Det er ret almindeligt at se databaser fordelt på flere geografiske steder. Et scenarie for at udføre denne type opsætning er katastrofegendannelse, hvor dit standby-datacenter er placeret på en anden placering end dit primære datacenter. Det kan lige så godt kræves, at databaserne er placeret tættere på brugerne.
Den største udfordring for at opnå denne opsætning er ved at designe databasen på en måde, der reducerer chancen for problemer relateret til netværksopdelingen. En af løsningerne kunne være at bruge Galera Cluster i stedet for almindelig asynkron (eller semi-synkron) replikering. I denne blog vil vi diskutere fordele og ulemper ved denne tilgang. Dette er første del i en serie på to blogs. I den anden del vil vi designe det geodistribuerede Galera Cluster og se, hvordan ClusterControl kan hjælpe os med at implementere et sådant miljø.
Hvorfor Galera Cluster i stedet for Asynkron replikering til geo-distribuerede klynger?
Lad os overveje de vigtigste forskelle mellem Galera og almindelig replikering. Regelmæssig replikering giver dig kun én node at skrive til, hvilket betyder, at hver skrivning fra fjerndatacenter skal sendes over Wide Area Network (WAN) for at nå masteren. Det betyder også, at alle proxyer placeret i det eksterne datacenter skal være i stand til at overvåge hele topologien, der spænder over alle involverede datacentre, da de skal kunne fortælle, hvilken node der i øjeblikket er master.
Dette fører til antallet af problemer. For det første skal der etableres flere forbindelser på tværs af WAN, dette tilføjer latens og sænker enhver kontrol af, at proxy kører. Derudover tilføjer dette unødvendig overhead på proxyerne og databaserne. Det meste af tiden er du kun interesseret i at dirigere trafik til de lokale databasenoder. Den eneste undtagelse er masteren, og kun på grund af dette er proxyer tvunget til at se hele infrastrukturen i stedet for kun den del, der er placeret i det lokale datacenter. Selvfølgelig kan du prøve at overvinde dette ved at bruge proxyer til kun at dirigere SELECT'er, mens du bruger en anden metode (dedikeret værtsnavn for master administreret af DNS) til at pege applikationen til master, men dette tilføjer unødvendige niveauer af kompleksitet og bevægelige dele, som kan alvorligt påvirke din evne til at håndtere flere node- og netværksfejl uden at miste datakonsistensen.
Galera Cluster kan understøtte flere forfattere. Latency er også en faktor, da alle noder i Galera-klyngen skal koordinere og kommunikere for at certificere skrivesæt, det kan endda være grunden til, at du måske beslutter dig for ikke at bruge Galera, når latensen er for høj. Det er også et problem i replikeringsklynger - i replikeringsklynger påvirker latens kun skrivninger fra de fjerntliggende datacentre, mens forbindelserne fra datacentret, hvor masteren er placeret, ville drage fordel af commits med lav latens.
I MySQL-replikering skal du også tage det værst tænkelige scenarie i tankerne og sikre, at applikationen er ok med forsinkede skrivninger. Master kan altid ændre sig, og du kan ikke være sikker på, at du hele tiden vil skrive til en lokal node.
En anden forskel mellem replikering og Galera Cluster er håndteringen af replikeringsforsinkelsen. Geo-distribuerede klynger kan blive alvorligt påvirket af forsinkelse:latens, begrænset gennemstrømning af WAN-forbindelsen, alt dette vil påvirke en replikeret klynges evne til at følge med replikeringen. Husk, at replikering genererer én til al trafik.
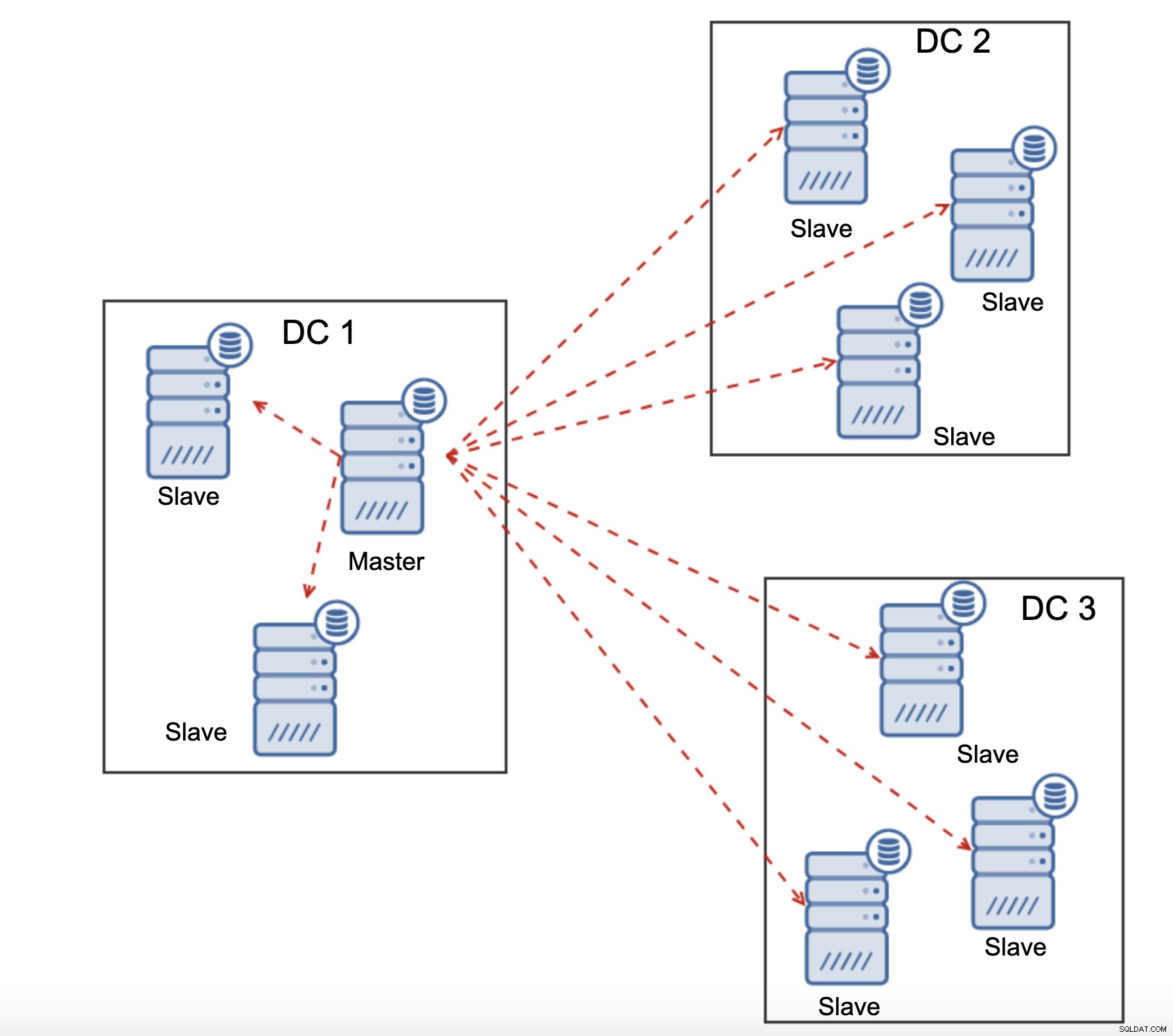
Alle slaver skal modtage hele replikeringstrafikken - mængden af data, du har at sende til fjernslaver over WAN stiger med hver fjernslave, du tilføjer. Dette kan nemt resultere i WAN-linkmætning, især hvis du laver mange ændringer, og WAN-linket ikke har god gennemstrømning. Som du kan se på diagrammet ovenfor, med tre datacentre og tre noder i hver af dem skal master sende 6 gange replikeringstrafikken over WAN-forbindelse.
Med Galera cluster er tingene lidt anderledes. Til at begynde med bruger Galera flowkontrol til at holde noderne synkroniseret. Hvis en af noderne begynder at sakke bagud, har den en evne til at bede resten af klyngen om at bremse og lade den indhente det. Selvfølgelig reducerer dette ydelsen af hele klyngen, men det er stadig bedre, end når du ikke rigtig kan bruge slaver til SELECT'er, da de har tendens til at halte fra tid til anden - i sådanne tilfælde kan de resultater, du får, være forældede og forkerte.
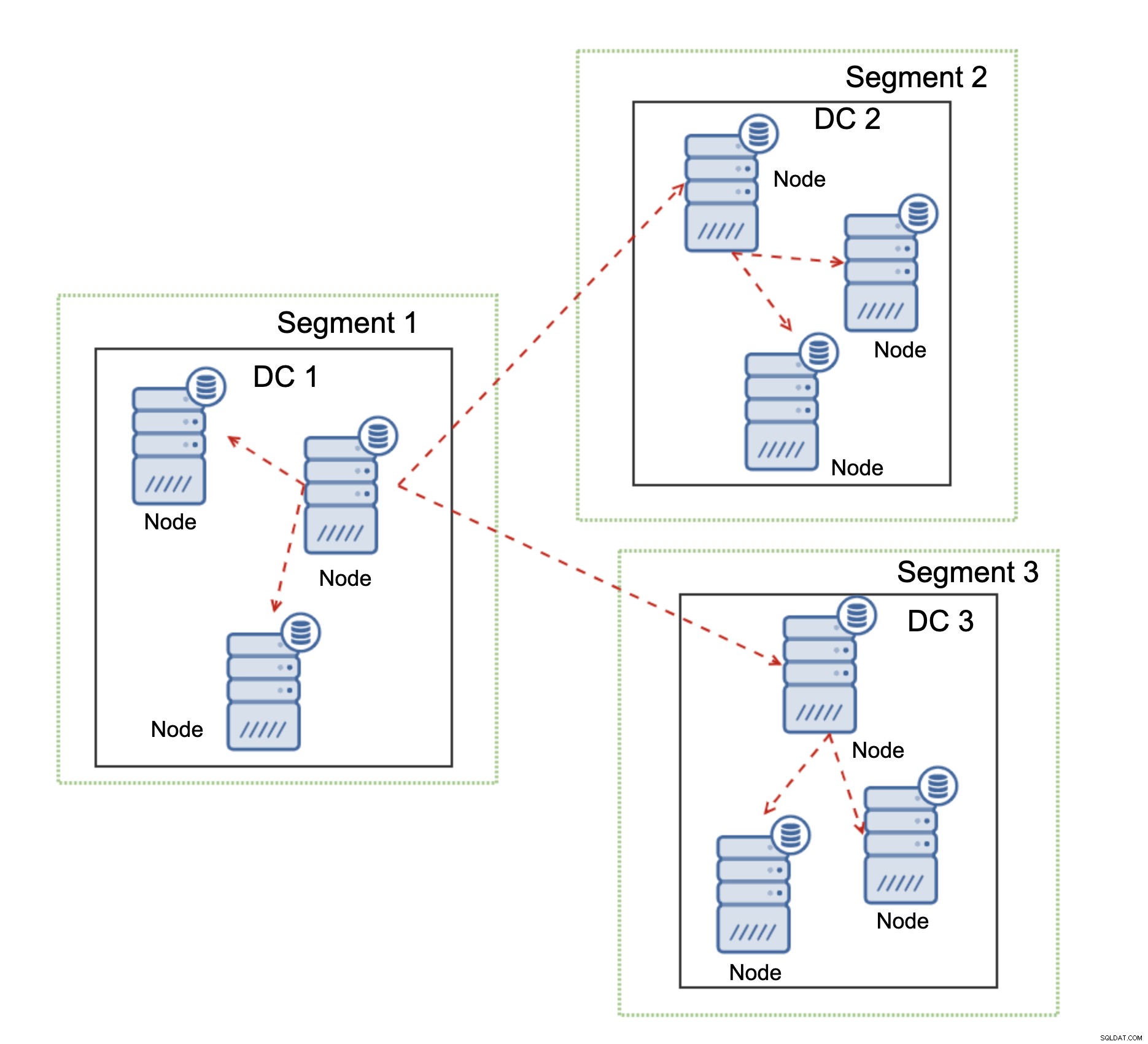
En anden funktion i Galera Cluster, som kan forbedre dens ydeevne betydeligt, når den bruges over WAN, er segmenter. Som standard bruger Galera alle til al kommunikation, og hvert skrivesæt sendes af noden til alle andre noder i klyngen. Denne adfærd kan ændres ved hjælp af segmenter. Segmenter giver brugerne mulighed for at opdele Galera-klyngen i flere dele. Hvert segment kan indeholde flere noder, og det vælger en af dem som en relæknude. En sådan node modtager skrivesæt fra andre segmenter og omdistribuerer dem på tværs af Galera-noder lokalt for segmentet. Som et resultat, som du kan se på diagrammet ovenfor, er det muligt at reducere replikeringstrafikken, der går over WAN tre gange - kun to "replikaer" af replikeringsstrømmen sendes over WAN:en pr. datacenter sammenlignet med en pr. slave i MySQL-replikering.
Håndtering af Galera Cluster Network Partitioning
Hvor Galera Cluster skinner, er håndteringen af netværkspartitioneringen. Galera Cluster overvåger konstant tilstanden af noderne i klyngen. Hver node forsøger at forbinde med sine jævnaldrende og udveksle klyngens tilstand. Hvis undersæt af noder ikke kan nås, forsøger Galera at videresende kommunikationen, så hvis der er en måde at nå disse noder på, vil de blive nået.

Et eksempel kan ses på diagrammet ovenfor:DC 1 mistede forbindelsen med DC2 men DC2 og DC3 kan forbindes. I dette tilfælde vil en af noderne i DC3 blive brugt til at videresende data fra DC1 til DC2 for at sikre, at intra-cluster-kommunikationen kan opretholdes.
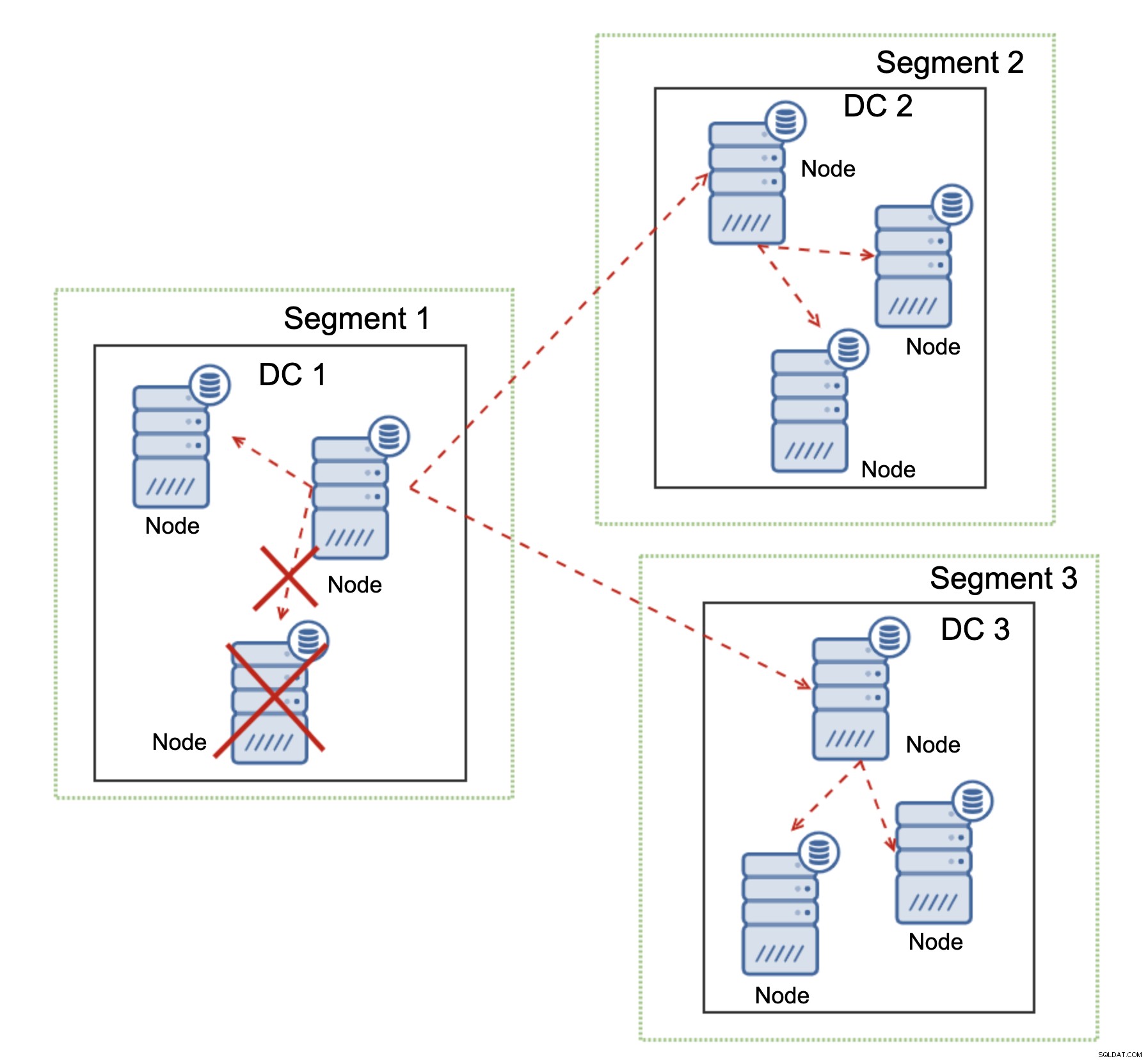
Galera Cluster er i stand til at udføre handlinger baseret på klyngens tilstand. Den implementerer quorum - størstedelen af noderne skal være tilgængelige, for at klyngen kan fungere. Hvis noden bliver afbrudt fra klyngen og ikke kan nå nogen anden node, vil den ophøre med at fungere.
Som det kan ses på diagrammet ovenfor, er der et delvist tab af netværkskommunikationen i DC1, og den berørte node fjernes fra klyngen, hvilket sikrer, at applikationen ikke får adgang til forældede data.
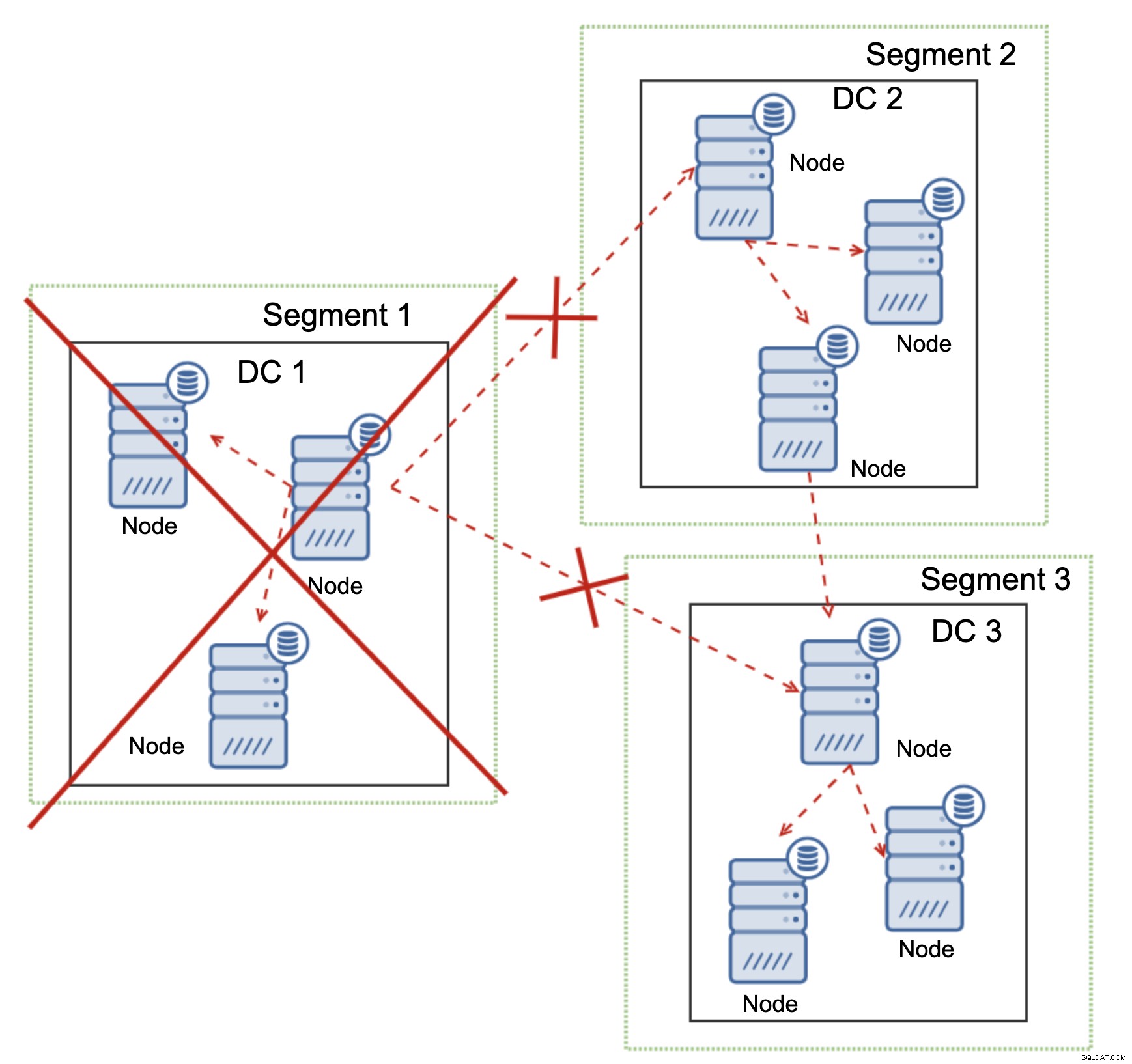
Dette gælder også i større skala. DC1 fik al sin kommunikation afbrudt. Som et resultat er hele datacenteret blevet fjernet fra klyngen, og ingen af dets noder vil betjene trafikken. Resten af klyngen bevarede flertal (6 ud af 9 noder er tilgængelige), og den omkonfigurerede sig selv for at bevare forbindelsen mellem DC 2 og DC3. I diagrammet ovenfor antog vi, at skrivningen rammer noden i DC2, men husk venligst, at Galera er i stand til at køre med flere forfattere.
MySQL-replikering har ikke nogen form for klyngebevidsthed, hvilket gør det problematisk at håndtere netværksproblemer. Den kan ikke lukke ned af sig selv, når den mister forbindelsen til andre noder. Der er ingen nem måde at forhindre den gamle mester i at dukke op efter netværksdelingen.
De eneste muligheder er begrænset til proxy-laget eller endnu højere. Du skal designe et system, som vil forsøge at forstå klyngens tilstand og tage de nødvendige handlinger. En mulig måde er at bruge klyngebevidste værktøjer som Orchestrator og derefter køre scripts, der kontrollerer status for Orchestrator RAFT-klyngen og, baseret på denne tilstand, udføre de nødvendige handlinger på databaselaget. Dette er langt fra ideelt, fordi enhver handling, der udføres på et lag, der er højere end databasen, tilføjer yderligere latenstid:det gør det muligt, så problemet dukker op, og datakonsistensen kompromitteres, før der kan foretages korrekt handling. Galera tager på den anden side handlinger på databaseniveau, hvilket sikrer den hurtigst mulige reaktion.