Da høj tilgængelighed er altafgørende i nutidens forretningsvirkelighed, er et af de mest almindelige scenarier for brugere at håndtere, hvordan man sikrer, at databasen altid vil være tilgængelig for applikationen.
Enhver tjenesteudbyder har en arvelig risiko for afbrydelse af tjenesten, og derfor er et af de skridt, der kan tages, at stole på flere udbydere for at afhjælpe risikoen og yderligere redundans.
Skytjenesteudbydere er ikke anderledes - de kan fejle, og du bør planlægge dette på forhånd. Hvilke muligheder er tilgængelige for MariaDB Cluster? Lad os tage et kig på det i dette blogindlæg.
MariaDB-databaseklynger i multi-sky-miljøer
Hvis SLA foreslået af én cloud-tjenesteudbyder ikke er nok, er der altid en mulighed for at oprette et katastrofegendannelsessted uden for denne udbyder. Takket være dette kan du altid skifte til en anden udbyder og holde din database oppe og tilgængelig, når en af cloud-udbyderne oplever en vis serviceforringelse.
Et af de problemer, der er typiske for multi-cloud-opsætninger, er netværksforsinkelsen, der er uundgåelig, hvis vi taler om større afstande eller generelt flere geografisk adskilte lokationer. Lyshastigheden er ret høj, men den er begrænset, hvert hop, hver router tilføjer også en vis latenstid til netværksinfrastrukturen.
MariaDB Cluster fungerer godt på netværk med lav latency. Det er en kvorum-baseret klynge, hvor hurtig kommunikation mellem alle noder er påkrævet for at holde driften glat. Forøgelse i netværksforsinkelse vil påvirke klyngedriften, især skrivningens ydeevne. Der er flere måder, hvorpå dette problem kan løses.
Først har vi en mulighed for at bruge separate klynger forbundet ved hjælp af asynkrone replikeringslinks. Dette giver os mulighed for næsten at glemme latens, fordi asynkron replikering er væsentligt bedre egnet til at arbejde i miljøer med høj latency.
En anden mulighed er, at givet netværk med lav latency mellem datacentre, kan du stadig være helt i orden at køre en MariaDB-klynge, der spænder over flere datacentre. Når alt kommer til alt, betyder flere datacentre ikke altid store afstande geografisk - du kan lige så godt bruge flere udbydere, der er placeret inden for det samme storbyområde, forbundet med hurtige netværk med lav latency. Så taler vi om latensstigning til højst titusinder af millisekunder, bestemt ikke hundredvis. Det hele afhænger af ansøgningen, men en sådan stigning kan være acceptabel.
Asynkron replikering mellem MariaDB-klynger
Lad os tage et hurtigt kig på den asynkrone tilgang. Ideen er enkel - to klynger forbundet med hinanden ved hjælp af asynkron replikering.
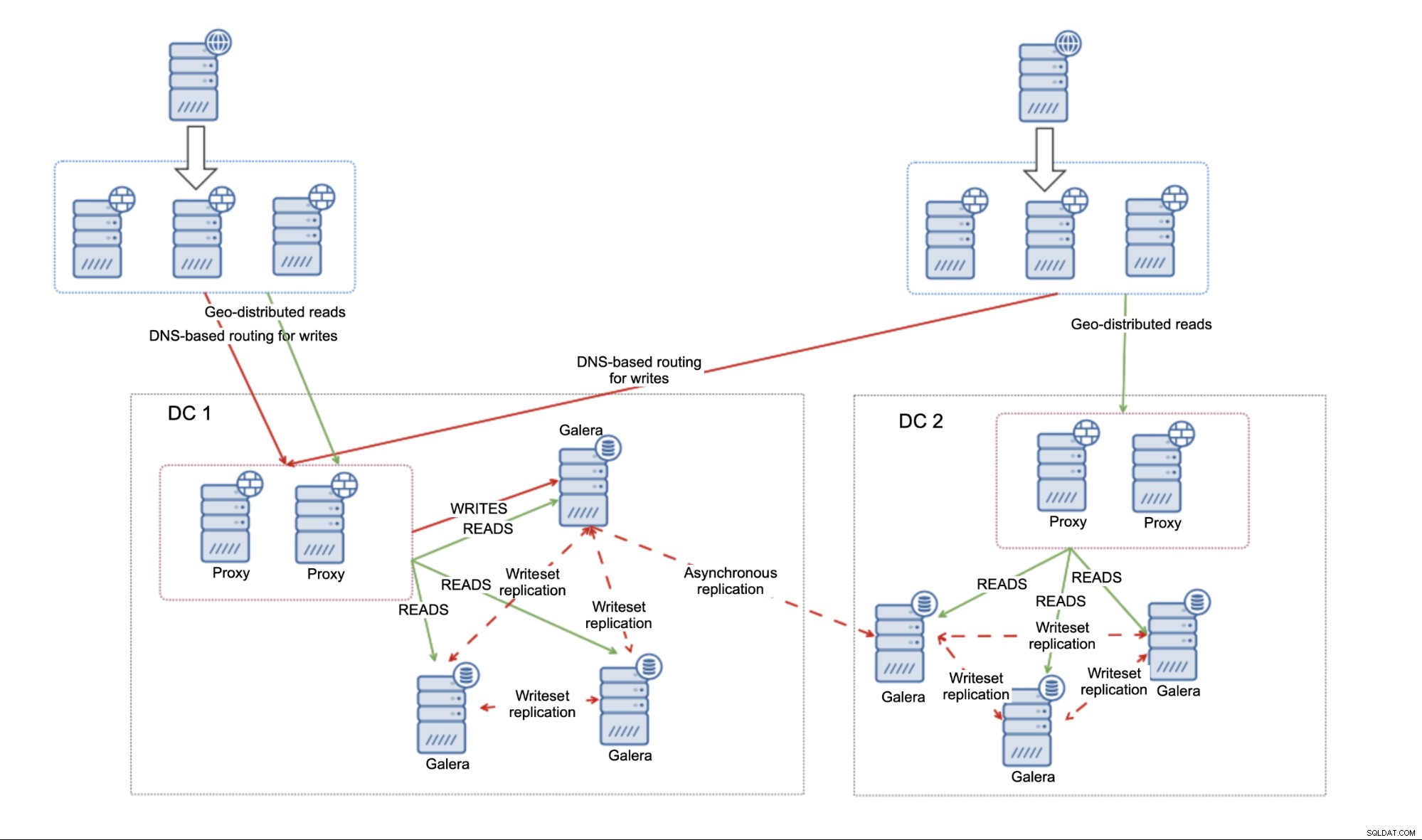
Dette kommer med flere begrænsninger. For det første skal du beslutte dig for, om du vil bruge multi-master, eller om du kun vil sende al trafik til ét datacenter. Vi vil anbefale at holde sig væk fra at skrive til begge datacentre og bruge master - master replikering. Dette kan føre til alvorlige problemer, hvis du ikke udviser forsigtighed.
Hvis du beslutter dig for at bruge den aktive - passive opsætning, vil du sandsynligvis implementere en slags DNS-baseret routing for skrivninger for at sikre, at dine applikationsservere altid vil oprette forbindelse til et sæt proxyer placeret i det aktive datacenter. Dette kan opnås enten ved bogstaveligt talt DNS-indtastning, der ville blive ændret, når failover er påkrævet, eller det kan gøres gennem en slags serviceopdagelsesløsning som Consul eller etcd.
Den største ulempe ved det miljø, der er bygget ved hjælp af den asynkrone replikering, er manglen på evne til at håndtere netværksopdelinger mellem datacentre. Dette er nedarvet fra replikationen - uanset hvad du vil linke til replikationen (single noder, MariaDB Clusters), er der ingen måde at komme uden om, at replikering ikke er kvorumsbevidst. Der er ingen mekanisme til at spore nodernes tilstand og forstå billedet på højt niveau af hele topologien. Som et resultat, når forbindelsen mellem to datacentre går ned, ender du med to separate MariaDB-klynger, der ikke er forbundet, og som begge er klar til at acceptere trafik. Det vil være op til brugeren at definere, hvad der skal gøres i et sådant tilfælde. Det er muligt at implementere yderligere værktøjer, der vil overvåge databasernes tilstand udefra (dvs. fra det tredje datacenter) og derefter foretage handlinger (eller ikke foretage handlinger) baseret på disse oplysninger. Det er også muligt at samle værktøjer, der vil dele infrastrukturen med databaser, men som ville være klyngebevidste og kunne spore tilstanden af datacenterforbindelsen og blive brugt som kilden til sandheden for de scripts, der ville styre miljøet. For eksempel kan ClusterControl implementeres i en klynge med tre noder, node pr. datacenter, der bruger RAFT-protokol til at sikre kvorum. Hvis en node mistede forbindelsen til resten af klyngen, kunne det antages, at datacentret har oplevet netværksopdeling.
Multi-DC MariaDB-klynger
Alternativt til den asynkrone replikering kunne være en helt MariaDB Cluster-løsning, der spænder over flere datacentre.
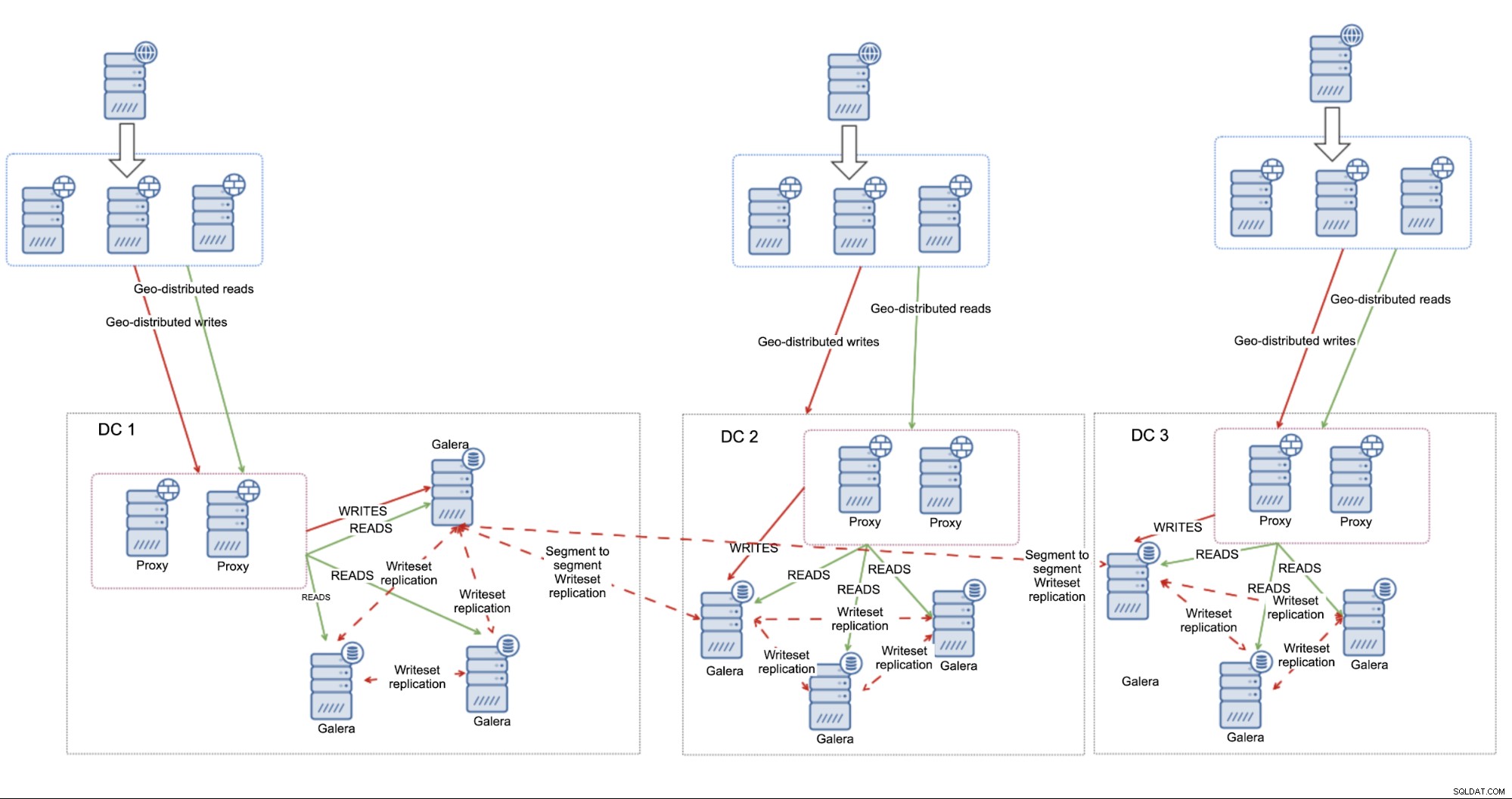
Som anført i begyndelsen af denne blog, MariaDB Cluster, ligesom alle Galera-baseret klynge, vil blive påvirket af den høje latenstid. Når det er sagt, er det helt acceptabelt at køre det i "ikke-så-høj" latency-miljøer og forvente, at det opfører sig korrekt og leverer acceptabel ydeevne. Det hele afhænger af netværkets gennemløb og design, afstanden mellem datacentre og applikationskrav. En sådan tilgang vil fungere godt, især hvis vi bruger segmenter til at differentiere separate datacentre. Det giver MariaDB Cluster mulighed for at optimere sin intra cluster-forbindelse og reducere kryds-DC-trafik til et minimum.
Den største fordel ved denne opsætning er, at den er afhængig af MariaDB Cluster til at håndtere fejl. Bruger du tre datacentre, er du stort set dækket ind over for split-brain situationen – så længe der er flertal, vil det fortsætte med at fungere. Det er ikke påkrævet at have en fuld-blæst node i det tredje datacenter - du kan lige så godt bruge Galera Arbitrator, en dæmon, der fungerer som en del af klyngen, men den behøver ikke at håndtere nogen databaseoperationer. Den opretter forbindelse til noderne, deltager i kvorumberegningen og kan bruges til at videresende trafikken, hvis den direkte forbindelse mellem de to datacentre ikke fungerer.
I så fald kan hele failover-processen beskrives som:definere alle noder i belastningsbalancerne (alt hvis datacentre er tæt på hinanden, i andre tilfælde vil du måske tilføje en prioritet for noder placeret tættere på belastningsbalanceren), og det er stort set det. MariaDB Cluster noder, der udgør flertallet, vil være tilgængelige via enhver proxy.
Deployering af en multi-cloud MariaDB-klynge ved hjælp af ClusterControl
Lad os tage et kig på to muligheder, du kan bruge til at implementere multi-cloud MariaDB-klynger ved hjælp af ClusterControl. Husk, at ClusterControl kræver SSH-forbindelse til alle de noder, den vil administrere, så det er op til dig at sikre netværksforbindelse på tværs af flere datacentre eller cloud-udbydere. Så længe forbindelsen er der, kan vi fortsætte med to metoder.
Implementering af MariaDB-klynger ved hjælp af asynkron replikering
ClusterControl kan hjælpe dig med at implementere to klynger forbundet ved hjælp af asynkron replikering. Når du har en enkelt MariaDB Cluster installeret, vil du sikre dig, at en af noderne har binære logfiler aktiveret. Dette giver dig mulighed for at bruge den node som en master for den anden klynge, som vi snart vil oprette.
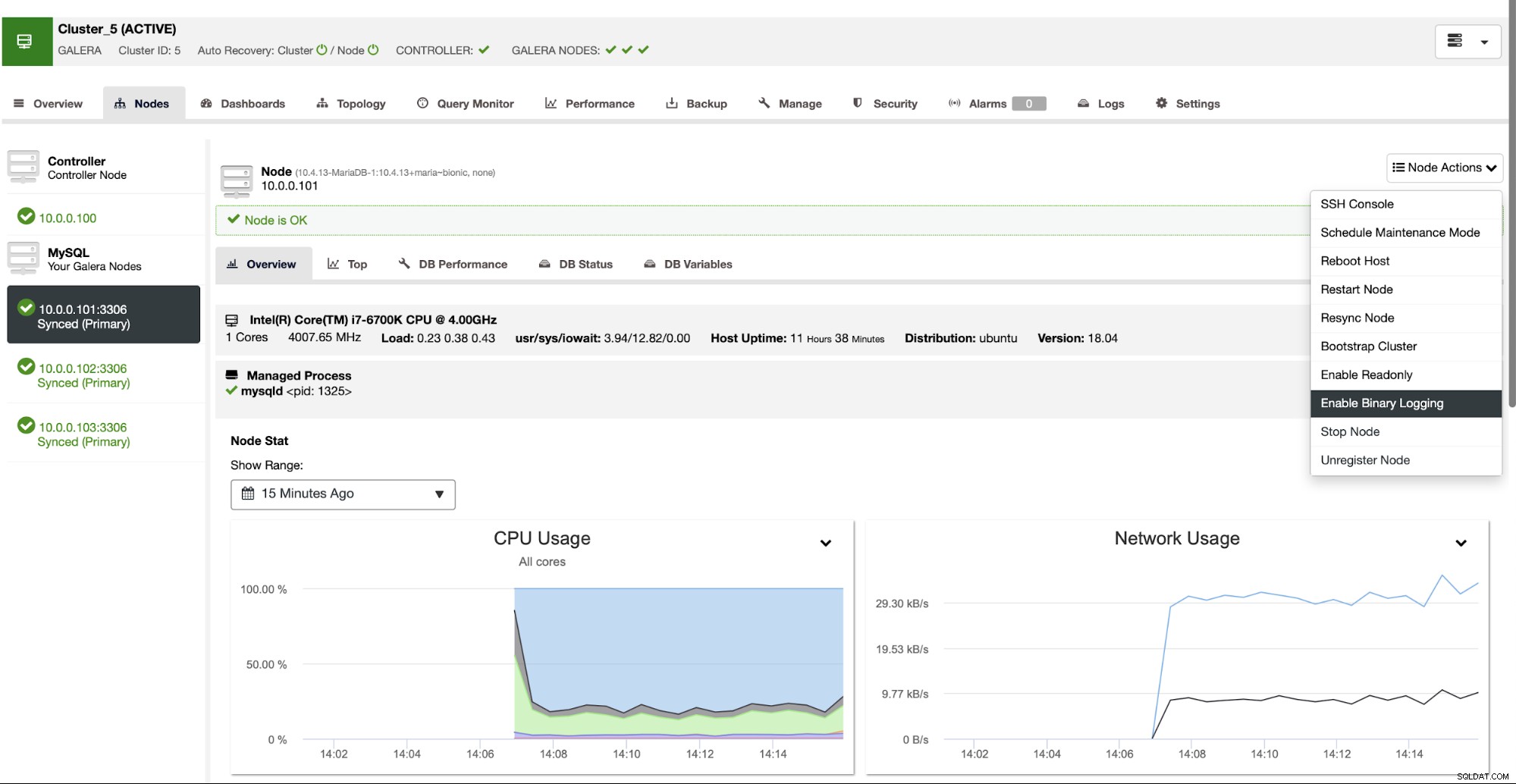
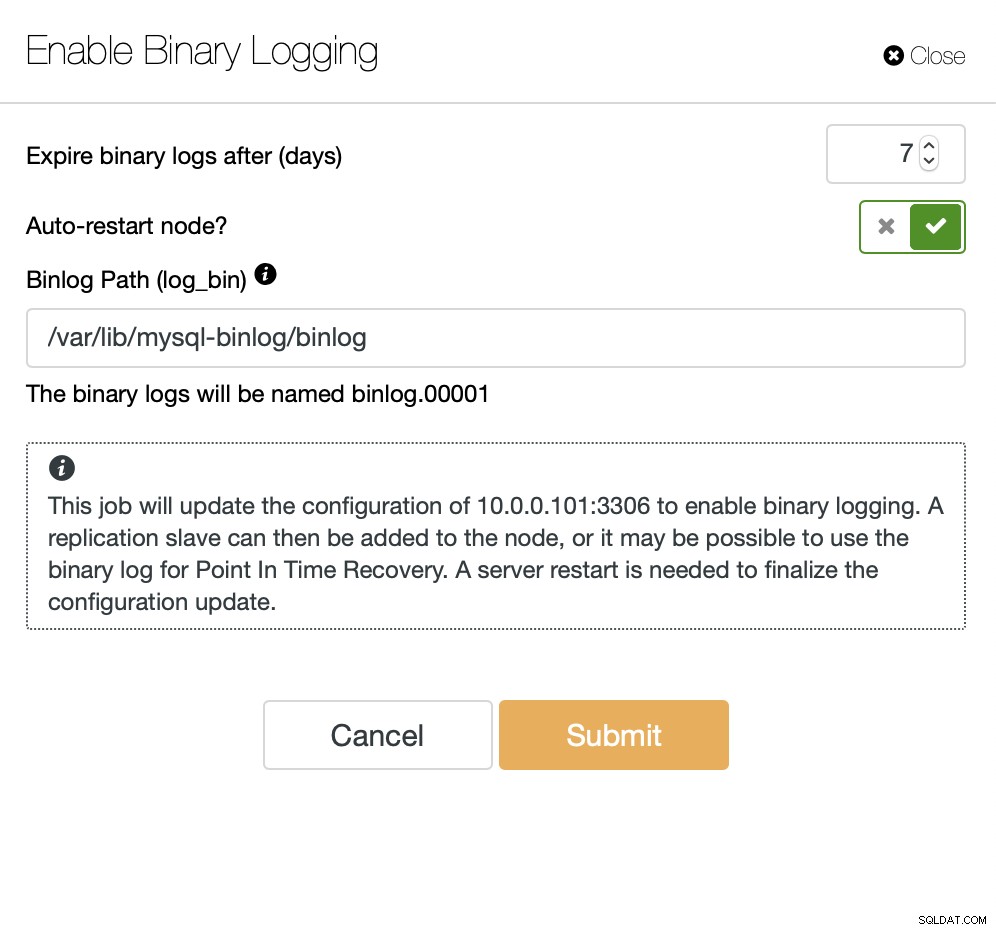
Når den binære log er blevet aktiveret, kan vi bruge Create Slave Cluster job for at starte installationsguiden.
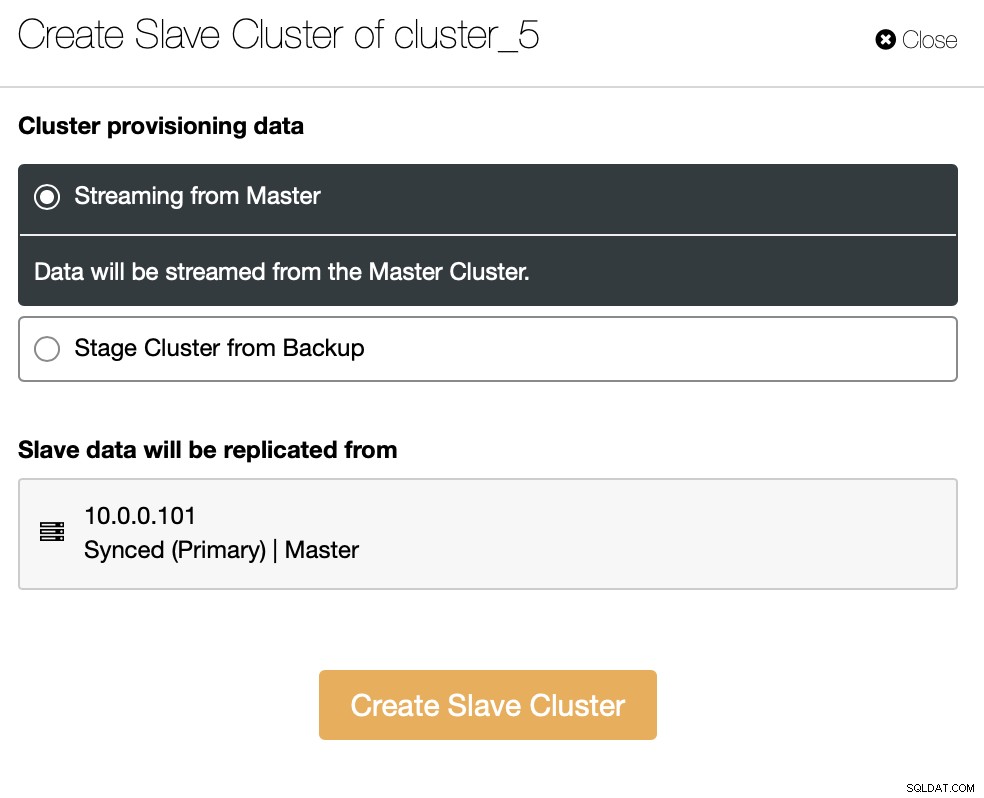
Vi kan enten streame dataene direkte fra masteren, eller du kan bruge en af sikkerhedskopierne for at klargøre dataene.
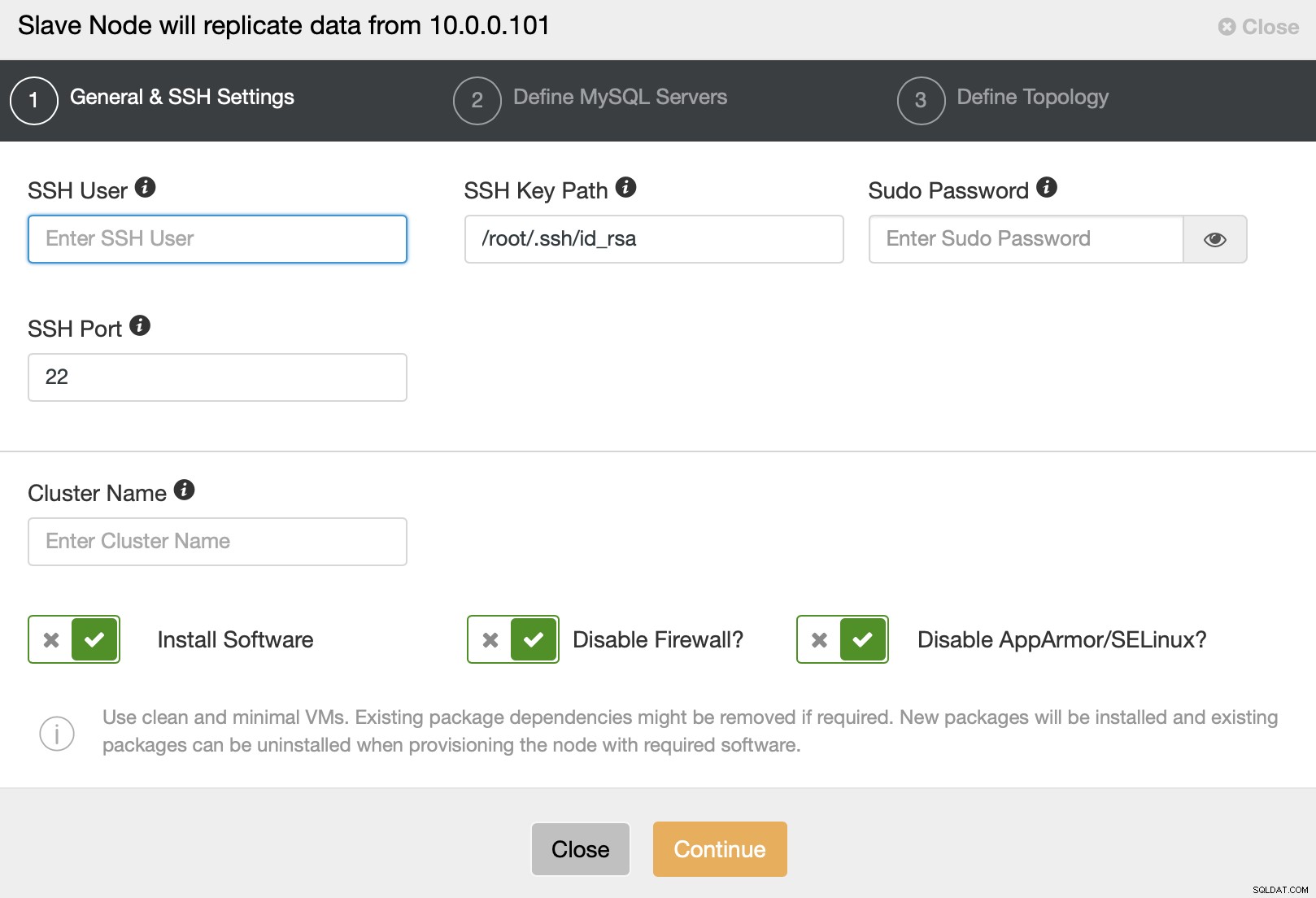
Så bliver du præsenteret for en standard cluster-implementeringsguide, hvor du skal bestå SSH-forbindelsesdetaljer.
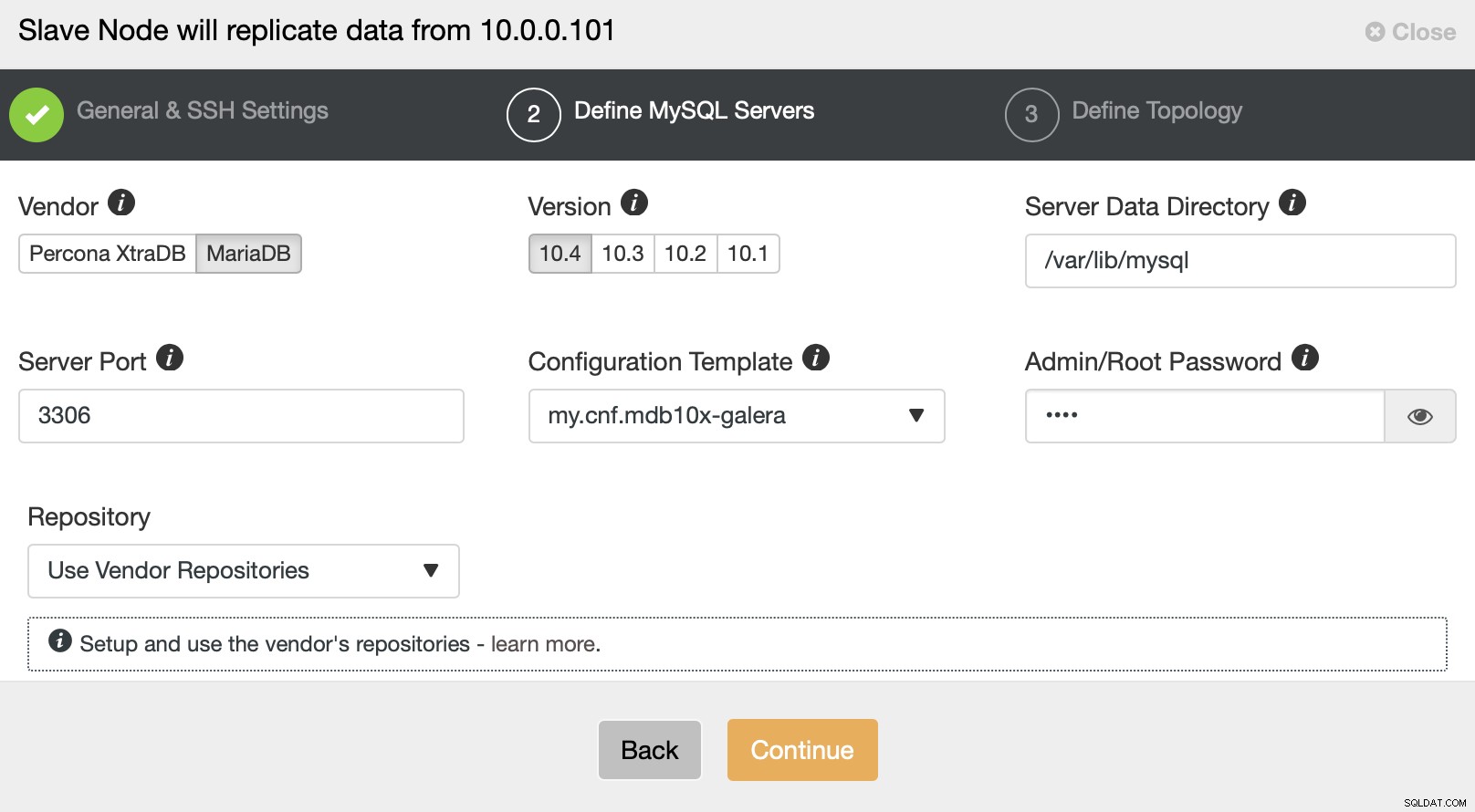
Du vil også blive bedt om at vælge leverandør og version af databaserne som bedt om adgangskoden til root-brugeren.
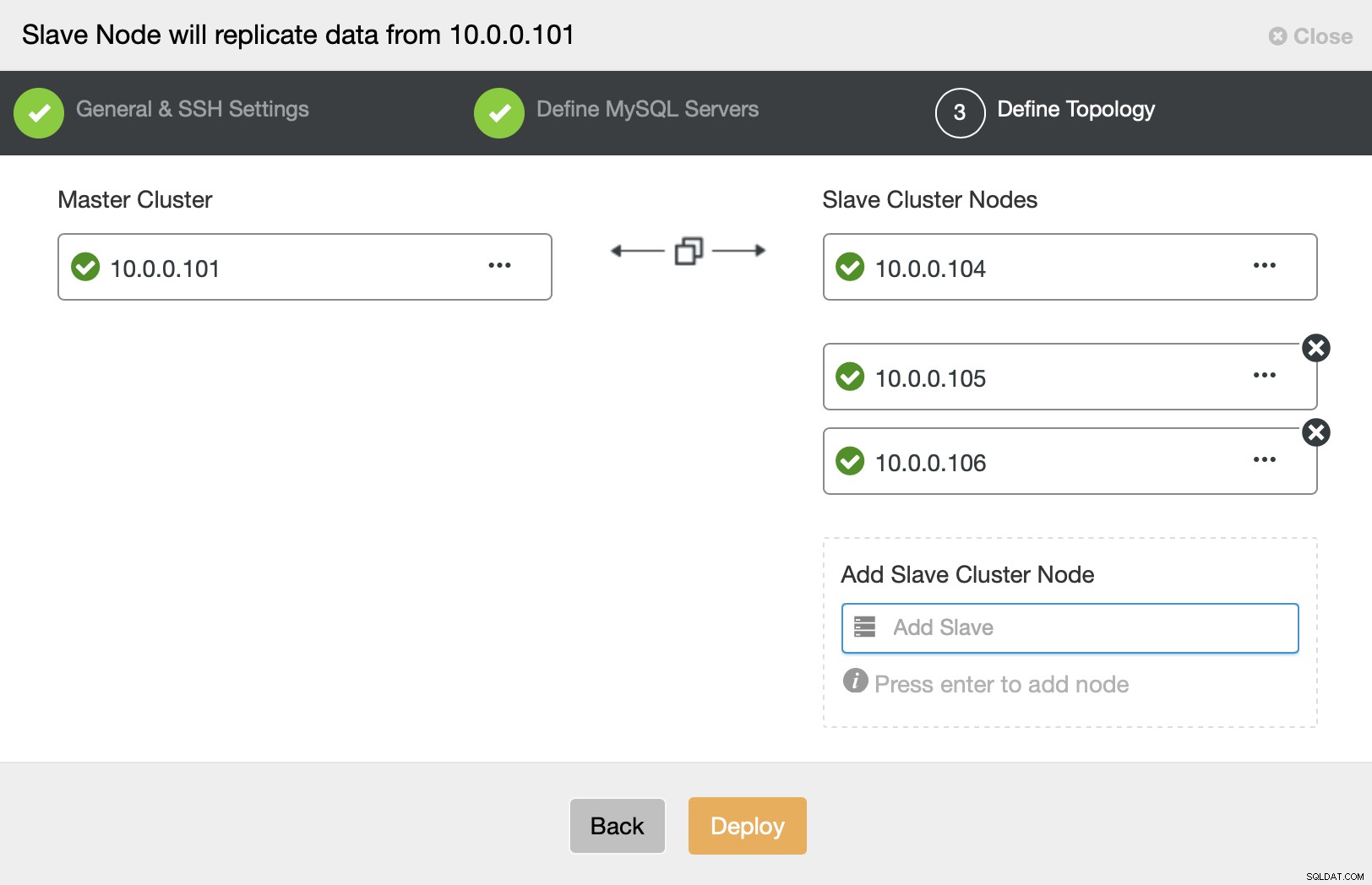
Til sidst bliver du bedt om at definere noder, du gerne vil tilføje til klynge, og du er klar.
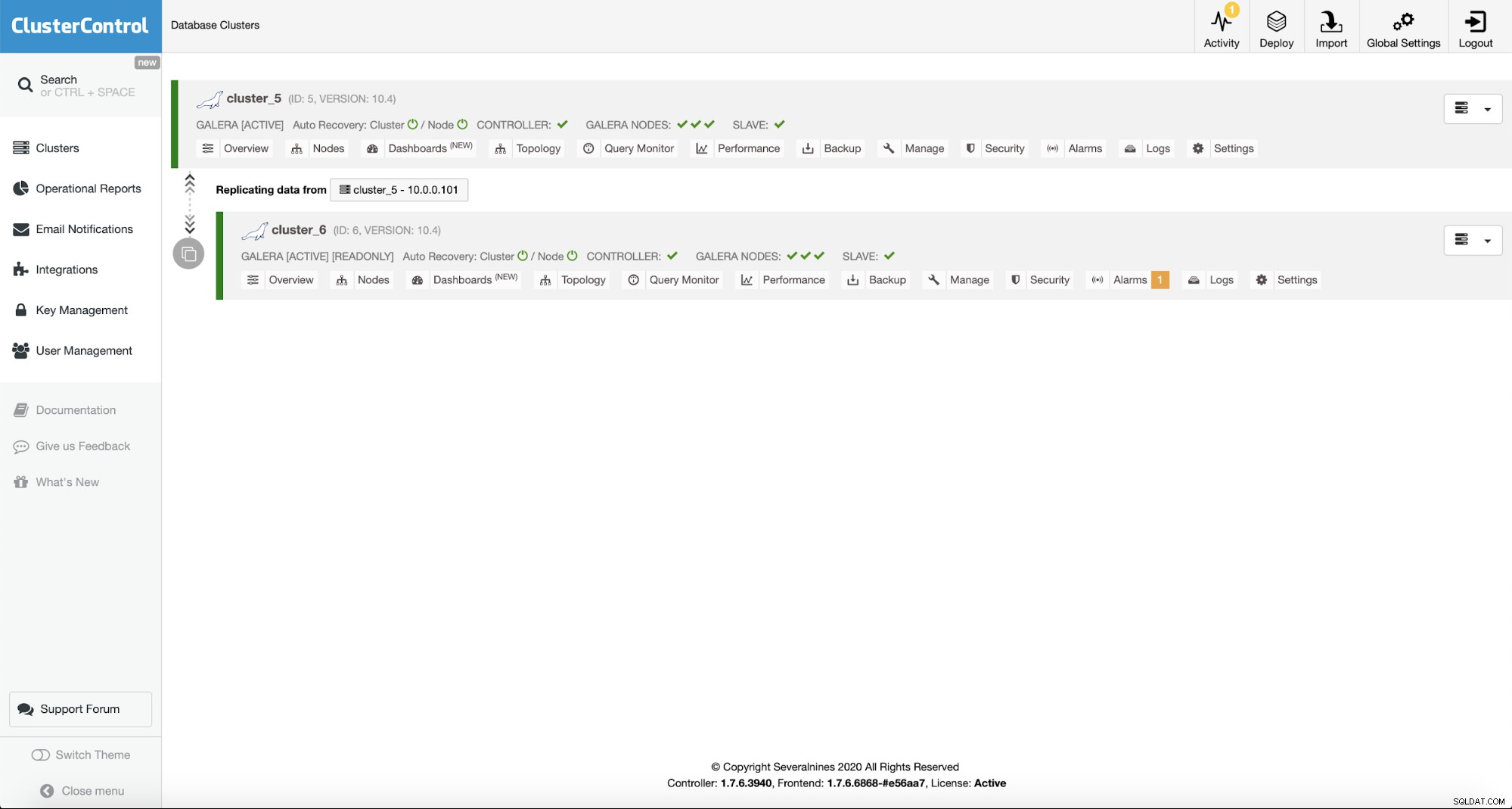
Når den er implementeret, vil du se den på listen over klyngerne i ClusterControl UI.
Implementering af Multi-Cloud MariaDB Cluster
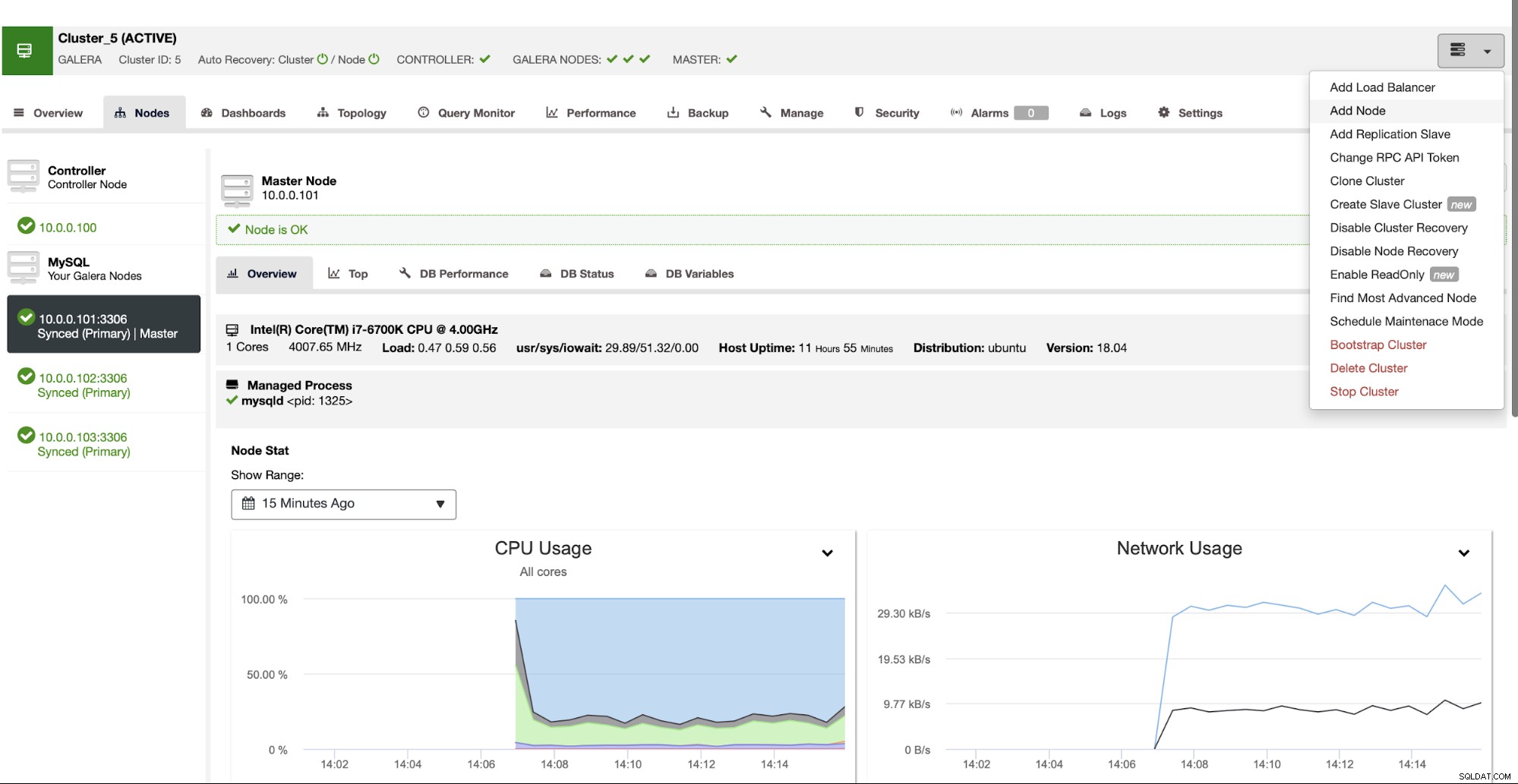
Som vi nævnte tidligere, ville en anden mulighed for at implementere MariaDB Cluster være at bruge separate segmenter, når du tilføjer noder til klyngen. I ClusterControl UI vil du finde en mulighed for at "Tilføj node":
Når du bruger det, vil du blive præsenteret for følgende skærmbillede:
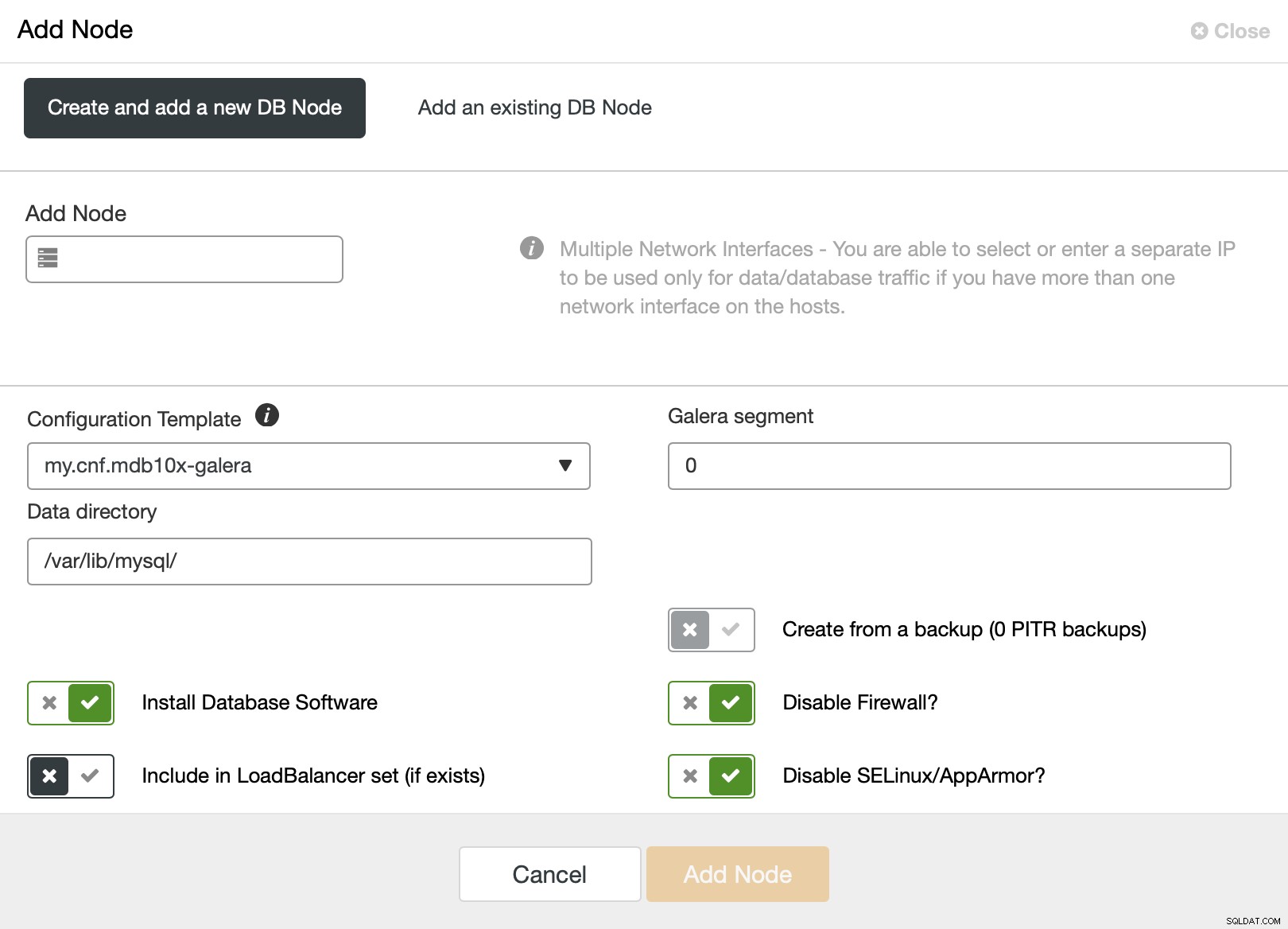
Standardsegmentet er 0, så du vil ændre det til en anden værdi .
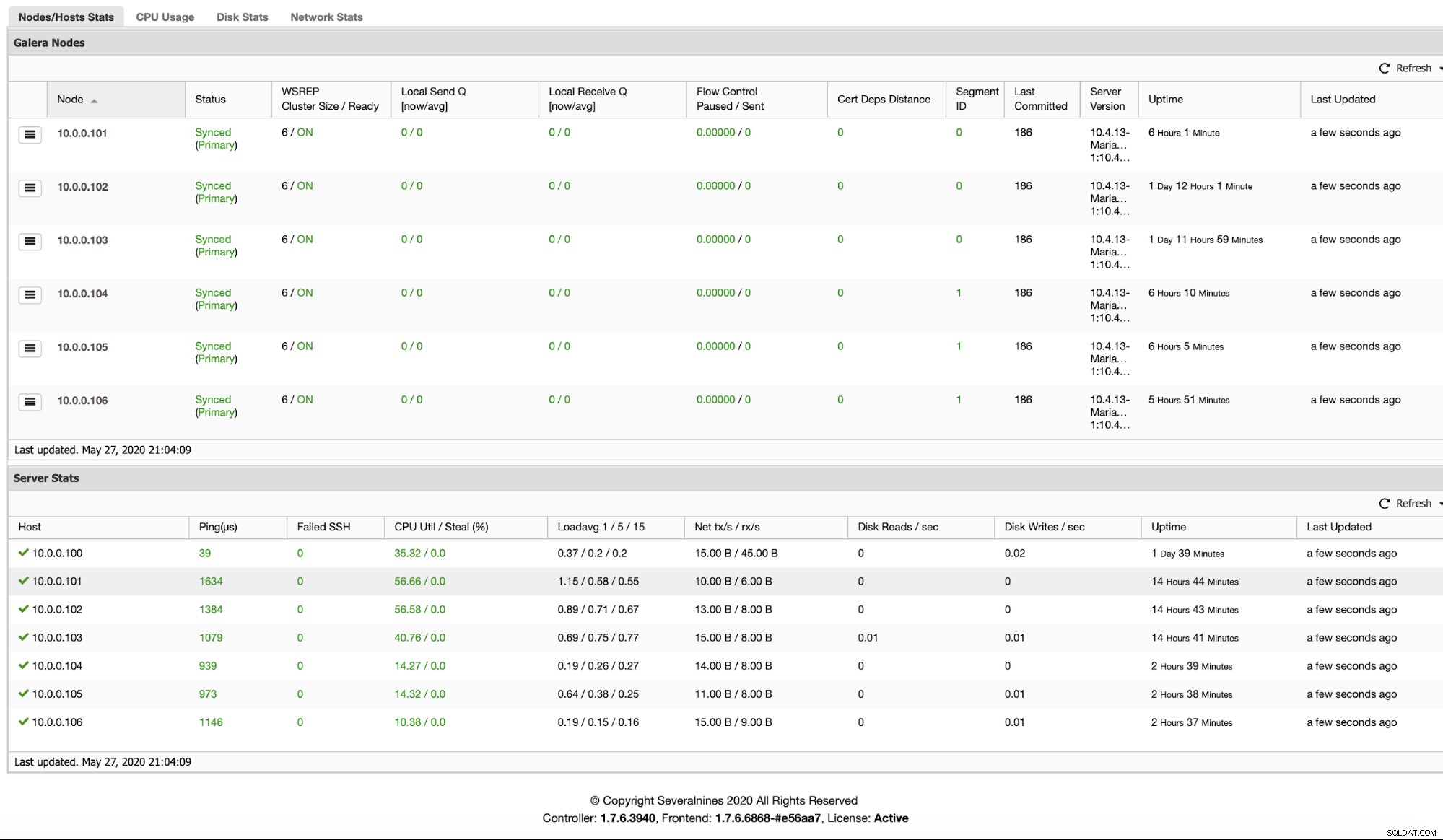
Efter at noder er blevet tilføjet, kan du tjekke, i hvilket segment de er placeret ved at se på fanen Oversigt:
Konklusion
Vi håber, at denne korte blog gav dig en bedre forståelse af de muligheder, du har for multi-cloud MariaDB Cluster-implementeringer, og hvordan de kan bruges til at sikre høj tilgængelighed af din databaseinfrastruktur.