I en tidligere blog annoncerede vi en ny ClusterControl 1.7.4-funktion kaldet Cluster-to-Cluster Replication. Det automatiserer hele processen med at opsætte en DR-klynge fra din primære klynge med replikering imellem. For mere detaljeret information henvises til ovennævnte blogindlæg.
Nu i denne blog vil vi tage et kig på, hvordan man konfigurerer denne nye funktion til en eksisterende klynge. Til denne opgave antager vi, at du har ClusterControl installeret, og at Master Cluster blev implementeret ved hjælp af det.
Krav til Master Cluster
Der er nogle krav til Master Cluster for at få det til at fungere:
- Percona XtraDB Cluster version 5.6.x og nyere, eller MariaDB Galera Cluster version 10.x og nyere.
- GTID aktiveret.
- Binær logning aktiveret på mindst én databasenode.
- Sikkerhedskopieringsoplysningerne skal være de samme på tværs af masterklyngen og slaveklyngen.
Forberedelse af masterklyngen
Masterklyngen skal være forberedt til at bruge denne nye funktion. Det kræver konfiguration fra både ClusterControl og Database side.
ClusterControl-konfiguration
I databasenoden skal du kontrollere de sikkerhedskopierede brugerlegitimationsoplysninger, der er gemt i /etc/my.cnf.d/secrets-backup.cnf (for RedHat-baseret OS) eller i /etc/mysql/secrets-backup .cnf (til Debian-baseret OS).
$ cat /etc/my.cnf.d/secrets-backup.cnf
# Security credentials for backup.
[mysqldump]
user=backupuser
password=cYj0GFBEdqdreZEl
[xtrabackup]
user=backupuser
password=cYj0GFBEdqdreZEl
[mysqld]
wsrep_sst_auth=backupuser:cYj0GFBEdqdreZElI ClusterControl-noden skal du redigere /etc/cmon.d/cmon_ID.cnf-konfigurationsfilen (hvor ID er Cluster ID-nummeret), og sørg for, at den indeholder de samme legitimationsoplysninger, der er gemt i secrets-backup. cnf.
$ cat /etc/cmon.d/cmon_8.cnf
backup_user=backupuser
backup_user_password=cYj0GFBEdqdreZEl
basedir=/usr
cdt_path=/
cluster_id=8
...Enhver ændring af denne fil kræver en genstart af cmon-tjenesten:
$ service cmon restartTjek databasereplikeringsparametrene for at sikre, at du har GTID og binær logning aktiveret.
Databasekonfiguration
I databasenoden skal du kontrollere filen /etc/my.cnf (for RedHat-baseret OS) eller /etc/mysql/my.cnf (for Debian-baseret OS) for at se konfigurationen relateret til replikeringsproces.
Percona XtraDB:
$ cat /etc/my.cnf
# REPLICATION SPECIFIC
server_id=4002
binlog_format=ROW
log_bin = /var/lib/mysql-binlog/binlog
log_slave_updates = ON
gtid_mode = ON
enforce_gtid_consistency = true
relay_log = relay-log
expire_logs_days = 7MariaDB Galera Cluster:
$ cat /etc/my.cnf
# REPLICATION SPECIFIC
server_id=9000
binlog_format=ROW
log_bin = /var/lib/mysql-binlog/binlog
log_slave_updates = ON
relay_log = relay-log
wsrep_gtid_domain_id=9000
wsrep_gtid_mode=ON
gtid_domain_id=9000
gtid_strict_mode=ON
gtid_ignore_duplicates=ON
expire_logs_days = 7Ind at kontrollere konfigurationsfilerne, kan du kontrollere, om det er aktiveret i ClusterControl UI. Gå til ClusterControl -> Vælg Cluster -> Noder. Der skulle du have sådan noget her:

"Master"-rollen tilføjet i den første node betyder, at binær logning er aktiveret.
Aktivering af binær logning
Hvis du ikke har den binære logning aktiveret, skal du gå til ClusterControl -> Vælg Klynge -> Noder -> Nodehandlinger -> Aktiver binær logning.
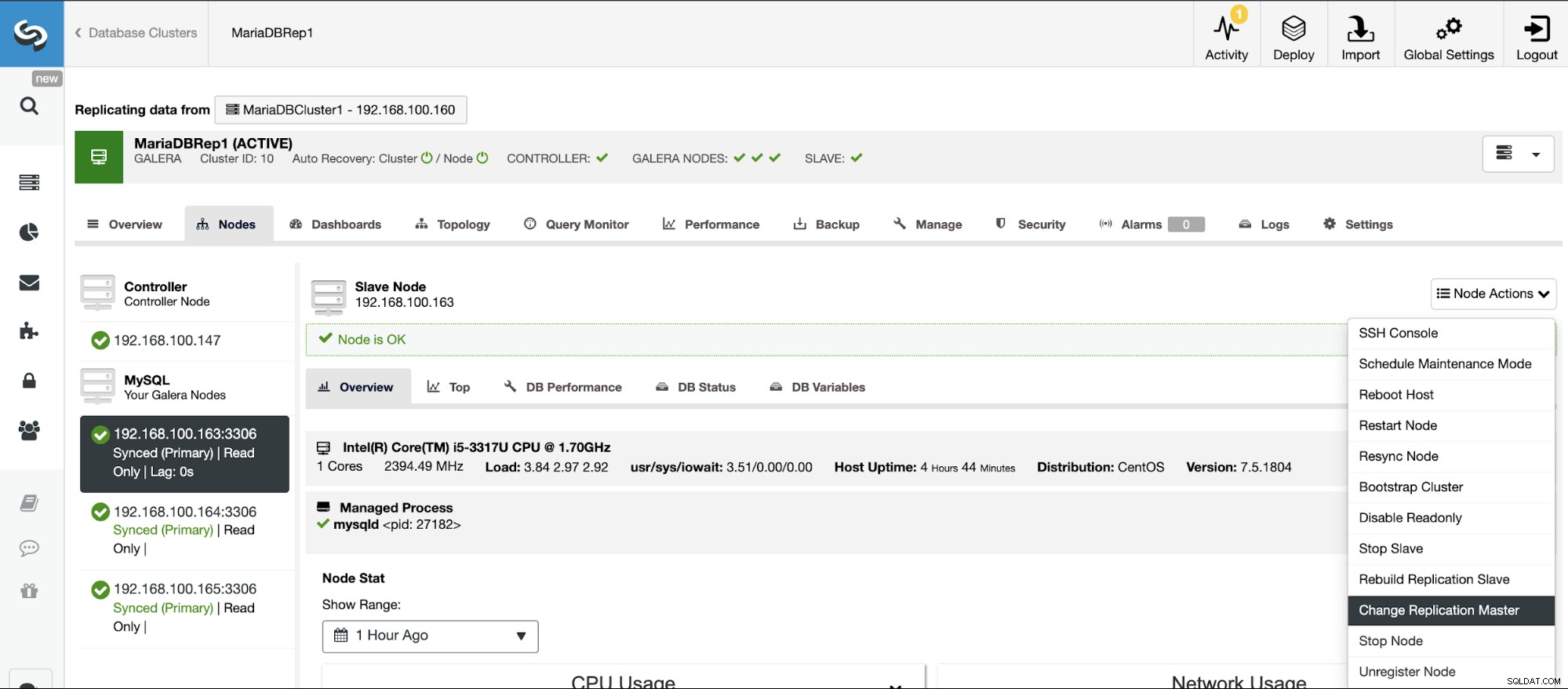
Derefter skal du angive den binære logopbevaring og stien til lagring det. Du skal også angive, om du vil have ClusterControl til at genstarte databasenoden efter konfiguration af den, eller om du foretrækker at genstarte den selv.
Husk på, at aktivering af binær logning altid kræver en genstart af databasetjenesten .
Oprettelse af slaveklyngen fra ClusterControl GUI
For at oprette en ny slaveklynge skal du gå til ClusterControl -> Vælg Cluster -> Cluster Actions -> Create Slave Cluster.
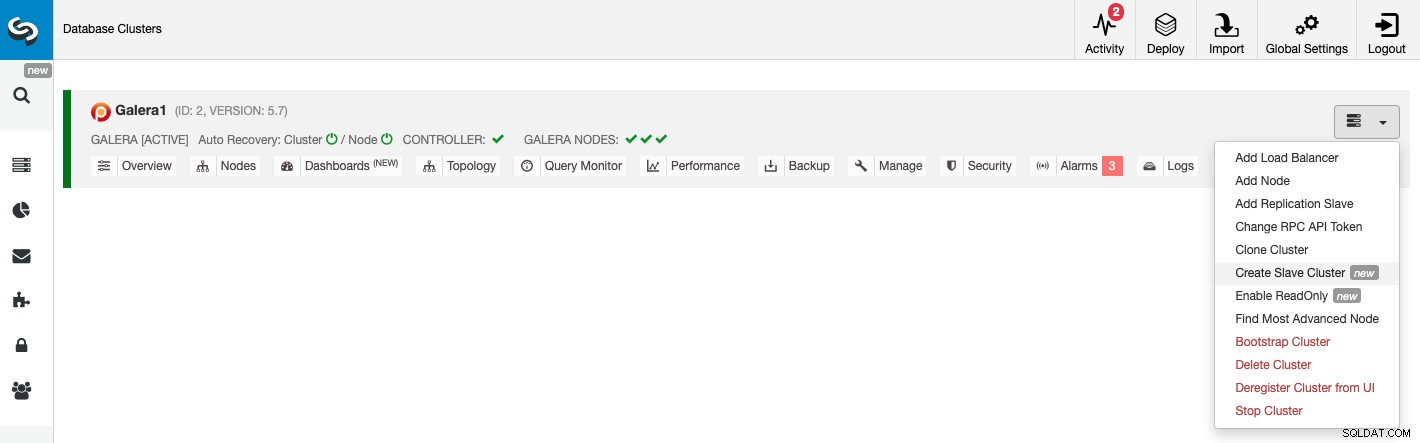
Slaveklyngen kan oprettes ved at streame data fra den aktuelle masterklynge eller ved at bruge en eksisterende backup.
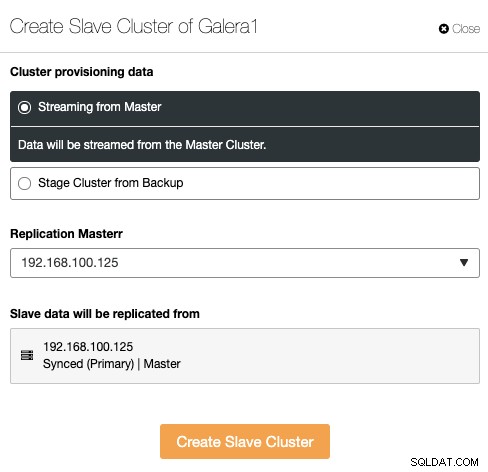
I dette afsnit skal du også vælge masterknudepunktet for den aktuelle klynge hvorfra dataene vil blive replikeret.
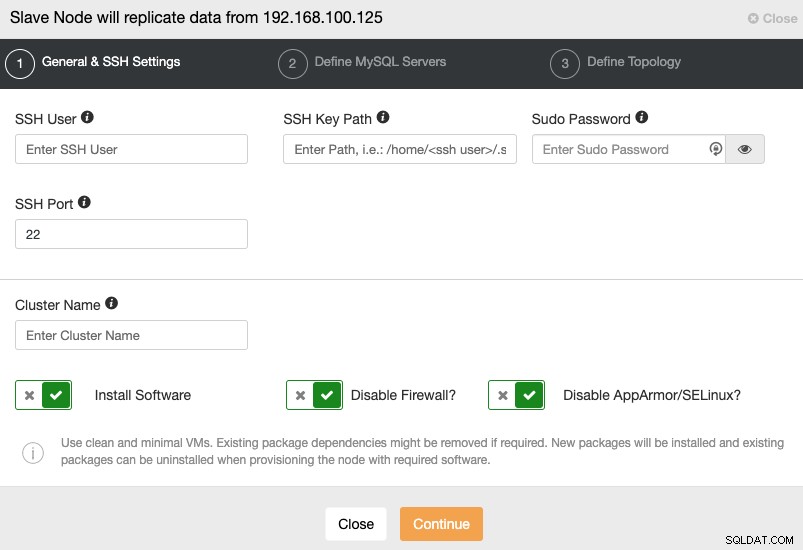
Når du går til næste trin, skal du angive Bruger, Nøgle eller Adgangskode og port for at forbinde med SSH til dine servere. Du skal også have et navn til din slaveklynge, og hvis du ønsker, at ClusterControl skal installere den tilsvarende software og konfigurationer for dig.
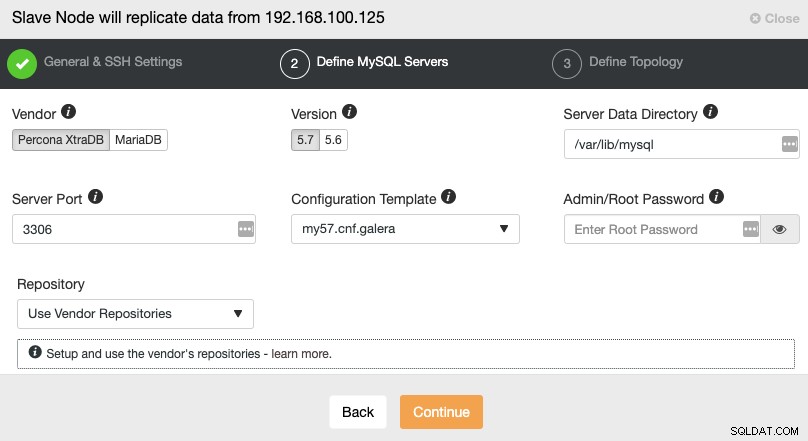
Efter opsætning af SSH-adgangsoplysningerne skal du definere databaseleverandøren og version, datadir, databaseport og administratoradgangskoden. Sørg for, at du bruger samme leverandør/version og legitimationsoplysninger som brugt af Master Cluster. Du kan også angive, hvilket lager der skal bruges.
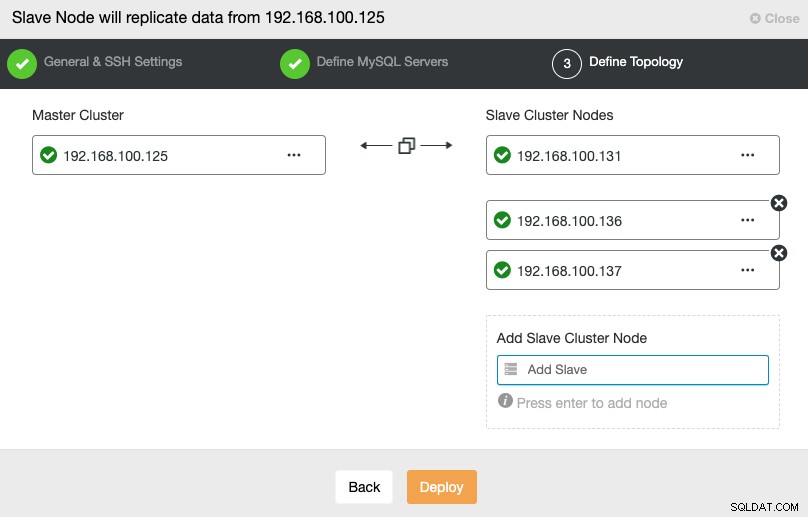
I dette trin skal du tilføje servere til den nye slaveklynge. Til denne opgave kan du indtaste både IP-adresse eller værtsnavn for hver databasenode.
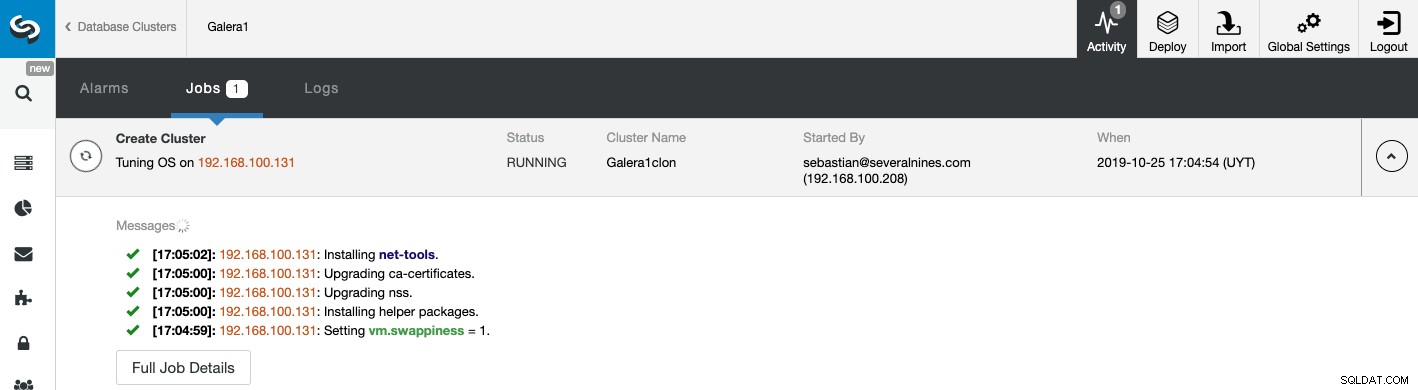
Du kan overvåge status for oprettelsen af din nye slaveklynge fra ClusterControl aktivitetsmonitor. Når opgaven er færdig, kan du se klyngen på hovedskærmen til ClusterControl.
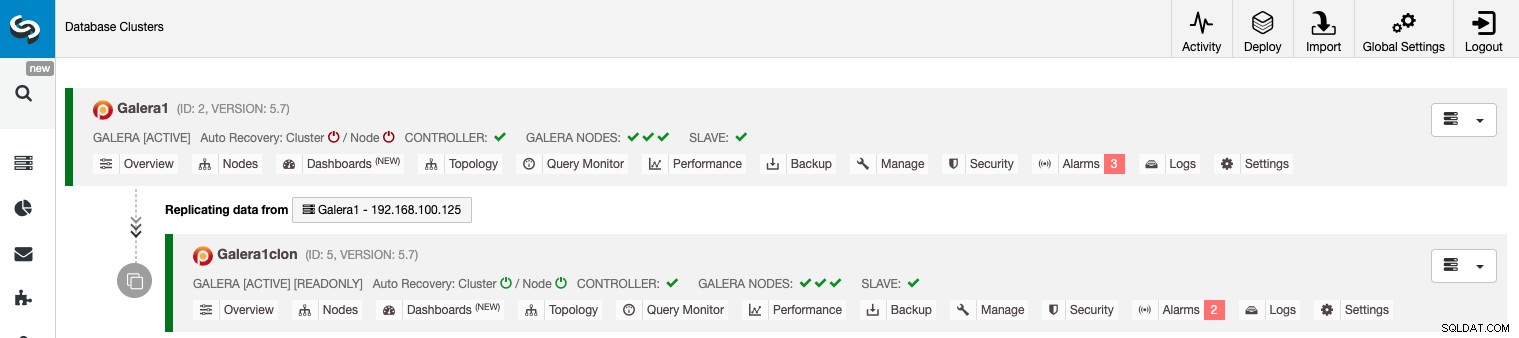
Håndtering af klynge-til-klynge-replikering ved hjælp af ClusterControl GUI
Nu har du din klynge-til-klynge-replikering oppe at køre, og der er forskellige handlinger at udføre på denne topologi ved hjælp af ClusterControl.
Konfigurer Active-Active Clusters
Som du kan se, er slaveklyngen som standard sat op i skrivebeskyttet tilstand. Det er muligt at deaktivere skrivebeskyttet flag på noderne én efter én fra ClusterControl UI, men husk, at Active-Active clustering kun anbefales, hvis applikationer kun berører usammenhængende datasæt på begge klynge, da MySQL/MariaDB ikke gør det. tilbyde enhver konfliktdetektion eller løsning.
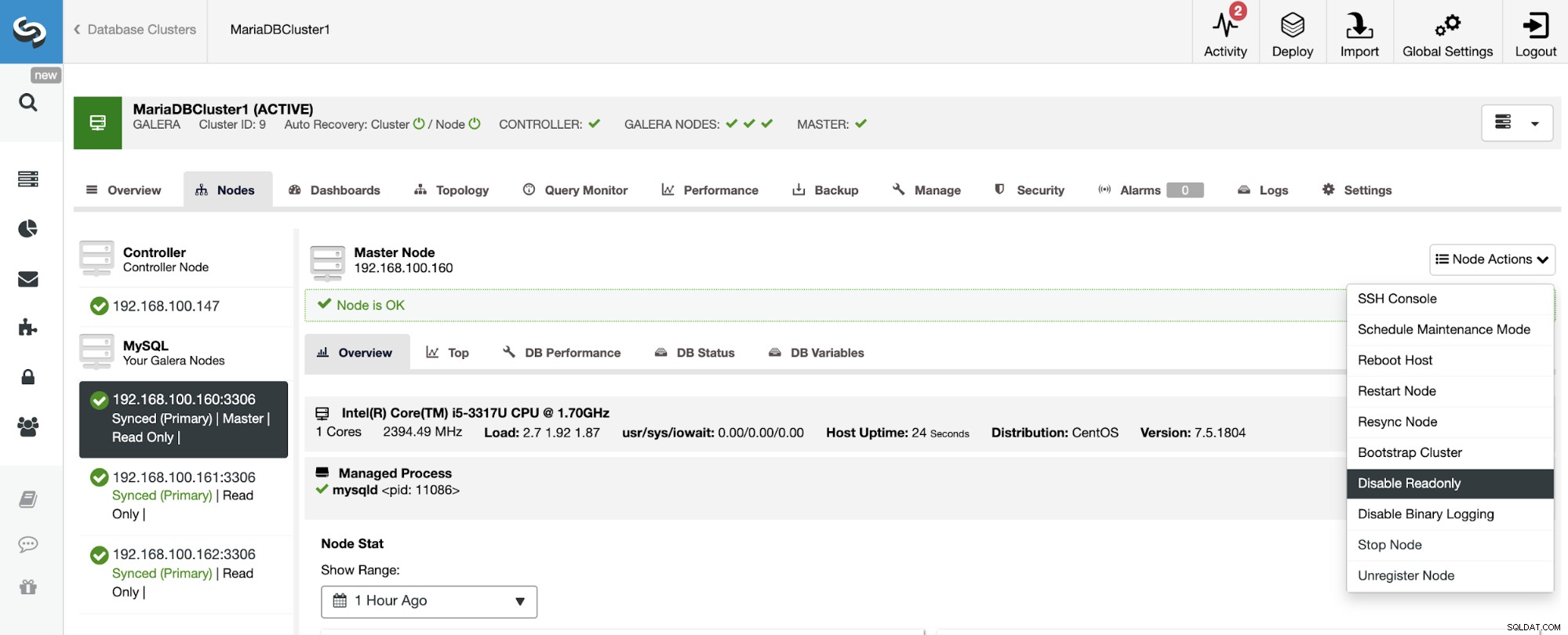
For at deaktivere skrivebeskyttet tilstand skal du gå til ClusterControl -> Vælg slave Klynge -> Noder. I dette afsnit skal du vælge hver node og bruge indstillingen Deaktiver skrivebeskyttet.
Genopbygning af en slaveklynge
For at undgå uoverensstemmelser, hvis du vil genopbygge en slaveklynge, skal dette være en skrivebeskyttet klynge, det betyder, at alle noder skal være i skrivebeskyttet tilstand.
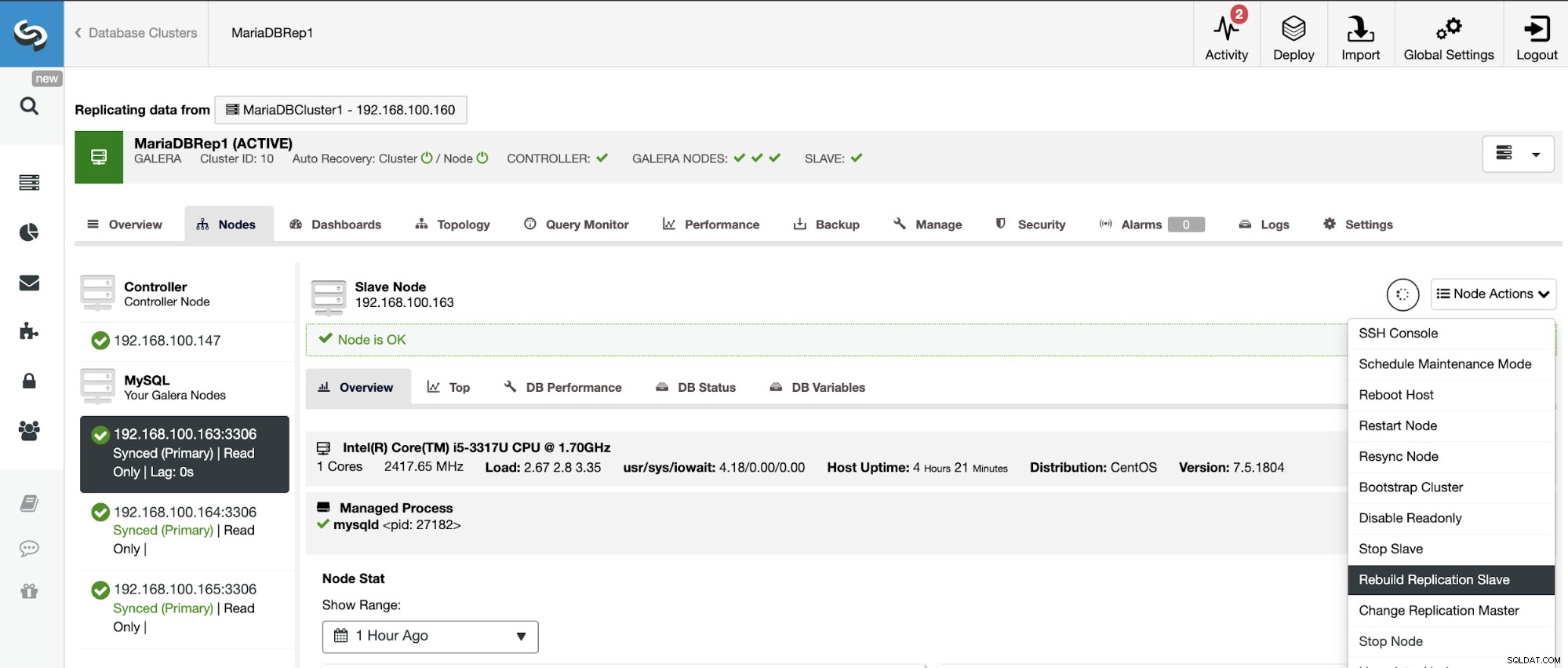
Gå til ClusterControl -> Vælg Slaveklynge -> Noder -> Vælg Node forbundet til masterklyngen -> Nodehandlinger -> Genopbyg replikeringsslave.
Topologiændringer
Hvis du har følgende topologi:
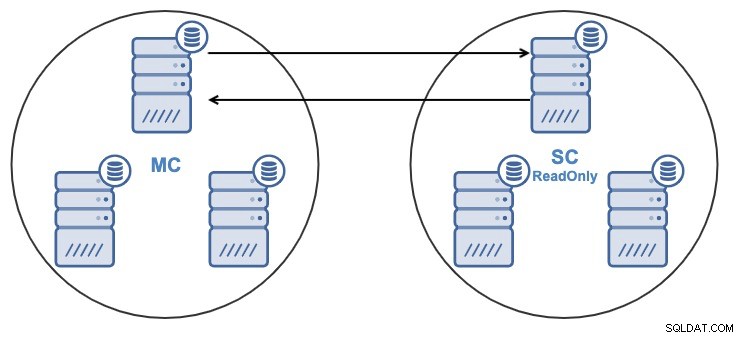
Og af en eller anden grund vil du ændre replikeringsnoden i Master Klynge. Det er muligt at ændre den masterknude, der bruges af slaveklyngen, til en anden masterknude i masterklyngen.
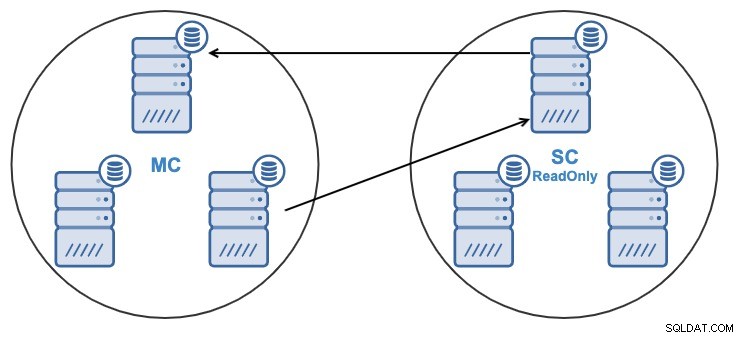
For at blive betragtet som en masterknude skal den have den binære logning aktiveret .
Gå til ClusterControl -> Vælg Slave Cluster -> Noder -> Vælg Node forbundet til masterklyngen -> Nodehandlinger -> Stop slave/start slave.
Stop/start replikeringsslave
Du kan stoppe og starte replikeringsslaver på en nem måde ved hjælp af ClusterControl.
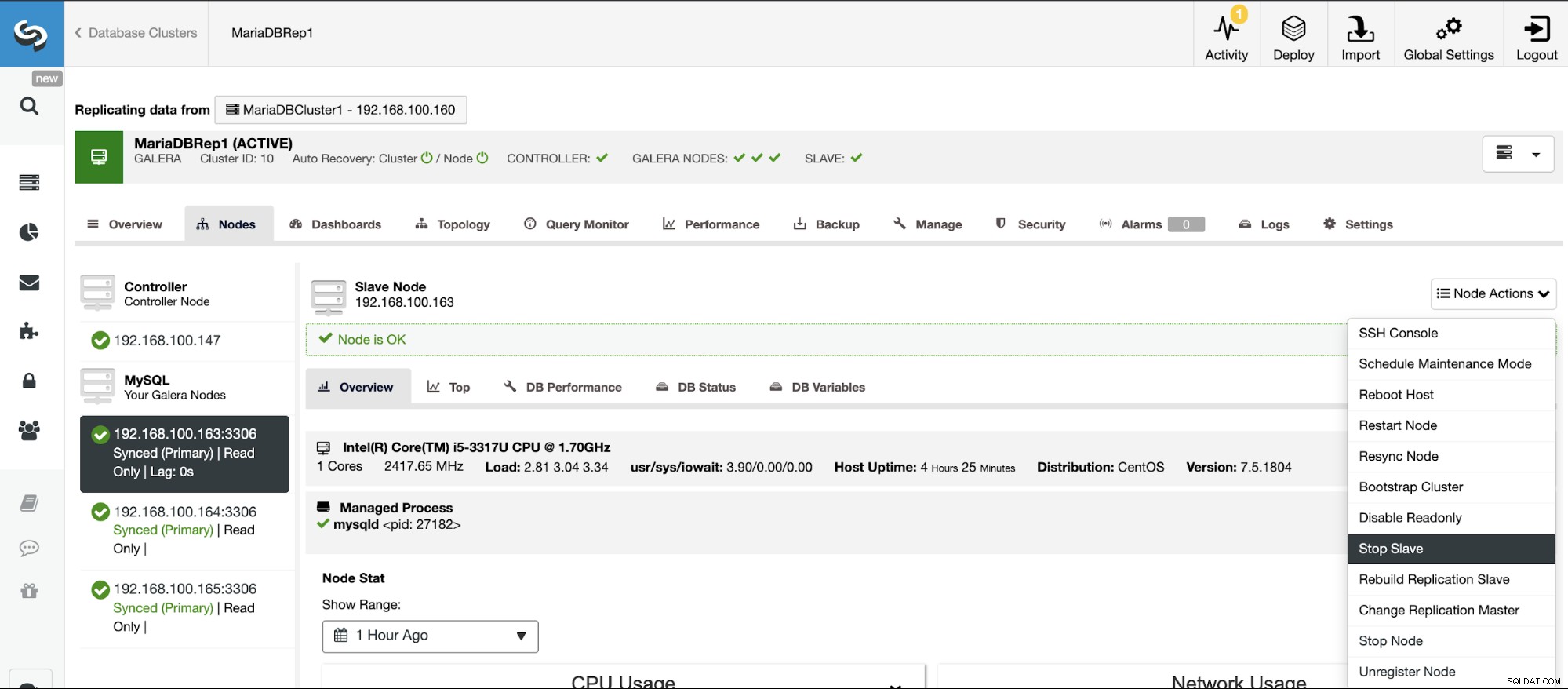
Gå til ClusterControl -> Vælg Slaveklynge -> Noder -> Vælg Node forbundet til masterklyngen -> Nodehandlinger -> Stop slave/start slave.
Nulstil replikeringsslave
Ved at bruge denne handling kan du nulstille replikeringsprocessen ved at bruge RESET SLAVE eller RESET SLAVE ALL. Forskellen mellem dem er, RESET SLAVE ændrer ikke nogen replikeringsparameter som masterhost, port og legitimationsoplysninger. For at slette disse oplysninger skal du bruge RESET SLAVE ALL, der fjerner al replikeringskonfigurationen, så ved at bruge denne kommando vil linket Cluster-to-Cluster Replikering blive ødelagt.
Før du bruger denne funktion, skal du stoppe replikeringsprocessen (se venligst den forrige funktion).
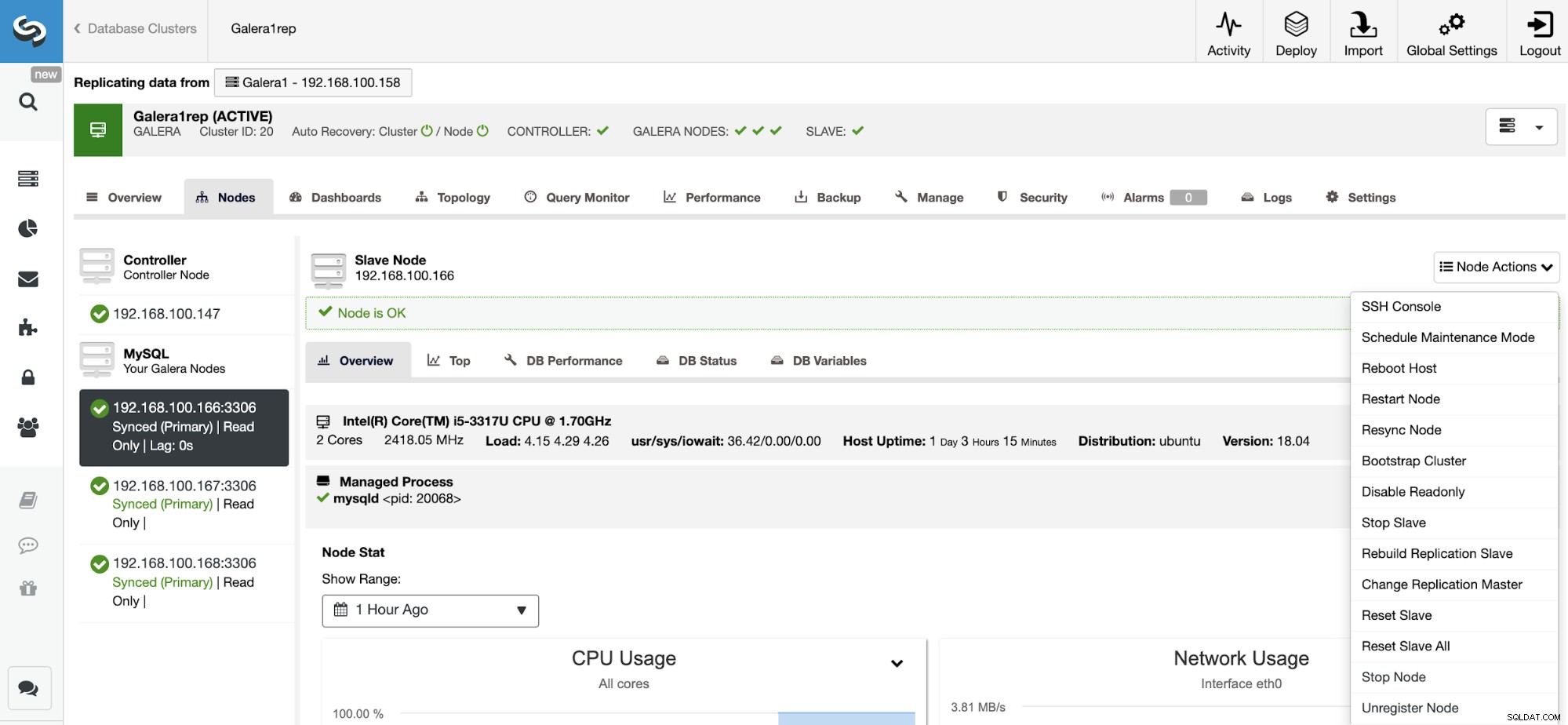
Gå til ClusterControl -> Vælg Slaveklynge -> Noder -> Vælg Node forbundet til masterklyngen -> Nodehandlinger -> Nulstil slave/nulstil slave alle.
Håndtering af klynge-til-klynge-replikering ved hjælp af ClusterControl CLI
I det forrige afsnit kunne du se, hvordan du administrerer en Cluster-to-Cluster-replikering ved hjælp af ClusterControl-brugergrænsefladen. Lad os nu se, hvordan man gør det ved at bruge kommandolinjen.
Bemærk:Som vi nævnte i begyndelsen af denne blog, antager vi, at du har ClusterControl installeret, og at Master Cluster blev implementeret ved hjælp af det.
Opret slaveklyngen
Lad os først se en eksempelkommando til at oprette en slaveklynge ved at bruge ClusterControl CLI:
$ s9s cluster --create --cluster-name=Galera1rep --cluster-type=galera --provider-version=10.4 --nodes="192.168.100.166;192.168.100.167;192.168.100.168" --os-user=root --os-key-file=/root/.ssh/id_rsa --db-admin=root --db-admin-passwd=xxxxxxxx --vendor=mariadb --remote-cluster-id=11 --logNu har du din oprettelsesslave-proces kørende, lad os se hver brugt parameter:
- Klynge:At liste og manipulere klynger.
- Opret:Opret og installer en ny klynge.
- Klyngenavn:Navnet på den nye slaveklynge.
- Klyngetype:Den type klynge, der skal installeres.
- Udbyder-version:Softwareversionen.
- Noder:Liste over de nye noder i slaveklyngen.
- Os-bruger:Brugernavnet til SSH-kommandoerne.
- Os-key-file:Nøglefilen, der skal bruges til SSH-forbindelse.
- Db-admin:Databaseadministratorens brugernavn.
- Db-admin-passwd:Adgangskoden til databaseadministratoren.
- Remote-cluster-id:Master Cluster ID for Cluster-to-Cluster-replikeringen.
- Log:Vent og overvåg jobmeddelelser.
Ved at bruge --log-flaget vil du være i stand til at se logfilerne i realtid:
Verifying job parameters.
Checking ssh/sudo on 3 hosts.
All 3 hosts are accessible by SSH.
192.168.100.166: Checking if host already exists in another cluster.
192.168.100.167: Checking if host already exists in another cluster.
192.168.100.168: Checking if host already exists in another cluster.
192.168.100.157:3306: Binary logging is enabled.
192.168.100.158:3306: Binary logging is enabled.
Creating the cluster with the following:
wsrep_cluster_address = 'gcomm://192.168.100.166,192.168.100.167,192.168.100.168'
Calling job: setupServer(192.168.100.166).
192.168.100.166: Checking OS information.
…
Caching config files.
Job finished, all the nodes have been added successfully.Konfigurer Active-Active Clusters
Som du kunne se tidligere, kan du deaktivere skrivebeskyttet tilstand i den nye klynge ved at deaktivere den i hver node, så lad os se, hvordan du gør det fra kommandolinjen.
$ s9s node --set-read-write --nodes="192.168.100.166" --cluster-id=16 --logLad os se hver parameter:
- Node:Til at håndtere noder.
- Set-read-write:Indstil noden til Read-Write-tilstand.
- Noder:Den node, hvor den skal ændres.
- Klynge-id:ID'et for den klynge, hvori noden er.
Derefter vil du se:
192.168.100.166:3306: Setting read_only=OFF.Genopbygning af en slaveklynge
Du kan genopbygge en slaveklynge ved hjælp af følgende kommando:
$ s9s replication --stage --master="192.168.100.157:3306" --slave="192.168.100.166:3306" --cluster-id=19 --remote-cluster-id=11 --logParametrene er:
- Replikering:Til at overvåge og kontrollere datareplikering.
- Stage:Fase/genopbygge en replikeringsslave.
- Master:Replikeringsmasteren i masterklyngen.
- Slave:Replikeringsslaven i slaveklyngen.
- Cluster-id:The Slave Cluster ID.
- Remote-cluster-id:Master Cluster ID.
- Log:Vent og overvåg jobmeddelelser.
Jobloggen skal ligne denne:
Rebuild replication slave 192.168.100.166:3306 from master 192.168.100.157:3306.
Remote cluster id = 11
Shutting down Galera Cluster.
192.168.100.166:3306: Stopping node.
192.168.100.166:3306: Stopping mysqld (timeout=60, force stop after timeout=true).
192.168.100.166: Stopping MySQL service.
192.168.100.166: All processes stopped.
192.168.100.166:3306: Stopped node.
192.168.100.167:3306: Stopping node.
192.168.100.167:3306: Stopping mysqld (timeout=60, force stop after timeout=true).
192.168.100.167: Stopping MySQL service.
192.168.100.167: All processes stopped.
…
192.168.100.157:3306: Changing master to 192.168.100.166:3306.
192.168.100.157:3306: Changed master to 192.168.100.166:3306
192.168.100.157:3306: Starting slave.
192.168.100.157:3306: Collecting replication statistics.
192.168.100.157:3306: Started slave successfully.
192.168.100.166:3306: Starting node
Writing file '192.168.100.167:/etc/mysql/my.cnf'.
Writing file '192.168.100.167:/etc/mysql/secrets-backup.cnf'.
Writing file '192.168.100.168:/etc/mysql/my.cnf'.Topologiændringer
Du kan ændre din topologi ved at bruge en anden node i Master Cluster, hvorfra du replikerer dataene, så du for eksempel kan køre:
$ s9s replication --failover --master="192.168.100.161:3306" --slave="192.168.100.163:3306" --cluster-id=10 --remote-cluster-id=9 --logLad os tjekke de anvendte parametre.
- Replikering:Til at overvåge og kontrollere datareplikering.
- Failover:Tag rollen som mester fra en mislykket/gammel mester.
- Master:Den nye replikeringsmaster i masterklyngen.
- Slave:Replikationsslaven i slaveklyngen.
- Klynge-id:ID for slaveklyngen.
- Remote-Cluster-id:Master-klyngens ID.
- Log:Vent og overvåg jobmeddelelser.
Du vil se denne log:
192.168.100.161:3306 belongs to cluster id 9.
192.168.100.163:3306: Changing master to 192.168.100.161:3306
192.168.100.163:3306: My master is 192.168.100.160:3306.
192.168.100.161:3306: Sanity checking replication master '192.168.100.161:3306[cid:9]' to be used by '192.168.100.163[cid:139814070386698]'.
192.168.100.161:3306: Executing GRANT REPLICATION SLAVE ON *.* TO 'cmon_replication'@'192.168.100.163'.
Setting up link between 192.168.100.161:3306 and 192.168.100.163:3306
192.168.100.163:3306: Stopping slave.
192.168.100.163:3306: Successfully stopped slave.
192.168.100.163:3306: Setting up replication using MariaDB GTID: 192.168.100.161:3306->192.168.100.163:3306.
192.168.100.163:3306: Changing Master using master_use_gtid=slave_pos.
192.168.100.163:3306: Changing master to 192.168.100.161:3306.
192.168.100.163:3306: Changed master to 192.168.100.161:3306
192.168.100.163:3306: Starting slave.
192.168.100.163:3306: Collecting replication statistics.
192.168.100.163:3306: Started slave successfully.
192.168.100.160:3306: Flushing logs to update 'SHOW SLAVE HOSTS'Stop/start replikeringsslave
Du kan stoppe med at replikere dataene fra Master Cluster på denne måde:
$ s9s replication --stop --slave="192.168.100.166:3306" --cluster-id=19 --logDu vil se dette:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Stopping slave.
192.168.100.166:3306: Successfully stopped slave.Og nu kan du starte det igen:
$ s9s replication --start --slave="192.168.100.166:3306" --cluster-id=19 --logSå du vil se:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Starting slave.
192.168.100.166:3306: Collecting replication statistics.
192.168.100.166:3306: Started slave successfully.Lad os nu tjekke de brugte parametre.
- Replikering:Til at overvåge og kontrollere datareplikering.
- Stop/Start:For at få slaven til at stoppe/begynde at replikere.
- Slave:Replikationsslaveknuden.
- Klynge-id:ID'et for den klynge, hvori slaveknuden er.
- Log:Vent og overvåg jobmeddelelser.
Nulstil replikeringsslave
Ved at bruge denne kommando kan du nulstille replikeringsprocessen ved at bruge RESET SLAVE eller RESET SLAVE ALL. For mere information om denne kommando, tjek venligst brugen af denne i det forrige ClusterControl UI-afsnit.
Før du bruger denne funktion, skal du stoppe replikeringsprocessen (se den forrige kommando).
NULSTIL SLAVE:
$ s9s replication --reset --slave="192.168.100.166:3306" --cluster-id=19 --logLoggen skal være sådan:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Executing 'RESET SLAVE'.
192.168.100.166:3306: Command 'RESET SLAVE' succeeded.NULSTIL SLAVE ALLE:
$ s9s replication --reset --force --slave="192.168.100.166:3306" --cluster-id=19 --logOg denne log skulle være:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Executing 'RESET SLAVE /*!50500 ALL */'.
192.168.100.166:3306: Command 'RESET SLAVE /*!50500 ALL */' succeeded.Lad os se de brugte parametre for både RESET SLAVE og RESET SLAVE ALL.
- Replikering:Til at overvåge og kontrollere datareplikering.
- Nulstil:Nulstil slavenoden.
- Force:Ved at bruge dette flag vil du bruge kommandoen RESET SLAVE ALL på slavenoden.
- Slave:Replikeringsslaveknuden.
- Cluster-id:The Slave Cluster ID.
- Log:Vent og overvåg jobmeddelelser.
Konklusion
Denne nye ClusterControl-funktion giver dig mulighed for hurtigt at oprette Cluster-to-Cluster-replikering og administrere det på en nem og venlig måde. Dette miljø vil forbedre din database-/klyngetopologi, og det ville være nyttigt til en katastrofegenetableringsplan, testmiljø og endnu flere muligheder nævnt i oversigtsbloggen.