Er det ikke fantastisk at have en ny version af SQL Server tilgængelig? Dette er noget, der kun sker hvert par år, og i denne måned så vi én nå General Tilgængelighed. (Ok, jeg ved, vi får en ny version af SQL Database i Azure næsten kontinuerligt, men jeg regner dette som anderledes.) Med anerkendelse af denne nye udgivelse handler denne måneds T-SQL-tirsdag (vært af Michael Swart – @mjswart) om alt, hvad SQL Server 2016 angår!
Er det ikke fantastisk at have en ny version af SQL Server tilgængelig? Dette er noget, der kun sker hvert par år, og i denne måned så vi én nå General Tilgængelighed. (Ok, jeg ved, vi får en ny version af SQL Database i Azure næsten kontinuerligt, men jeg regner dette som anderledes.) Med anerkendelse af denne nye udgivelse handler denne måneds T-SQL-tirsdag (vært af Michael Swart – @mjswart) om alt, hvad SQL Server 2016 angår!
Så i dag vil jeg se på SQL 2016's Temporal Tables-funktion og se på nogle forespørgselsplansituationer, du kan ende med at se. Jeg elsker Temporal Tables, men er stødt på noget af en ting, som du måske vil være opmærksom på.
Nu, på trods af at SQL Server 2016 nu er i RTM, bruger jeg AdventureWorks2016CTP3, som du kan downloade her - men du skal ikke bare downloade AdventureWorks2016CTP3.bak , tag også fat i SQLServer2016CTP3Samples.zip fra samme websted.
Du kan se, i prøvearkivet er der nogle nyttige scripts til at afprøve nye funktioner, herunder nogle til Temporal Tables. Det er win-win - du kan prøve en masse nye funktioner, og jeg behøver ikke at gentage så meget script i dette indlæg. Under alle omstændigheder, tag fat i de to scripts om Temporal Tables, der kører AW 2016 CTP3 Temporal Setup.sql , efterfulgt af Temporal System-Versioning Sample.sql .
Disse scripts opsætter temporale versioner af nogle få tabeller, inklusive HumanResources.Employee . Det opretter HumanResources.Employee_Temporal (selvom det teknisk set kunne have heddet hvad som helst). I slutningen af CREATE TABLE sætning, vises denne bit og tilføjer to skjulte kolonner, der skal bruges til at angive, hvornår rækken er gyldig, og angiver, at en tabel skal oprettes kaldet HumanResources.Employee_Temporal_History for at gemme de gamle versioner.
... ValidFrom datetime2(7) GENERERET ALTID SOM RÆKKE START SKJULT IKKE NULL, ValidTo datetime2(7) GENERERET ALTID SOM RÆKKE END SKJULT IKKE NULL, PERIODE FOR SYSTEM_TIME (ValidFrom, ValidTo)) MED (SYSTEM_VERSIONING_TABLESTORY =[HumanResources].[Employee_Temporal_History]));
Det, jeg vil udforske i dette indlæg, er, hvad der sker med forespørgselsplaner, når historikken bruges.
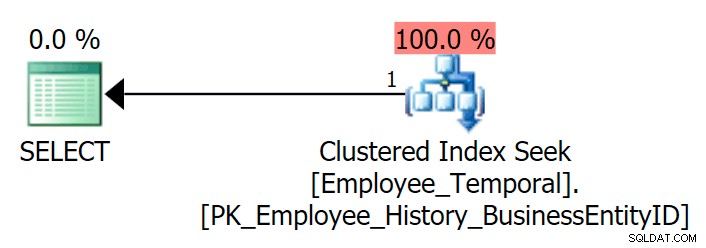
Hvis jeg forespørger i tabellen for at se den seneste række for en bestemt BusinessEntityID , får jeg en Clustered Index Seek, som forventet.
SELECT e.BusinessEntityID, e.ValidFrom, e.ValidToFROM HumanResources.Employee_Temporal AS eWHERE e.BusinessEntityID =4;
Jeg er sikker på, at jeg kunne forespørge denne tabel ved hjælp af andre indekser, hvis den havde nogen. Men i dette tilfælde gør det ikke. Lad os oprette en.
OPRET UNIKT INDEX rf_ix_Login på HumanResources.Employee_Temporal(LoginID);
Nu kan jeg forespørge i tabellen med LoginID , og vil se et nøgleopslag, hvis jeg beder om andre kolonner end Loginid eller BusinessEntityID . Intet af dette er overraskende.
SELECT * FROM HumanResources.Employee_Temporal eWHERE e.LoginID =N'adventure-works\rob0';
Lad os bruge SQL Server Management Studio et øjeblik og se, hvordan denne tabel ser ud i Object Explorer.

Vi kan se historiktabellen nævnt under HumanResources.Employee_Temporal , og kolonnerne og indekserne fra både selve tabellen og historietabellen. Men mens indekserne på den rigtige tabel er den primære nøgle (på BusinessEntityID ) og det indeks, jeg lige havde oprettet, har historiktabellen ikke matchende indekser.
Indekset på historiktabellen er på ValidTo og ValidFrom . Vi kan højreklikke på indekset og vælge Egenskaber, og vi ser denne dialogboks:
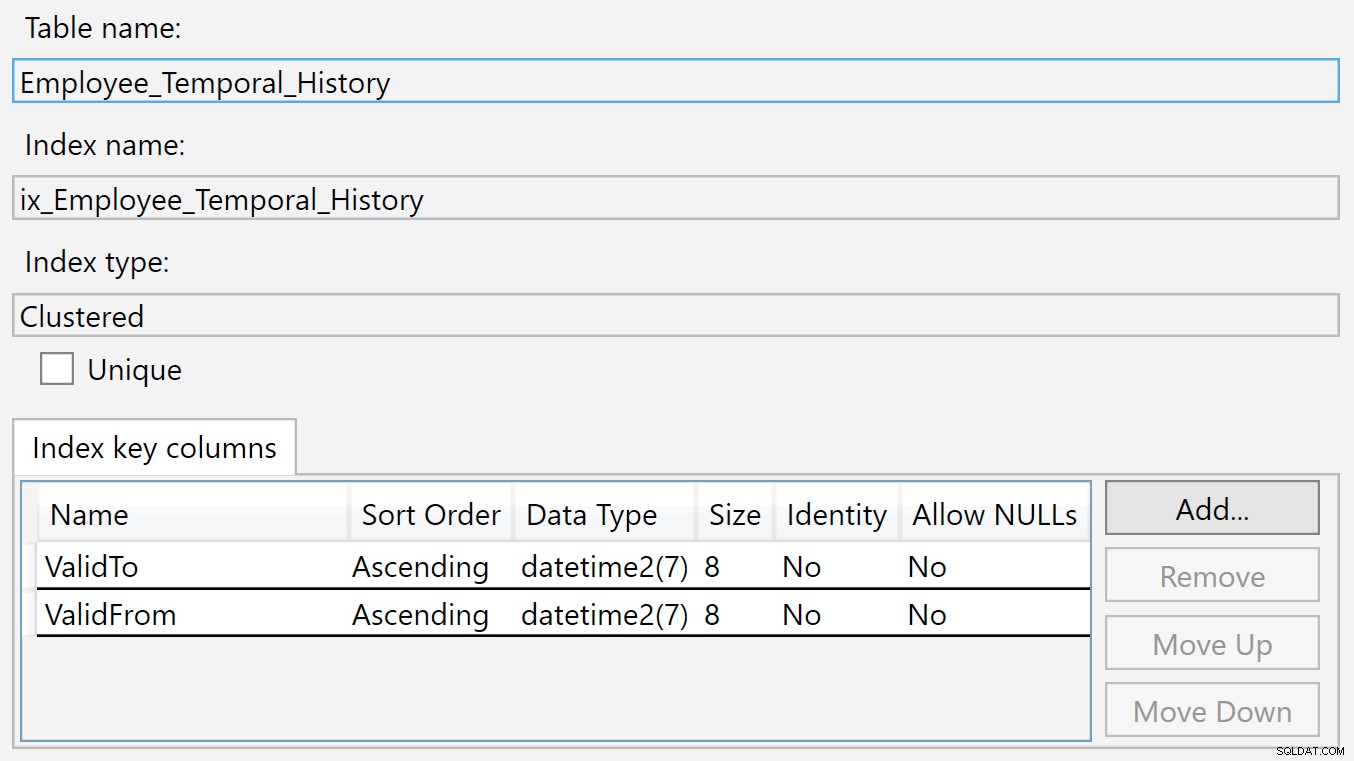
En ny række indsættes i denne historiktabel, når den ikke længere er gyldig i hovedtabellen, fordi den lige er blevet slettet eller ændret. Værdierne i ValidTo kolonne er naturligt udfyldt med det aktuelle tidspunkt, så ValidTo fungerer som en stigende nøgle, som en identitetskolonne, så nye indsættelser vises i slutningen af b-træstrukturen.
Men hvordan fungerer dette, når du vil forespørge i tabellen?
Hvis vi ønsker at forespørge i vores tabel om, hvad der var aktuelt på et bestemt tidspunkt, så skal vi bruge en forespørgselsstruktur som:
VÆLG * FRA HumanResources.Employee_TemporalFOR SYSTEM_TIME SOM AF '20160612 11:22';
Denne forespørgsel skal sammenkæde de relevante rækker fra hovedtabellen med de relevante rækker fra historiktabellen.
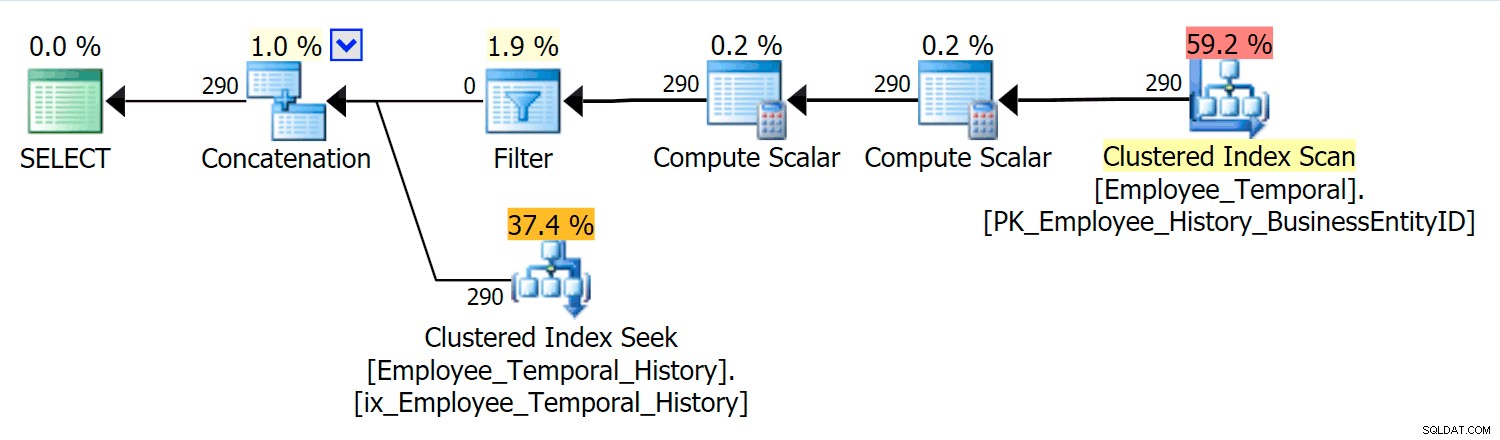
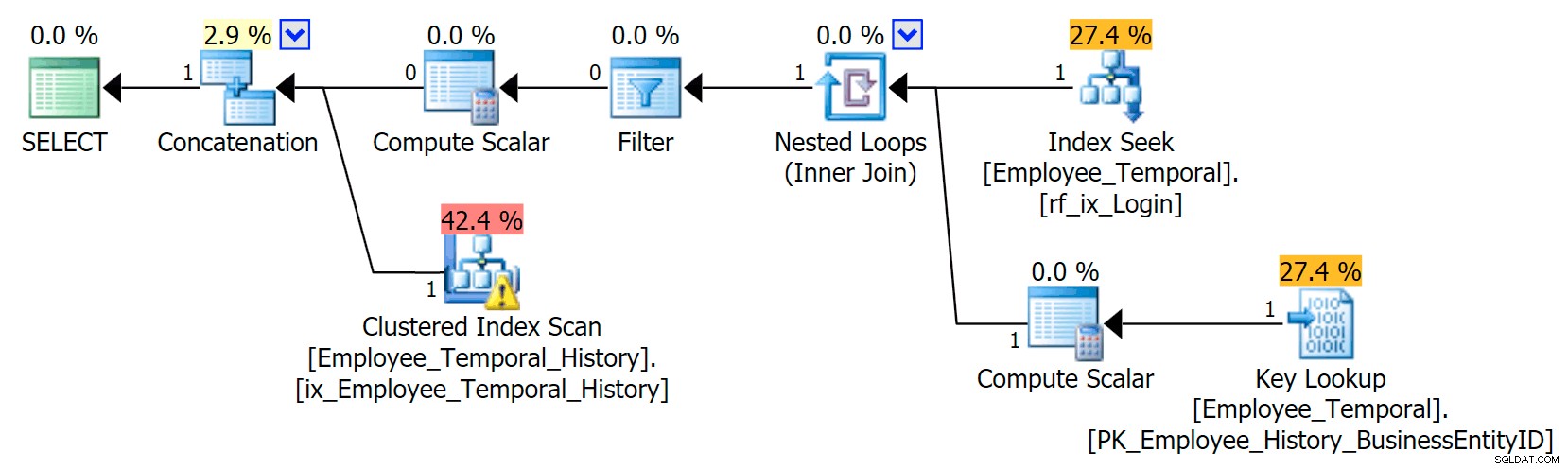
I dette scenarie var de rækker, der var gyldige i det øjeblik, jeg valgte, alle fra historiktabellen, men ikke desto mindre ser vi en Clustered Index Scan mod hovedtabellen, som blev filtreret af en Filter-operator. Prædikatet for dette filter er:
[HumanResources].[Employee_Temporal].[ValidFrom] <='2016-06-12 11:22:00.0000000' OG [HumanResources].[Employee_Temporal].[ValidTo]> '62216-1:2016 :00.0000000'
Lad os gense dette om et øjeblik.
Clustered Index Seek på historiktabellen skal helt klart udnytte et Seek-prædikat på ValidTo. Starten på søgningens rækkeviddescanning er HumanResources.Employee_Temporal_History.ValidTo > Scalar Operator('2016-06-12 11:22:00') , men der er ingen End, fordi hver række, der har en ValidTo efter den tid, vi bekymrer os om, er en kandidatrække, og skal testes for en passende ValidFrom værdi af Residual Predicate, som er HumanResources.Employee_Temporal_History.ValidFrom <= '2016-06-12 11:22:00' .
Nu er intervaller svære at indeksere for; det er en kendt ting, der er blevet diskuteret på mange blogs. De mest effektive løsninger overvejer kreative måder at skrive forespørgsler på, men der er ikke indbygget sådanne smarte i Temporal Tables. Du kan dog også sætte indekser på andre kolonner, såsom på ValidFrom, eller endda have indekser, der matcher de typer forespørgsler, du måtte have i hovedtabellen. Med et klynget indeks som en sammensat nøgle på begge ValidTo og ValidFrom , bliver disse to kolonner inkluderet i hver anden kolonne, hvilket giver en god mulighed for nogle resterende prædikattest.
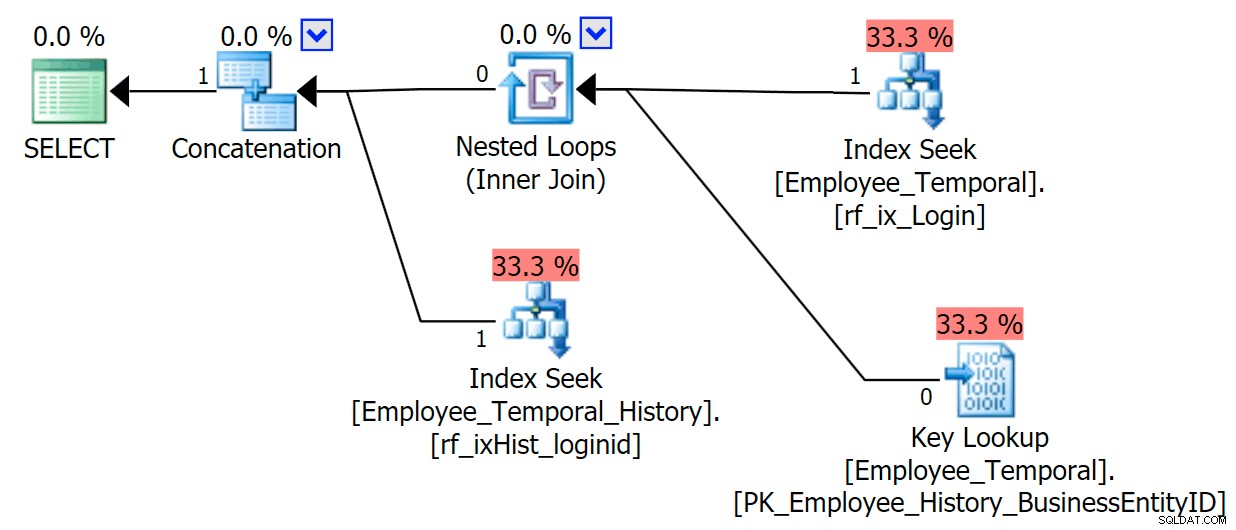
Hvis jeg ved, hvilket loginid jeg er interesseret i, danner min plan en anden form.
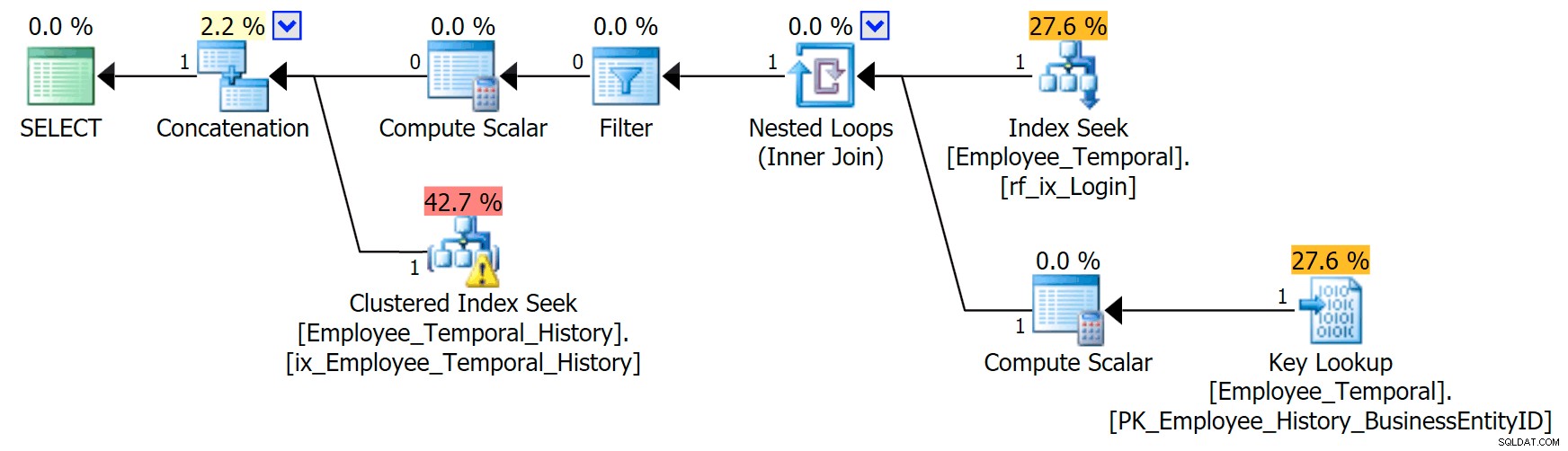
Den øverste gren af sammenkædningsoperatoren ligner før, selvom denne filteroperator er gået ind i kampen for at fjerne alle rækker, der ikke er gyldige, men den grupperede indekssøgning på den nederste gren har en advarsel. Dette er en advarsel om resterende prædikat, ligesom eksemplerne i et tidligere indlæg af mit. Det er i stand til at filtrere til poster, der er gyldige indtil et tidspunkt efter det tidspunkt, vi bekymrer os om, men Residual Predicate filtrerer nu til LoginID samt ValidFrom .
[HumanResources].[Employee_Temporal_History].[ValidFrom] <='2016-06-12 11:22:00.0000000' OG [HumanResources].[Employee_Temporal_History] =.['Login-ID'0] /pre>Ændringer i rob0s rækker vil være en lille del af rækkerne i historikken. Denne kolonne vil ikke være unik som i hovedtabellen, fordi rækken kan være blevet ændret flere gange, men der er stadig en god kandidat til indeksering.
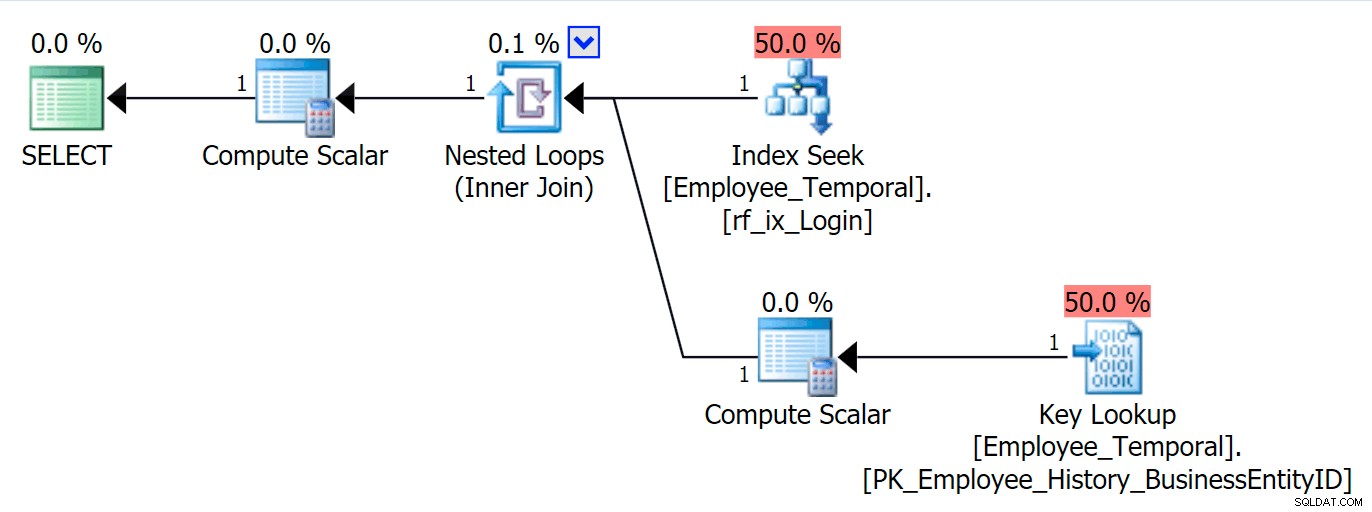
OPRET INDEX rf_ixHist_loginidON HumanResources.Employee_Temporal_History(LoginID);Dette nye indeks har en bemærkelsesværdig effekt på vores plan.
Det har nu ændret vores Clustered Index Seek til en Clustered Index Scan!!
Du kan se, Query Optimizer finder nu ud af, at den bedste ting at gøre ville være at bruge det nye indeks. Men det beslutter også, at indsatsen med at skulle lave opslag for at få alle de andre kolonner (fordi jeg spurgte om alle kolonner) simpelthen ville være for meget arbejde. Vippepunktet blev nået (desværre en forkert antagelse i dette tilfælde), og der blev valgt en Clustered Index SCAN i stedet. Selvom uden det ikke-klyngede indeks ville den bedste mulighed have været at bruge en Clustered Index Seek, når det ikke-clusterede indeks er blevet overvejet og afvist af tipping point-årsager, vælger den at scanne.
Frustrerende nok har jeg kun lige oprettet dette indeks, og dets statistikker burde være gode. Det burde vide, at en søgning, der kræver præcis ét opslag, burde være bedre end en Clustered Index Scan (kun ved statistik – hvis du troede, at den skulle vide dette, fordi
LoginIDer unik i hovedtabellen, husk at det måske ikke altid har været det). Så jeg formoder, at opslag i historietabeller bør undgås, selvom jeg ikke har forsket ret nok i dette endnu.Hvis vi nu kun skulle forespørge på kolonner, der vises i vores ikke-klyngede indeks, ville vi få meget bedre adfærd. Nu hvor der ikke kræves opslag, er vores nye indeks på historiktabellen med glæde brugt. Den skal stadig anvende et restprædikat baseret på kun at kunne filtrere til
LoginIDogValidTo, men det opfører sig meget bedre end at falde ind i en Clustered Index Scan.VÆLG LoginID, ValidFrom, ValidToFROM HumanResources.Employee_TemporalFOR SYSTEM_TIME SOM AF '20160612 11:22'WHERE LoginID =N'adventure-works\rob0'
Så indekser dine historietabeller på ekstra måder, i betragtning af hvordan du vil forespørge på dem. Inkluder de nødvendige kolonner for at undgå opslag, fordi du virkelig undgår scanninger.
Disse historietabeller kan vokse sig store, hvis data ændres ofte. Så vær opmærksom på, hvordan de bliver håndteret. Den samme situation opstår, når du bruger den anden
FOR SYSTEM_TIMEkonstruktioner, så du bør (som altid) gennemgå de planer, dine forespørgsler producerer, og indeksere for at sikre, at du er godt positioneret til at udnytte, hvad der er en meget kraftfuld funktion i SQL Server 2016.