Denne artikel handler om T-SQL (Transact-SQL) vinduesfunktioner og deres grundlæggende brug i daglige dataanalyseopgaver.
Der er mange alternativer til T-SQL, når det kommer til dataanalyse. Men når forbedringer over tid og introduktion af vinduesfunktioner overvejes, er T-SQL i stand til at udføre dataanalyse på et grundlæggende niveau og i nogle tilfælde endda ud over det.
Om SQL-vinduefunktioner
Lad os først blive fortrolige med SQL Window-funktioner i forbindelse med Microsoft-dokumentationen.
Microsoft Definition
En vinduesfunktion beregner en værdi for hver række i vinduet.
Simpel definition
En vinduesfunktion hjælper os med at fokusere på en bestemt del (vindue) af resultatsættet, så vi kun kan udføre dataanalyse på den specifikke del (vindue) i stedet for på hele resultatsættet.
Med andre ord gør SQL-vinduefunktioner et resultatsæt til flere mindre sæt til dataanalyseformål.
Hvad er et resultatsæt
Kort sagt består et resultatsæt af alle poster, der er hentet ved at køre en SQL-forespørgsel.
For eksempel kan vi oprette en tabel med navnet Produkt og indsæt følgende data i den:
-- (1) Create the Product table CREATE TABLE [dbo].[Product] ( [ProductId] INT NOT NULL PRIMARY KEY, [Name] VARCHAR(40) NOT NULL, [Region] VARCHAR(40) NOT NULL ) -- (2) Populate the Product table INSERT INTO Product (ProductId,Name,Region) VALUES (1,'Laptop','UK'),(2,'PC','UAE'),(3,'iPad','UK')
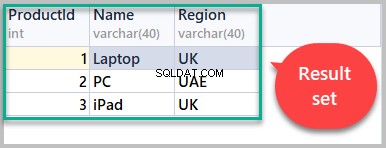
Nu vil resultatsættet hentet ved at bruge scriptet nedenfor indeholde alle rækker fra Produkt tabel:
-- (3) Result set SELECT [ProductId], [Name],[Region] FROM Product
Hvad er et vindue
Det er vigtigt først at forstå konceptet med et vindue, da det relaterer til SQL vinduesfunktioner. I denne sammenhæng er et vindue blot en måde at indsnævre dit omfang ved at målrette mod en bestemt del af resultatsættet (som vi allerede har nævnt ovenfor).
Du undrer dig måske nu - hvad betyder 'målretning mod en bestemt del af resultatsættet' egentlig?
For at vende tilbage til eksemplet, vi så på, kan vi oprette et SQL-vindue baseret på produktregionen ved at opdele resultatsættet i to vinduer.
Forstå Row_Number()
For at fortsætte skal vi bruge funktionen Row_Number() som midlertidigt giver et sekvensnummer til outputrækkerne.
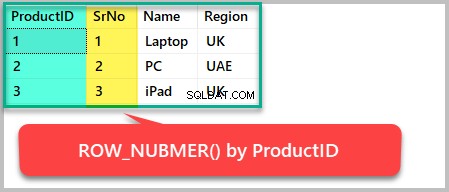
Hvis vi f.eks. ønsker at tilføje rækkenumre til resultatsættet baseret på ProduktID, vi skal bruge ROW_NUMBER() for at bestille det efter produkt-id som følger:
--Using the row_number() function to order the result set by ProductID SELECT ProductID,ROW_NUMBER() OVER (ORDER BY ProductID) AS SrNo,Name,Region FROM Product
Hvis vi nu vil have funktionen Row_Number() for at bestille resultatet sat efter ProduktID faldende, derefter rækkefølgen af outputrækker baseret på ProduktID ændres som følger:
--Using the row_number() function to order the result set by ProductID descending SELECT ProductID,ROW_NUMBER() OVER (ORDER BY ProductID DESC) AS SrNo,Name,Region FROM Product

Der er endnu ingen SQL-vinduer, da det eneste, vi har gjort, er at bestille sættet efter specifikke kriterier. Som diskuteret tidligere betyder vinduesinddeling at opdele resultatsættet i flere mindre sæt for at analysere hver enkelt af dem separat.
Oprettelse af et vindue med Row_Number()
For at oprette et SQL-vindue i vores resultatsæt, skal vi partitionere det baseret på en hvilken som helst af de kolonner, det indeholder.
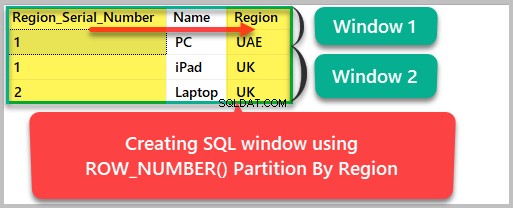
Vi kan nu opdele resultatet indstillet efter region som følger:
--Creating a SQL window based on Region SELECT ROW_NUMBER() OVER (Partition by region ORDER BY Region) as Region_Serial_Number , Name, Region FROM dbo.Product
Vælg – Over-klausul
Med andre ord, Vælg med Over klausul baner vejen for SQL-vinduefunktioner ved at partitionere et resultatsæt i mindre vinduer.
I henhold til Microsoft-dokumentationen, Vælg med Over klausul definerer et vindue, som derefter kan bruges af enhver vinduesfunktion.
Lad os nu oprette en tabel kaldet KøkkenProdukt som følger:
CREATE TABLE [dbo].[KitchenProduct]
(
[KitchenProductId] INT NOT NULL PRIMARY KEY IDENTITY(1,1),
[Name] VARCHAR(40) NOT NULL,
[Country] VARCHAR(40) NOT NULL,
[Quantity] INT NOT NULL,
[Price] DECIMAL(10,2) NOT NULL
);
GO
INSERT INTO dbo.KitchenProduct
(Name, Country, Quantity, Price)
VALUES
('Kettle','Germany',10,15.00)
,('Kettle','UK',20,12.00)
,('Toaster', 'France',10,10.00)
,('Toaster','UAE',10,12.00)
,('Kitchen Clock','UK',50,20.00)
,('Kitchen Clock','UAE',35,15.00) Lad os nu se tabellen:
SELECT [KitchenProductId], [Name], [Country], [Quantity], [Price] FROM dbo.KitchenProduct

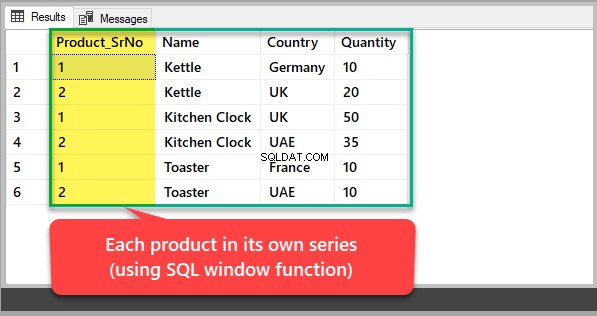
Hvis du ønsker at se hvert produkt med sit eget serienummer i stedet for et nummer baseret på det generaliserede produkt-id, skal du bruge en SQL-vinduefunktion til at opdele resultatet, der er sat af produktet som følger:
-- Viewing each product in its own series SELECT ROW_NUMBER() OVER (Partition by Name order by Name) Product_SrNo,Name,Country,Quantity FROM dbo.KitchenProduct
Kompatibilitet (Vælg – Overklausul)
Ifølge Microsofts dokumentation , Vælg – Over-klausul er kompatibel med følgende SQL-databaseversioner:
- SQL Server 2008 og nyere
- Azure SQL-database
- Azure SQL Data Warehouse
- Parallel Data Warehouse
Syntaks
VÆLG – OVER (Opdeling efter
Bemærk venligst, at jeg har forenklet syntaksen for at gøre i t let at forstå; se venligst den Microsoft-dokumentation for at se fuld syntaks.
Forudsætninger
Denne artikel er grundlæggende skrevet til begyndere, men der er stadig nogle forudsætninger, som skal huskes.
Kendskab til T-SQL
Denne artikel forudsætter, at læserne har et grundlæggende kendskab til T-SQL og er i stand til at skrive og køre grundlæggende SQL-scripts.
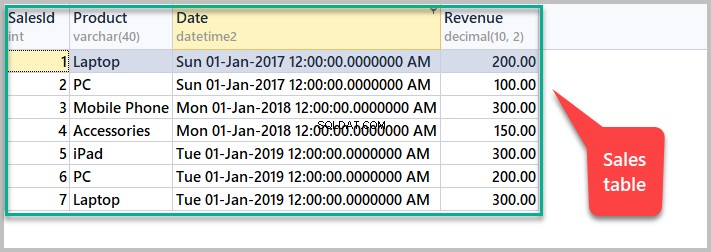
Opsæt salgseksempeltabellen
Denne artikel kræver følgende eksempeltabel, så vi kan køre vores SQL-vinduefunktionseksempler:
-- (1) Create the Sales sample table
CREATE TABLE [dbo].[Sales]
(
[SalesId] INT NOT NULL IDENTITY(1,1),
[Product] VARCHAR(40) NOT NULL,
[Date] DATETIME2,
[Revenue] DECIMAL(10,2),
CONSTRAINT [PK_Sales] PRIMARY KEY ([SalesId])
);
GO
-- (2) Populating the Sales sample table
SET IDENTITY_INSERT [dbo].[Sales] ON
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (1, N'Laptop', N'2017-01-01 00:00:00', CAST(200.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (2, N'PC', N'2017-01-01 00:00:00', CAST(100.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (3, N'Mobile Phone', N'2018-01-01 00:00:00', CAST(300.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (4, N'Accessories', N'2018-01-01 00:00:00', CAST(150.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (5, N'iPad', N'2019-01-01 00:00:00', CAST(300.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (6, N'PC', N'2019-01-01 00:00:00', CAST(200.00 AS Decimal(10, 2)))
INSERT INTO [dbo].[Sales] ([SalesId], [Product], [Date], [Revenue]) VALUES (7, N'Laptop', N'2019-01-01 00:00:00', CAST(300.00 AS Decimal(10, 2)))
SET IDENTITY_INSERT [dbo].[Sales] OFF Se alle salg ved at køre følgende script:
-- View sales SELECT [SalesId],[Product],[Date],[Revenue] FROM dbo.Sales
Grupper efter vs SQL vinduesfunktioner
Man kan undre sig – hvad er forskellen mellem at bruge Group By-klausulen og SQL-vinduefunktionerne?
Nå, svaret ligger i eksemplerne nedenfor.
Gruppér efter eksempel
For at se det samlede salg efter produkt, kan vi bruge Grupper efter som følger:
-- Total sales by product using Group By SELECT Product ,SUM(REVENUE) AS Total_Sales FROM dbo.Sales GROUP BY Product ORDER BY Product

Så Group By-klausulen hjælper os med at se det samlede salg. Den samlede salgsværdi er summen af omsætningen for alle lignende produkter i samme række uden brug af Group By-klausul. Hvad hvis vi er interesserede i at se omsætningen (salget) af hvert enkelt produkt sammen med det samlede salg?
Det er her, SQL-vinduefunktioner træder i kraft.
SQL-vinduefunktionseksempel
For at se produktet, omsætningen og den samlede omsætning for alle lignende produkter, skal vi opdele dataene på biproduktbasis ved hjælp af OVER() som følger:
-- Total sales by product using an SQL window function SELECT Product ,REVENUE ,SUM(REVENUE) OVER (PARTITION BY PRODUCT) AS Total_Sales FROM dbo.Sales
Outputtet skal være som følger:

Så vi kan nu nemt se salget for hvert enkelt produkt sammen med det samlede salg for det pågældende produkt. For eksempel omsætningen for PC er 100,00, men samlet salg (summen af omsætning for pc'en produkt) er 300,00, fordi to forskellige pc-modeller blev solgt.
Grundlæggende analyse med de samlede funktioner
Aggregerede funktioner returnerer en enkelt værdi efter at have udført beregninger på et sæt data.
I dette afsnit skal vi yderligere udforske SQL-vinduefunktioner – specifikt ved at bruge dem sammen med aggregerede funktioner til at udføre grundlæggende dataanalyse.
Almindelige aggregerede funktioner
De mest almindelige aggregerede funktioner er:
- Sum
- Tæl
- Min.
- Maks.
- Gns. (gennemsnit)
Aggregeret dataanalyse efter produkt
For at analysere resultatsættet på biproduktbasis ved hjælp af aggregerede funktioner, skal vi blot bruge en aggregeret funktion med en biproduktpartition inde i OVER()-sætningen:
-- Data analysis by product using aggregate functions SELECT Product,Revenue ,SUM(REVENUE) OVER (PARTITION BY PRODUCT) as Total_Sales ,MIN(REVENUE) OVER (PARTITION BY PRODUCT) as Minimum_Sales ,MAX(REVENUE) OVER (PARTITION BY PRODUCT) as Maximum_Sales ,AVG(REVENUE) OVER (PARTITION BY PRODUCT) as Average_Sales FROM dbo.Sales

Hvis du ser nærmere på pc'en eller bærbar produkter, du vil se, hvordan aggregerede funktioner arbejder sammen ved siden af SQL-vinduefunktionen.
I eksemplet ovenfor kan vi se, at omsætningsværdien for pc er 100,00 første gang og 200,00 næste gang, men Samlet salg udgør 300,00. Den lignende information kan ses for resten af de samlede funktioner.
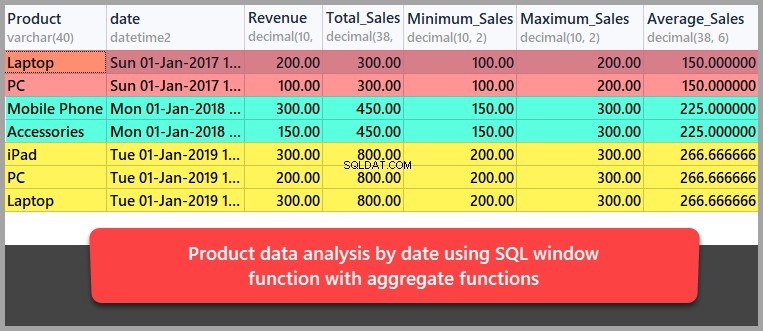
Samlet dataanalyse efter dato
Lad os nu udføre nogle dataanalyse af produkterne på en efter-dato-basis ved hjælp af SQL-vinduefunktioner i kombination med aggregerede funktioner.
Denne gang vil vi opdele resultatet indstillet efter dato i stedet for efter produkt som følger:
-- Data analysis by date using aggregate functions SELECT Product,date,Revenue ,SUM(REVENUE) OVER (PARTITION BY DATE) as Total_Sales ,MIN(REVENUE) OVER (PARTITION BY DATE) as Minimum_Sales ,MAX(REVENUE) OVER (PARTITION BY DATE) as Maximum_Sales ,AVG(REVENUE) OVER (PARTITION BY DATE) as Average_Sales FROM dbo.Sales
Med dette har vi lært grundlæggende dataanalyseteknikker ved at bruge tilgangen til SQL-vinduefunktioner.
Ting at gøre
Nu hvor du er fortrolig med SQL-vinduefunktioner, prøv venligst følgende:
- Med de eksempler, vi kiggede på, i tankerne, udfør grundlæggende dataanalyse ved hjælp af SQL-vinduefunktioner på prøvedatabasen nævnt i denne artikel.
- Tilføjelse af en kundekolonne til salgseksempeltabellen, og se, hvor rig din dataanalyse kan blive, når en anden kolonne (kunde) føjes til den.
- Tilføjelse af en regionskolonne til salgseksempeltabellen og udfør grundlæggende dataanalyse ved hjælp af aggregerede funktioner efter region.