I mit sidste indlæg demonstrerede jeg, at en hukommelsesoptimeret TVP ved små mængder kan levere væsentlige ydeevnefordele til typiske forespørgselsmønstre.
For at teste i lidt højere skala lavede jeg en kopi af SalesOrderDetailEnlarged tabel, som jeg havde udvidet til omkring 5.000.000 rækker takket være dette script af Jonathan Kehayias (blog | @SQLPoolBoy)).
DROP TABLE dbo.SalesOrderDetailEnlarged; GO SELECT * INTO dbo.SalesOrderDetailEnlarged FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged; -- 4,973,997 rows CREATE CLUSTERED INDEX PK_SODE ON dbo.SalesOrderDetailEnlarged(SalesOrderID, SalesOrderDetailID);
Jeg har også oprettet tre in-memory versioner af denne tabel, hver med et forskelligt spandantal (fisker efter et "sweet spot") – 16.384, 131.072 og 1.048.576. (Du kan bruge rundere tal, men de bliver alligevel rundet op til næste potens af 2.) Eksempel:
CREATE TABLE [dbo].[SalesOrderDetailEnlarged_InMem_16K] -- and _131K and _1MM ( [SalesOrderID] [int] NOT NULL, [SalesOrderDetailID] [int] NOT NULL, [CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_CP1_CI_AS NULL, [OrderQty] [smallint] NOT NULL, [ProductID] [int] NOT NULL, [SpecialOfferID] [int] NOT NULL, [UnitPrice] [money] NOT NULL, [UnitPriceDiscount] [money] NOT NULL, [LineTotal] [numeric](38, 6) NOT NULL, [rowguid] [uniqueidentifier] NOT NULL, [ModifiedDate] [datetime] NOT NULL PRIMARY KEY NONCLUSTERED HASH ( [SalesOrderID], [SalesOrderDetailID] ) WITH ( BUCKET_COUNT = 16384) -- and 131072 and 1048576 ) WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA ); GO INSERT dbo.SalesOrderDetailEnlarged_InMem_16K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_131K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_1MM SELECT * FROM dbo.SalesOrderDetailEnlarged; GO
Bemærk, at jeg ændrede spandstørrelsen fra det forrige eksempel (256). Når du bygger bordet, vil du vælge "sweet spot" for spandstørrelse - du vil optimere hash-indekset for punktopslag, hvilket betyder, at du vil have så mange spande som muligt med så få rækker i hver spand som muligt. Selvfølgelig, hvis du opretter ~5 millioner buckets (da der i dette tilfælde, måske ikke et særlig godt eksempel, er ~5 millioner unikke kombinationer af værdier), vil du have nogle hukommelsesudnyttelse og affaldsindsamling at håndtere. Men hvis du prøver at proppe ~5 millioner unikke værdier i 256 buckets, vil du også opleve nogle problemer. Under alle omstændigheder går denne diskussion langt ud over omfanget af mine tests for dette indlæg.
For at teste mod standardtabellen lavede jeg lignende lagrede procedurer som i de tidligere tests:
CREATE PROCEDURE dbo.SODE_InMemory
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged AS sode
WHERE EXISTS (SELECT 1 FROM @InMemory AS t
WHERE sode.SalesOrderID = t.Item);
END
GO
CREATE PROCEDURE dbo.SODE_Classic
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged AS sode
WHERE EXISTS (SELECT 1 FROM @Classic AS t
WHERE sode.SalesOrderID = t.Item);
END
GO Så først, for at se på planerne for f.eks. 1.000 rækker, der indsættes i tabelvariablerne, og derefter køre procedurerne:
DECLARE @InMemory dbo.InMemoryTVP; INSERT @InMemory SELECT TOP (1000) SalesOrderID FROM dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); DECLARE @Classic dbo.ClassicTVP; INSERT @Classic SELECT Item FROM @InMemory; EXEC dbo.SODE_Classic @Classic = @Classic; EXEC dbo.SODE_InMemory @InMemory = @InMemory;
Denne gang ser vi, at optimeringsværktøjet i begge tilfælde har valgt en klynget indekssøgning mod basistabellen, og en indlejret loops joinforbindelse mod TVP. Nogle omkostningsmålinger er forskellige, men ellers er planerne ret ens:
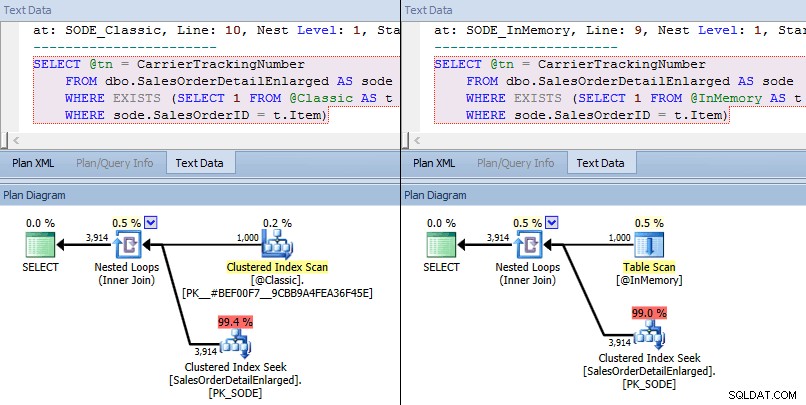 Lignende planer for in-memory TVP vs. klassisk TVP i højere skala
Lignende planer for in-memory TVP vs. klassisk TVP i højere skala
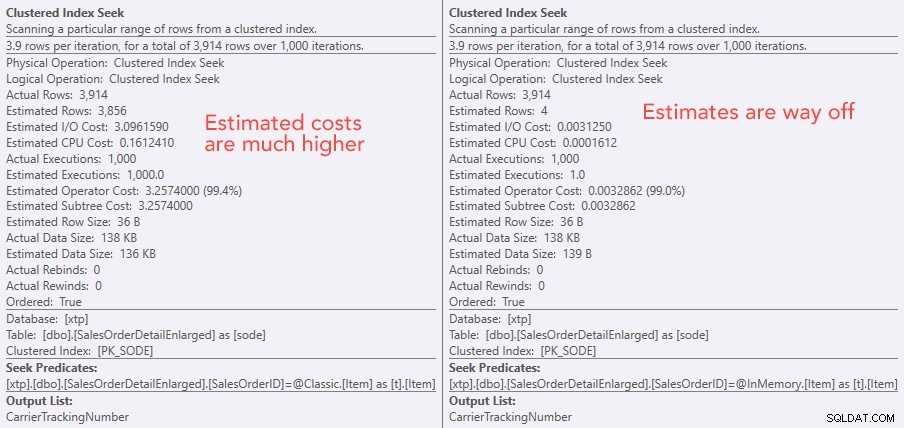 Sammenligning af søgeoperatøromkostninger – Classic til venstre, In-Memory til højre
Sammenligning af søgeoperatøromkostninger – Classic til venstre, In-Memory til højre
Den absolutte værdi af omkostningerne får det til at se ud som om den klassiske TVP ville være meget mindre effektiv end In-Memory TVP. Men jeg spekulerede på, om dette ville være sandt i praksis (især da det estimerede antal henrettelser til højre virkede mistænkeligt), så selvfølgelig kørte jeg nogle tests. Jeg besluttede at tjekke mod 100, 1.000 og 2.000 værdier, der skulle sendes til proceduren.
DECLARE @values INT = 100; -- 1000, 2000 DECLARE @Classic dbo.ClassicTVP; DECLARE @InMemory dbo.InMemoryTVP; INSERT @Classic(Item) SELECT TOP (@values) SalesOrderID FROM dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); INSERT @InMemory(Item) SELECT Item FROM @Classic; DECLARE @i INT = 1; SELECT SYSDATETIME(); WHILE @i <= 10000 BEGIN EXEC dbo.SODE_Classic @Classic = @Classic; SET @i += 1; END SELECT SYSDATETIME(); SET @i = 1; WHILE @i <= 10000 BEGIN EXEC dbo.SODE_InMemory @InMemory = @InMemory; SET @i += 1; END SELECT SYSDATETIME();
Ydeevneresultaterne viser, at ved et større antal punktopslag fører brugen af en In-Memory TVP til lidt faldende afkast, idet det er lidt langsommere hver gang:
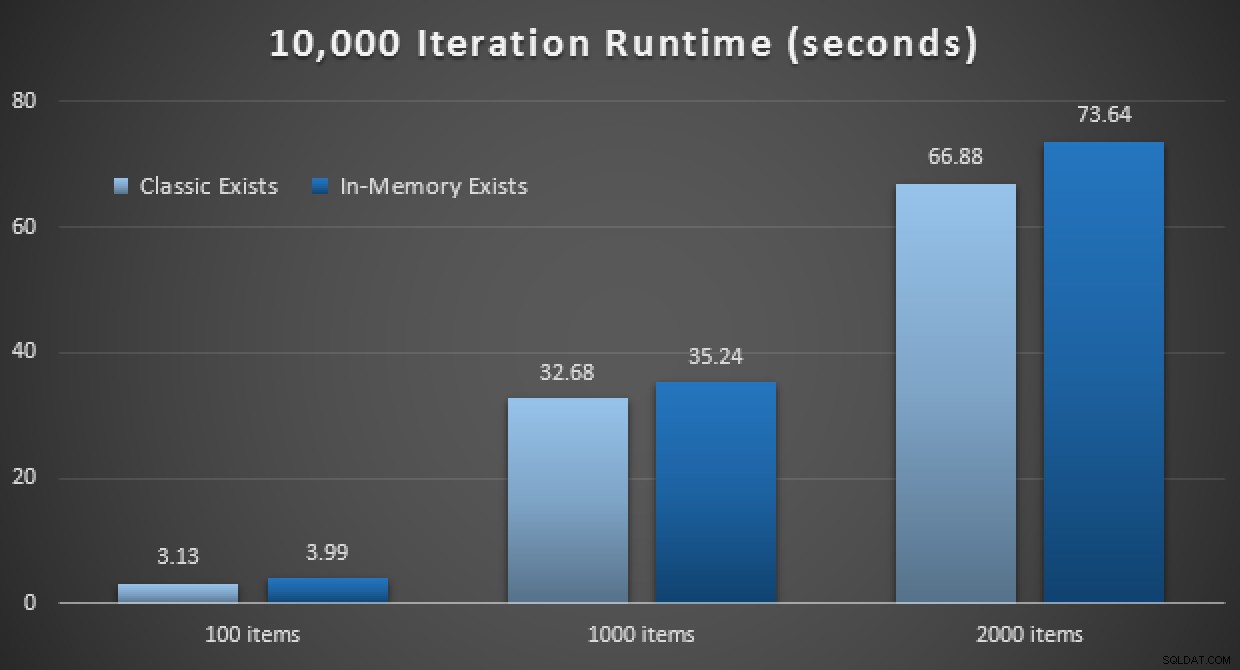
Resultater af 10.000 henrettelser ved hjælp af klassiske og in-memory TVP'er em>
Så i modsætning til det indtryk, du måske har taget fra mit tidligere indlæg, er det ikke nødvendigvis gavnligt at bruge en TVP i hukommelsen i alle tilfælde.
Tidligere har jeg også set på native kompilerede lagrede procedurer og in-memory-tabeller i kombination med in-memory TVP'er. Kan det her gøre en forskel? Spoiler:absolut ikke. Jeg oprettede tre procedurer som denne:
CREATE PROCEDURE [dbo].[SODE_Native_InMem_16K] -- and _131K and _1MM
@InMemory dbo.InMemoryTVP READONLY
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english');
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged_InMem_16K AS sode -- and _131K and _1MM
INNER JOIN @InMemory AS t -- no EXISTS allowed here
ON sode.SalesOrderID = t.Item;
END
GO Endnu en spoiler:Jeg var ikke i stand til at køre disse 9 tests med et gentagelsestal på 10.000 – det tog alt for lang tid. I stedet gik jeg igennem og kørte hver procedure 10 gange, kørte det sæt test 10 gange og tog gennemsnittet. Her er resultaterne:
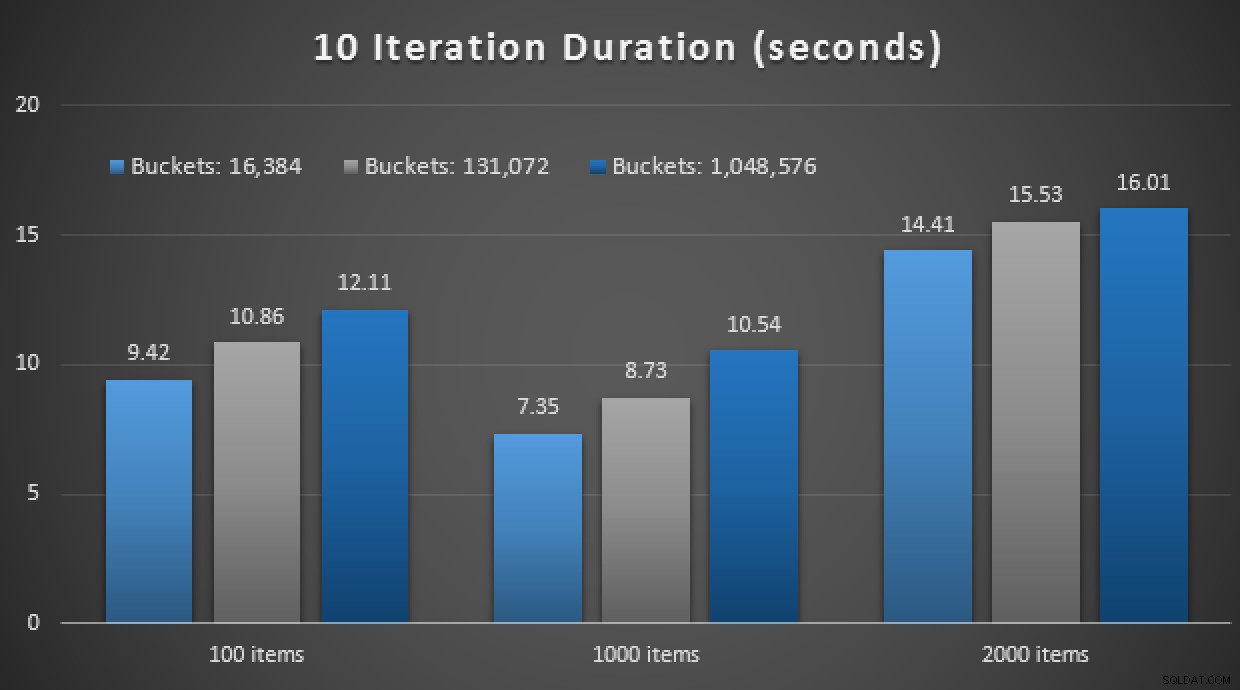
Resultater af 10 henrettelser ved hjælp af TVP'er i hukommelsen og native kompilerede lagrede procedurer
Alt i alt var dette eksperiment ret skuffende. Bare man ser på forskellens størrelse, med en on-disk-tabel, blev det gennemsnitlige lagrede procedurekald gennemført på et gennemsnit på 0,0036 sekunder. Men når alt brugte in-memory-teknologier, var det gennemsnitlige lagrede procedurekald 1,1662 sekunder. Av . Det er højst sandsynligt, at jeg lige har valgt en dårlig usecase til demo generelt, men det virkede på det tidspunkt som et intuitivt "første forsøg."
Konklusion
Der er meget mere at teste omkring dette scenarie, og jeg har flere blogindlæg at følge. Jeg har endnu ikke identificeret den optimale use case for in-memory TVP'er i større skala, men håber, at dette indlæg tjener som en påmindelse om, at selvom en løsning virker optimal i et tilfælde, er det aldrig sikkert at antage, at den er lige anvendelig til forskellige scenarier. Det er præcis sådan, In-Memory OLTP skal gribes an:som en løsning med et snævert sæt af use cases, der absolut skal valideres, før de implementeres i produktionen.