Strengdatatypen er en af de mest betydningsfulde datatyper i ethvert programmeringssprog. Du kan næsten ikke skrive et brugbart program uden det. Ikke desto mindre kender mange udviklere ikke visse aspekter af denne type. Lad os derfor overveje disse aspekter.
Repræsentation af strenge i hukommelsen
I .Net er strenge placeret i henhold til BSTR-reglen (Basic string or binary string). Denne metode til strengdatarepræsentation bruges i COM (ordet 'basic' stammer fra det Visual Basic-programmeringssprog, hvor det oprindeligt blev brugt). Som vi ved, bruges PWSZ (Pointer to Wide-character String, Zero-terminated) i C/C++ til repræsentation af strenge. Med en sådan placering i hukommelsen er en nulltermineret placeret i enden af en streng. Denne terminator gør det muligt at bestemme slutningen af strengen. Strenglængden i PWSZ er kun begrænset af en mængde ledig plads.
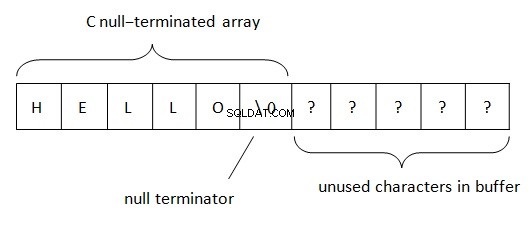
I BSTR er situationen lidt anderledes.
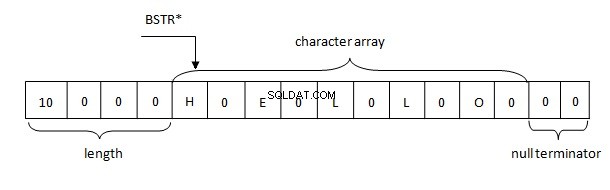
Grundlæggende aspekter af BSTR-strengrepræsentationen i hukommelsen er følgende:
- Længden af strengen er begrænset af et bestemt antal. I PWSZ er strenglængden begrænset af tilgængeligheden af ledig hukommelse.
- BSTR-strengen peger altid på det første tegn i bufferen. PWSZ kan pege på et hvilket som helst tegn i bufferen.
- I BSTR, i lighed med PWSZ, er nul-tegnet altid placeret i slutningen. I BSTR er nul-tegnet et gyldigt tegn og kan findes hvor som helst i strengen.
- Fordi nulterminatoren er placeret i slutningen, er BSTR kompatibel med PWSZ, men ikke omvendt.
Derfor er strenge i .NET repræsenteret i hukommelsen i henhold til BSTR-reglen. Bufferen indeholder en 4-byte strenglængde efterfulgt af to-byte tegn af en streng i UTF-16 formatet, som igen efterfølges af to null bytes (\u0000).
Brug af denne implementering har mange fordele:strenglængde må ikke genberegnes, da den er gemt i headeren, en streng kan indeholde null-tegn overalt. Og det vigtigste er, at adressen på en streng (fastgjort) nemt kan overføres til den oprindelige kode, hvor WCHAR* forventes.
Hvor meget hukommelse tager et strengobjekt?
Jeg stødte på artikler, der siger, at strengobjektets størrelse er lig med størrelse=20 + (længde/2)*4, men denne formel er ikke helt korrekt.
Til at begynde med er en streng en linktype, så de første fire bytes indeholder SyncBlockIndex og de næste fire bytes indeholder typemarkøren.
Strengstørrelse =4 + 4 + …
Som jeg sagde ovenfor, er strenglængden gemt i bufferen. Det er et int type felt, derfor skal vi tilføje yderligere 4 bytes.
Stringstørrelse =4 + 4 + 4 + …
For at sende en streng over til den oprindelige kode hurtigt (uden at kopiere), er nulterminatoren placeret i slutningen af hver streng, der tager 2 bytes. Derfor,
Strengstørrelse =4 + 4 + 4 + 2 + …
Det eneste tilbage er at huske, at hvert tegn i en streng er i UTF-16-kodningen og også tager 2 bytes. Derfor:
Stringstørrelse =4 + 4 + 4 + 2 + 2 * længde =14 + 2 * længde
En ting mere og vi er færdige. Hukommelsen tildelt af hukommelsesadministratoren i CLR er multiplum af 4 bytes (4, 8, 12, 16, 20, 24, …). Så hvis strenglængden tager 34 bytes i alt, vil der blive tildelt 36 bytes. Vi skal afrunde vores værdi til det nærmeste større tal, der er multiplum af fire. Til dette har vi brug for:
Strengstørrelse =4 * ((14 + 2 * længde + 3) / 4) (heltalsdivision)
Spørgsmålet om versioner :indtil .NET v4 var der en ekstra m_arrayLength felt af typen int i String-klassen, der tog 4 bytes. Dette felt er en reel længde af den buffer, der er allokeret til en streng, inklusive null-terminatoren, dvs. det er længde + 1. I .NET 4.0 blev dette felt slettet fra klassen. Som et resultat optager et objekt af strengtypen 4 bytes mindre.
Størrelsen af en tom streng uden m_arrayLength felt (dvs. i .Net 4.0 og højere) er lig med =4 + 4 + 4 + 2 =14 bytes, og med dette felt (dvs. lavere end .Net 4.0) er dets størrelse lig med =4 + 4 + 4 + 4 + 2 =18 bytes. Hvis vi runder 4 bytes, bliver størrelsen 16 og 20 bytes tilsvarende.
Strengaspekter
Så vi overvejede repræsentationen af strenge og størrelsen, de tager i hukommelsen. Lad os nu tale om deres ejendommeligheder.
Grundlæggende aspekter af strenge i .NET er følgende:
- Strenge er referencetyper.
- Strenge er uforanderlige. Når først den er oprettet, kan en streng ikke ændres (på rimelig måde). Hvert kald af metoden i denne klasse returnerer en ny streng, mens den forrige streng bliver et bytte for skraldeopsamleren.
- Strenge omdefinerer Object.Equals-metoden. Som et resultat sammenligner metoden tegnværdier i strenge, ikke linkværdier.
Lad os overveje hvert punkt i detaljer.
Strenge er referencetyper
Strenge er rigtige referencetyper. Det vil sige, at de altid er placeret i bunke. Mange af os forveksler dem med værdityper, da du opfører dig på samme måde. For eksempel er de uforanderlige, og deres sammenligning udføres efter værdi, ikke efter referencer, men vi skal huske på, at det er en referencetype.
Strenge er uforanderlige
- Strenge er uforanderlige til et formål. Strengens uforanderlighed har en række fordele:
- Stringtype er trådsikker, da ikke en enkelt tråd kan ændre indholdet af en streng.
- Brug af uforanderlige strenge fører til et fald i hukommelsesbelastning, da der ikke er behov for at gemme 2 forekomster af den samme streng. Som et resultat bliver der brugt mindre hukommelse, og sammenligning udføres hurtigere, da kun referencer sammenlignes. I .NET kaldes denne mekanisme string interning (string pool). Vi vil tale om det lidt senere.
- Når vi sender en uforanderlig parameter til en metode, kan vi stoppe med at bekymre os om, at den vil blive ændret (hvis den ikke blev videregivet som ref eller ud, selvfølgelig).
Datastrukturer kan opdeles i to typer:flygtige og vedvarende. Flygtige datastrukturer gemmer kun deres seneste versioner. Vedvarende datastrukturer gemmer alle deres tidligere versioner under ændring. Sidstnævnte er faktisk uforanderlige, da deres operationer ikke ændrer strukturen på stedet. I stedet returnerer de en ny struktur, der er baseret på den tidligere.
I betragtning af det faktum, at strenge er uforanderlige, kan de være vedvarende, men det er de ikke. Strenge er flygtige i .Net.
Til sammenligning, lad os tage Java-strenge. De er uforanderlige, ligesom i .NET, men derudover er de vedvarende. Implementeringen af String-klassen i Java ser ud som følger:
public final class String
{
private final char value[];
private final int offset;
private final int count;
private int hash;
.....
}
Ud over 8 bytes i objektets header, inklusive en reference til typen og en reference til et synkroniseringsobjekt, indeholder strenge følgende felter:
- En reference til et char-array;
- Et indeks over det første tegn i strengen i char-arrayet (forskudt fra begyndelsen)
- Antallet af tegn i strengen;
- Hashkoden beregnet efter første opkald til HashCode() metode.
Strenge i Java tager mere hukommelse end i .NET, da de indeholder yderligere felter, der tillader dem at være vedvarende. På grund af persistens, udførelsen af String.substring() metode i Java tager O(1) , da det ikke kræver strengkopiering som i .NET, hvor udførelse af denne metode tager O(n) .
Implementering af String.substring()-metoden i Java:
public String substring(int beginIndex, int endIndex)
{
if (beginIndex < 0) throw new StringIndexOutOfBoundsException(beginIndex); if (endIndex > count)
throw new StringIndexOutOfBoundsException(endIndex);
if (beginIndex > endIndex)
throw new StringIndexOutOfBoundsException(endIndex - beginIndex);
return ((beginIndex == 0) && (endIndex == count)) ? this : new String(offset + beginIndex, endIndex - beginIndex, value);
}
public String(int offset, int count, char value[])
{
this.value = value;
this.offset = offset;
this.count = count;
} Men hvis en kildestreng er stor nok, og den udskårne understreng er på flere tegn lang, vil hele rækken af tegn i den indledende streng være afventende i hukommelsen, indtil der er en reference til understrengen. Eller hvis du serialiserer den modtagne understreng med standardmidler og sender den over netværket, vil hele det originale array blive serialiseret, og antallet af bytes, der sendes over netværket, vil være stort. Derfor i stedet for koden
s =ss.substring(3)
følgende kode kan bruges:
s =new String(ss.substring(3)),
Denne kode gemmer ikke referencen til rækken af tegn i kildestrengen. I stedet vil den kun kopiere den faktisk brugte del af arrayet. Hvis vi kalder denne konstruktør på en streng, hvis længde er lig med længden af rækken af tegn, vil kopiering ikke finde sted. I stedet vil referencen til det originale array blive brugt.
Som det viste sig, er implementeringen af strengtypen blevet ændret i den sidste version af Java. Nu er der ingen offset- og længdefelter i klassen. Den nye hash32 (med anden hashing-algoritme) er blevet introduceret i stedet. Det betyder, at strenge ikke længere er vedvarende. Nu, String.substring metoden vil oprette en ny streng hver gang.
Streng omdefinerer Onbject.Equals
Strengeklassen omdefinerer Object.Equals-metoden. Som et resultat finder sammenligning sted, men ikke ved reference, men efter værdi. Jeg formoder, at udviklere er taknemmelige over for skabere af String-klassen for at omdefinere ==-operatoren, da kode, der bruger ==til strengsammenligning, ser mere dybtgående ud end metodekaldet.
if (s1 == s2)
Sammenlignet med
if (s1.Equals(s2))
Forresten, i Java sammenligner ==operatoren ved reference. Hvis du skal sammenligne strenge efter tegn, skal vi bruge string.equals() metoden.
Strenginternering
Lad os endelig overveje strenginternering. Lad os tage et kig på et simpelt eksempel – en kode, der vender en streng om.
var s = "Strings are immutuble";
int length = s.Length;
for (int i = 0; i < length / 2; i++)
{
var c = s[i];
s[i] = s[length - i - 1];
s[length - i - 1] = c;
} Denne kode kan naturligvis ikke kompileres. Compileren vil kaste fejl for disse strenge, da vi forsøger at ændre indholdet af strengen. Enhver metode i String-klassen returnerer en ny forekomst af strengen i stedet for dens indholdsændring.
Strengen kan ændres, men vi bliver nødt til at bruge den usikre kode. Lad os overveje følgende eksempel:
var s = "Strings are immutable";
int length = s.Length;
unsafe
{
fixed (char* c = s)
{
for (int i = 0; i < length / 2; i++)
{
var temp = c[i];
c[i] = c[length - i - 1];
c[length - i - 1] = temp;
}
}
} Efter udførelse af denne kode, elbatummi era sgnirtS vil blive skrevet ind i strengen, som forventet. Foranderlighed af strenge fører til en fancy sag relateret til strenginternering.
Strenginternering er en mekanisme, hvor lignende bogstaver er repræsenteret i hukommelsen som et enkelt objekt.
Kort sagt er pointen med strenginternering følgende:der er en enkelt hashed intern tabel i en proces (ikke inden for et applikationsdomæne), hvor strenge er dens nøgler, og værdier er referencer til dem. Under JIT-kompilering placeres bogstavelige strenge i en tabel sekventielt (hver streng i en tabel kan kun findes én gang). Under udførelsen tildeles referencer til bogstavelige strenge fra denne tabel. Under udførelsen kan vi placere en streng i den interne tabel med String.Intern metode. Vi kan også kontrollere tilgængeligheden af en streng i intern tabel ved hjælp af String.IsInterned metode.
var s1 = "habrahabr"; var s2 = "habrahabr"; var s3 = "habra" + "habr"; Console.WriteLine(object.ReferenceEquals(s1, s2));//true Console.WriteLine(object.ReferenceEquals(s1, s3));//true
Bemærk, at kun strengliteraler er interneret som standard. Da den hashed interne tabel bruges til intern implementering, udføres søgningen mod denne tabel under JIT kompilering. Denne proces tager noget tid. Så hvis alle strenge er interneret, vil det reducere optimering til nul. Under kompilering til IL-kode sammenkæder compileren alle bogstavelige strenge, da der ikke er behov for at gemme dem i dele. Derfor returnerer den anden lighed sand .
Lad os nu vende tilbage til vores sag. Overvej følgende kode:
var s = "Strings are immutable";
int length = s.Length;
unsafe
{
fixed (char* c = s)
{
for (int i = 0; i < length / 2; i++)
{
var temp = c[i];
c[i] = c[length - i - 1];
c[length - i - 1] = temp;
}
}
}
Console.WriteLine("Strings are immutable"); Det ser ud til, at alt er ret indlysende, og koden skulle returnere Strenge er uforanderlige . Det gør det dog ikke! Koden returnererelbatummi era sgnirtS . Det sker netop på grund af praktik. Når vi ændrer strenge, ændrer vi dens indhold, og da det er bogstaveligt, internt og repræsenteret af en enkelt forekomst af strengen.
Vi kan opgive strenginternering, hvis vi anvender CompilationRelaxationsAttribute attribut til forsamlingen. Denne attribut styrer nøjagtigheden af koden, der er oprettet af JIT-kompileren i CLR-miljøet. Konstruktøren af denne attribut accepterer CompilationRelaxations enumeration, som i øjeblikket kun omfatter CompilationRelaxations.NoStringInterning . Som et resultat er samlingen markeret som den, der ikke kræver internering.
I øvrigt behandles denne attribut ikke i .NET Framework v1.0. Derfor var det umuligt at deaktivere internering. Fra version 2 er mscorlib assembly er markeret med denne attribut. Så det viser sig, at strenge i .NET kan modificeres med den usikre kode.
Hvad hvis vi glemmer usikre?
Som det sker, kan vi ændre strengindhold uden den usikre kode. I stedet kan vi bruge refleksionsmekanismen. Dette trick var vellykket i .NET indtil version 2.0. Bagefter fratog udviklere af String-klassen os denne mulighed. I .NET 2.0 har String-klassen to interne metoder:SetChar til grænsekontrol og InternalSetCharNoBoundsCheck det gør ikke grænsekontrol. Disse metoder indstiller det angivne tegn med et bestemt indeks. Implementeringen af metoderne ser ud på følgende måde:
internal unsafe void SetChar(int index, char value)
{
if ((uint)index >= (uint)this.Length)
throw new ArgumentOutOfRangeException("index", Environment.GetResourceString("ArgumentOutOfRange_Index"));
fixed (char* chPtr = &this.m_firstChar)
chPtr[index] = value;
}
internal unsafe void InternalSetCharNoBoundsCheck (int index, char value)
{
fixed (char* chPtr = &this.m_firstChar)
chPtr[index] = value;
} Derfor kan vi ændre strengindholdet uden usikker kode ved hjælp af følgende kode:
var s = "Strings are immutable";
int length = s.Length;
var method = typeof(string).GetMethod("InternalSetCharNoBoundsCheck", BindingFlags.Instance | BindingFlags.NonPublic);
for (int i = 0; i < length / 2; i++)
{
var temp = s[i];
method.Invoke(s, new object[] { i, s[length - i - 1] });
method.Invoke(s, new object[] { length - i - 1, temp });
}
Console.WriteLine("Strings are immutable");
Som forventet returnerer koden elbatummi era sgnirtS .
Spørgsmålet om versioner :i forskellige versioner af .NET Framework kan string.Empty integreres eller ej. Lad os overveje følgende kode:
string str1 = String.Empty;
StringBuilder sb = new StringBuilder().Append(String.Empty);
string str2 = String.Intern(sb.ToString());
if (object.ReferenceEquals(str1, str2))
Console.WriteLine("Equal");
else
Console.WriteLine("Not Equal"); I .NET Framework 1.0, .NET Framework 1.1 og .NET Framework 3.5 med 1 (SP1) service pack, str1 og str2 er ikke lige. I øjeblikket er string.Empty er ikke interneret.
Aspekter af ydeevne
Der er én negativ bivirkning ved internering. Sagen er, at referencen til et String-internet objekt, der er gemt af CLR, kan gemmes selv efter slutningen af applikationsarbejdet og endda efter slutningen af applikationsdomænearbejdet. Derfor er det bedre at undlade at bruge store bogstavelige strenge. Hvis det stadig er påkrævet, skal internering deaktiveres ved at anvende CompilationRelaxations attribut til samling.