Introduktion
Du må allerede have hørt udtrykket "Samling" i SQL Server. Sortering er en konfiguration, der bestemmer, hvordan karakterdatasortering udføres. Dette er en vigtig indstilling, som har en enorm indflydelse på, hvordan SQL Server-databasemotoren opfører sig i håndteringen af karakterdata. I denne artikel sigter vi mod at diskutere sammenstillinger generelt og vise nogle få eksempler på håndtering af sammenstillinger.
Hvor finder jeg sorteringer?
Du kan finde SQL-sortering på server-, database- og kolonneniveau. En anden vigtig ting at vide er, at sorteringsindstillingen ikke behøver at være den samme på server-, database- og kolonneniveau. Du kan også opdatere dine forespørgsler for at bruge specifikke sorteringer. Det er på dette tidspunkt, du vil indse vigtigheden af at konfigurere den korrekte sortering på tværs af dit miljø, da der er stor mulighed for uventede problemer, hvis sorteringen ikke er konsistent.
Hvad er de forskellige typer af sorteringer tilgængelige?
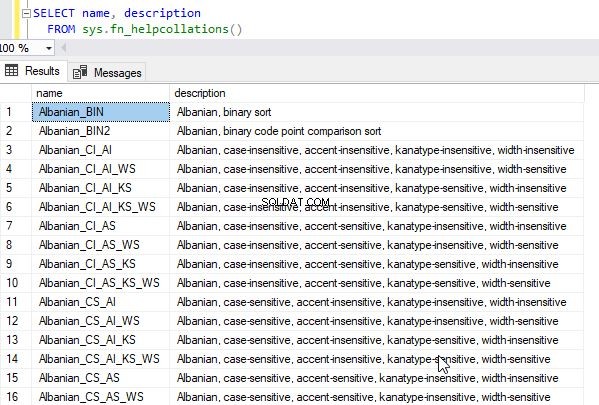
Du kan få den fulde liste over tilgængelige sorteringer ved at søge efter systemfunktionen sys.fn_helpcollations()
select * from sys.fn_helpcollations()
Dette vil returnere følgende output.
Hvis du leder efter specifikke sammenstillinger efter sprog, kan du filtrere navnet yderligere. Hvis du f.eks. leder efter den maori-understøttede sortering, kan du bruge følgende forespørgsel.
select * from sys.fn_helpcollations()
where name like '%Maori%' Dette vil returnere følgende output.
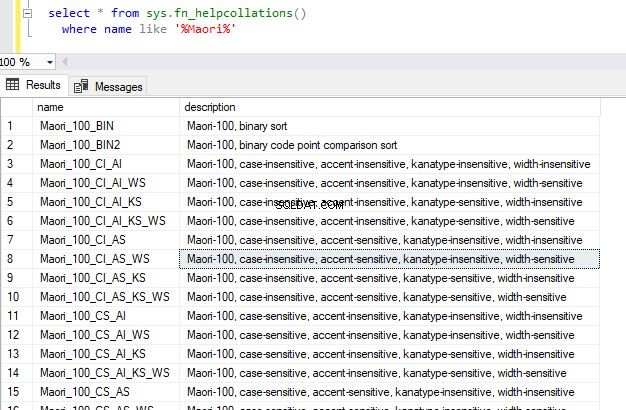
På denne måde kan du tjekke for de understøttede sorteringer til den sortering, du vælger. Ved blot at forespørge på systemfunktionen fn_helpcollations() blev der returneret 5508 rækker i alt, hvilket betyder, at der er så mange understøttede sorteringer. Bemærk, at dette dækker et flertal af sprogene rundt om i verden.
Hvad er de forskellige muligheder, du ser i sorteringsnavnet?
For eksempel, i denne sortering:Maori_100_CS_AI_KS_WS_SC_UTF8, kan du se de forskellige muligheder i sorteringsnavnet.
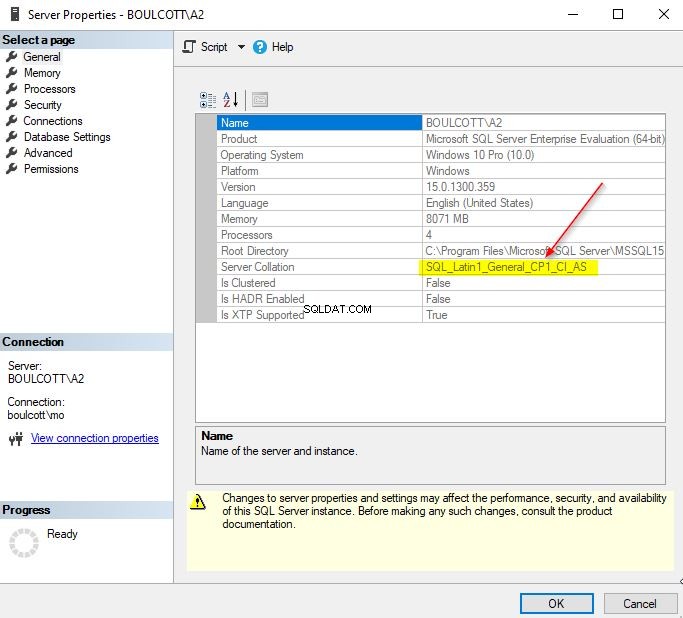
CS – skelner mellem store og små bogstaver
AI – accentufølsom
KS – kana type-sensitive
WS – breddefølsom
SC – supplerende tegn
UTF8 – Kodningsstandard
Baseret på typen af en valgt sorteringsindstilling vil SQL Server-databasemotoren fungere anderledes, når det drejer sig om tegndata til sorterings- og søgeoperationer. For eksempel, hvis du bruger den store og små bogstaver i SQL-sorteringen, vil databasemotoren opføre sig anderledes for en forespørgselsoperation, der leder efter "Adam" eller "adam". Forudsat at du har en tabel kaldet "sample", og der er en fornavnskolonne med en bruger "adam". Forespørgslen nedenfor giver ingen resultater, hvis der ikke er nogen række med fornavnet "Adam". Dette er på grund af "CS-Case sensitive"-indstillingen i sorteringen.
select * from sample
where firstname like '%Adam%' Med dette enkle eksempel kan du forstå betydningen af at vælge den korrekte SQL-sorteringsindstilling. Sørg for, at du forstår applikationskravene, før du vælger sortering i første omgang.
Find sortering på SQL Server-instans
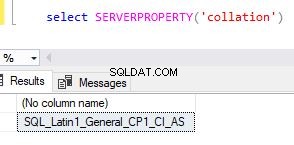
Du kan få serversorteringen i SQL Server Management Studio (SSMS) ved at højreklikke på SQL-forekomsten og derefter klikke på "Egenskaber" og markere fanen "Generelt". Denne sortering er valgt som standard ved installationen af SQL Server.
Alternativt kan du bruge serveregenskabsindstillingen til at finde sorteringsværdien.
select SERVERPROPERTY('collation'),
Find samling af en SQL-database
I SSMS skal du højreklikke på SQL-databasen og gå til "Egenskaber". Du kan kontrollere sorteringsdetaljerne på fanen "Generelt" som vist nedenfor.
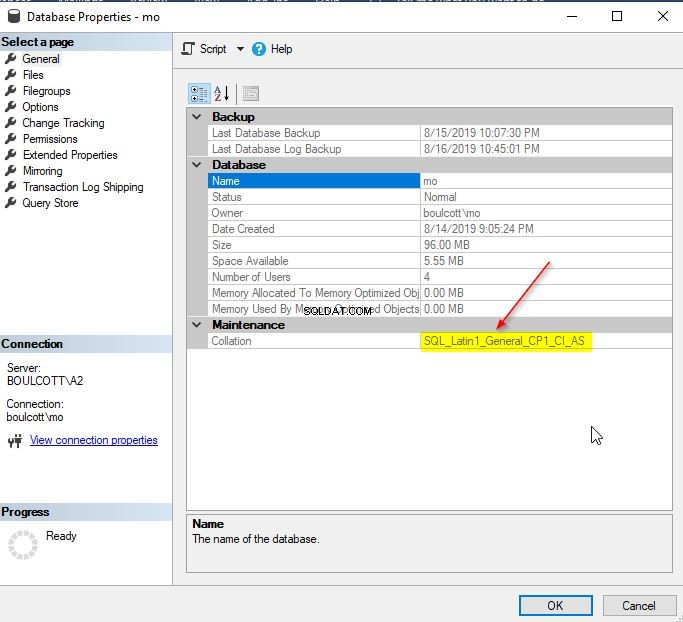
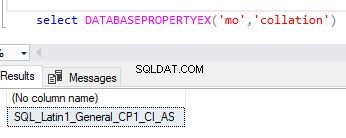
Alternativt kan du bruge databasepropertyex-funktionen til at få oplysninger om en databasesortering.
select DATABASEPROPERTYEX('Your DB Name','collation')
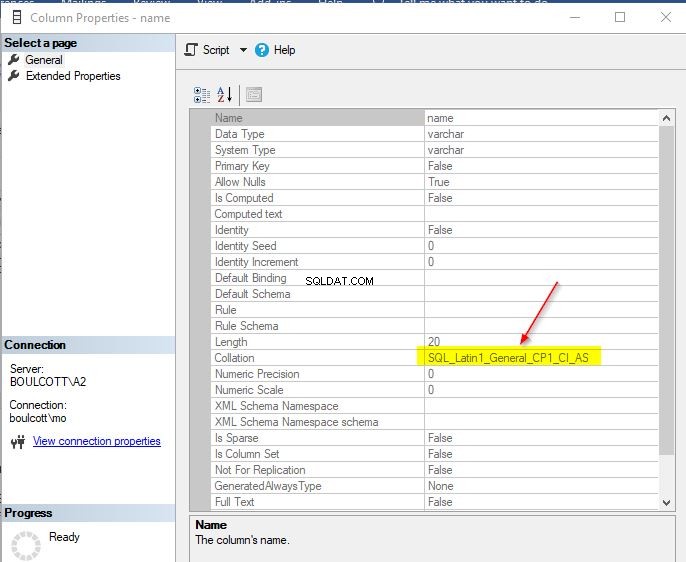
Find samling af en kolonne i en tabel
I SSMS skal du gå til tabellen, derefter kolonner og til sidst højreklikke på de enkelte kolonner for at se "Egenskaber". Hvis kolonnen er af en karakterdatatype, vil du se detaljer om sorteringen.
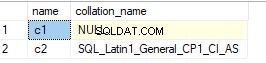
Men samtidig, hvis du tjekker værdien for en ikke-tegn datatype, vil sorteringsværdien være nul. Nedenfor er et skærmbillede af en kolonne, der har int datatype.
Alternativt kan du bruge en eksempelforespørgsel nedenfor til at se sorteringsværdierne for kolonner.
select sc.name, sc.collation_name from sys.columns sc inner join sys.tables t on sc.object_id=t.object_id where t.name='t1' – enter your table name
Nedenfor er output for forespørgslen.
Prøver forskellige sorteringer i SQL-forespørgsler
I dette afsnit vil vi se, hvordan sorteringsrækkefølgen bliver påvirket, når forskellige sorteringer bruges i forespørgsler. Der oprettes en eksempeltabel med 2 kolonner som vist nedenfor.
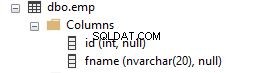
Kolonnen fname har standardsorteringen af den database, den tilhører. I dette tilfælde er sorteringen SQL_Latin1_General_CP1_CI_AS.
For at indsætte et par poster i tabellen skal du bruge en forespørgsel nedenfor. Tildel dine egne værdier til parametrene.
insert into emp values (1,'mohammed') insert into emp values (2,'moinudheen') insert into emp values (3,'Mohammed') insert into emp values (4,'Moinudheen') insert into emp values (5,'MOHAMMED') insert into emp values (6,'MOINUDHEEN')
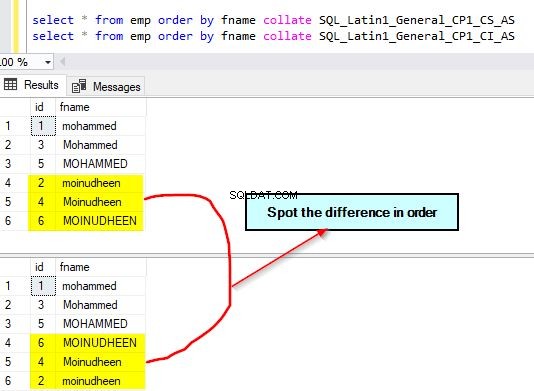
Forespørg nu emp-tabellen og sorter den efter fname-kolonnen ved hjælp af forskellige sorteringer. Vi vil bruge standardsorteringen af kolonnen til sortering samt en anden versalfølsom sortering – SQL_Latin1_General_CP1_CS_AS.
select * from emp order by fname collate SQL_Latin1_General_CP1_CS_AS select * from emp order by fname collate SQL_Latin1_General_CP1_CI_AS – this is default
Outputtet for disse forespørgsler er angivet nedenfor. Bemærk forskellen i den anvendte sortering. Vi bruger store og små bogstaver i stedet for ufølsomme.
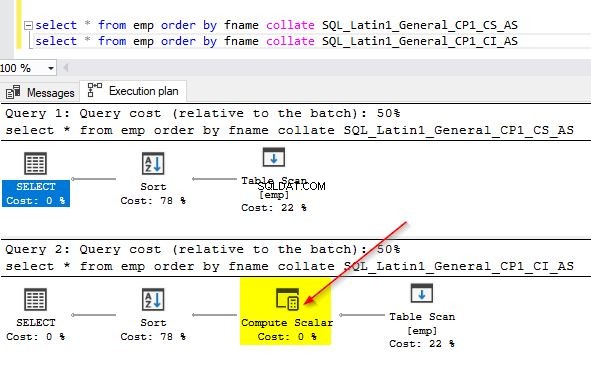
Du kan også tjekke forespørgselsplanerne for begge disse forespørgsler for at se forskellen. På den første forespørgselsplan, hvor vi bruger en anden sortering end den i kolonnen, kan du bemærke den ekstra "Compute Scalar"-operator.
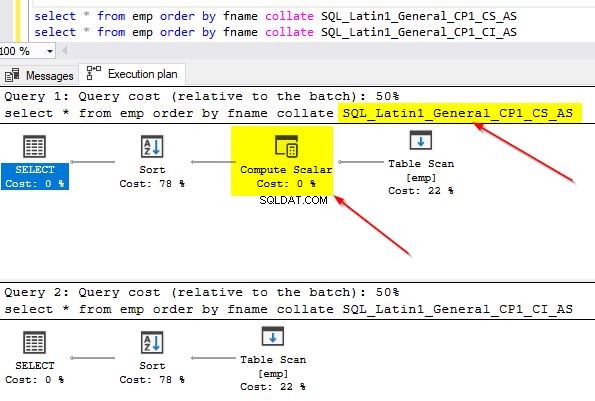
Når du holder musen over "Compute Scalar"-operatoren, vil du se de yderligere detaljer som vist nedenfor. Dette skyldes den implicitte konvertering, der finder sted, da vi bruger en anden sortering end den standard, der bruges i kolonnen.
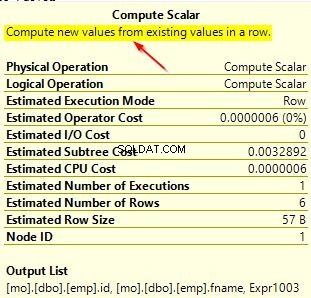
Med dette lille eksempel kan du se, hvilken indvirkning det har på forespørgselsydeevne, når du bruger sorteringer eksplicit i forespørgsler. I vores demodatabase brugte vi en simpel tabel, men forestil dig et scenarie i realtid, hvor små ændringer i forespørgselsydeevne kan forårsage uventede resultater.
Tjekker om det er muligt at ændre sortering på instansniveau
I dette afsnit vil vi gennemgå forskellige scenarier, hvor vi muligvis skal ændre standardsorteringerne. Du kan støde på situationer, hvor servere eller databaser bliver overdraget til dig, og de muligvis ikke opfylder dine standardpolitikker, så du skal muligvis ændre sorteringen. Standard SQL Server-sorteringen er SQL_Latin1_General_CP1_CI_AS. Ændring af sorteringen på SQL-instansniveau er ikke ligetil. Det kræver, at alle objekterne i brugerdatabaserne udskrives, eksporteres dataene, brugerdatabaserne droppes, masterdatabasen genopbygges med den nye kollation, oprettes brugerdatabaser og derefter importeres alle data. Så hvis du installerer nye SQL-instanser, skal du bare sørge for at få sorteringen rigtigt første gang, ellers kan du blive nødt til at udføre en masse uønsket arbejde senere. En detaljeret forklaring af stadierne til ændring af sortering på instansniveau er uden for denne artikels omfang på grund af de detaljerede trin, der kræves for hvert af stadierne.
Ændring af sortering på databaseniveau
Heldigvis er det ikke så svært at ændre sorteringen på databaseniveau som at ændre forekomstsorteringen. Vi kan opdatere sammenstillingen ved hjælp af både SSMS og T-SQL. I SSMS skal du bare højreklikke på databasen, gå til "Egenskaber" og klikke på fanen "Indstillinger" i venstre side. Der kan du se muligheden for at ændre sorteringen i rullemenuen.
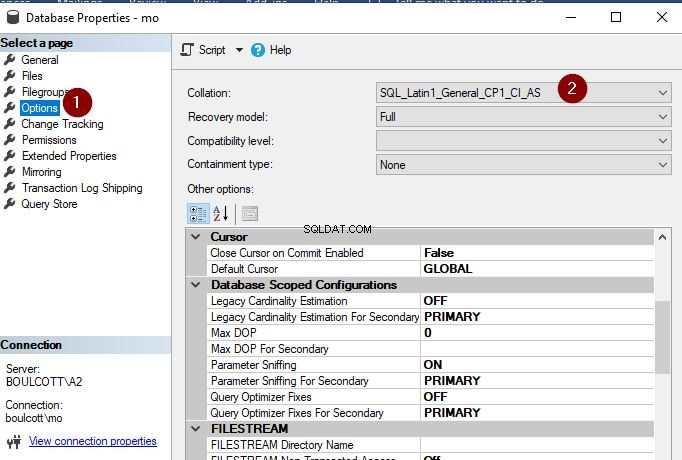
Klik på "OK" når du er færdig. Jeg har lige ændret databasesorteringen til SQL_Latin1_General_CP1_CI_AS. Bare sørg for, at du udfører denne handling, når databasen ikke er i brug, da handlingen ellers vil mislykkes som vist nedenfor.
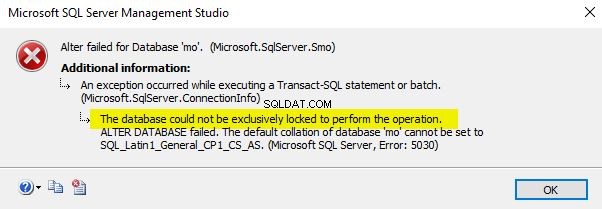
Brug den fortsættende forespørgsel for at ændre databasesorteringen ved hjælp af T-SQL.
USE master; GO ALTER DATABASE mo COLLATE SQL_Latin1_General_CP1_CS_AS; GO
Du vil bemærke, at ændring af databaseniveausorteringen ikke vil påvirke sammenstillingen af de eksisterende kolonner i tabellerne. Du kan bruge de tidligere eksempler til at kontrollere indvirkningen af sortering på sorteringsrækkefølgen for forespørgslerne nedenfor.
select * from emp order by fname collate SQL_Latin1_General_CP1_CS_AS select * from emp order by fname collate SQL_Latin1_General_CP1_CI_AS – - this is default
Fname-kolonnesorteringen forbliver den oprindelige og forbliver uændret, selv efter ændring af databaseniveausorteringen.
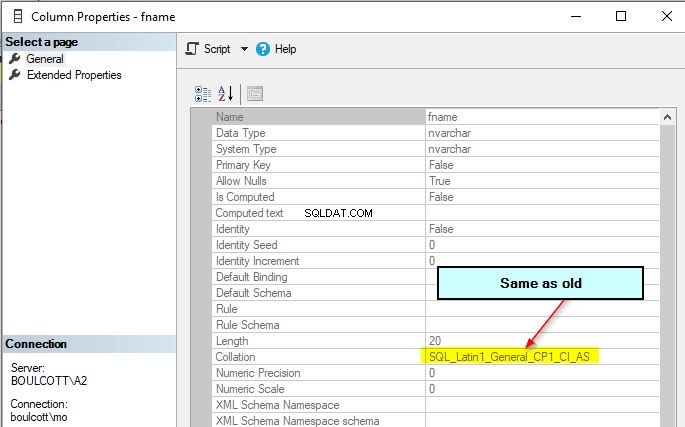
Den nye sortering på databaseniveau vil dog blive anvendt for alle nye kolonner i de nye tabeller, som du vil oprette. Så test altid ændringen af databasesorteringer grundigt, da det har en betydelig indvirkning på forespørgselsoutput eller adfærd.
Ændring af sortering på kolonneniveau
I det foregående afsnit bemærkede du, at selv efter at have ændret sorteringen på databaseniveau, forbliver sammenstillingen af de eksisterende kolonner i tabellerne uændret. I dette afsnit vil vi se, hvordan vi kan ændre sammenstillingen af de eksisterende kolonner i tabellerne, så den matcher databasesorteringen. I det forrige afsnit ændrede du databasesorteringen til SQL_Latin1_General_CP1_CS_AS. Dernæst vil du identificere alle de kolonner i brugertabellerne, der ikke matcher denne databasesortering. Du kan bruge dette script til at identificere disse kolonner.
select so.name TableName,sc.name ColumnName, sc.collation_name CollationName from sys.objects so inner join sys.columns sc on so.object_id=sc.object_id where sc.collation_name!='SQL_Latin1_General_CP1_CS_AS' and so.[type] ='U'
Eksempeloutputtet fra min demodatabase er som vist nedenfor.
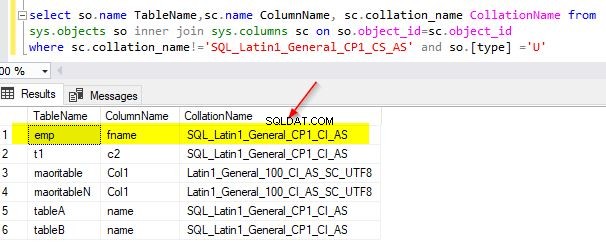
Antag, at du vil ændre sammenstillingen af den eksisterende fname-kolonne til "SQL_Latin1_General_CP1_CS_AS", så kan du bruge dette ændringsscript nedenfor.
use mo
go
ALTER TABLE dbo.emp ALTER COLUMN fname
nvarchar(20) COLLATE SQL_Latin1_General_CP1_CS_AS NULL;
GO Hvis du bruger de tidligere eksempler, hvor du kontrollerede forespørgselsydeevnen ved hjælp af forskellige sorteringer, vil du bemærke, at "compute scalar"-operatoren ikke bruges, når vi bruger den samme sortering som databasen. Se skærmbilledet nedenfor. I det tidligere eksempel kunne du have bemærket, at "Compute scalar"-operatoren blev brugt i den første udførelsesplan. Da vi ændrede kolonnesorteringen til at matche den for databasesorteringen, er der ikke behov for implicit konvertering. Du vil se operatoren "Compute scalar" i den anden forespørgsel, da den eksplicit bruger en anden sortering.
select * from emp order by fname collate SQL_Latin1_General_CP1_CS_AS – - this is default select * from emp order by fname collate SQL_Latin1_General_CP1_CI_AS
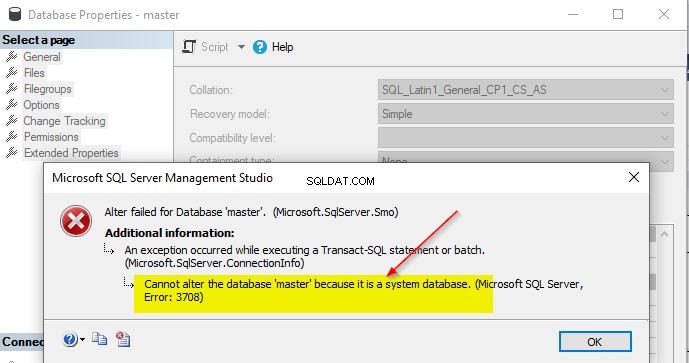
Kan vi ændre sammenstillingen af systemdatabaser?
Det er ikke muligt at ændre sammenstillingen af systemdatabaser. Hvis du forsøger at ændre sammenstillingen af systemdatabaserne – master, model, msdb eller tempdb, får du denne fejlmeddelelse.
Du skal følge de trin, der er skitseret tidligere, for at ændre sorteringen på SQL Server-instansniveau for at ændre sammenstillingen af systemdatabaserne. Det er vigtigt at få kollationerne korrekte første gang du installerer SQL Server for at undgå sådanne problemer.
Det kendte problem om sorteringskonflikt
Et andet almindeligt problem, du kan finde, er fejlen relateret til kollationskonflikt, især når du bruger midlertidige objekter. De midlertidige objekter gemmes i tempdb. At tempdb er en systemdatabase, antager sammenstillingen af SQL-instansen. Når du opretter brugerdatabaser, der har anden sortering end SQL-forekomsten, vil du løbe ind i problemer, når du bruger midlertidige objekter. Du kan også støde på problemer, mens du sammenligner kolonner i tabeller, der har forskellige sorteringer. På nuværende tidspunkt ved du allerede, at en tabel kan have kolonner med forskellige sorteringer, da vi ikke kan ændre sammenstillingen på tabelniveau. Den almindelige fejlmeddelelse, du vil bemærke, er noget i retning af "Kan ikke løse sorteringskonflikten mellem "Sortering1" og "Samling2" i lig med operation." Collation1 og Collation2 kan være enhver sortering, der bruges i en forespørgsel. Ved at bruge et simpelt eksempel kan vi lave en demo af denne kollationskonflikt. Hvis du har gennemført de foregående eksempler i denne artikel, har du allerede en tabel med navnet "emp". Du skal bare oprette en midlertidig tabel i din demodatabase og indsætte poster ved hjælp af det medfølgende eksempelscript.
create table #emptemp (id int, fname nvarchar(20)) insert into #emptemp select * from emp
Bare kør en joinforbindelse ved hjælp af begge tabeller, og du vil få denne kollationskonfliktfejl som vist nedenfor.
select e.id, et.fname from emp e inner join #emptemp et on e.fname=et.fname

Du vil bemærke, at den anvendte brugerdatabasesortering er "SQL_Latin1_General_CP1_CS_AS", og den stemmer ikke overens med serversorteringen. For at rette denne type fejl kan du ændre de kolonner, der bruges i de midlertidige objekter, til at bruge standardsorteringen af brugerdatabasen. Du kan bruge indstillingen "database_default" eller udtrykkeligt angive sorteringsnavnet på brugerdatabasen. I dette eksempel bruger vi sorteringen "SQL_Latin1_General_CP1_CS_AS". Prøv en af disse muligheder
Mulighed 1: Brug indstillingen database_default
alter table #emptemp alter column fname nvarchar(20) collate database_default
Når du er færdig, skal du køre select-sætningen igen, og fejlen vil blive rettet.
Mulighed 2: Brug eksplicit sorteringen af brugerdatabasen
alter table #emptemp alter column fname nvarchar(20) collate SQL_Latin1_General_CP1_CS_AS
Når det er gjort, skal du køre select-sætningen igen, og fejlen vil blive rettet.
Konklusion
I denne artikel fandt du ud af:
• begrebet sortering
• de forskellige tilgængelige sorteringsmuligheder
• at finde sorteringsdetaljer for enhver SQL-instans, database og kolonne
• A ARBEJDSEKSEMPEL på afprøvning af sorteringsmuligheder i SQL-forespørgsler
• ændring af kollationer på instansniveau, databaseniveau og kolonneniveau
• SÅDAN ændrer DU sortering af systemdatabaser
• en kollationskonflikt og hvordan for at rette det
Nu ved du om vigtigheden af sortering og vigtigheden af at konfigurere den korrekte sortering på SQL-instansen og også på tværs af databaseobjekterne. Test altid de forskellige scenarier på dit testmiljø, før du anvender nogen af ovenstående muligheder på dine produktionssystemer.