I denne artikel vil vi se på, hvordan et indeks kan forbedre forespørgselsydeevnen.
Introduktion
Indekser i Oracle og andre databaser er objekter, der gemmer referencer til data i andre tabeller. De bruges til at forbedre forespørgselsydeevnen, oftest SELECT-sætningen.
De er ikke en "sølvkugle" - de løser ikke altid præstationsproblemer med SELECT-udsagn. Men de kan bestemt hjælpe.
Lad os overveje dette på et bestemt eksempel.
Eksempel
Til dette eksempel skal vi bruge en enkelt tabel kaldet Kunde, der indeholder kolonner som ID, Fornavn, Efternavn, maksimal kreditværdi, oprettet datoværdi og andre kolonner, som vi ikke vil bruge.
SELECT customer_id,first_name,last_name, max_credit, created_date FROM customer;
Her er et eksempel på bordet.
[tabel id=38 /]
Nu skal vi finde følgende:
- Hvem af kunderne blev tilføjet til tabellen på samme dato som de første kunder
- Klienter filtreret efter efternavn i stigende rækkefølge
- Vis kunde-id, fornavn, efternavn, maks. kredit og oprettelsesdato
For at gøre dette skal du oprette følgende forespørgsel:
SELECT customer_id,
first_name,
last_name,
max_credit,
created_date
FROM customer
WHERE created_date = (
SELECT MIN(created_date)
FROM customer
)
ORDER BY last_name; Outputtet ser sådan ud:
[tabel id=39 /]
Det viser de data, vi ønsker.
Ydeevne før indeks blev anvendt
Lad os nu se på forklaringsplanen for denne forespørgsel. Jeg fik dette ved at køre EXPLAIN PLAN FOR for SELECT-sætningen og følgende kommando:
SELECT * FROM TABLE(dbms_xplan.display);
Du kan også få et lignende outputresultat ved at bruge funktionen Explain Plan inde i din IDE.
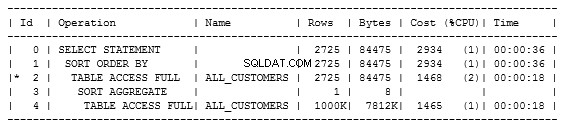
Vi kan se, at den udfører en Table Access Full på to punkter, nemlig i underforespørgslen og i den ydre forespørgsel. Dette skyldes, at der ikke er nogen indekser på bordet, der skal bruges.
Den har en pris på 2934. Da jeg kørte den, hentede forespørgslen 785 rækker på 1,9 sekunder. Det ser måske ud til at være hurtigt, men dette er blot et eksempel, som vi kan forbedre os på. Forespørgsler i rigtige systemer kan tage meget længere tid.
En måde, hvorpå vi kunne forbedre ydeevnen af denne forespørgsel, er at tilføje et indeks til kolonnen create_date. Denne kolonne bruges både i WHERE-sætningen af den ydre forespørgsel og i MIN-funktionen for den indre forespørgsel.
Tilføj indeks
Vi kan tilføje et indeks til denne tabel for at forbedre forespørgselsydeevnen. Dette indeks vil blive gemt i kolonnen create_date, så koden kan se sådan ud:
CREATE INDEX idx_cust_cdate ON customer (created_date);
Nu oprettes indekset kun i denne kolonne. Det burde give os en præstationsforbedring i vores forespørgsel, men vi bliver nødt til at tjekke det først.
Vi har oprettet et b-træ-indeks, som sandsynligvis er alt, hvad vi har brug for i denne kolonne. Vi bekræfter det i forklaringsplanen snart. Jeg har skrevet en guide om Oracle-indekser, herunder hvordan man ved, hvilken indekstype der skal bruges, samt en masse andre værdifulde oplysninger.
Ydeevne efter indeks tilføjet
Lad os køre forklaringsplanen igen på denne forespørgsel.
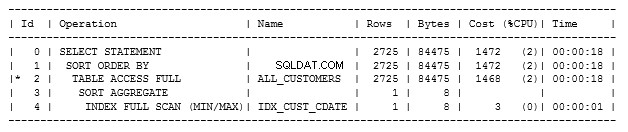
Vi kan se, at der er brugt et indeks på sidste trin. Det viser, at en fuld scanning er blevet udført med idx_cust_cdate-indekset, som er det, vi lige har oprettet.
Den viser også en samlet pris på 1472 og henter de 785 poster på 0,9 sekunder.
Kørselstiden er kun forbedret en smule (fra 1,9 til 0,9 sekunder), men det er omkring en forbedring på 50 % blot ved at tilføje indekset til dette lille datasæt.
Som tidligere nævnt vil rigtige forespørgsler være mere komplicerede end denne, og det vil tage længere tid at blive udført. Men dette er et eksempel på, hvordan et indeks kan forbedre forespørgselsplanen og forespørgselskørselstiden.