Amazon Relational Database Service (AWS RDS) er en fuldt administreret databasetjeneste, som kan understøtte flere databasemotorer. Blandt de understøttede er PostgreSQL, MySQL og MariaDB. ClusterControl, på den anden side, er en databasestyrings- og automatiseringssoftware, som også understøtter backup-håndtering til PostgreSQL, MySQL og MariaDB open source-databaser.
Mens RDS er blevet bredt omfavnet af mange virksomheder, er nogle måske ikke bekendt med, hvordan deres Point-in-time Recovery (PITR) fungerer, og hvordan det kan bruges.
Flere af databasemotorerne, der bruges af Amazon RDS, har særlige overvejelser ved gendannelse fra et bestemt tidspunkt, og i denne blog vil vi dække, hvordan det fungerer for PostgreSQL, MySQL og MariaDB. Vi vil også sammenligne, hvordan den adskiller sig med PITR-funktionen i ClusterControl.
Hvad er Point-in-Time Recovery (PITR)
Hvis du endnu ikke er bekendt med Disaster Recovery Planning (DRP) eller Business Continuity Planning (BCP), bør du vide, at PITR er en af de vigtige standardpraksis for databasestyring. Som nævnt i vores tidligere blog involverer Point In Time Recovery (PITR) gendannelse af databasen på ethvert givet tidspunkt i fortiden. For at kunne gøre dette, skal vi gendanne en fuld sikkerhedskopi, og derefter finder PITR sted ved at anvende alle de ændringer, der skete på et bestemt tidspunkt, du vil gendanne.
Point-in-time Recovery (PITR) med AWS RDS
AWS RDS håndterer PITR anderledes end den traditionelle måde, der er almindelig for en on-prem database. Slutresultatet deler det samme koncept, men med AWS RDS er den fulde backup et øjebliksbillede, det anvender derefter PITR (som er gemt i S3), og lancerer derefter en ny (anden) databaseinstans.
Den almindelige måde kræver, at du enten bruger en logisk (ved hjælp af pg_dump, mysqldump, mydumper) eller en fysisk (Percona Xtrabackup, Mariabackup, pg_basebackup, pg_backrest) til din fulde backup, før du anvender PITR.
AWS RDS vil kræve, at du starter en ny DB-instans, hvorimod den traditionelle tilgang giver dig mulighed for fleksibelt at gemme PITR'en på den samme databaseknude, hvor sikkerhedskopieringen blev taget, eller målrette mod en anden (eksisterende) DB-instans, der skal gendannes eller til en ny DB-instans.
Ved oprettelse af din AWS RDS-instans vil automatiske sikkerhedskopier blive aktiveret. Amazon RDS udfører automatisk et fuldt dagligt øjebliksbillede af dine data. Snapshot-planer kan indstilles under oprettelsen i dit foretrukne backupvindue. Mens automatiserede sikkerhedskopier er slået til, fanger AWS også transaktionslogfiler til Amazon S3 hvert 5. minut og registrerer alle dine DB-opdateringer. Når du starter en punkt-i-tidsgendannelse, anvendes transaktionslogfiler til den mest passende daglige backup for at gendanne din DB-instans til det specifikke anmodede tidspunkt.
Sådan anvender du en PITR med AWS RDS
Anvendelse af PITR kan gøres på tre forskellige måder. Du kan bruge AWS Management Console, AWS CLI eller Amazon RDS API, når DB-instansen er tilgængelig. Du skal også tage i betragtning, at transaktionsloggene registreres hvert femte minut, som derefter gemmes i AWS S3.
Når du gendanner en DB-instans, anvendes standard DB-sikkerhedsgruppen (SG) på den nye DB-instans. Hvis du har brug for den tilpassede db SG, kan du udtrykkeligt definere dette ved at bruge AWS Management Console, AWS CLI modify-db-instance-kommandoen eller Amazon RDS API ModifyDBInstance-operationen, efter at DB-instansen er tilgængelig.
PITR kræver, at du skal identificere den seneste gendannelsestid for en DB-instans. For at gøre dette kan du bruge kommandoen AWS CLI describe-db-instances og se på den returnerede værdi i feltet LatestRestorableTime for DB-forekomsten. For eksempel
[example@sqldat.com ~]# aws rds describe-db-instances --db-instance-identifier database-s9s-mysql|grep LatestRestorableTime
"LatestRestorableTime": "2020-05-08T07:25:00+00:00", Anvendelse af PITR med AWS-konsol
For at anvende PITR i AWS-konsol skal du logge ind på AWS-konsol → gå til Amazon RDS → Databaser → Vælg (eller klik) din ønskede DB-instans, og klik derefter på Handlinger. Se nedenfor,
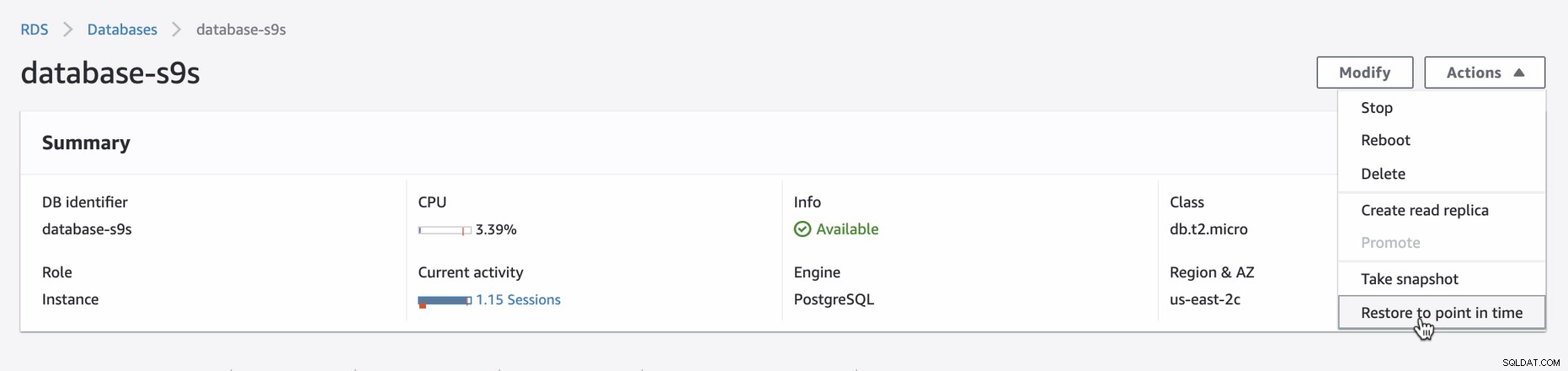
Når du forsøger at gendanne via PITR, giver konsollens brugerflade besked om, hvad der er den seneste gendannelsestid, du kan indstille. Du kan bruge den seneste gendannelsestid eller angive din ønskede måldato og -klokkeslæt. Se nedenfor:
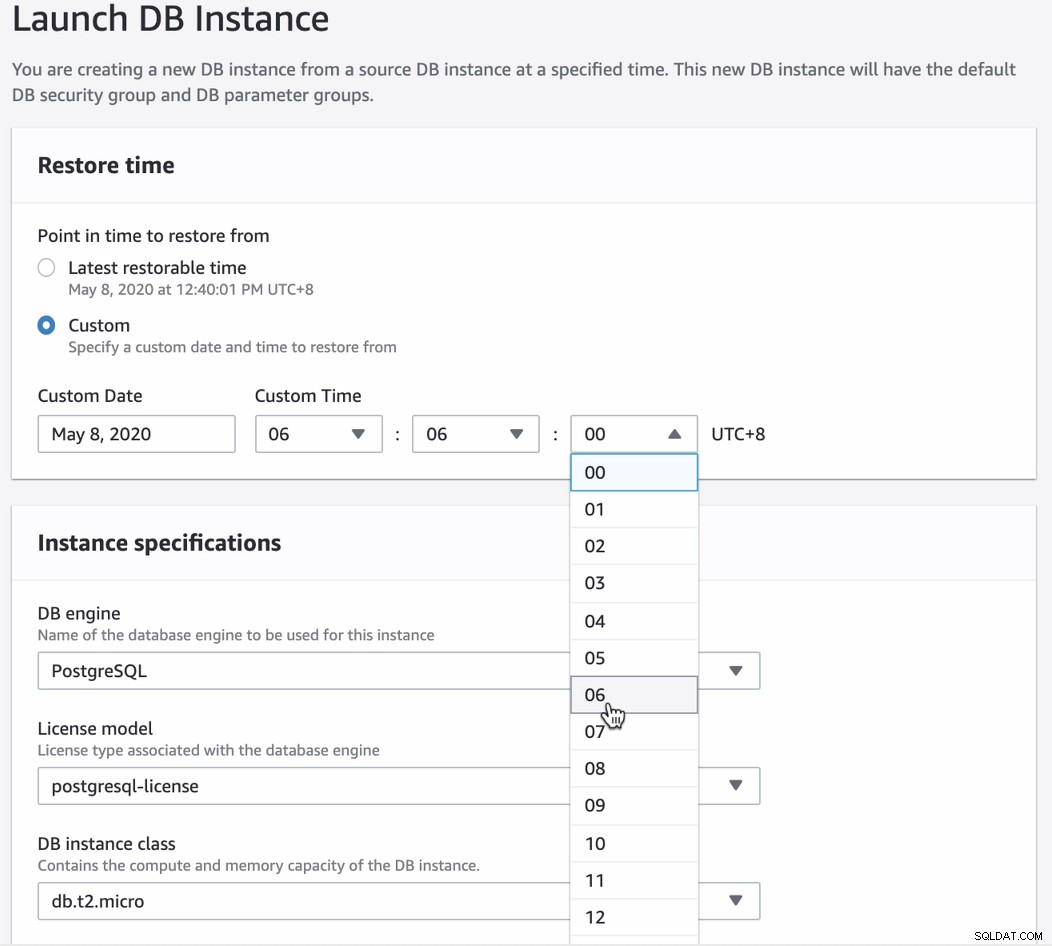
Det er ret nemt at følge, men det kræver, at du er opmærksom og udfylder de ønskede specifikationer, du skal bruge for at den nye instans kan lanceres.
Anvendelse af PITR med AWS CLI
At bruge AWS CLI kan være ret praktisk, især hvis du har brug for at inkorporere dette med dine automatiseringsværktøjer til din CI/CD-pipeline. For at gøre dette kan du starte med,
[example@sqldat.com ~]# aws rds restore-db-instance-to-point-in-time \
> --source-db-instance-identifier database-s9s-mysql \
> --target-db-instance-identifier database-s9s-mysql-pitr \
> --restore-time 2020-05-08T07:30:00+00:00
{
"DBInstance": {
"DBInstanceIdentifier": "database-s9s-mysql-pitr",
"DBInstanceClass": "db.t2.micro",
"Engine": "mysql",
"DBInstanceStatus": "creating",
"MasterUsername": "admin",
"DBName": "s9s",
"AllocatedStorage": 18,
"PreferredBackupWindow": "00:00-00:30",
"BackupRetentionPeriod": 7,
"DBSecurityGroups": [],
"VpcSecurityGroups": [
{
"VpcSecurityGroupId": "sg-xxxxx",
"Status": "active"
}
],
"DBParameterGroups": [
{
"DBParameterGroupName": "default.mysql5.7",
"ParameterApplyStatus": "in-sync"
}
],
"DBSubnetGroup": {
"DBSubnetGroupName": "default",
"DBSubnetGroupDescription": "default",
"VpcId": "vpc-f91bdf90",
"SubnetGroupStatus": "Complete",
"Subnets": [
{
"SubnetIdentifier": "subnet-exxxxx",
"SubnetAvailabilityZone": {
"Name": "us-east-2a"
},
"SubnetStatus": "Active"
},
{
"SubnetIdentifier": "subnet-xxxxx",
"SubnetAvailabilityZone": {
"Name": "us-east-2c"
},
"SubnetStatus": "Active"
},
{
"SubnetIdentifier": "subnet-xxxxxx",
"SubnetAvailabilityZone": {
"Name": "us-east-2b"
},
"SubnetStatus": "Active"
}
]
},
"PreferredMaintenanceWindow": "fri:06:01-fri:06:31",
"PendingModifiedValues": {},
"MultiAZ": false,
"EngineVersion": "5.7.22",
"AutoMinorVersionUpgrade": true,
"ReadReplicaDBInstanceIdentifiers": [],
"LicenseModel": "general-public-license",
"OptionGroupMemberships": [
{
"OptionGroupName": "default:mysql-5-7",
"Status": "pending-apply"
}
],
"PubliclyAccessible": true,
"StorageType": "gp2",
"DbInstancePort": 0,
"StorageEncrypted": false,
"DbiResourceId": "db-XXXXXXXXXXXXXXXXX",
"CACertificateIdentifier": "rds-ca-2019",
"DomainMemberships": [],
"CopyTagsToSnapshot": false,
"MonitoringInterval": 0,
"DBInstanceArn": "arn:aws:rds:us-east-2:042171833148:db:database-s9s-mysql-pitr",
"IAMDatabaseAuthenticationEnabled": false,
"PerformanceInsightsEnabled": false,
"DeletionProtection": false,
"AssociatedRoles": []
}
} Begge disse tilgange tager tid at oprette eller forberede databaseforekomsten, indtil den bliver tilgængelig og kan ses på listen over databaseforekomster i din AWS RDS-konsol.
AWS RDS PITR-begrænsninger
Når du bruger AWS RDS, er du bundet til dem som leverandør. Det kan være besværligt at flytte dine operationer ud af deres system. Her er nogle ting, du skal overveje:
- Niveauet af leverandørlås ved brug af AWS RDS
- Din eneste mulighed for at gendanne via PITR kræver, at du starter en ny instans, der kører på RDS
- Du kan på ingen måde gendanne ved hjælp af PITR-processen til en ekstern node, der ikke er i RDS
- Kræver, at du lærer og er fortrolig med deres værktøjer og sikkerhedsramme.
Sådan anvender du en PITR med ClusterControl
ClusterControl udfører PITR på en enkel, men ligetil måde (men kræver, at du skal aktivere eller indstille forudsætningerne, så PITR kan bruges). Som diskuteret tidligere fungerer PITR for ClusterControl anderledes end AWS RDS. Her er en liste over, hvor PITR kan anvendes ved hjælp af ClusterControl (fra version 1.7.6):
- Gælder efter den fulde backup baseret på de tilgængelige backupmetodeløsninger, som vi understøtter til PostgreSQL-, MySQL- og MariaDB-databaser.
- For PostgreSQL er det kun pg_basebackup backup-metoden, der understøttes og er kompatibel til at arbejde med PITR
- For MySQL eller MariaDB er kun xtrabackup/mariabackup backup-metoden understøttet og kompatibel til at arbejde med PITR
- Gælder for MySQL- eller MariaDB-databaser, PITR gælder kun, hvis kildenoden for den fulde backup er målknuden, der skal gendannes.
- MySQL- eller MariaDB-databaser kræver, at du har aktiveret binær logning
- Gælder for PostgreSQL-databaser, PITR gælder kun for den aktive master/primære og kræver, at du skal aktivere WAL-arkivering.
- PITR kan kun anvendes ved gendannelse af en eksisterende fuld sikkerhedskopi
Backup Management for ClusterControl kan anvendes til miljøer, hvor databaser ikke er fuldt administreret og kræver SSH-adgang, som er helt anderledes end AWS RDS. Selvom de deler det samme resultat, som er at gendanne data, kan de backupløsninger, der findes i ClusterControl, ikke anvendes i AWS RDS. ClusterControl understøtter heller ikke RDS så godt til styring og overvågning.
Brug af ClusterControl til PITR i PostgreSQL
Som tidligere nævnt af forudsætningerne for at udnytte PITR, skal du aktivere WAL-arkivering. Dette kan opnås ved at klikke på tandhjulsikonet som vist nedenfor:
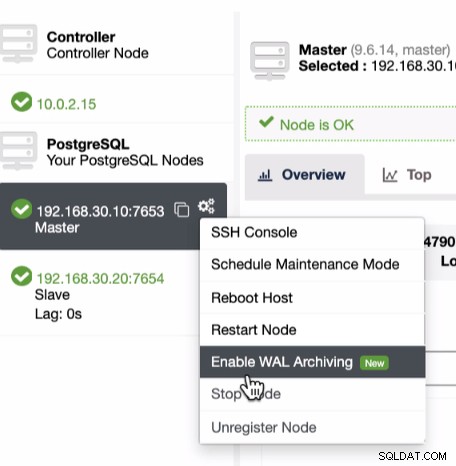
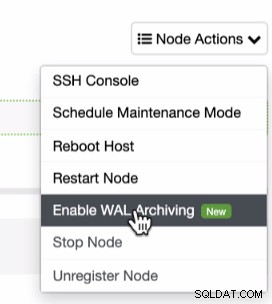
Da PITR kan anvendes lige efter en fuld sikkerhedskopiering, kan du kun køre find denne funktion under sikkerhedskopieringslisten, hvor du kan forsøge at gendanne en eksisterende sikkerhedskopi. For at gøre det vil sekvensen af skærmbilleder vise dig, hvordan du gør det:
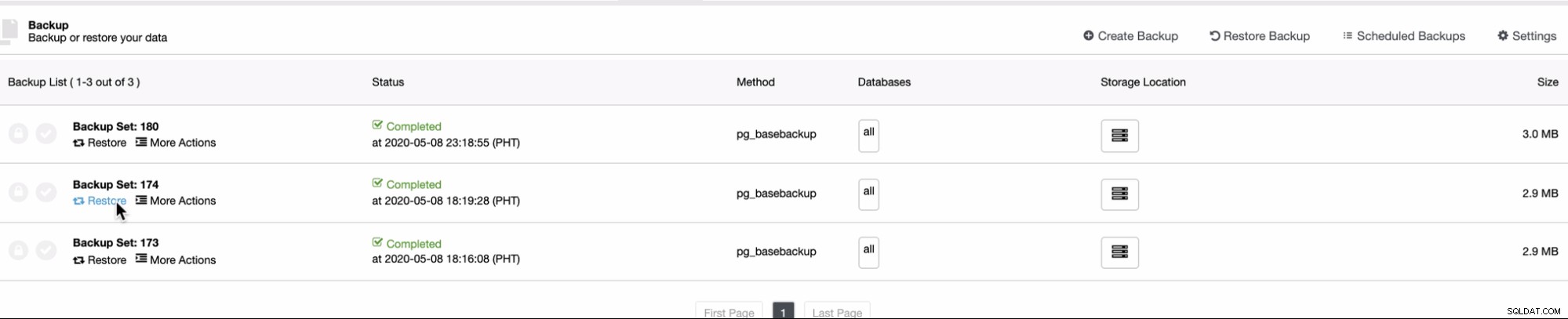
Gendan den derefter på den samme vært som kilden til sikkerhedskopieringen som taget ,
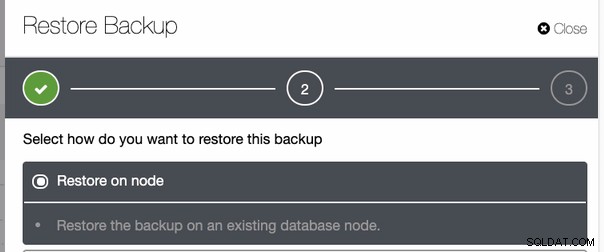
Så skal du blot angive dato og klokkeslæt,
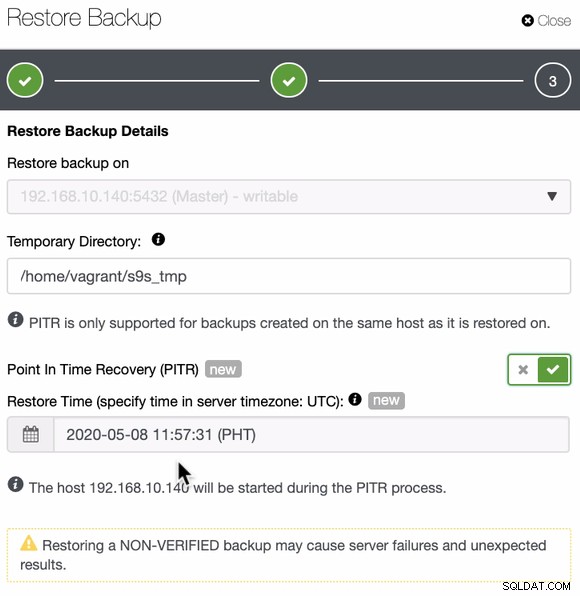
Når du er indstillet og angivet dato og klokkeslæt, vil ClusterControl derefter gendanne sikkerhedskopien anvender derefter PITR, når sikkerhedskopieringen er færdig. Du kan også bekræfte dette ved at inspicere jobaktivitetsloggene ligesom nedenfor,

Brug af ClusterControl til PITR i MySQL/MariaDB
PITR for MySQL eller MariaDB adskiller sig ikke fra den tilgang, vi har ovenfor for PostgreSQL. Der er dog ingen WAL-arkiveringsækvivalens eller en knap eller mulighed, du kan indstille, som kræves for at aktivere PITR-funktionaliteten. Da MySQL og MariaDB kræver, at en PITR kan anvendes ved hjælp af binære logfiler, kan dette i ClusterControl håndteres under fanen Administrer. Se nedenfor:
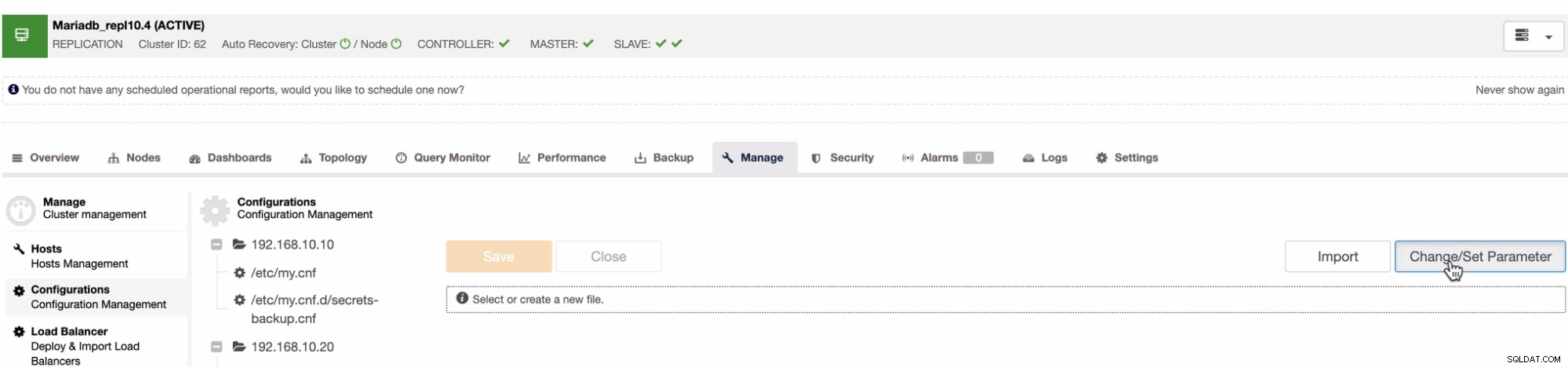
Angiv derefter log_bin-variablen med den tilsvarende booleske værdi. For eksempel
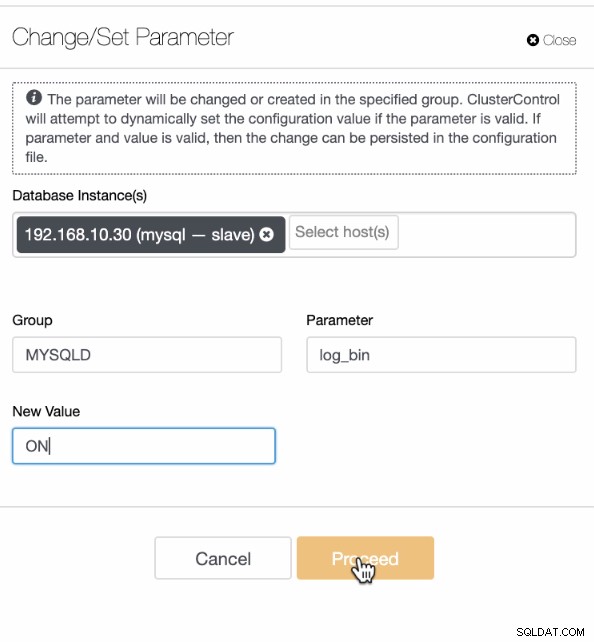
Når log_bin er indstillet på noden, skal du sikre dig, at du har den fulde backup taget på den samme node, hvor du også vil anvende PITR-processen. Dette står tidligere i forudsætningerne. Alternativt kan du også bare redigere konfigurationsfilerne (/etc/my.cnf eller /etc/mysql/my.cnf) og f.eks. tilføje log_bin=ON under [mysqld] sektionen.
Når binære logfiler er aktiveret, og en fuld backup er tilgængelig, kan du derefter udføre PITR-processen på samme måde som PostgreSQL UI, men med forskellige felter, som du kan udfylde. Du kan angive dato og klokkeslæt eller specificer baseret på binlogens fil og position (eller x &y position). Se nedenfor:
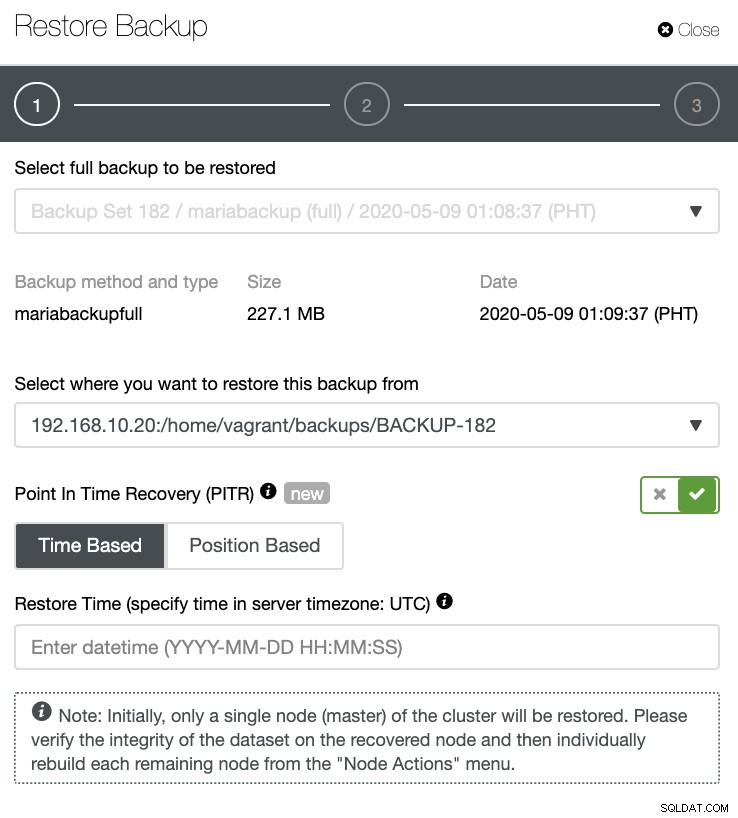
ClusterControl PITR-begrænsninger
Hvis du undrer dig over, hvad du kan og ikke kan gøre for PITR i ClusterControl, her er listen nedenfor:
- Der er ikke noget aktuelt s9s CLI-værktøj, som understøtter PITR-processen, så det er ikke muligt at automatisere eller integrere til din CI/CD-pipeline.
- Ingen PITR-understøttelse for eksterne noder
- Ingen PITR-understøttelse, når kilden til sikkerhedskopieringen er forskellig fra målknuden
- Der er ingen sådan periodisk meddelelse om, hvad der er den seneste periode, du kan ansøge om PITR
Konklusion
Begge værktøjer har forskellige tilgange og forskellige løsninger til målmiljøet. Det vigtigste er, at AWS RDS har sin egen PITR, som er hurtigere, men kun gælder, hvis din database er hostet under RDS, og du er bundet til en leverandørlås.
ClusterControl giver dig mulighed for frit at anvende PITR-processen til et hvilket som helst datacenter eller on-premise, så længe forudsætningerne tages i betragtning. Dets mål er at gendanne dataene. Uanset dens begrænsninger er det baseret på, hvordan du vil bruge løsningen i overensstemmelse med det arkitektoniske miljø, du bruger.