Det bedste scenarie er, at du i tilfælde af en databasefejl har en god Disaster Recovery Plan (DRP) og et meget tilgængeligt miljø med en automatisk failover-proces, men... hvad sker der, hvis det mislykkes for en eller anden uventet grund? Hvad hvis du skal udføre en manuel failover? I denne blog deler vi nogle anbefalinger, du kan følge, hvis du har brug for at failover din database.
Verifikationstjek
Før du udfører en ændring, skal du bekræfte nogle grundlæggende ting for at undgå nye problemer efter failover-processen.
replikeringsstatus
Det kan være muligt, at slaveknuden på fejltidspunktet ikke er opdateret på grund af en netværksfejl, høj belastning eller et andet problem, så du skal sikre dig, at slave har alle (eller næsten alle) oplysningerne. Hvis du har mere end én slaveknude, bør du også tjekke, hvilken der er den mest avancerede node og vælge den til failover.
f.eks.:Lad os tjekke replikeringsstatussen i en MariaDB-server.
MariaDB [(ingen)]> VIS SLAVESTATUS\G****************************** 1. række ** *************************Slave_IO_State:Venter på, at master sender eventMaster_Host:192.168.100.110Master_User:rpl_userMaster_Port:3306Connect_Retry:10Master_Log_File:binlog.000000:LogRead_Master_Log. :relay-bin.000002Relay_Log_Pos:635Relay_Master_Log_File:binlog.000014Slave_IO_Running:YesSlave_SQL_Running:YesLast_Errno:0Skip_Counter:0Exec_Master_Log_Pos:339Relay_Log_Space:938Until_Condition:NoneUntil_Log_Pos:0Master_SSL_Allowed:NoSeconds_Behind_Master:0Master_SSL_Verify_Server_Cert:NoLast_IO_Errno:0Last_SQL_Errno:0Replicate_Ignore_Server_Ids:Master_Server_Id:3001Using_Gtid:Slave_PosGtid_IO_Pos:0-3001-20Parallel_Mode :konservativSQL_Delay:0SQL_Remaining_Delay:NULLSlave_SQL_Running_State:Slaven har læst al relælog; venter på, at slave-I/O-tråden opdaterer itSlave_DDL_Groups:0Slave_Non_Transactional_Groups:0Slave_Transactional_Groups:01 række i sæt (0,000 sek.) I tilfælde af PostgreSQL er det lidt anderledes, da du skal kontrollere WALs-status og sammenligne de anvendte med de hentede.
postgres=# VÆLG CASE NÅR pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()postgres-# THEN 0postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())END AS log_delay log_delay----------- 0(1 række) legitimationsoplysninger
Før du kører failover, skal du kontrollere, om din applikation/brugere vil være i stand til at få adgang til din nye master med de aktuelle legitimationsoplysninger. Hvis du ikke replikerer dine databasebrugere, er legitimationsoplysningerne måske blevet ændret, så du bliver nødt til at opdatere dem i slaveknuderne før eventuelle ændringer.
f.eks.:Du kan forespørge brugertabellen i mysql-databasen for at kontrollere brugeroplysningerne i en MariaDB/MySQL-server:
MariaDB [(ingen)]> VÆLG vært, bruger, adgangskode FRA mysql.user;+----------------+------- -------+-------------------------------------------------- -+| Vært | Bruger | Adgangskode |+----------------+--------------+------------------- ----------------------------+| lokalvært | rod | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 || lokalvært | mysql | ugyldig || 127.0.0.1 | backupbruger | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 || 192.168.100.100 | cmon | *F80B5EE41D1FB1FA67D83E96FCB1638ABCFB86E2 || 127.0.0.1 | rod | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 || ::1 | rod | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 || lokalvært | backupbruger | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 || 192.168.100.112 | bruger1 | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 || lokalvært | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 || 127.0.0.1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 || ::1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 || 192.168.100.110 | rpl_bruger | *EEA7B018B16E0201270B3CDC0AF8FC335048DC63 |+----------------+---------+------ ------------------------------+12 rækker i sæt (0,001 sek.) I tilfælde af PostgreSQL kan du bruge '\du'-kommandoen til at kende rollerne, og du skal også tjekke pg_hba.conf-konfigurationsfilen for at administrere brugeradgangen (ikke legitimationsoplysninger). Så:
postgres=# \du Liste over roller Rollenavn | Attributter | Medlem af ------------------+------------------------------ ------------------------------------+------------ admindb | Superbruger, Opret rolle, Opret DB | {} cmon_replikering | Replikation | {} cmonexporter | | {} postgres | Superbruger, Opret rolle, Opret DB, Replikering, Bypass RLS | {} s9smysqlchk | Superbruger, Opret rolle, Opret DB | {} Og pg_hba.conf:
# TYPE DATABASE BRUGERADRESSE METODE værtsreplikering cmon_replication localhost md5host replikering cmon_replication 127.0.0.1/32 md5host alle s9smysqlchk localhost md5host alle s9smysqlchk 127.0.01> Netværks-/firewalladgang
Logioplysningerne er ikke det eneste mulige problem med at få adgang til din nye master. Hvis noden er i et andet datacenter, eller du har en lokal firewall til at filtrere trafik, skal du kontrollere, om du har tilladelse til at få adgang til den, eller endda om du har netværksruten til at nå den nye masterknude.
f.eks.:iptables. Lad os tillade trafikken fra netværket 167.124.57.0/24 og kontrollere de nuværende regler efter at have tilføjet det:
$ iptables -A INPUT -s 167.124.57.0/24 -m state --state NY -j ACCEPT$ iptables -L -nChain INPUT (policy ACCEPT)mål prot opt source destinationACCEPT alle -- 167.124.57.0 /24 0.0.0.0/0 tilstand NEWChain FORWARD (policy ACCEPT) target prot opt source destinationChain OUTPUT (policy ACCEPT) target prot opt source destination f.eks.:ruter. Lad os antage, at din nye masterknude er i netværket 10.0.0.0/24, din applikationsserver er i 192.168.100.0/24, og du kan nå fjernnetværket ved hjælp af 192.168.100.100, så tilføj den tilsvarende rute i din applikationsserver:
$ route add -net 10.0.0.0/24 gw 192.168.100.100$ route -nKernel IP routing tableDestination Gateway Genmask Flags Metric Ref Use Iface0.0.0.0 192.168.100.1 0 UG 0.0 eth . 0.0.0 192.168.100.100 255.255.255.0 UG 0 0 0 eth0169.254.0.0 0.0.0.0 255.255.0.0 U 1027 0 0 eth0192.01.5 .0 0 eth0192.01.5 .0 .0 .0 .0 . Handlingspunkter
Efter at have kontrolleret alle de nævnte punkter, bør du være klar til at foretage handlingerne for at failover din database.
Ny IP-adresse
Da du vil promovere en slaveknude, ændres master-IP-adressen, så du bliver nødt til at ændre den i din applikation eller klientadgang.
Brug af en Load Balancer er en glimrende måde at undgå dette problem/ændring på. Efter failover-processen vil Load Balancer registrere den gamle master som offline og (afhængigt af konfigurationen) sende trafikken til den nye for at skrive på den, så du ikke behøver at ændre noget i din applikation.
f.eks.:Lad os se et eksempel på en HAProxy-konfiguration:
lyt haproxy_5433 bind *:5433 mode tcp timeout klient 10800s timeout server 10800s balance leastconn option tcp-check server 192.168.100.119 192.168.100.119:51932.026 tjek .01.026 server I dette tilfælde, hvis én node er nede, sender HAProxy ikke trafik dertil og sender kun trafikken til den tilgængelige node.
Genkonfigurer slaveknuderne
Hvis du har mere end én slaveknude, efter at have promoveret en af dem, skal du omkonfigurere resten af slaverne til at oprette forbindelse til den nye master. Dette kan være en tidskrævende opgave, afhængigt af antallet af noder.
Bekræft og konfigurer sikkerhedskopierne
Når du har alt på plads (ny master fremmet, slaver rekonfigureret, applikationsskrivning i den nye master), er det vigtigt at tage de nødvendige handlinger for at forhindre et nyt problem, så sikkerhedskopiering er et must i dette trin. Sandsynligvis havde du en sikkerhedskopieringspolitik kørende før hændelsen (hvis ikke, skal du have den med sikkerhed), så du skal kontrollere, om sikkerhedskopierne stadig kører, ellers vil de gøre det i den nye topologi. Det kan være muligt, at du havde sikkerhedskopierne kørende på den gamle master, eller at du brugte den slaveknude, der er master nu, så du skal tjekke den for at sikre, at din sikkerhedskopieringspolitik stadig fungerer efter ændringerne.
Databaseovervågning
Når du udfører en failover-proces, er overvågning et must før, under og efter processen. Med dette kan du forhindre et problem, før det bliver værre, opdage et uventet problem under failover, eller endda vide, om noget går galt efter det. For eksempel skal du overvåge, om din applikation kan få adgang til din nye master ved at kontrollere antallet af aktive forbindelser.
Nøglemålinger, der skal overvåges
Lad os se nogle af de vigtigste metrics at tage hensyn til:
- replikeringsforsinkelse
- replikeringsstatus
- Antal forbindelser
- Netværksbrug/fejl
- Serverbelastning (CPU, hukommelse, disk)
- Database- og systemlogfiler
Tilbage
Selvfølgelig, hvis noget gik galt, skal du kunne rulle tilbage. Blokering af trafik til den gamle node og at holde den så isoleret som muligt kunne være en god strategi for dette, så i tilfælde af at du har brug for at rulle tilbage, vil du have den gamle node tilgængelig. Hvis tilbagerulningen sker efter nogle minutter, afhængigt af trafikken, bliver du sandsynligvis nødt til at indsætte dataene for disse minutter i den gamle master, så sørg for, at du også har din midlertidige masterknude tilgængelig og isoleret for at tage disse oplysninger og anvende dem tilbage .
Automatisk failover-proces med ClusterControl
Når du ser alle disse nødvendige opgaver for at udføre en failover, vil du sandsynligvis automatisere den og undgå alt dette manuelle arbejde. Til dette kan du drage fordel af nogle af de funktioner, som ClusterControl kan tilbyde dig til forskellige databaseteknologier, såsom automatisk gendannelse, sikkerhedskopier, brugeradministration, overvågning, blandt andre funktioner, alt sammen fra det samme system.
Med ClusterControl kan du verificere replikeringsstatussen og dens forsinkelse, oprette eller ændre legitimationsoplysninger, kende netværks- og værtsstatus og endnu flere verifikationer.
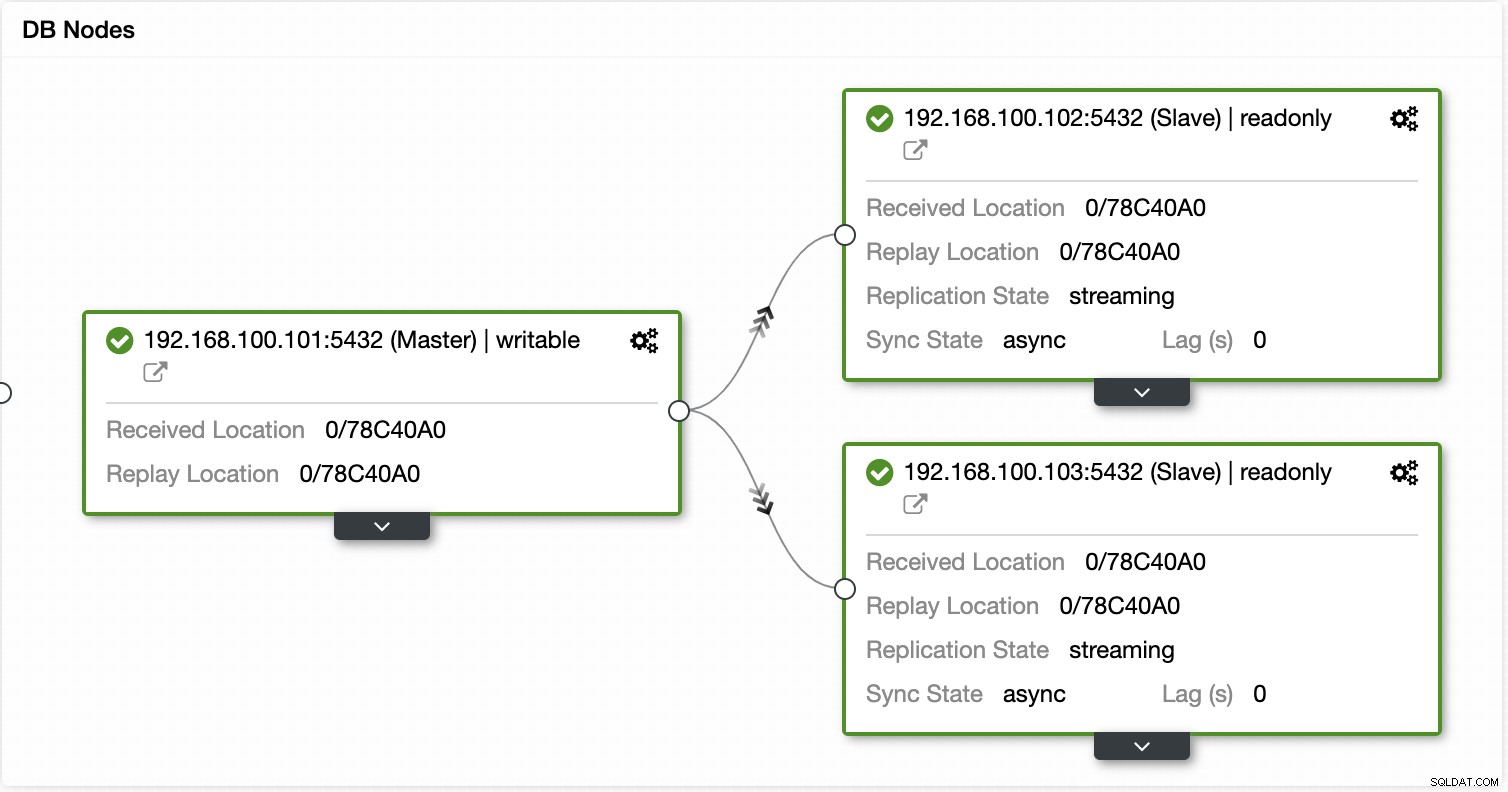
Ved at bruge ClusterControl kan du også udføre forskellige klynge- og nodehandlinger, såsom at fremme slave , genstart database og server, tilføj eller fjern databasenoder, tilføj eller fjern belastningsbalanceringsnoder, genopbyg en replikeringsslave og mere.
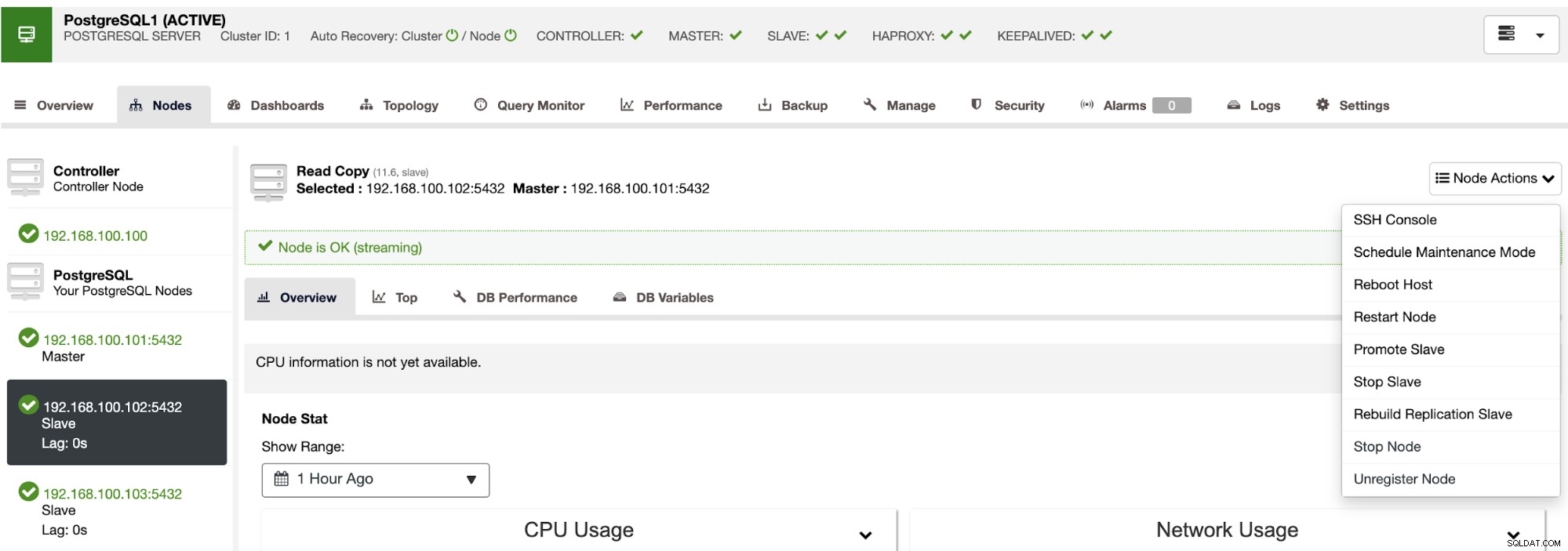
Ved at bruge disse handlinger kan du også rulle tilbage din failover, hvis det er nødvendigt ved at genopbygge og promovere den forrige mester.
ClusterControl har overvågnings- og alarmtjenester, der hjælper dig med at vide, hvad der sker, eller endda hvis noget er sket tidligere.
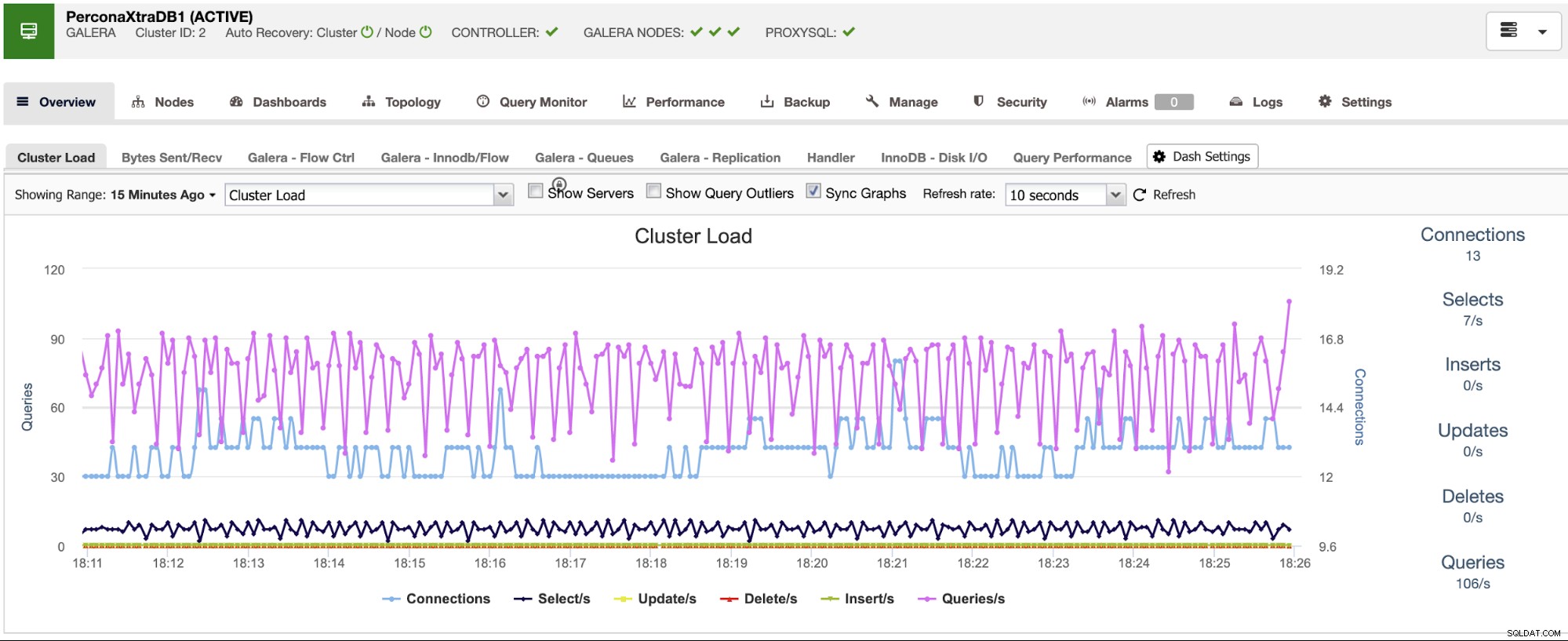
Du kan også bruge dashboardsektionen til at få en mere brugervenlig visning om status for dine systemer.
Konklusion
I tilfælde af en masterdatabasefejl, vil du gerne have alle oplysningerne på plads for at tage de nødvendige handlinger ASAP. At have en god DRP er nøglen til at holde dit system kørende hele (eller næsten hele) tiden. Denne DRP bør omfatte en veldokumenteret failover-proces for at have en acceptabel RTO (Recovery Time Objective) for virksomheden.