For at drive enhver database effektivt, skal du have indsigt i databasens ydeevne. Dette er måske ikke indlysende, når alt går godt, men så snart noget går galt, kan adgang til information være medvirkende til hurtigt og korrekt at diagnosticere problemet.
Alle databaser gør nogle af deres interne statusdata tilgængelige for brugerne. I MySQL kan du for det meste få disse data ved at køre 'VIS STATUS' og 'VIS GLOBAL STATUS', ved at udføre 'SHOW ENGINE INNODB STATUS', kontrollere informationsskematabeller og, i nyere versioner, ved at forespørge performance_schema-tabeller.

Disse metoder er langt fra praktiske i den daglige drift, derfor er de forskellige overvågnings- og trendløsningers popularitet. Værktøjer som Nagios/Icinga er designet til at se værter/tjenester og advare, når en tjeneste falder uden for et acceptabelt område. Andre værktøjer såsom Cacti og Munin giver et grafisk blik på værts-/tjenesteinformationer og giver historisk kontekst til ydeevne og brug. ClusterControl kombinerer disse to typer overvågning, så vi vil se på den information, den præsenterer, og hvordan vi skal fortolke den.
Hvis du bruger Galera Cluster (MySQL Galera Cluster by Codership eller MariaDB Cluster eller Percona XtraDB Cluster), har du muligvis bemærket følgende afsnit i ClusterControls fane "Overview":
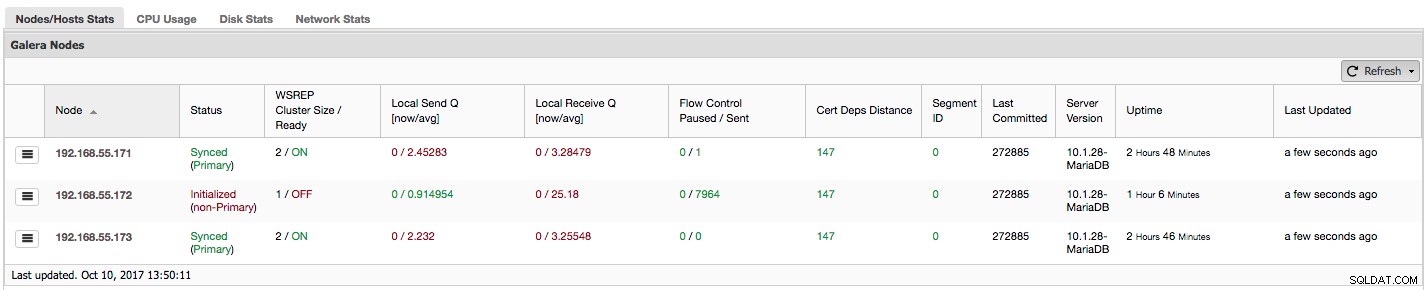
Lad os se, trin for trin, hvilken slags data vi har her.
Den første kolonne indeholder listen over noder med deres IP-adresser - der er ikke meget andet at sige om det.
Anden kolonne er mere interessant - den beskriver nodestatus (wsrep_local_state_comment status). En node kan være i forskellige tilstande:
- Initialiseret – Noden er oppe at køre, men den er ikke en del af en klynge. Det kan for eksempel være forårsaget af netværksproblemer;
- Deltagelse - Noden er i gang med at tilslutte sig klyngen, og den enten modtager eller anmoder om en tilstandsoverførsel fra en af de andre noder;
- Donor/Desynkroniseret - Noden fungerer som donor til en anden node, som slutter sig til klyngen;
- Tilsluttet - Noden er sluttet til klyngen, men har travlt med at indhente forpligtede skrivesæt;
- Synkroniseret - Noden fungerer normalt.
I samme kolonne inden for parentes er klyngestatussen (wsrep_cluster_status status). Det kan have tre forskellige tilstande:
- Primær - Kommunikationen mellem noder fungerer, og kvorum er til stede (flertallet af noder er tilgængelige)
- Ikke-primær - Noden var en del af klyngen, men af en eller anden grund mistede den kontakten med resten af klyngen. Som følge heraf betragtes denne node som inaktiv, og den accepterer ikke forespørgsler
- Afbrudt - Noden kunne ikke etablere gruppekommunikation.
"WSREP Cluster Size / Ready" fortæller os om en klyngestørrelse, som noden ser den, og om noden er klar til at acceptere forespørgsler. Ikke-primære komponenter opretter en klynge med størrelsen 1, og wsrep-beredskab er FRA.
Lad os tage et kig på skærmbilledet ovenfor og se, hvad det fortæller os om Galera. Vi kan se tre noder. To af dem (192.168.55.171 og 192.168.55.173) er helt i orden, de er begge "Synced", og klyngen er i "Primær" tilstand. Klyngen består i øjeblikket af to noder. Node 192.168.55.172 er "initialiseret", og den danner "ikke-primær" komponent. Det betyder, at denne node mistede forbindelsen til klyngen - højst sandsynligt en form for netværksproblemer (faktisk brugte vi iptables til at blokere en trafik til denne node fra både 192.168.55.171 og 192.168.55.173).
I dette øjeblik må vi stoppe lidt op og beskrive, hvordan Galera Cluster fungerer internt. Vi vil ikke gå i for mange detaljer, da det ikke er inden for rammerne af dette blogindlæg, men der kræves en vis viden for at forstå vigtigheden af de data, der præsenteres i næste kolonner.
Galera er en "stort set" synkron multi-master klynge. Det betyder, at du skal forvente, at data overføres på tværs af noder "stort set" på samme tid (ikke flere irriterende problemer med haltende slaver), og at du kan skrive til enhver node i en klynge (ikke flere irriterende problemer med at fremme en slave til master ). For at opnå det bruger Galera skrivesæt - atomære sæt ændringer, der replikeres på tværs af klyngen. Et skrivesæt kan indeholde flere rækkeændringer og yderligere nødvendige informationer som f.eks. data vedrørende låsning.
Når en klient udsteder COMMIT, men før MySQL rent faktisk begår noget, oprettes et skrivesæt og sendes til alle noder i klyngen for certificering. Alle noder tjekker, om det er muligt at foretage ændringerne eller ej (da ændringer kan forstyrre andre skrivninger, der udføres i mellemtiden direkte på en anden node). Hvis ja, er data faktisk begået af MySQL, hvis ikke, udføres rollback.
Det, der er vigtigt at huske, er det faktum, at noder, der ligner slaver i almindelig replikering, kan fungere anderledes - nogle kan have bedre hardware end andre, nogle kan være mere belastede end andre. Alligevel kræver Galera, at de behandler skrivesættene på en kort og hurtig måde for at opretholde "virtuel" synkronisering. Der skal være en mekanisme, som kan bremse replikationen og tillade langsommere noder at følge med resten af klyngen.
Lad os tage et kig på kolonnerne "Lokal Send Q [nu/avg]" og "Lokal Modtag Q [nu/avg]". Hver node har en lokal kø til afsendelse og modtagelse af skrivesæt. Det giver mulighed for at parallelisere nogle af skrive- og kødataene, som ikke kunne behandles på én gang, hvis noden ikke kan følge med trafikken. I VIS GLOBAL STATUS kan vi finde otte tællere, der beskriver begge køer, fire tællere pr. kø:
- wsrep_local_send_queue - aktuelle tilstand af sendekøen
- wsrep_local_send_queue_min - minimum siden FLUSH STATUS
- wsrep_local_send_queue_max - maksimum siden FLUSH STATUS
- wsrep_local_send_queue_avg - gennemsnit siden FLUSH STATUS
- wsrep_local_recv_queue - nuværende tilstand for modtagekøen
- wsrep_local_recv_queue_min - minimum siden FLUSH STATUS
- wsrep_local_recv_queue_max - maksimum siden FLUSH STATUS
- wsrep_local_recv_queue_avg - gennemsnit siden FLUSH STATUS
Ovenstående metrics er samlet på tværs af noder under ClusterControl -> Ydelse -> DB Status:
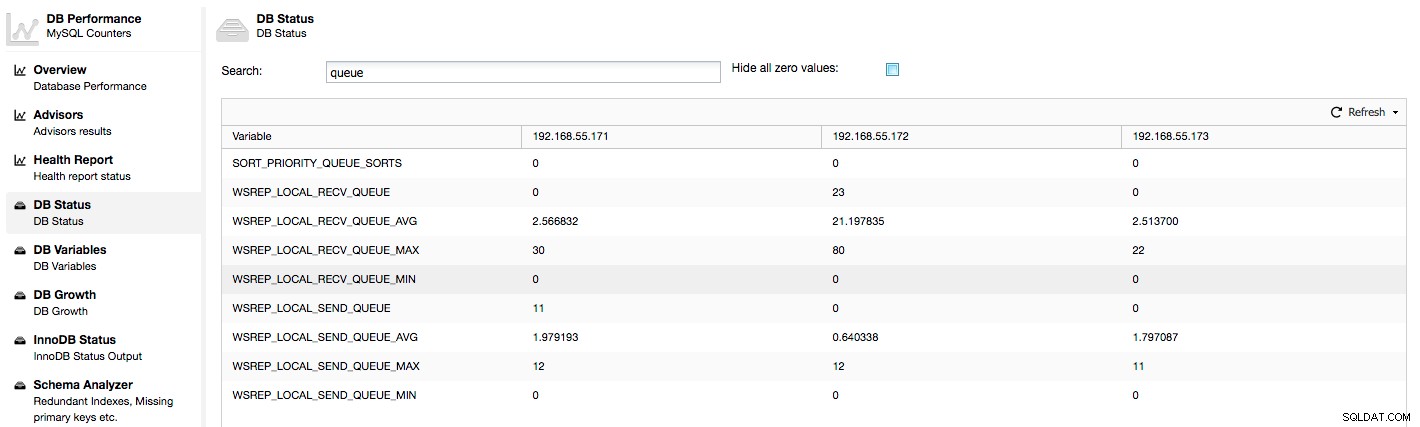
ClusterControl viser "nu" og "gennemsnitlige" tællere, da de er de mest meningsfulde som et enkelt tal (du kan også oprette brugerdefinerede grafer baseret på variabler, der beskriver den aktuelle tilstand af køerne). Når vi ser, at en af køerne stiger, betyder det, at noden ikke kan følge med replikationen, og andre noder bliver nødt til at sænke farten for at lade den indhente. Vi vil anbefale at undersøge en arbejdsbyrde for den givne node - tjek proceslisten for nogle langvarige forespørgsler, tjek OS-statistikker som CPU-udnyttelse og I/O-arbejdsbelastning. Måske er det også muligt at omfordele noget af trafikken fra den node til resten af klyngen.
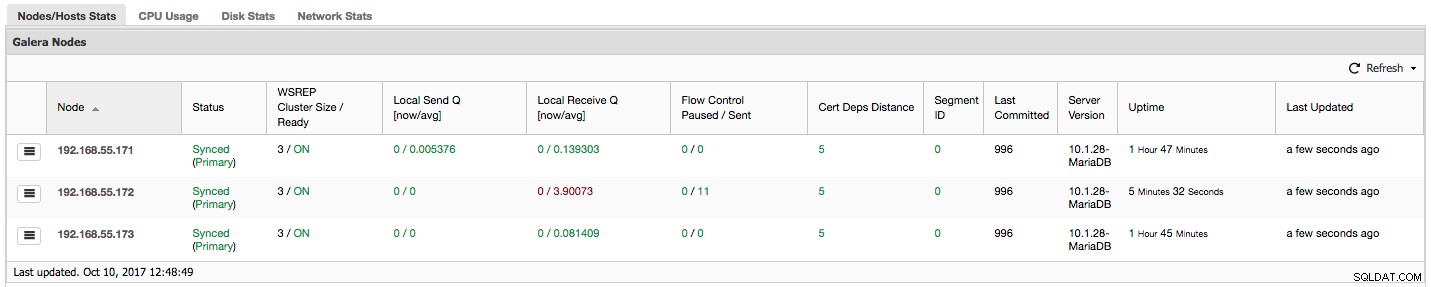
"Flowkontrol sat på pause" viser information om den procentdel af tid, en given node måtte sætte sin replikering på pause på grund af for stor belastning. Når en node ikke kan følge med arbejdsbyrden, sender den Flow Control-pakker til andre noder, og informerer dem om, at de skal skrue ned for at sende skrivesæt. I vores skærmbillede har vi værdien '0.30' for node 192.168.55.172. Dette betyder, at næsten 30 % af tiden var denne node nødt til at sætte replikeringen på pause, fordi den ikke var i stand til at holde trit med skrivesæt-certificeringshastigheden, der kræves af andre noder (eller enklere, for mange skrivninger ramte den!). Som vi kan se, peger det "Local Receive Q [avg]" os også på dette faktum.
Næste kolonne, "Flow Control Sendt" giver os information om, hvor mange Flow Control-pakker en given node sendte til klyngen. Igen ser vi, at det er node 192.168.55.172, som bremser klyngen.
Hvad kan vi gøre med disse oplysninger? For det meste bør vi undersøge, hvad der foregår i den langsomme knude. Tjek CPU-udnyttelse, kontroller I/O-ydeevne og netværksstatistik. Dette første trin hjælper med at vurdere, hvilken slags problem vi står over for.
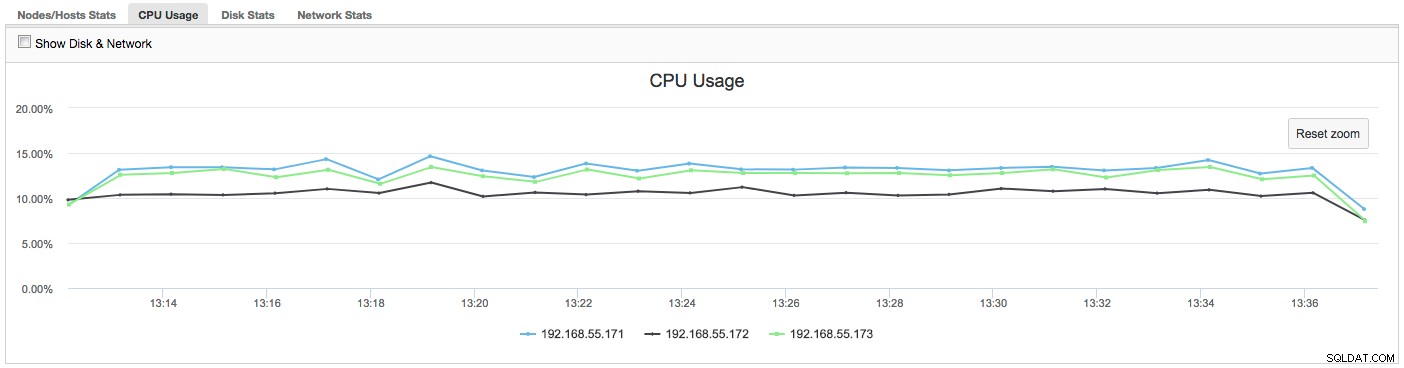
I dette tilfælde, når vi skifter til CPU Usage-fanen, bliver det klart, at omfattende CPU-udnyttelse forårsager vores problemer. Næste trin ville være at identificere den skyldige ved at se på PROCESSLISTE (Query Monitor -> Running Queries -> filtrer efter 192.168.55.172) for at tjekke for stødende forespørgsler:
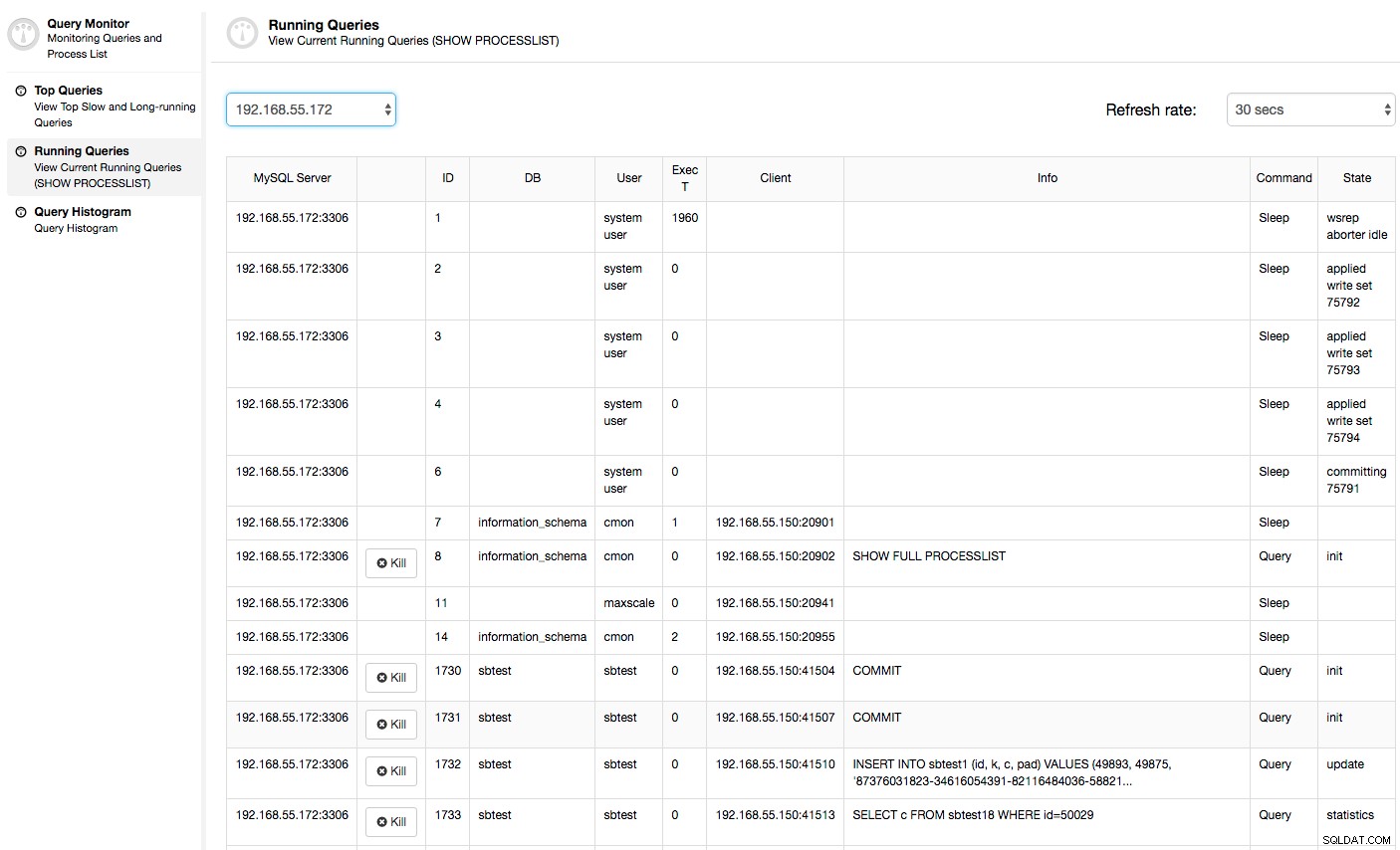
Eller tjek processer på noden fra operativsystemets side (Nodes -> 192.168.55.172 -> Top) for at se, om belastningen ikke er forårsaget af noget uden for Galera/MySQL.
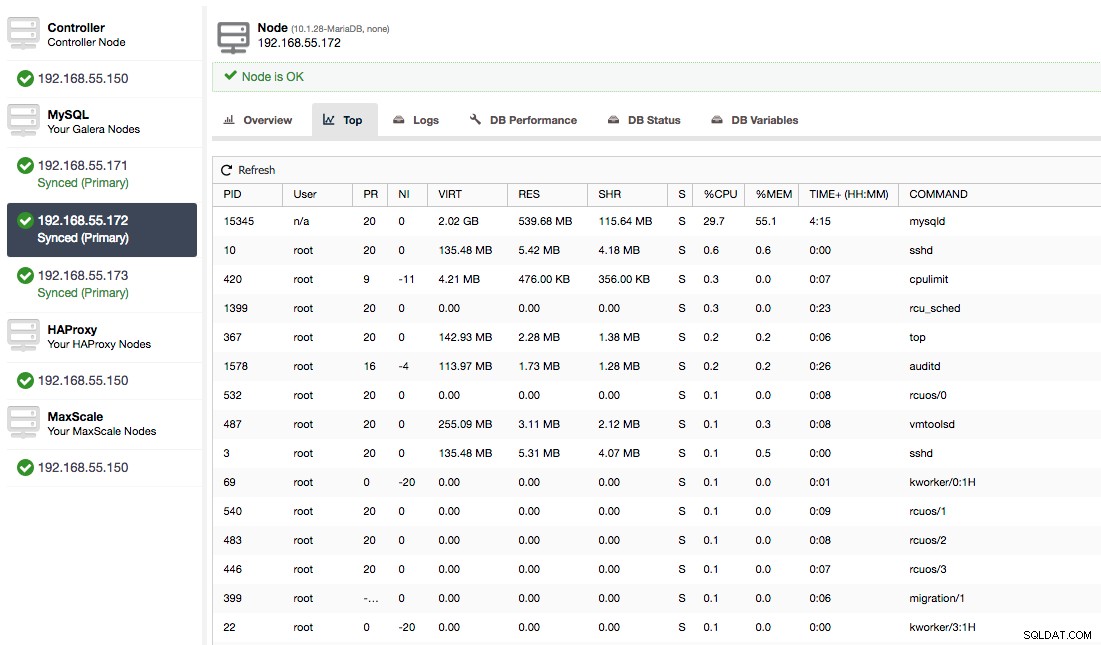
I dette tilfælde har vi udført mysqld-kommandoen gennem cpulimit for at simulere langsom CPU-brug specifikt til mysqld-processen ved at begrænse den til 30 % ud af 400 % tilgængelig CPU (serveren har 4 kerner).
Kolonnen "Cert Deps Distance" giver os information om, hvor mange skrivesæt der i gennemsnit kan anvendes parallelt. Skrivesæt kan nogle gange udføres på samme tid - Galera udnytter dette ved at bruge flere wsrep_slave_threads at anvende skrivesæt. Denne kolonne giver dig en idé om, hvor mange slavetråde du kan bruge på din arbejdsbyrde. Det er værd at bemærke, at det ikke nytter noget at konfigurere wsrep_slave_threads variabel til værdier højere end du ser i denne kolonne eller i wsrep_cert_deps_distance statusvariabel, som kolonnen "Cert Deps Distance" er baseret på. En anden vigtig bemærkning - det nytter heller ikke noget at indstille wsrep_slave_threads variabel til mere end antallet af kerner, din CPU har.
"Segment ID" - denne kolonne kræver lidt mere forklaring. Segmenter er en ny funktion tilføjet i Galera 3.0. Før denne version blev skrivesæt udvekslet mellem alle noder. Lad os sige, at vi har to datacentre:
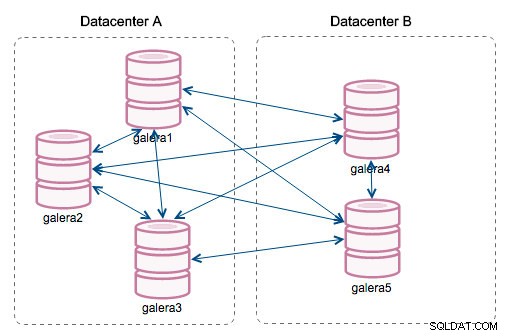
Denne form for chatter fungerer ok på lokale netværk, men WAN er en anden historie - certificeringen bliver langsommere på grund af øget latenstid, yderligere omkostninger genereres på grund af netværksbåndbredde, der bruges til at overføre skrivesæt mellem hvert medlem af klyngen.
Med introduktionen af "Segmenter" ændrede tingene sig. Du kan tildele en node til et segment ved at ændre wsrep_provider_options variabel og tilføje "gmcast.segment=x" (0, 1, 2) til den. Noder med samme segmentnummer behandles, som de er i det samme datacenter, forbundet med lokalt netværk. Vores graf bliver så anderledes:
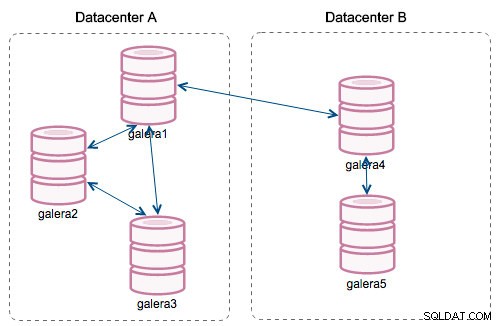
Den største forskel er, at det ikke længere er alle for alle-kommunikation. Inden for hvert segment, ja - det er stadig den samme mekanisme, men begge segmenter kommunikerer kun gennem en enkelt forbindelse mellem to valgte noder. I tilfælde af nedetid vil denne forbindelse automatisk failover. Som et resultat får vi mindre netværkssnak og mindre båndbreddeforbrug mellem fjerndatacentre. Så dybest set fortæller kolonnen "Segment ID" os, hvilket segment en node er tildelt.
Kolonnen "Last Committed" giver os information om sekvensnummeret for det skrivesæt, der sidst blev udført på en given node. Det kan være nyttigt til at bestemme, hvilken node der er den mest aktuelle, hvis der er behov for at bootstrap klyngen.
Resten af kolonnerne er selvforklarende:Serverversion, oppetid for en node og hvornår status blev opdateret.
Som du kan se, giver sektionen "Galera Nodes" i "Nodes/Hosts Stats" i fanen "Overview" dig en ret god forståelse af klyngens helbred - om det danner en "Primær" komponent, hvor mange noder der er sunde , er der nogen ydeevneproblemer med nogle noder, og hvis ja, hvilken node bremser klyngen.
Dette sæt data er meget praktisk, når du betjener din Galera-klynge, så forhåbentlig ikke mere at flyve blindt :-)