Så snart du begynder at køre en databaseserver og dit forbrug vokser, er du udsat for mange typer tekniske problemer, ydeevneforringelse og databasefejl. Hver af disse kan føre til meget større problemer, såsom katastrofale fejl eller tab af data. Det er som en kædereaktion, hvor én ting kan føre til en anden, hvilket forårsager flere og flere problemer. Der skal udføres proaktive modforanstaltninger, for at du kan have et stabilt miljø længst muligt.
I dette blogindlæg skal vi se på en masse fede funktioner, der tilbydes af ClusterControl, som i høj grad kan hjælpe os med at fejlfinde og rette vores MySQL-databaseproblemer, når de opstår.
Databasealarmer og -meddelelser
For alle uønskede hændelser vil ClusterControl logge alt under Alarmer, som er tilgængeligt på aktiviteten (topmenuen) på ClusterControl-siden. Dette er almindeligvis det første skridt til at starte fejlfinding, når noget går galt. Fra denne side kan vi få en idé om, hvad der rent faktisk foregår med vores databaseklynge:
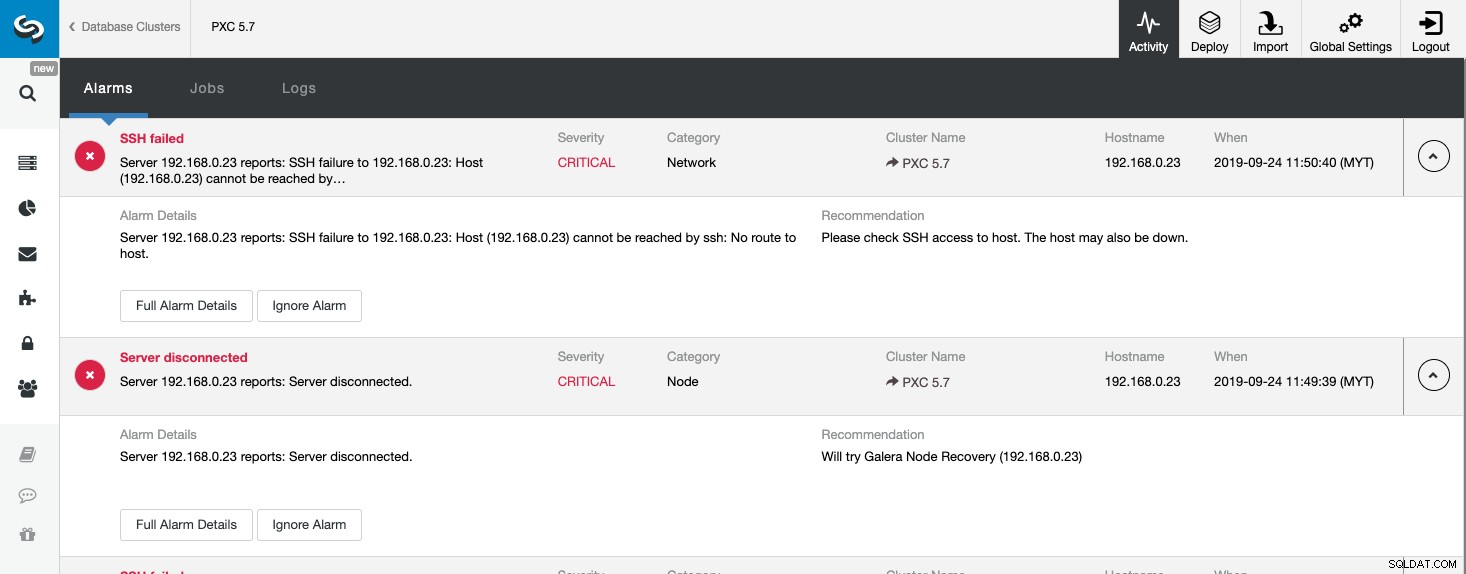
Ovenstående skærmbillede viser et eksempel på en server, der ikke kan nås, med sværhedsgrad KRITISK , detekteret af to komponenter, Network og Node. Hvis du har konfigureret indstillingen for e-mailbeskeder, bør du få en kopi af disse alarmer i din postkasse.
Når du klikker på "Fuld alarmdetaljer", kan du få de vigtige detaljer om alarmen som værtsnavn, tidsstempel, klyngenavn og så videre. Det giver også det næste anbefalede skridt at tage. Du kan også sende denne alarm ud som en e-mail til andre modtagere, der er konfigureret under Indstillinger for e-mailbeskeder.
Du kan også vælge at slå en alarm fra ved at klikke på knappen "Ignorer alarm", og den vises ikke på listen igen. Det kan være nyttigt at ignorere en alarm, hvis du har en alarm af lav sværhedsgrad og ved, hvordan du håndterer eller omgår den. For eksempel hvis ClusterControl registrerer et dubletindeks i din database, hvor det i nogle tilfælde ville være nødvendigt for dine ældre applikationer.
Ved at se på denne side kan vi få en øjeblikkelig forståelse af, hvad der foregår med vores databaseklynge, og hvad det næste skridt er at gøre for at løse problemet. Som i dette tilfælde gik en af databasenoderne ned og blev utilgængelig via SSH fra ClusterControl-værten. Selv en nybegynder SysAdmin ville nu vide, hvad han skal gøre, hvis denne alarm vises.
Centraliserede databaselogfiler
Det er her, vi kan se, hvad der var galt med vores databaseserver. Under ClusterControl -> Logs -> System Logs kan du se alle logfiler relateret til databaseklyngen. Hvad angår MySQL-baseret databaseklynge, trækker ClusterControl ProxySQL-loggen, MySQL-fejllog og backuplogfiler:
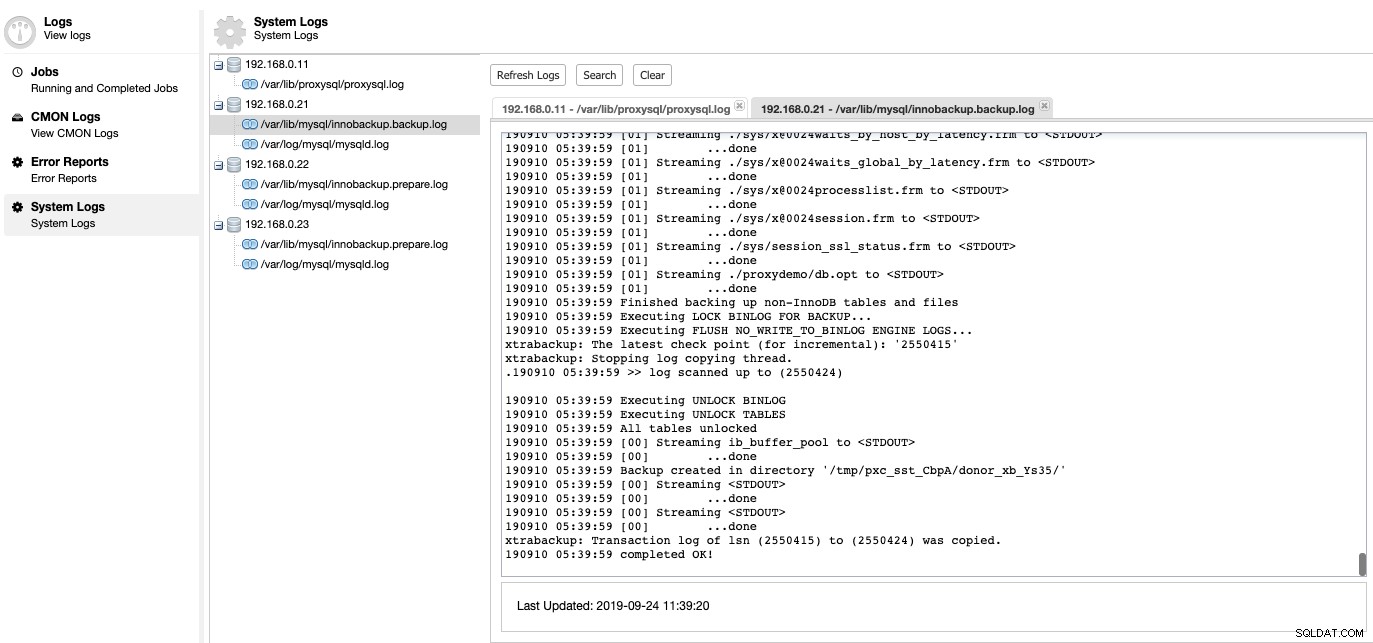
Klik på "Opdater log" for at hente den seneste log fra alle værter, der er tilgængelige på det pågældende tidspunkt. Hvis en node ikke er tilgængelig, vil ClusterControl stadig se det forældede login, da disse oplysninger er gemt i CMON-databasen. Som standard bliver ClusterControl ved med at hente systemlogfilerne hvert 10. minut, konfigurerbart under Indstillinger -> Loginterval.
ClusterControl udløser jobbet for at trække den seneste log fra hver server, som vist i følgende "Indsaml logs"-job:
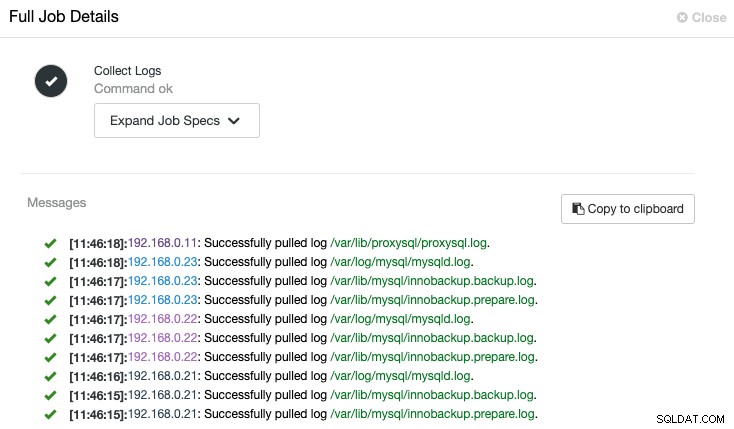
En centraliseret visning af logfilen giver os mulighed for hurtigere at forstå, hvad der gik forkert. For en databaseklynge, som almindeligvis involverer flere noder og niveauer, vil denne funktion i høj grad forbedre loglæsningen, hvor en SysAdmin kan sammenligne disse logfiler side om side og lokalisere kritiske hændelser, hvilket reducerer den samlede fejlfindingstid.
Web SSH-konsol
ClusterControl tilbyder en webbaseret SSH-konsol, så du kan få adgang til DB-serveren direkte via ClusterControl-brugergrænsefladen (da SSH-brugeren er konfigureret til at oprette forbindelse til databaseværterne). Herfra kan vi samle meget mere information, som giver os mulighed for at løse problemet endnu hurtigere. Alle ved, når et databaseproblem rammer produktionssystemet, hvert sekund af nedetid tæller.
For at få adgang til SSH-konsollen via nettet skal du blot vælge noderne under Noder -> Nodehandlinger -> SSH-konsol, eller blot klikke på tandhjulsikonet for en genvej:
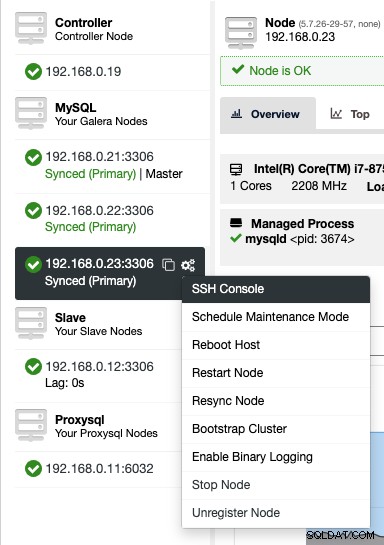
På grund af sikkerhedsproblemer, der kan pålægges denne funktion, især for multi -bruger- eller multi-tenant-miljø, kan man deaktivere det ved at gå til /var/www/html/clustercontrol/bootstrap.php på ClusterControl-serveren og sætte følgende konstant til false:
define('SSH_ENABLED', false);Opdater ClusterControl UI-siden for at indlæse de nye ændringer.
Problemer med databaseydelse
Udover overvågnings- og trendfunktioner sender ClusterControl dig proaktivt forskellige alarmer og rådgivere relateret til databasens ydeevne, for eksempel:
- Overdreven brug – Ressource, der passerer visse tærskler såsom CPU, hukommelse, swap-brug og diskplads.
- Klyngeforringelse - Klynge- og netværkspartitionering.
- Systemets tidsdrift – Tidsforskel mellem alle noder i klyngen (inklusive ClusterControl-knudepunktet).
- Forskellige andre MySQL-relaterede rådgivere:
- Replikering – replikeringsforsinkelse, binlog-udløb, placering og vækst
- Galera - SST-metode, scan GRA-logfil, klyngeadressekontrol
- Skemakontrol - Ikke-transaktionel tabeleksistens på Galera Cluster.
- Forbindelser - Trådforbundne forhold
- InnoDB - Beskidte sider-forhold, vækst af InnoDB-logfil
- Langsomme forespørgsler - Som standard vil ClusterControl udløse en alarm, hvis den finder en forespørgsel, der kører i mere end 30 sekunder. Dette kan selvfølgelig konfigureres under Indstillinger -> Runtime Configuration -> Long Query.
- Deadlocks - InnoDB-transaktioner deadlock og Galera-deadlock.
- Indekser - Dublerede nøgler, tabel uden primærnøgler.
Tjek Advisors-siden under Performance -> Advisors for at få detaljerne om ting, der kan forbedres som foreslået af ClusterControl. For hver rådgiver giver den begrundelser og råd som vist i følgende eksempel for rådgiveren "Kontrol af diskpladsforbrug":
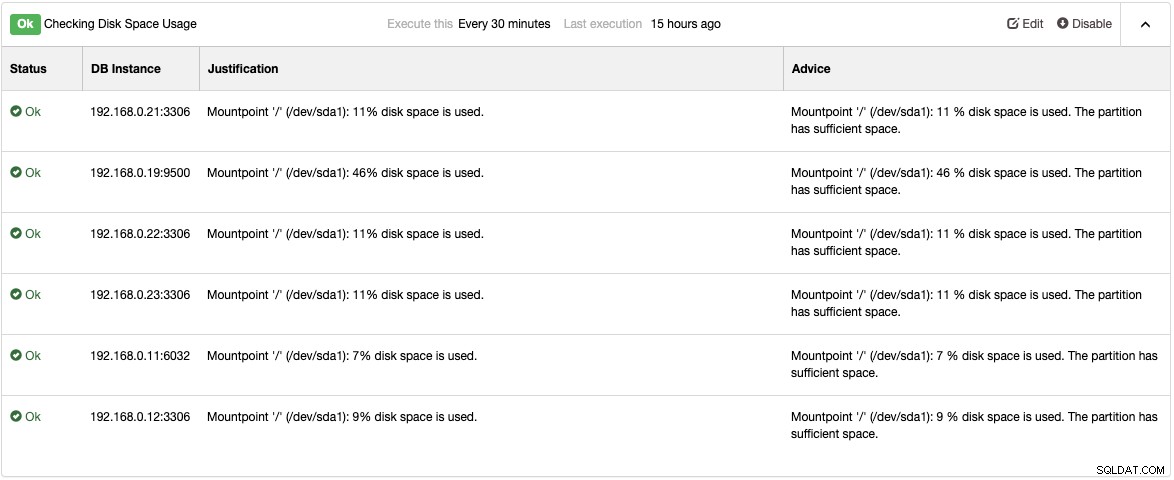
Når der opstår et ydeevneproblem, får du "Advarsel" (gul) eller "Kritisk" (rød) status på disse rådgivere. Yderligere tuning er almindeligvis påkrævet for at løse problemet. Rådgivere laver alarmer, hvilket betyder, at brugere vil få en kopi af disse alarmer inde i postkassen, hvis e-mailmeddelelser er konfigureret i overensstemmelse hermed. For hver alarm, der udløses af ClusterControl eller dets rådgivere, vil brugerne også modtage en e-mail, hvis alarmen er blevet slettet. Disse er forudkonfigureret i ClusterControl og kræver ingen indledende konfiguration. Yderligere tilpasning er altid mulig under Administrer -> Udviklerstudie. Du kan tjekke dette blogindlæg om, hvordan du skriver din egen rådgiver.
ClusterControl giver også en dedikeret side med hensyn til databaseydelse under ClusterControl -> Ydelse. Det giver alle slags databaseindsigter efter bedste praksis som centraliseret visning af DB Status, Variabler, InnoDB status, Schema Analyzer, Transaction Logs. Disse er ret selvforklarende og ligetil at forstå.
For forespørgselsydeevne kan du inspicere Topforespørgsler og Forespørgselsoutliers, hvor ClusterControl fremhæver forespørgsler, som udføres væsentligt afvigende fra deres gennemsnitlige forespørgsel. Vi har dækket dette emne i detaljer i dette blogindlæg, MySQL Query Performance Tuning.
Databasefejlrapporter
ClusterControl kommer med et fejlrapportgeneratorværktøj til at indsamle fejlfindingsoplysninger om din databaseklynge for at hjælpe med at forstå den aktuelle situation og status. For at generere en fejlrapport skal du blot gå til ClusterControl -> Logs -> Error Reports -> Create Error Report:
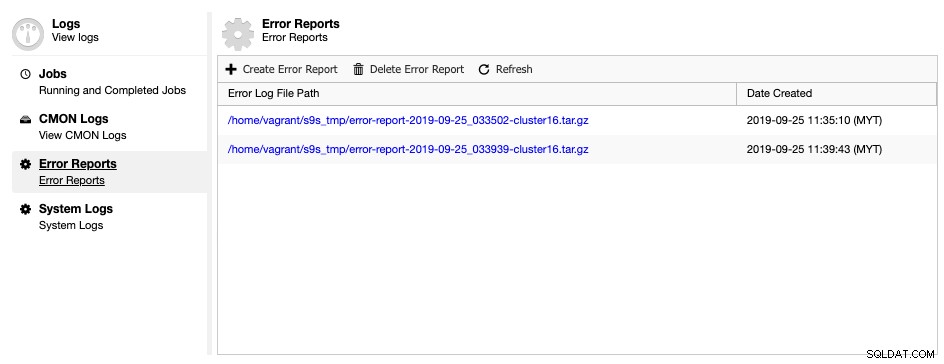
Den genererede fejlrapport kan downloades fra denne side, når den er klar. Denne genererede rapport vil være i TAR-boldformat (tar.gz), og du kan vedhæfte den til en supportanmodning. Da supportbilletten har en grænse på 10 MB filstørrelse, kan du, hvis tarball-størrelsen er større end det, uploade den til et skydrev og kun dele downloadlinket med os med korrekt tilladelse. Du kan fjerne den senere, når vi allerede har fået filen. Du kan også generere fejlrapporten via kommandolinjen som forklaret på dokumentationssiden for fejlrapporten.
I tilfælde af en fejl, anbefaler vi stærkt, at du genererer flere fejlrapporter under og lige efter udfaldet. Disse rapporter vil være meget nyttige for at forsøge at forstå, hvad der gik galt, konsekvenserne af afbrydelsen og for at verificere, at klyngen faktisk er tilbage til driftsstatus efter en katastrofal hændelse.
Konklusion
ClusterControl proaktiv overvågning sammen med et sæt fejlfindingsfunktioner giver en effektiv platform for brugere til at fejlfinde enhver form for MySQL-databaseproblemer. Længe væk er den gamle måde at fejlfinde på, hvor man skal åbne flere SSH-sessioner for at få adgang til flere værter og udføre flere kommandoer gentagne gange for at lokalisere årsagen.
Hvis de ovennævnte funktioner ikke hjælper dig med at løse problemet eller fejlfinde databaseproblemet, kontakter du altid Severalnines supportteam for at sikkerhedskopiere dig. Vores 24/7/365 dedikerede tekniske eksperter er til rådighed til at deltage i din anmodning når som helst. Vores gennemsnitlige første svartid er normalt mindre end 30 minutter.