Parsing af data fra XML ved hjælp af XQuery er en rutinemæssig praksis. For at gøre dette mest effektivt kræves der kun en lille indsats.
Antag, at vi skal parse data fra diskfilen med følgende struktur:
<tables> <table name="Accounting" schema="Production" object="Accounting"> <column name="Date" order="3" visible="1" /> <column name="DateFrom" order="5" visible="1" /> <column name="DateTo" order="6" visible="1" /> <column name="Description" order="4" visible="1" /> <column name="DocumentUID" order="1" visible="0" /> <column name="Number" order="2" visible="1" /> <column name="Warehouse" order="7" visible="1" /> </table> </tables>
Brug BULK INSERT, hvis du har brug for at læse data fra en fil:
SELECT BulkColumn FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x sample xml file
En eksempel-xml-fil er her.
Men husk en bestemt ting... Prøv ikke at læse dataene direkte:
;WITH cte AS
(
SELECT x = CAST(BulkColumn AS XML)
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
)
SELECT t.c.value('@name', 'VARCHAR(100)')
FROM cte
CROSS APPLY x.nodes('tables/table') t(c) Tildel data til en variabel. På denne måde kan du få en mere effektiv eksekveringsplan:
DECLARE @xml XML
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
SELECT t.c.value('@name', 'VARCHAR(100)')
FROM @xml.nodes('tables/table') t(c) Sammenlign resultaterne:
Table 'Worktable'. Scan count 0, logical reads 729, physical reads 0, read-ahead reads 0, lob logical reads 62655,... SQL Server Execution Times: CPU time = 1203 ms, elapsed time = 1214 ms. Table 'Worktable'. Scan count 0, logical reads 7, physical reads 0, read-ahead reads 0, lob logical reads 202,.... SQL Server Execution Times: CPU time = 16 ms, elapsed time = 4 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 3 ms.
Som du kan se, er den anden mulighed væsentligt hurtigere.
En anden vigtig egenskab ved SQL Server, når du arbejder med XQuery, er, at læsning af et overordnet element kan resultere i dårlig ydeevne. Overvej følgende eksempel:
SET STATISTICS PROFILE OFF
DECLARE @xml XML
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
SET STATISTICS PROFILE ON
SELECT
t.c.value('@name', 'SYSNAME')
, t.c.value('@order', 'INT')
, t.c.value('@visible', 'BIT')
, t.c.value('../@name', 'SYSNAME')
, t.c.value('../@schema', 'SYSNAME')
, t.c.value('../@object', 'SYSNAME')
FROM @xml.nodes('tables/table/*') t(c) Lad os se på det faktiske antal rækker modtaget fra operatøren. Værdien er unormalt stor:
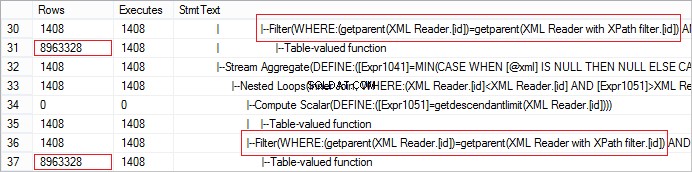
Anmodningen kan nemt optimeres ved at bruge CROSS APPLY:
SELECT
t2.c2.value('@name', 'SYSNAME')
, t2.c2.value('@order', 'INT')
, t2.c2.value('@visible', 'BIT')
, t.c.value('@name', 'SYSNAME')
, t.c.value('@schema', 'SYSNAME')
, t.c.value('@object', 'SYSNAME')
FROM @xml.nodes('tables/table') t(c)
CROSS APPLY t.c.nodes('column') t2(c2) Lad os sammenligne udførelsestiden:
(1408 row(s) affected) SQL Server Execution Times: CPU time = 10125 ms, elapsed time = 10135 ms. (1408 row(s) affected) SQL Server Execution Times: CPU time = 78 ms, elapsed time = 156 ms.
Som du kan se fra eksemplet, virker anmodningen med CROSS APPLY øjeblikkeligt.
Tak for din opmærksomhed. Jeg håber, at denne artikel var nyttig. Du er velkommen til at stille spørgsmål, efterlade dine kommentarer og forslag vedrørende denne artikel.