Når du arbejder på et projekt, der består af en masse mikrotjenester, vil det sandsynligvis også omfatte flere databaser.
For eksempel kan du have en MySQL-database og en PostgreSQL-database, som begge kører på separate servere.
Normalt, for at forbinde dataene fra de to databaser, skal du introducere en ny mikrotjeneste, der vil samle dataene. Men dette ville øge kompleksiteten af systemet.
I denne tutorial vil vi bruge Materialize til at deltage i MySQL og Postgres i en levende materialiseret visning. Vi vil derefter være i stand til at forespørge det direkte og få resultater tilbage fra begge databaser i realtid ved hjælp af standard SQL.
Materialize er en kildetilgængelig streamingdatabase skrevet i Rust, der vedligeholder resultaterne af en SQL-forespørgsel (en materialiseret visning) i hukommelsen, efterhånden som dataene ændres.
Selvstudiet inkluderer et demoprojekt, som du kan begynde at bruge docker-compose .
Demoprojektet, som vi skal bruge, vil overvåge ordrerne på vores falske hjemmeside. Det vil generere begivenheder, der senere kan bruges til at sende meddelelser, når en vogn har været forladt i lang tid.
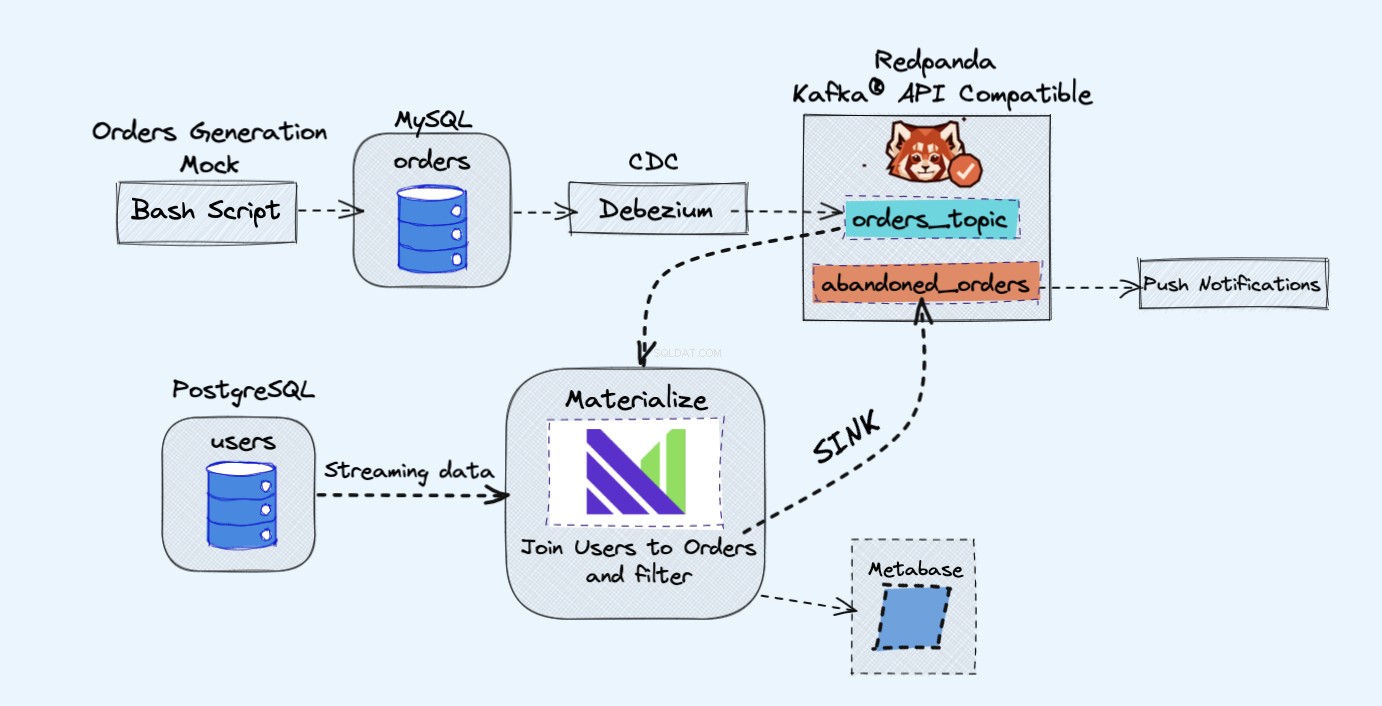
Demoprojektets arkitektur er som følger:
Forudsætninger
Alle de tjenester, som vi vil bruge i demoen, kører i Docker-containere, på den måde behøver du ikke installere yderligere tjenester på din bærbare computer eller server i stedet for Docker og Docker Compose.
Hvis du ikke allerede har Docker og Docker Compose installeret, kan du følge de officielle instruktioner om, hvordan du gør det her:
- Installer Docker
- Installer Docker Compose
Oversigt
Som vist i diagrammet ovenfor, vil vi have følgende komponenter:
- En falsk tjeneste til konstant at generere ordrer.
- Ordrerne vil blive gemt i en MySQL-database .
- Når databasen skriver opstår, Debezium streamer ændringerne fra MySQL til en Redpanda emne.
- Vi har også en Postgres database, hvor vi kan få vores brugere.
- Vi indtager derefter dette Redpanda-emne i Materialize direkte sammen med brugerne fra Postgres-databasen.
- I Materialize slår vi vores ordrer og brugere sammen, foretager nogle filtreringer og skaber en materialiseret visning, der viser oplysninger om de forladte indkøbskurv.
- Vi vil derefter oprette en vask til at sende de forladte vogndata ud til et nyt Redpanda-emne.
- I slutningen vil vi bruge Metabase at visualisere dataene.
- Du kan senere bruge oplysningerne fra det nye emne til at sende meddelelser til dine brugere og minde dem om, at de har en forladt vogn.
Som en sidebemærkning her, ville du være helt i orden med at bruge Kafka i stedet for Redpanda. Jeg kan bare godt lide den enkelhed, som Redpanda bringer til bordet, da du kan køre en enkelt Redpanda-instans i stedet for alle Kafka-komponenterne.
Sådan kører du demoen
Start først med at klone depotet:
git-klon https://github.com/bobbyiliev/materialize-tutorials.git Derefter kan du få adgang til biblioteket:
cd materialize-tutorials/mz-join-mysql-and-postgresql Lad os starte med først at køre Redpanda-beholderen:
docker-compose up -d redpanda Byg billederne:
docker-compose build Til sidst skal du starte alle tjenesterne:
docker-compose up -d For at starte Materialize CLI kan du køre følgende kommando:
docker-compose kør mzcli
Dette er blot en genvej til en Docker-container med postgres-client forudinstalleret. Hvis du allerede har psql du kunne køre psql -U materialize -h localhost -p 6875 materialize i stedet.
Sådan opretter du en Materialize Kafka-kilde
Nu hvor du er i Materialize CLI, lad os definere ordrerne tabeller i mysql.shop database som Redpanda-kilder:
OPRET KILDEordrer FRA KAFKA MÆgler 'redpanda:9092' TOPIC 'mysql.shop.orders'FORMAT AVRO VED BRUG AF CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081'ENVELOPE DEBEZIUM;
Hvis du skulle tjekke de tilgængelige kolonner fra ordrerne kilde ved at køre følgende sætning:
VIS KOLONNER FRA ordrer; Du ville være i stand til at se, at da Materialize trækker meddelelsesskemadata fra Redpanda-registret, kender den kolonnetyperne, der skal bruges for hver attribut:
navn | nullbar | type--------------+-----------+------------ id | f | bigint bruger_id | t | bigint ordrestatus | t | heltalspris | t | numerisk oprettet_ved | f | tekst updated_at | t | tidsstempel Sådan opretter du materialiserede visninger
Dernæst vil vi oprette vores første materialiserede visning for at få alle data fra ordrerne Redpanda-kilde:
OPRET MATERIALISERET VISNING orders_view ASSELECT * FRA ordrer; OPRET MATERIALISERET VISNING abandoned_orders AS SELECT user_id, order_status, SUM(price) som omsætning, COUNT(id) AS total FROM orders_view WHERE order_status=0 GROUP BY 1,2;
Du kan nu bruge SELECT * FROM abandoned_orders; for at se resultaterne:
SELECT * FROM abandoned_orders; For mere information om oprettelse af materialiserede visninger, se afsnittet Materialiserede visninger i Materialize-dokumentationen.
Sådan opretter du en Postgres-kilde
Der er to måder at oprette en Postgres-kilde på i Materialize:
- Bruger Debezium ligesom vi gjorde med MySQL-kilden.
- Brug af Postgres Materialize-kilden, som giver dig mulighed for at forbinde Materialize direkte til Postgres, så du ikke behøver at bruge Debezium.
Til denne demo vil vi bruge Postgres Materialize-kilden kun som en demonstration af, hvordan man bruger den, men du er velkommen til at bruge Debezium i stedet for.
For at oprette en Postgres Materialize-kilde skal du køre følgende sætning:
OPRET MATERIALISERET KILDE "mz_source" FRA POSTGRESCONNECTION 'user=postgres port=5432 host=postgres dbname=postgres password=postgres'PUBLICATION 'mz_source'; En hurtig gennemgang af ovenstående udsagn:
MATERIALISERET:Materialiserer PostgreSQL-kildens data. Alle data gemmes i hukommelsen og gør kilder direkte valgbare.mz_source:Navnet på PostgreSQL-kilden.FORBINDELSE:PostgreSQL-forbindelsesparametrene.PUBLIKATION:PostgreSQL-publikationen, der indeholder tabellerne, der skal streames til Materialize.
Når vi har oprettet PostgreSQL-kilden, skal vi for at kunne forespørge PostgreSQL-tabellerne oprette visninger, der repræsenterer opstrømspublikationens originale tabeller.
I vores tilfælde har vi kun én tabel kaldet brugere så den erklæring, som vi skal køre, er:
OPRET VISNINGER FRA KILDEN mz_source (brugere); For at se de tilgængelige visninger skal du udføre følgende sætning:
VIS FULDE VISNINGER; Når det er gjort, kan du forespørge de nye visninger direkte:
VÆLG * FRA brugere; Lad os derefter gå videre og oprette et par flere visninger.
Sådan opretter du en Kafka-vask
Sinks lader dig sende data fra Materialize til en ekstern kilde.
Til denne demo vil vi bruge Redpanda.
Redpanda er Kafka API-kompatibel, og Materialize kan behandle data fra det, ligesom det ville behandle data fra en Kafka-kilde.
Lad os skabe en materialiseret visning, der vil indeholde alle de ubetalte ordrer med høj volumen:
CREATE MATERIALIZED VIEW high_value_orders AS SELECT users.id, users.email, abandoned_orders.revenue, abandoned_orders.total FRA brugere JOIN Abandoned_orders ON abandoned_orders.user_id =users.id GRUPPER VED 1,2,3,4> 2000;
Som du kan se, slutter vi os faktisk til brugerne visning, som indtager dataene direkte fra vores Postgres-kilde, og abandond_orders se, som indtager data fra Redpanda-emnet sammen.
Lad os oprette en vask, hvor vi sender dataene fra ovenstående materialiserede visning:
OPRET SINK high_value_orders_sink FRA high_value_orders INTO KAFKA BROKER 'redpanda:9092' TOPIC 'high-value-orders-sink' FORMAT AVRO BRUG AF CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081';
Hvis du nu skulle oprette forbindelse til Redpanda-beholderen og bruge rpk-emnet forbrug kommando, vil du være i stand til at læse posterne fra emnet.
Men på nuværende tidspunkt vil vi ikke være i stand til at forhåndsvise resultaterne med rpk fordi det er AVRO-formateret. Redpanda ville højst sandsynligt implementere dette i fremtiden, men i øjeblikket kan vi faktisk streame emnet tilbage til Materialize for at bekræfte formatet.
Først skal du få navnet på det emne, der er blevet automatisk genereret:
VÆLG emne FRA mz_kafka_sinks; Output:
emne -------------------------------------------- ---------------------- high-volume-orders-sink-u12-1637586945-13670686352905873426 For mere information om, hvordan emnenavnene genereres, se dokumentationen her.
Opret derefter en ny materialiseret kilde fra dette Redpanda-emne:
OPRET MATERIALISERET KILDE high_volume_orders_testFRA KAFKA MÆGLER 'redpanda:9092' TOPIC ' high-volume-orders-sink-u12-1637586945-13670686352905873426' CONFENTRO US:<1pSCHEMA REGISTRATION:<1p://www. /kode> Sørg for at ændre emnenavnet tilsvarende!
Forespørg endelig på denne nye materialiserede visning:
VÆLG * FRA high_volume_orders_test LIMIT 2; Nu hvor du har dataene i emnet, kan du få andre tjenester til at oprette forbindelse til det og forbruge det og derefter udløse e-mails eller advarsler for eksempel.
Sådan forbinder du Metabase
Besøg https://localhost:3030 for at få adgang til Metabase-forekomsten hvis du kører demoen lokalt eller https://din_server_ip:3030 hvis du kører demoen på en server. Følg derefter trinene for at fuldføre Metabase-opsætningen.
Sørg for at vælge Materialize som kilden til dataene.
Når du er klar, vil du være i stand til at visualisere dine data, ligesom du ville gøre med en standard PostgreSQL-database.
Sådan stoppes demoen
For at stoppe alle tjenester skal du køre følgende kommando:
docker-compose down Konklusion
Som du kan se, er dette et meget simpelt eksempel på, hvordan du bruger Materialize. Du kan bruge Materialize til at indlæse data fra en række forskellige kilder og derefter streame dem til en række forskellige destinationer.
Nyttige ressourcer:
OPRET KILDE:PostgreSQLOPRET KILDEOPRET VISNINGERVÆLG