Oversigt
Oracle Data Mining (ODM) er en komponent i Oracle Advanced Analytics Database Option. ODM indeholder en række avancerede data mining-algoritmer, der er indlejret i databasen, som giver dig mulighed for at udføre avancerede analyser på dine data.
Oracle Data Miner er en udvidelse af Oracle SQL Developer, et grafisk udviklingsmiljø til Oracle SQL. Oracle Data Miner bruger data mining-teknologien indlejret i Oracle Database til at skabe, eksekvere og administrere arbejdsgange, der indkapsler data mining-operationer. Arkitekturen af ODM er illustreret i figur 1.
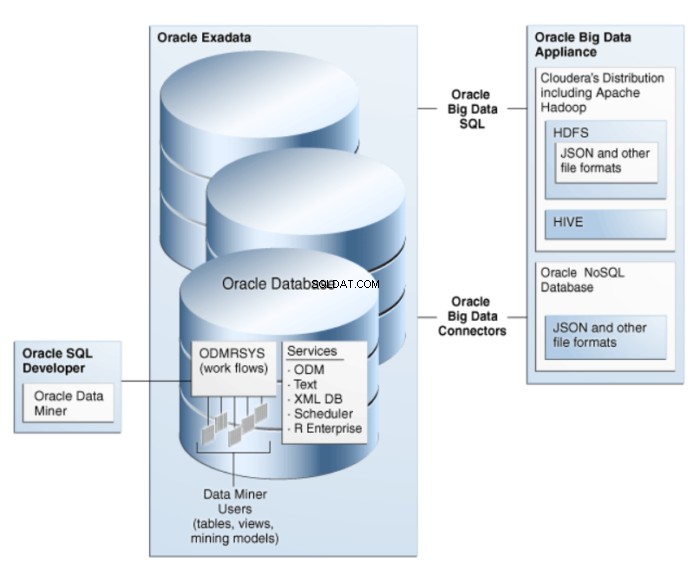
Figur 1:Oracle Data Mining Architecture for Big Data
Algoritmer implementeres som SQL-funktioner og udnytter styrkerne ved Oracle-databasen. SQL-data mining-funktionerne kan mine transaktionsdata, aggregeringer, ustrukturerede data, dvs. CLOB-datatype (ved hjælp af Oracle Text) og geografiske data.
Hver dataminingfunktion specificerer en klasse af problemer, der kan modelleres og løses. Data mining-funktioner falder generelt i to kategorier:overvåget og ikke-overvåget.
Begreber om overvåget og ikke-overvåget læring er afledt af videnskaben om maskinlæring, som er blevet kaldt et underområde af kunstig intelligens.
Superviseret læring er også kendt som rettet læring. Læringsprocessen styres af en tidligere kendt afhængig egenskab eller mål. Direkte data mining forsøger at forklare målets adfærd som en funktion af et sæt uafhængige attributter eller forudsigere.
Uovervåget læring er ikke-rettet. Der er ingen forskel mellem afhængige og uafhængige egenskaber. Der er ikke noget tidligere kendt resultat til at guide algoritmen i opbygningen af modellen. Uovervåget læring kan bruges til beskrivende formål.
Oracle Data Mining-overvågede algoritmer
| Teknik | Anvendelse | Algorithmer (kort beskrivelse) |
|---|---|---|
Klassificering | Mest anvendte teknik til at forudsige et specifikt resultat, f.eks. identifikation af cancertumorceller, sentimentanalyse, narkotikaklassificering, spam-detektion. | Generaliserede lineære modeller Logistisk regression - klassisk statistisk teknik tilgængelig i Oracle-databasen i en yderst effektiv, skalerbar, paralliseret implementering (gælder for alle OAA ML-algoritmer). Understøtter tekst- og transaktionsdata (gælder næsten alle OAA ML-algoritmer) Naive Bayes - Hurtig, enkel, almindeligt anvendelig. Support Vector Machine - Machine learning-algoritme, understøtter tekst og brede data. Beslutningstræ - Populær ML-algoritme til fortolkning. Giver "regler", der kan læses af mennesker. |
Regression | Teknik til at forudsige et kontinuerligt numerisk resultat, såsom astronomisk dataanalyse, Generering af indsigt i forbrugeradfærd, rentabilitet og andre forretningsfaktorer, Beregning af årsagssammenhænge mellem parametre i biologiske systemer. | Generaliserede lineære modeller Multipel regression - klassisk statistisk teknik, men nu tilgængelig i Oracle-databasen som en yderst effektiv, skalerbar, paralliseret implementering. Understøtter ridge-regression, funktionsoprettelse og funktionsvalg. Understøtter tekst og transaktionsdata. Support Vector Machine - Machine learning algoritme, understøtter tekst og brede data. |
Betydning af egenskaber | Rangerer attributter efter styrken af forholdet til målattributten. Brugstilfælde omfatter at finde faktorer, der er mest forbundet med kunder, der reagerer på et tilbud, faktorer, der er mest forbundet med raske patienter. | Minimum beskrivelseslængde – betragter hver egenskab som en simpel forudsigelsesmodel for målklassen og giver relativ indflydelse. |
Oracle Data Mining Uovervågede Algoritmer
| Teknik | Anvendelse | Algorithmer |
|---|---|---|
Klyngedannelse | Klynge bruges til at opdele en databases poster i undersæt eller klynger, hvor elementer i en klynge deler et sæt fælles egenskaber. Eksempler omfatter at finde nye kundesegmenter og filmanbefalinger. | K-Means - Understøtter tekstmining, hierarkisk clustering, afstandsbaseret. Ortogonal partitionering Clustering - Hierarkisk clustering, tæthedsbaseret. Forventningsmaksimering - Klyngeteknik, der fungerer godt i problemer med blandede data (tætte og sparsomme) datamining. |
Anomalidetektion | Anomalidetektion identificerer datapunkter, hændelser og/eller observationer, der afviger fra et datasæts normale adfærd. Almindelige eksempler omfatter banksvig, en strukturel defekt, medicinske problemer eller fejl i en tekst | One-Class Support Vector Machine - træner umærkede data og forsøger at bestemme, om et testpunkt hører til distributionen af træningsdata. |
Funktionsvalg og ekstraktion | Producerer nye attributter som lineær kombination af eksisterende attributter. Gælder for tekstdata, latent semantisk analyse (LSA), datakomprimering, datanedbrydning og projektion og mønstergenkendelse. | Ikke-negativ matrixfaktorisering - Mapper de originale data til det nye sæt attributter Principal Components Analysis (PCA) - skaber nye færre sammensatte attributter, der repræsenterer alle de attributter. Singular Vector Decomposition - etableret funktionsekstraktionsmetode, der har en bred vifte af applikationer. |
Forening | Finder regler forbundet med hyppigt forekommende varer, der bruges til markedskurvsanalyse, krydssalg, årsagsanalyse. Nyttigt til produktbundtning og defektanalyse. | Apriori - Hashed et træ for at indsamle oplysninger i en database |
Aktivering af Oracle Data Mining Option
Fra 12c Release 2 Oracle Advanced Analytics Muligheden inkluderer Data Mining og Oracle R-funktionalitet.
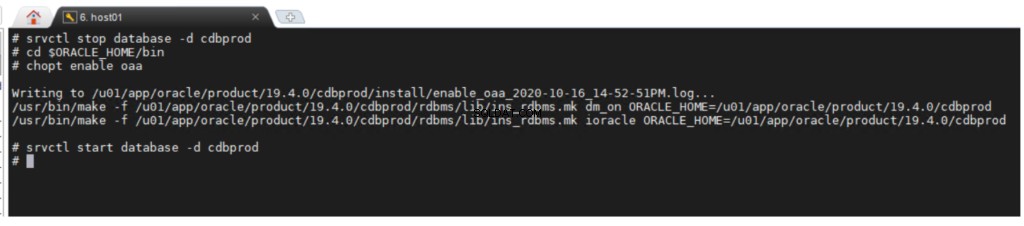
Oracle Advanced Analytics-indstillingen er aktiveret som standard under installationen af Oracle Database Enterprise Edition. Hvis du ønsker at aktivere eller deaktivere en databaseindstilling, kan du bruge kommandolinjeværktøjet chopt .
chopt [ enable | disable ] oaa
Sådan aktiverer du Oracle Advanced Analytics-indstillingen:
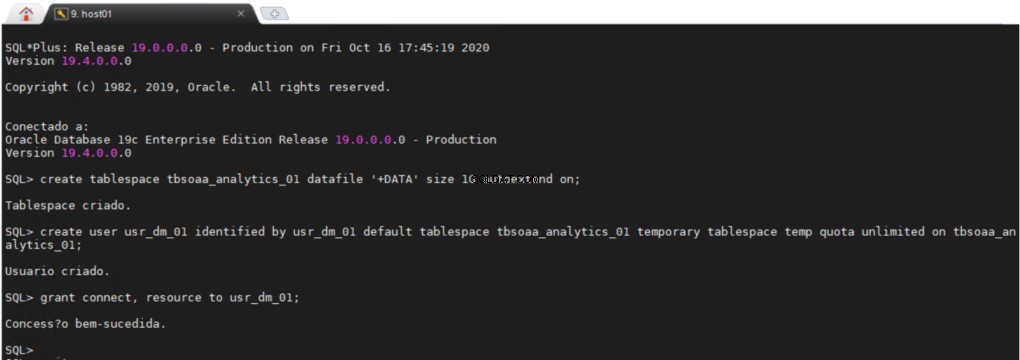
Oprettelse af Tablespace et ODM-skema
Alle brugere kræver et permanent tablespace og et midlertidigt tablespace, hvor de kan udføre deres arbejde. Det kan være meget brugervenligt at have et separat område i din database, hvor du kan oprette alle dine data mining-objekter.
usr_dm_01 skema vil indeholde alle dine Data Mining-værker.
Oprettelse af ODM-lageret
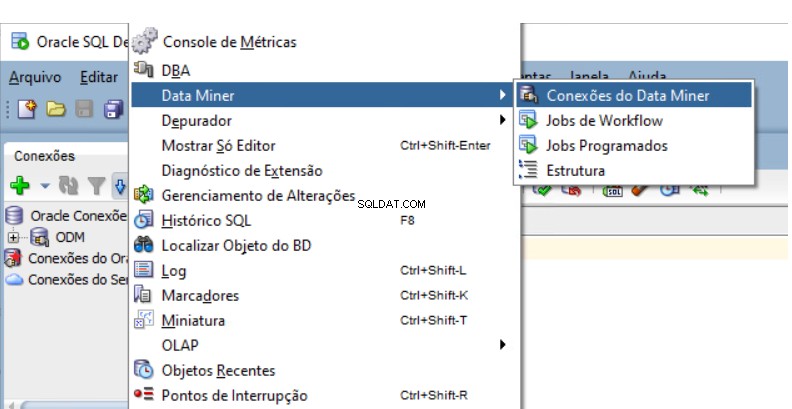
Du skal oprette et Oracle Data Mining Repository i databasen. Gå til Data Miner Navigator i SQL Developer.
Vælg Vis -> Data Miner -> Data Miner-forbindelser:
En ny fane åbnes ved siden af din eksisterende fane Forbindelser:
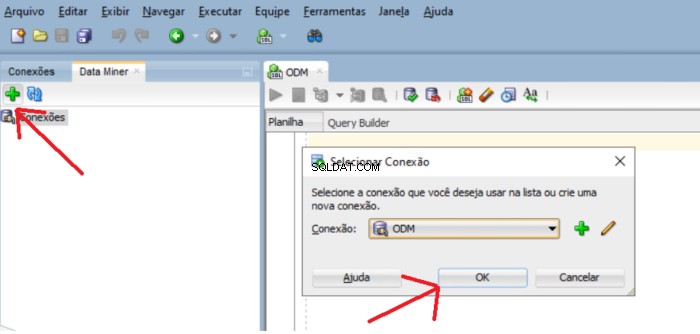
For at tilføje usr_dm_01 skema til denne liste, klik på de grønne plusvinduer og OK
Hvis lageret ikke eksisterer, vises en meddelelse, der spørger, om du vil installere lageret. Klik på Ja knappen for at fortsætte med installationen.
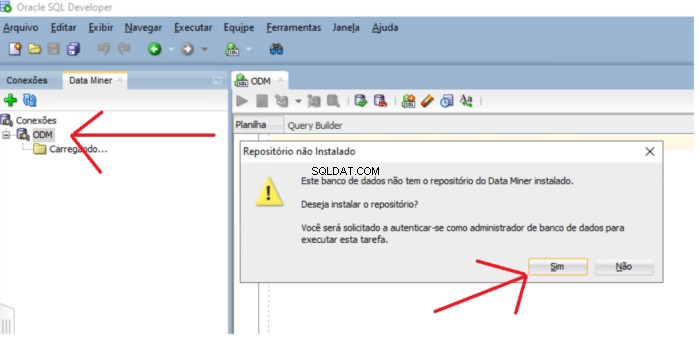
Du skal indtaste SYS-adgangskoden
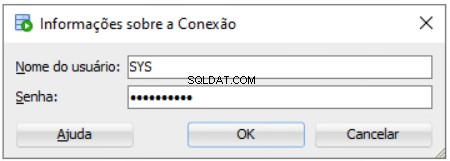
Indstilling for lagerinstallation
Vinduet Installation af Data Miner Repository-fremskridt
Opgave afsluttet med succes
Logfil
Oracle Data Mining-komponenter
Workflowet giver dig mulighed for at opbygge en række noder, der udfører al den nødvendige behandling af dine data.
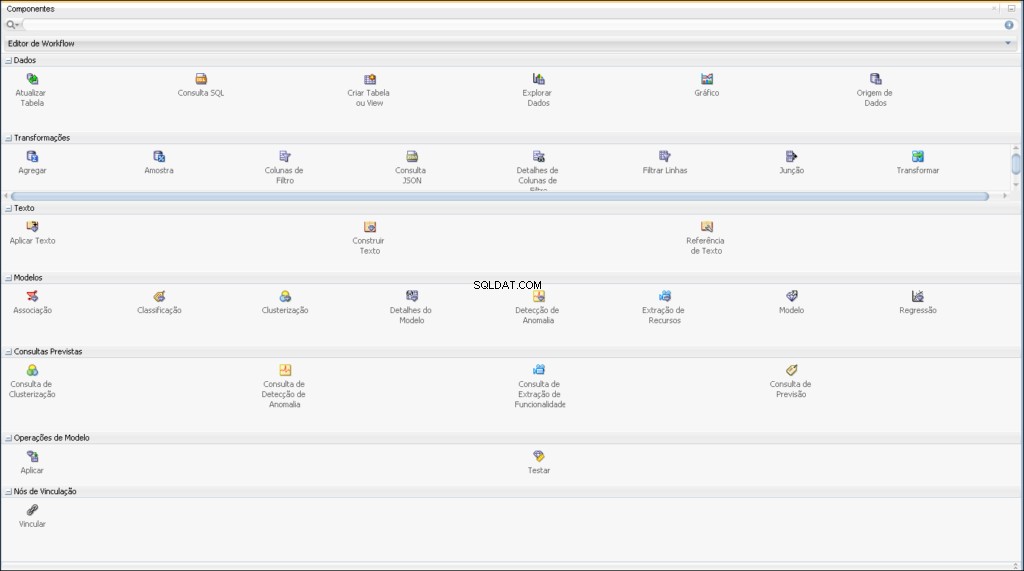
Eksempel på en arbejdsgang udviklet til prædiktiv analyse
ODM Data Dictionary Views
Du kan få oplysninger om minedriftsmodeller fra dataordbogen.
Data Mining-dataordbogsvisningerne er opsummeret som følger:
Bemærk:* kan erstattes af ALL_, USER_, DBA_ og CDB_
*_MINING_MODELS :Information om de minedriftsmodeller, der er blevet oprettet.
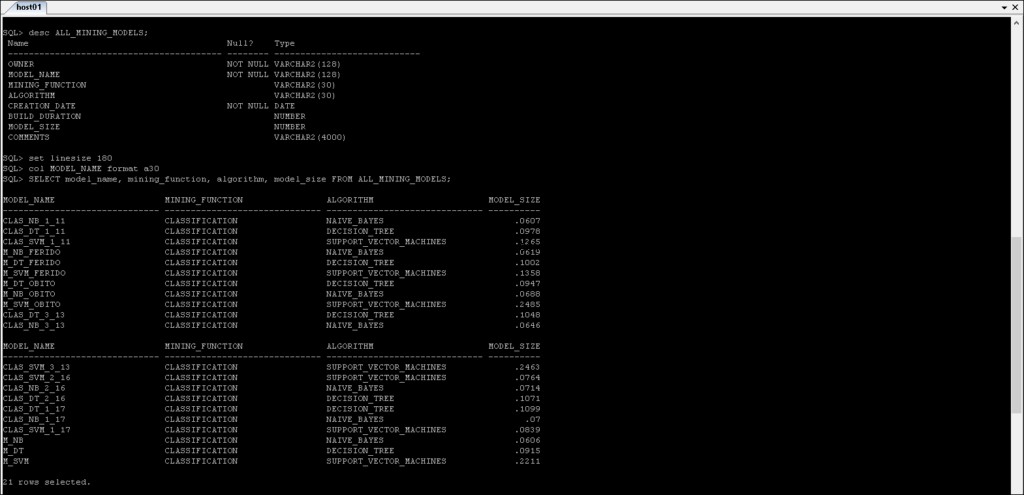
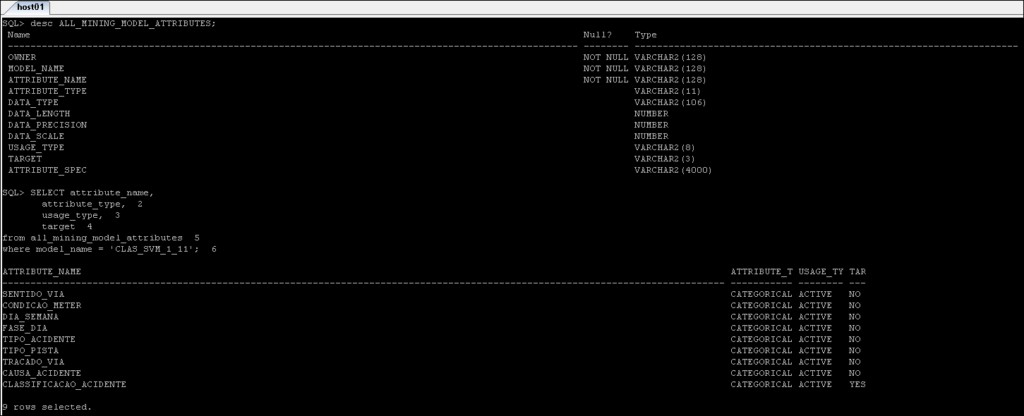
*_MINING_MODEL_ATTRIBUTES :Indeholder detaljerne om de attributter, der er blevet brugt til at skabe Oracle Data Mining-modellen.
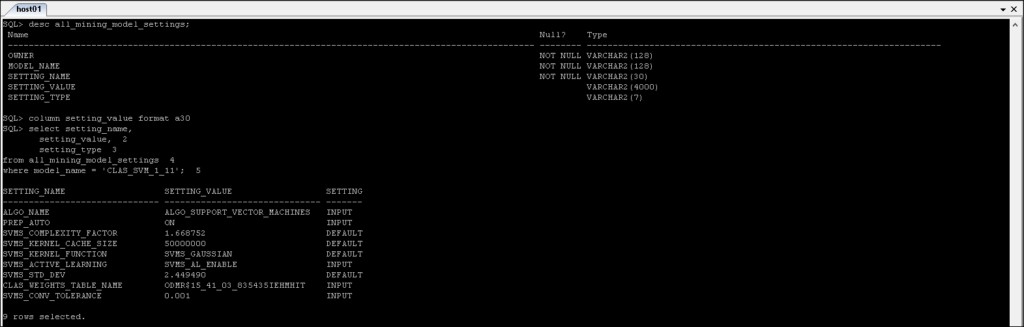
*_MINING_MODEL_SETTINGS :Returnerer oplysninger om indstillingerne for de minedriftsmodeller, som du har adgang til.
Referencer
Oracle Data Mining Brugervejledning. Tilgængelig på:https://docs.oracle.com/en/database/oracle/oracle-database/19/dmprg/lot.html
Oracle Data Mining – Skalerbar forudsigelig analyse i databasen. Tilgængelig på:https://www.oracle.com/database/technologies/advanced-analytics/odm.html
Oracle Data Miner-systemoversigt. Tilgængelig på:https://docs.oracle.com/database/sql-developer-17.4/DMRIG/oracle-data-miner-overview.htm#DMRIG124