Load balancers er en væsentlig komponent i database høj tilgængelighed; især når man laver topologiændringer gennemsigtige for applikationer og implementerer læse-skrive split-funktionalitet. ClusterControl tilbyder en række funktioner til sikkert at implementere, overvåge og konfigurere branchens førende open source belastningsbalanceringsteknologier.
I det seneste år har vi tilføjet understøttelse af ProxySQL og tilføjet flere forbedringer til HAProxy og MariaDBs Maxscale. Vi fortsætter denne tradition med den seneste udgivelse af ClusterControl 1.5.
Baseret på feedback, vi har modtaget fra vores brugere, har vi forbedret, hvordan ProxySQL administreres. Vi tilføjede også understøttelse af HAProxy og Keepalved til at køre oven på PostgreSQL-klynger.
I dette blogindlæg vil vi se på disse forbedringer...
ProxySQL - Brugerstyringsforbedringer
Tidligere ville brugergrænsefladen kun give dig mulighed for at oprette en ny bruger eller tilføje en eksisterende én ad gangen. En tilbagemelding, vi fik fra vores brugere, var, at det er ret svært at administrere et stort antal brugere. Vi lyttede og i ClusterControl 1.5 er det nu muligt at importere store partier af brugere. Lad os tage et kig på, hvordan du kan gøre det. Først og fremmest skal du have din ProxySQL installeret. Gå derefter til ProxySQL-noden, og på fanen Brugere skulle du se knappen "Importér brugere".

Når du klikker på den, åbnes en ny dialogboks:

Her kan du se alle de brugere, som ClusterControl har registreret på din klynge. Du kan rulle gennem dem og vælge dem, du vil importere. Du kan også vælge eller fravælge alle brugere fra en aktuel visning.

Når du begynder at skrive i søgefeltet, filtrerer ClusterControl ikke-matchende resultater fra, og indsnævrer listen kun til brugere, der er relevante for din søgning.
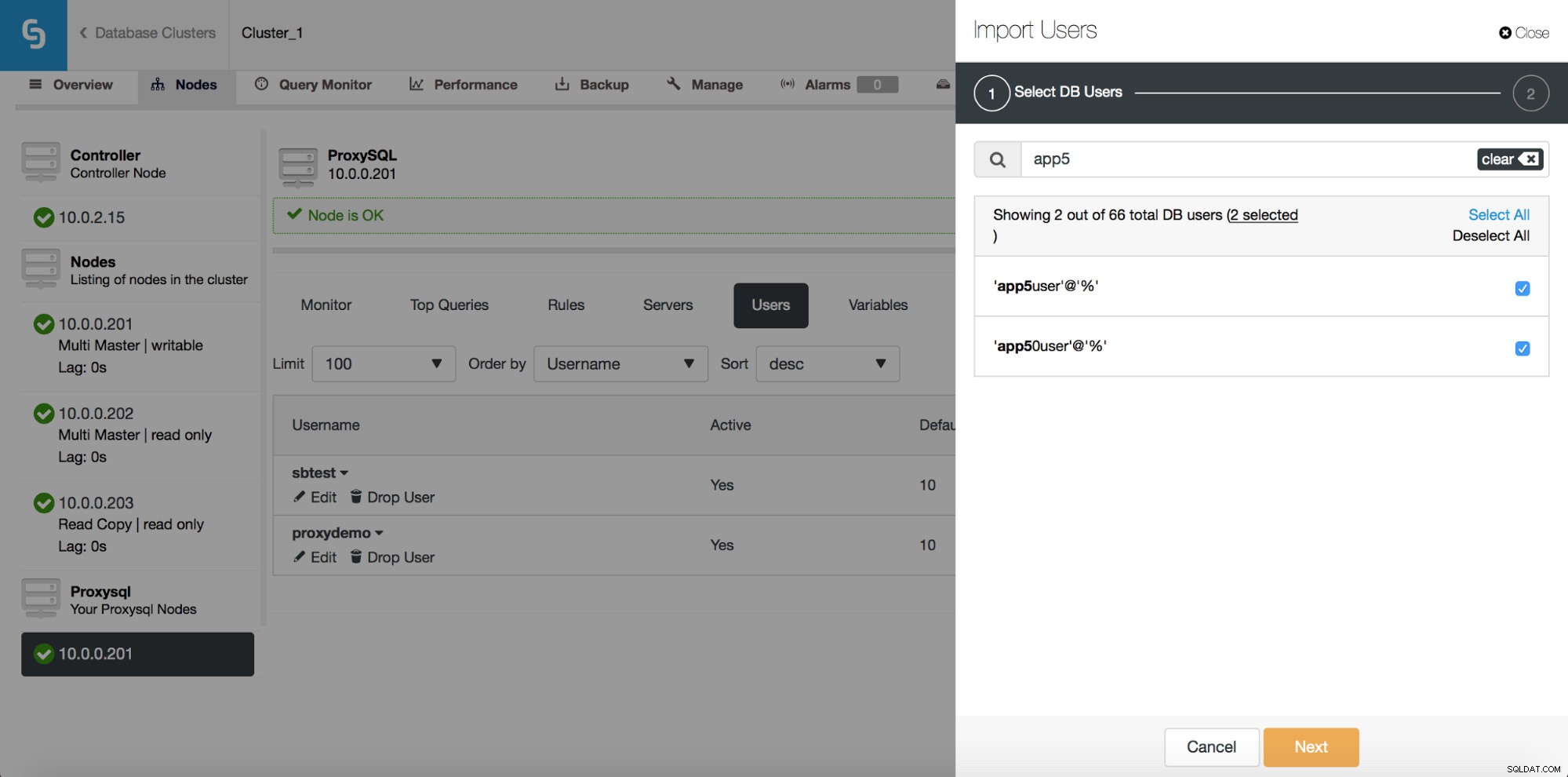
Du kan bruge knappen "Vælg alle" til at vælge alle brugere, der matcher din søgning. Når du har valgt de brugere, du vil importere, kan du selvfølgelig rydde søgefeltet og starte en ny søgning:

Bemærk venligst "(7 udvalgte)" - den fortæller dig, hvor mange brugere, i alt (ikke kun fra denne søgning), du har valgt at importere. Du kan også klikke på den for kun at se de brugere, du har valgt at importere.

Når du er tilfreds med dit valg, kan du klikke på "Næste" for at gå til næste skærmbillede.

Her skal du bestemme, hvad der skal være standard værtsgruppe for hver bruger. Du kan gøre det på basis af brugere eller globalt, for hele sættet eller en undergruppe af brugere, der er resultatet af en søgning.

Når du klikker på knappen "Importér brugere", vil brugerne blive importeret, og de vises på fanen Brugere.
ProxySQL - Planlægningsstyring
ProxySQLs skemalægger er et cron-lignende modul, som gør det muligt for ProxySQL at starte eksterne scripts med et regelmæssigt interval. Tidsplanen kan være ret detaljeret - op til én udførelse hvert millisekund. Typisk bruges skemalæggeren til at udføre Galera checker scripts (såsom proxysql_galera_checker.sh), men den kan også bruges til at udføre ethvert andet script, som du kan lide. Tidligere brugte ClusterControl planlæggeren til at implementere Galera checker-scriptet, men dette blev ikke vist i brugergrænsefladen. Når du starter ClusterControl 1.5, har du nu fuld kontrol.

Som du kan se, er et script blevet planlagt til at køre hvert andet sekund (2000 millisekunder) - dette er standardkonfigurationen for Galera-klyngen.

Ovenstående skærmbillede viser os muligheder for at redigere eksisterende poster. Bemærk venligst, at ProxySQL understøtter op til 5 argumenter til de scripts, den udfører gennem planlæggeren.

Hvis du ønsker, at et nyt script skal tilføjes til skemalæggeren, kan du klikke på knappen "Tilføj nyt script", og du vil blive præsenteret for en skærm som ovenstående. Du kan også forhåndsvise, hvordan det fulde script vil se ud, når det udføres. Når du har udfyldt alle "Argument"-felter og defineret intervallet, kan du klikke på knappen "Tilføj nyt script".

Som et resultat vil et script blive føjet til planlæggeren, og det vil være synligt på listen over planlagte scripts.
Download Whitepaper Today PostgreSQL Management &Automation med ClusterControlFå flere oplysninger om, hvad du skal vide for at implementere, overvåge, administrere og skalere PostgreSQLDownload WhitepaperPostgreSQL - Opbygning af High Availability Stack
Opsætning af replikering med automatisk failover er god, men programmer har brug for en enkel måde at spore den skrivbare master på. Så vi tilføjede understøttelse af HAProxy og Keepalived oven på PostgreSQL-klyngerne. Dette giver vores PostgreSQL-brugere mulighed for at implementere en fuld høj tilgængelig stak ved hjælp af ClusterControl.

Fra underfanen Load Balancer kan du nu implementere HAProxy - hvis du er bekendt med, hvordan ClusterControl implementerer MySQL-replikering, er det en meget lignende opsætning. Vi installerer HAProxy på en given vært, to backends, læser på port 3308 og skriver på port 3307. Den bruger tcp-check og forventer, at en bestemt streng vender tilbage. For at producere denne streng udføres følgende trin på alle databasenoder. Først og fremmest er xinet.d konfigureret til at køre en tjeneste på port 9201 (for at undgå forveksling med MySQL-opsætning, som bruger port 9200).
# default: on
# description: postgreschk
service postgreschk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/postgreschk
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITEDTjenesten udfører /usr/local/sbin/postgreschk script, som validerer PostgreSQL's tilstand og fortæller, om en given vært er tilgængelig, og hvilken type vært det er (master eller slave). Hvis alt er ok, returnerer den den streng, der forventes af HAProxy.
Ligesom med MySQL ses HAProxy-noder i PostgreSQL-klynger i brugergrænsefladen, og statussiden kan tilgås:

Her kan du se begge backends og verificere, at kun masteren er oppe til r/w backend, og alle noder kan tilgås via den skrivebeskyttede backend. Du kan også få nogle statistikker om trafik og forbindelser.
HAProxy hjælper med at forbedre høj tilgængelighed, men det kan blive et enkelt fejlpunkt. Vi er nødt til at gå den ekstra mil og konfigurere redundans ved hjælp af Keepalived.

Under Administrer -> Load balancer -> Keepalved vælger du de HAProxy-værter, du gerne vil bruge, og Keepalived vil blive implementeret oven på dem med en virtuel IP knyttet til den grænseflade, du vælger.
Fra nu af skal al forbindelse gå til VIP'en, som vil blive knyttet til en af HAProxy-noderne. Hvis den node går ned, vil Keepalived tage VIP'en ned på den node og bringe den op på en anden HAProxy-node.
Det er det for belastningsbalanceringsfunktionerne introduceret i ClusterControl 1.5. Prøv dem, og lad os vide, hvordan du gør