PostgreSQL-streamingreplikering er en fantastisk måde at skalere PostgreSQL-klynger på og gør det tilføjer høj tilgængelighed til dem. Som med enhver replikering er ideen, at slaven er en kopi af masteren, og at slaven konstant opdateres med de ændringer, der skete på masteren, ved hjælp af en form for replikeringsmekanisme.
Det kan ske, at slaven af en eller anden grund bliver ude af sync med masteren. Hvordan kan jeg bringe det tilbage til replikationskæden? Hvordan kan jeg sikre, at slaven igen er synkroniseret med masteren? Lad os tage et kig i dette korte blogindlæg.
Hvad er meget nyttigt, der er ingen måde at skrive på en slave, hvis den er i gendannelsestilstand. Du kan teste det sådan:
postgres=# SELECT pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
postgres=# CREATE DATABASE mydb;
ERROR: cannot execute CREATE DATABASE in a read-only transactionDet kan stadig ske, at slaven ville gå ude af sync med masteren. Datakorruption - hverken hardware eller software er uden fejl og problemer. Nogle problemer med diskdrevet kan udløse datakorruption på slaven. Nogle problemer med "vakuum"-processen kan resultere i, at data bliver ændret. Hvordan genoprettes fra den tilstand?
Genopbygning af slaven ved hjælp af pg_basebackup
Hovedtrinet er at klargøre slaven ved hjælp af data fra masteren. Da vi bruger streaming-replikering, kan vi ikke bruge logisk backup. Heldigvis er der et klar værktøj, der kan bruges til at sætte tingene op:pg_basebackup. Lad os se, hvad der ville være de trin, vi skal tage for at klargøre en slaveserver. For at gøre det klart, bruger vi PostgreSQL 12 til formålet med dette blogindlæg.
Udgangstilstanden er enkel. Vores slave replikerer ikke fra sin herre. Data, den indeholder, er beskadiget og kan ikke bruges eller stole på. Derfor vil det første skridt, vi vil gøre, være at stoppe PostgreSQL på vores slave og fjerne de data, den indeholder:
example@sqldat.com:~# systemctl stop postgresqlEller endda:
example@sqldat.com:~# killall -9 postgresLad os nu tjekke indholdet af postgresql.auto.conf-filen, vi kan bruge replikeringslegitimationsoplysninger gemt i den fil senere til pg_basebackup:
example@sqldat.com:~# cat /var/lib/postgresql/12/main/postgresql.auto.conf
# Do not edit this file manually!
# It will be overwritten by the ALTER SYSTEM command.
promote_trigger_file='/tmp/failover_5432.trigger'
recovery_target_timeline=latest
primary_conninfo='application_name=pgsql_0_node_1 host=10.0.0.126 port=5432 user=cmon_replication password=qZnVoV7LV97CFX9F'Vi er interesserede i den bruger og adgangskode, der bruges til at opsætte replikeringen.
Endelig kan vi fjerne dataene:
example@sqldat.com:~# rm -rf /var/lib/postgresql/12/main/*Når dataene er fjernet, skal vi bruge pg_basebackup for at få dataene fra masteren:
example@sqldat.com:~# pg_basebackup -h 10.0.0.126 -U cmon_replication -Xs -P -R -D /var/lib/postgresql/12/main/
Password:
waiting for checkpointDe flag, vi brugte, har følgende betydning:
- -Xs: vi vil gerne streame WAL, mens sikkerhedskopien oprettes. Dette hjælper med at undgå problemer med at fjerne WAL-filer, når du har et stort datasæt.
- -P: vi vil gerne se forløbet af sikkerhedskopieringen.
- -R: vi vil have pg_basebackup til at oprette standby.signal-fil og forberede postgresql.auto.conf-fil med forbindelsesindstillinger.
pg_basebackup vil vente på kontrolpunktet, før du starter sikkerhedskopieringen. Hvis det tager for lang tid, kan du bruge to muligheder. For det første er det muligt at indstille kontrolpunktstilstand til hurtig i pg_basebackup ved at bruge '-c fast' mulighed. Alternativt kan du tvinge kontrolpunkter ved at udføre:
postgres=# CHECKPOINT;
CHECKPOINTPå den ene eller den anden måde starter pg_basebackup. Med -P-flaget kan vi spore fremskridtene:
416906/1588478 kB (26%), 0/1 tablespaceceaceNår sikkerhedskopien er klar, er det eneste, vi skal gøre, at sikre, at indholdet i databiblioteket har den korrekte bruger og gruppe tildelt - vi udførte pg_basebackup som 'root', derfor vil vi ændre det til 'postgres' ':
example@sqldat.com:~# chown -R postgres.postgres /var/lib/postgresql/12/main/Det er alt, vi kan starte slaven, og den burde begynde at replikere fra masteren.
example@sqldat.com:~# systemctl start postgresqlDu kan dobbelttjekke replikeringsforløbet ved at udføre følgende forespørgsel på masteren:
postgres=# SELECT * FROM pg_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state | reply_time
-------+----------+------------------+------------------+-------------+-----------------+-------------+-------------------------------+--------------+-----------+------------+------------+------------+------------+-----------+-----------+------------+---------------+------------+-------------------------------
23565 | 16385 | cmon_replication | pgsql_0_node_1 | 10.0.0.128 | | 51554 | 2020-02-27 15:25:00.002734+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:32.594213+00
11914 | 16385 | cmon_replication | 12/main | 10.0.0.127 | | 25058 | 2020-02-28 13:42:09.160576+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:42.41722+00
(2 rows)Som du kan se, replikerer begge slaver korrekt.
Genopbygning af slaven ved hjælp af ClusterControl
Hvis du er en ClusterControl-bruger, kan du nemt opnå præcis det samme blot ved at vælge en mulighed fra brugergrænsefladen.
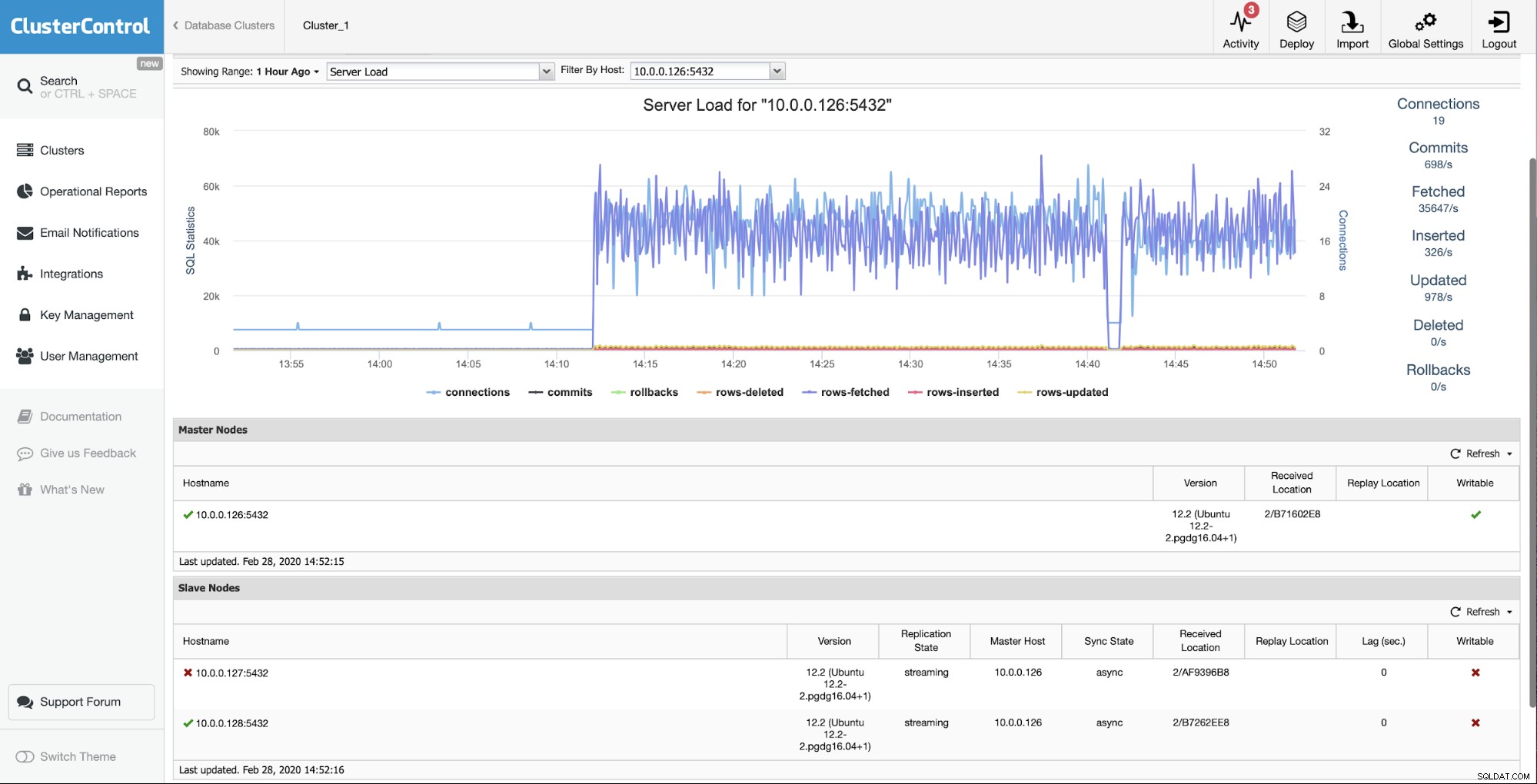
Udgangssituationen er, at en af slaverne (10.0.0.127) er virker ikke, og det replikerer ikke. Vi vurderede, at ombygningen er den bedste løsning for os.
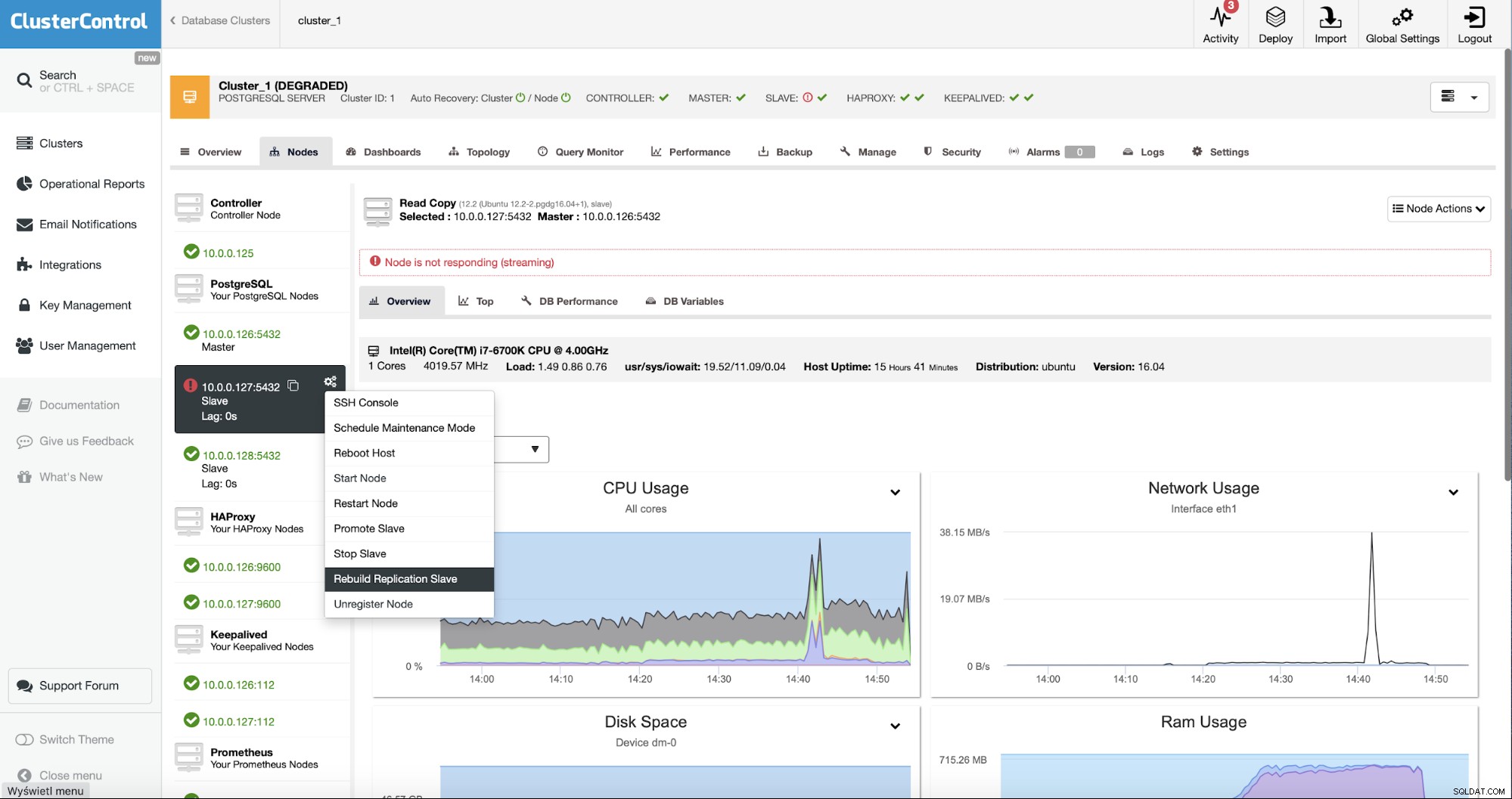
Som ClusterControl-brugere skal vi kun gå til "Nodes" ”-fanen og kør “Genopbyg replikeringsslave”-job.
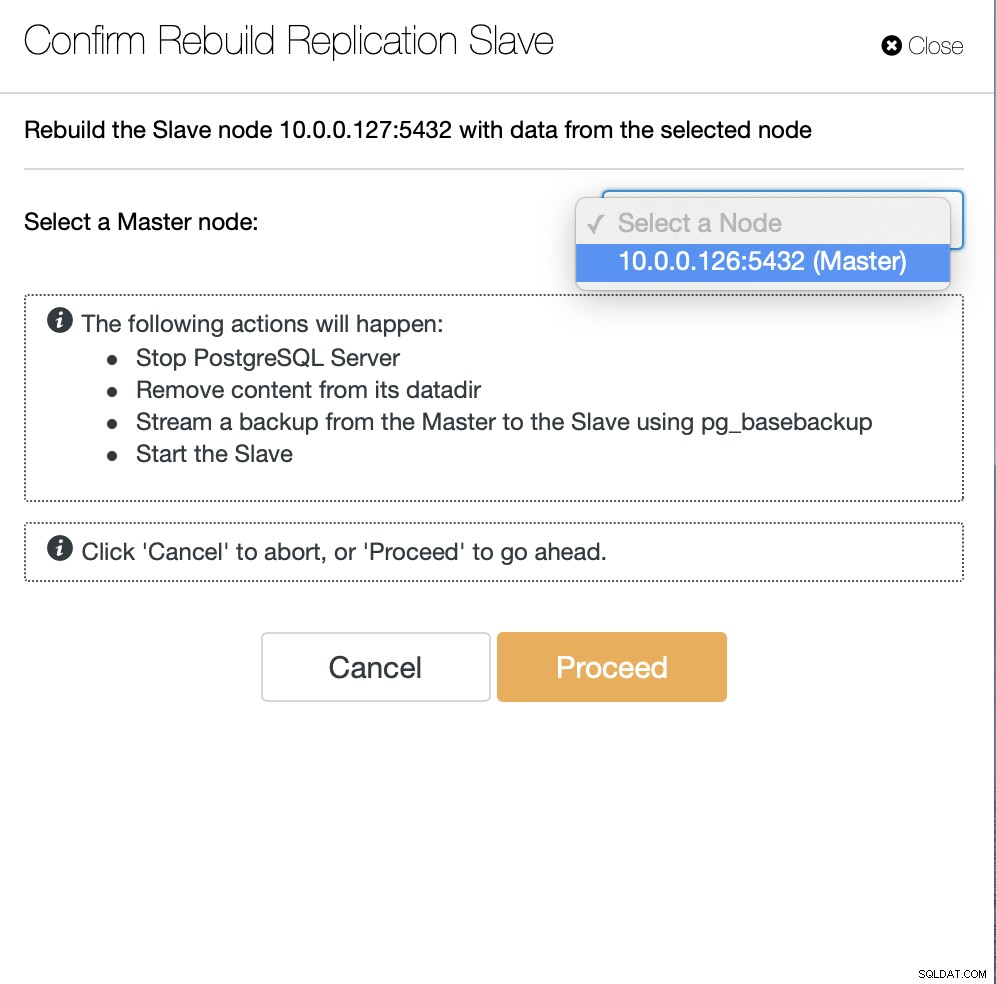
Dernæst skal vi vælge den node, vi skal genopbygge slaven fra, og det er alle. ClusterControl vil bruge pg_basebackup til at konfigurere replikeringsslaven og konfigurere replikeringen, så snart dataene er overført.
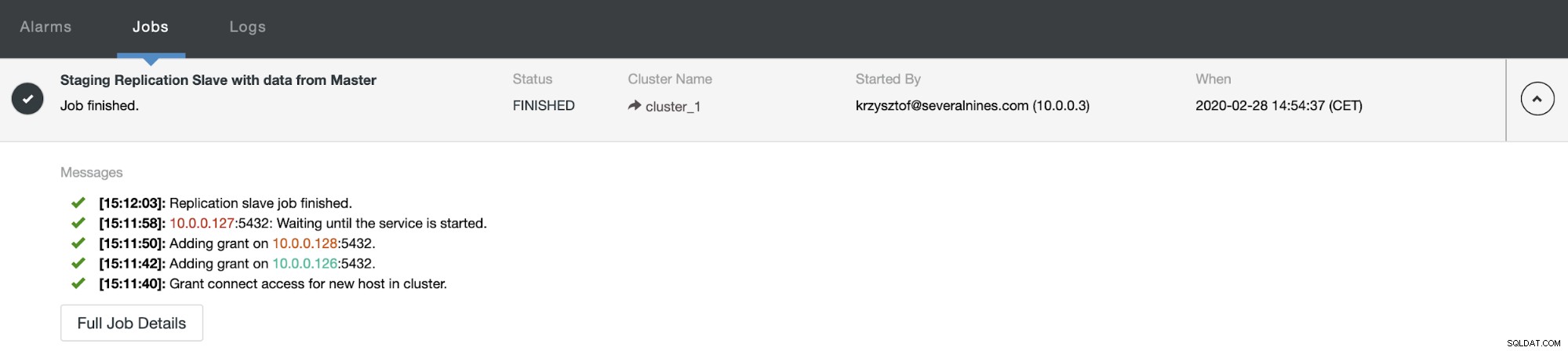
Efter nogen tid er opgaven fuldført, og slaven er tilbage i replikeringskæden:
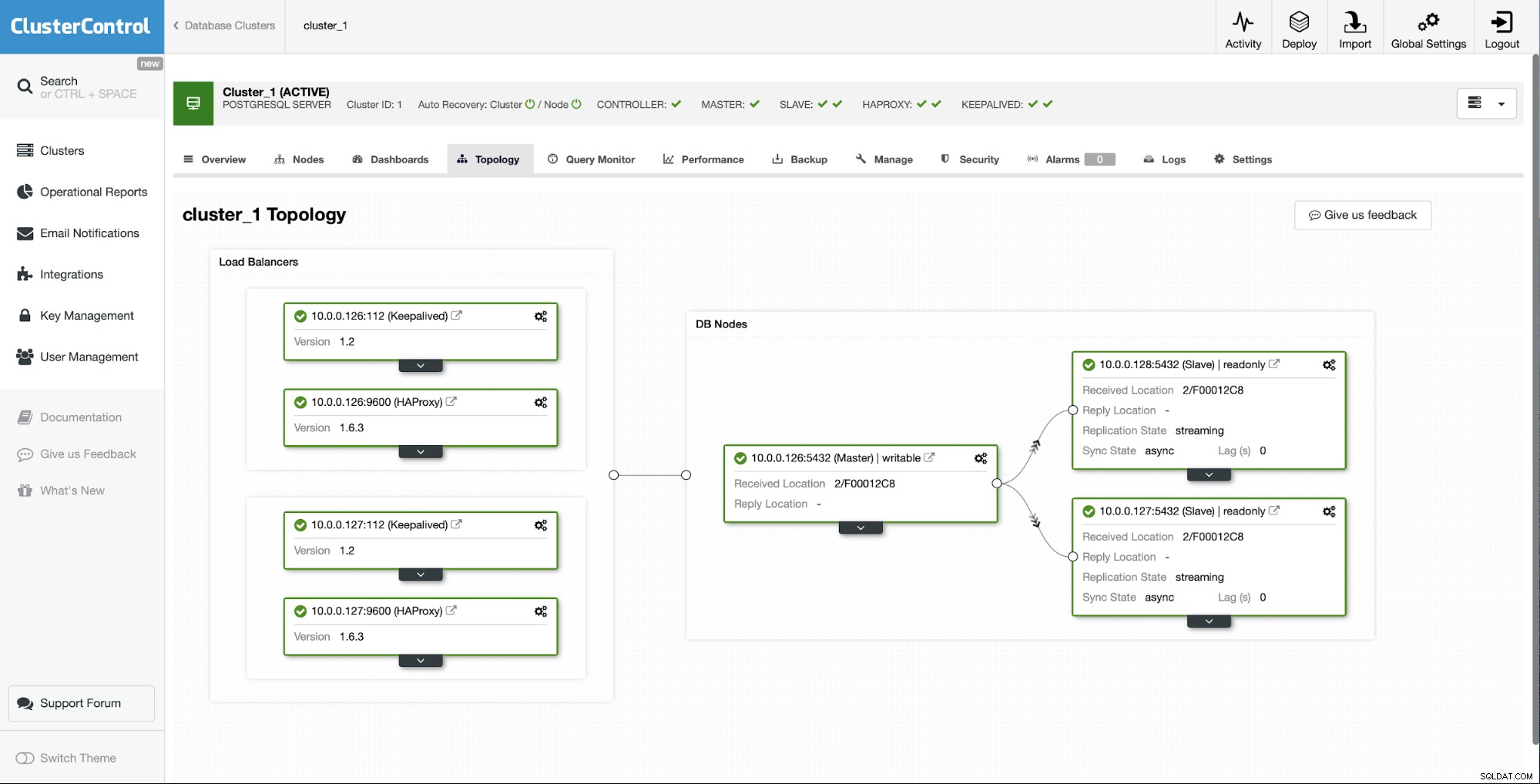
Som du kan se, lykkedes det med blot et par klik, takket være ClusterControl, at genopbygge vores mislykkede slave og bringe den tilbage til klyngen.