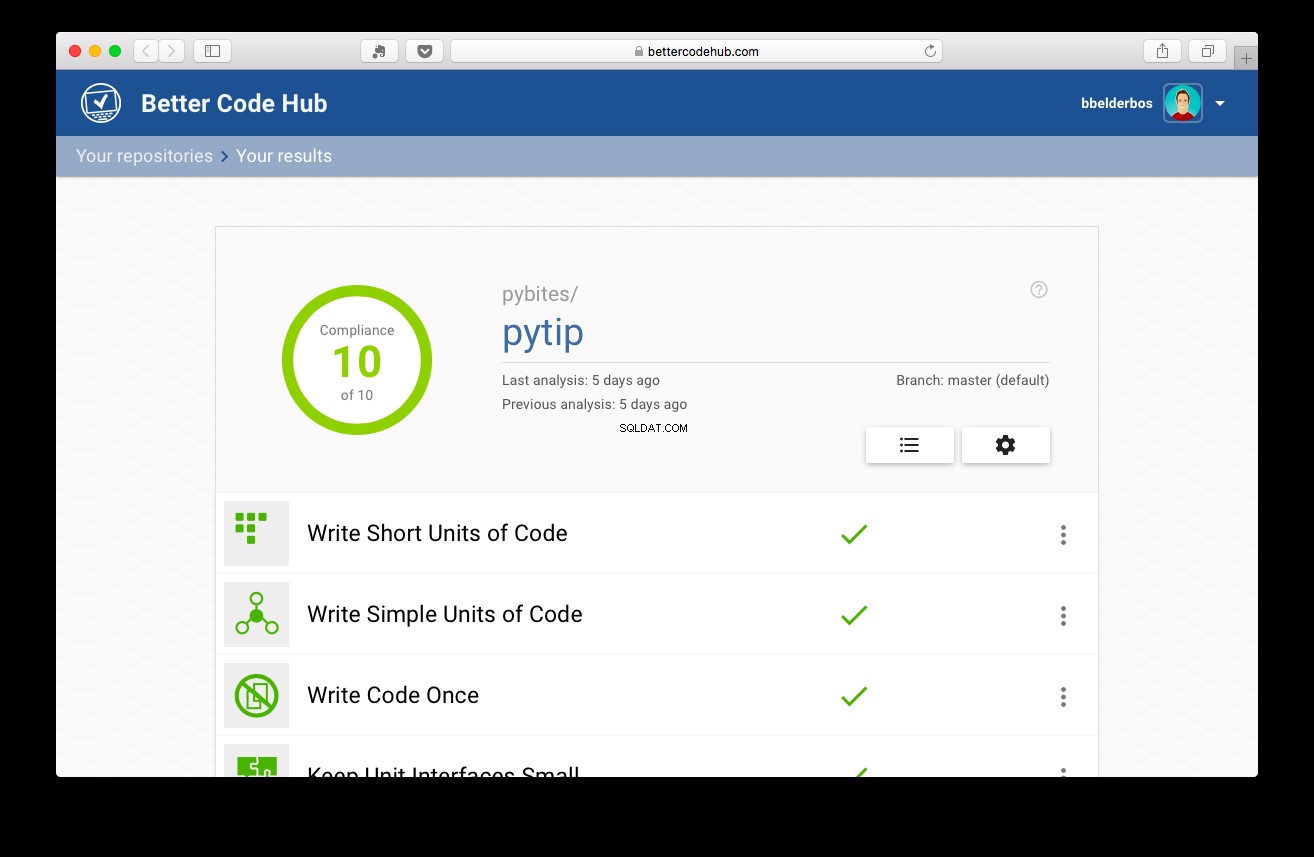
Konklusion og læring
Vores Code Challenge #40 tilbød nogle gode øvelser:
- Jeg byggede en nyttig app, som kan udvides (jeg vil tilføje en API).
- Jeg brugte nogle seje moduler, der er værd at udforske:Tweepy, SQLAlchemy og Bottle.
- Jeg lærte noget mere pytest, fordi jeg havde brug for fixtures til at teste interaktion med DB.
- Over alt, fordi appen skulle gøres testbar, blev appen mere modulopbygget, hvilket gjorde den nemmere at vedligeholde. Better Code Hub var til stor hjælp i denne proces.
- Jeg implementerede appen til Heroku ved hjælp af vores trinvise vejledning.
Vi udfordrer dig
Den bedste måde at lære og forbedre dine kodningsfærdigheder er at øve sig. Hos PyBites styrkede vi dette koncept ved at organisere Python-kodeudfordringer. Tjek vores voksende kollektion, køb repoen, og få kodning!
Fortæl os, hvis du bygger noget sejt ved at lave en Pull Request af dit arbejde. Vi har set folk virkelig strække sig gennem disse udfordringer, og det gjorde vi også.
God kodning!