Langvarige forespørgsler/erklæringer/transaktioner er nogle gange uundgåelige i et MySQL-miljø. I nogle tilfælde kan en langvarig forespørgsel være en katalysator for en katastrofal begivenhed. Hvis du bekymrer dig om din database, skal optimering af forespørgselsydeevne og detektering af langvarige forespørgsler udføres regelmæssigt. Tingene bliver dog sværere, når flere forekomster i en gruppe eller klynge er involveret.
Når vi har at gøre med flere noder, er de gentagne opgaver at kontrollere hver enkelt node noget, vi skal undgå. ClusterControl overvåger flere aspekter af din databaseserver, inklusive forespørgsler. ClusterControl samler alle forespørgselsrelaterede oplysninger fra alle noder i gruppen eller klyngen for at give et centraliseret overblik over arbejdsbyrden. Lige der er en fantastisk måde at forstå din klynge som helhed på med minimal indsats.
I dette blogindlæg viser vi dig, hvordan du registrerer MySQL langvarige forespørgsler ved hjælp af ClusterControl.
Hvorfor tager en forespørgsel længere tid?
Først og fremmest skal vi kende arten af forespørgslen, om det forventes at være en lang eller kort kørende forespørgsel. Nogle analytiske og batch-operationer formodes at være langvarige forespørgsler, så vi kan springe dem over indtil videre. Afhængigt af tabelstørrelsen kan det også være en langvarig operation at ændre tabelstrukturen med ALTER-kommandoen.
For en kortvarig transaktion skal den udføres så hurtigt som muligt, normalt i løbet af et sekund. Jo kortere jo bedre. Dette kommer med et sæt best practice-regler for forespørgsler, som brugerne skal følge, som f.eks. at bruge korrekt indeksering i WHERE- eller JOIN-sætningen, bruge den rigtige lagringsmotor, vælge de rigtige datatyper, planlægge batch-driften i lavtæppet, aflæsning af analytisk /rapportering af trafik til dedikerede replikaer og så videre.
Der er en række ting, der kan få en forespørgsel til at tage længere tid at udføre:
- Ineffektiv forespørgsel - Brug ikke-indekserede kolonner, mens du slår op eller deltager, så MySQL tager længere tid at matche betingelsen.
- Tabellås – Tabellen er låst med global lås eller eksplicit tabellås, når forespørgslen forsøger at få adgang til den.
- Deadlock - En forespørgsel venter på at få adgang til de samme rækker, som er låst af en anden forespørgsel.
- Datasæt passer ikke ind i RAM - Hvis dine arbejdssætdata passer ind i den cache, vil SELECT-forespørgsler normalt være relativt hurtige.
- Suboptimale hardwareressourcer - Dette kan være langsomme diske, RAID-genopbygning, mættet netværk osv.
- Vedligeholdelsesoperation - At køre mysqldump kan bringe enorme mængder af ellers ubrugte data ind i bufferpuljen, og samtidig vil de (potentielt nyttige) data, der allerede er der, blive smidt ud og skyllet til disken.
Ovenstående liste understreger, at det ikke kun er selve forespørgslen, der forårsager alle mulige problemer. Der er masser af grunde, som kræver at se på forskellige aspekter af en MySQL-server. I nogle værre tilfælde kan en lang kørende forespørgsel forårsage en total serviceafbrydelse som servernedbrud, servernedbrud og forbindelser, der max. Hvis du ser, at en forespørgsel tager længere tid end normalt at udføre, så undersøg den.
Hvordan tjekker man det?
PROCESLISTE
MySQL giver en række indbyggede værktøjer til at kontrollere den langvarige transaktion. Først og fremmest kan kommandoerne VIS PROCESSLISTE eller VIS FULD PROCESSLISTE afsløre de kørende forespørgsler i realtid. Her er et skærmbillede af ClusterControl Running Queries-funktionen, der ligner SHOW FULL PROCESSLIST-kommandoen (men ClusterControl samler hele processen i én visning for alle noder i klyngen):
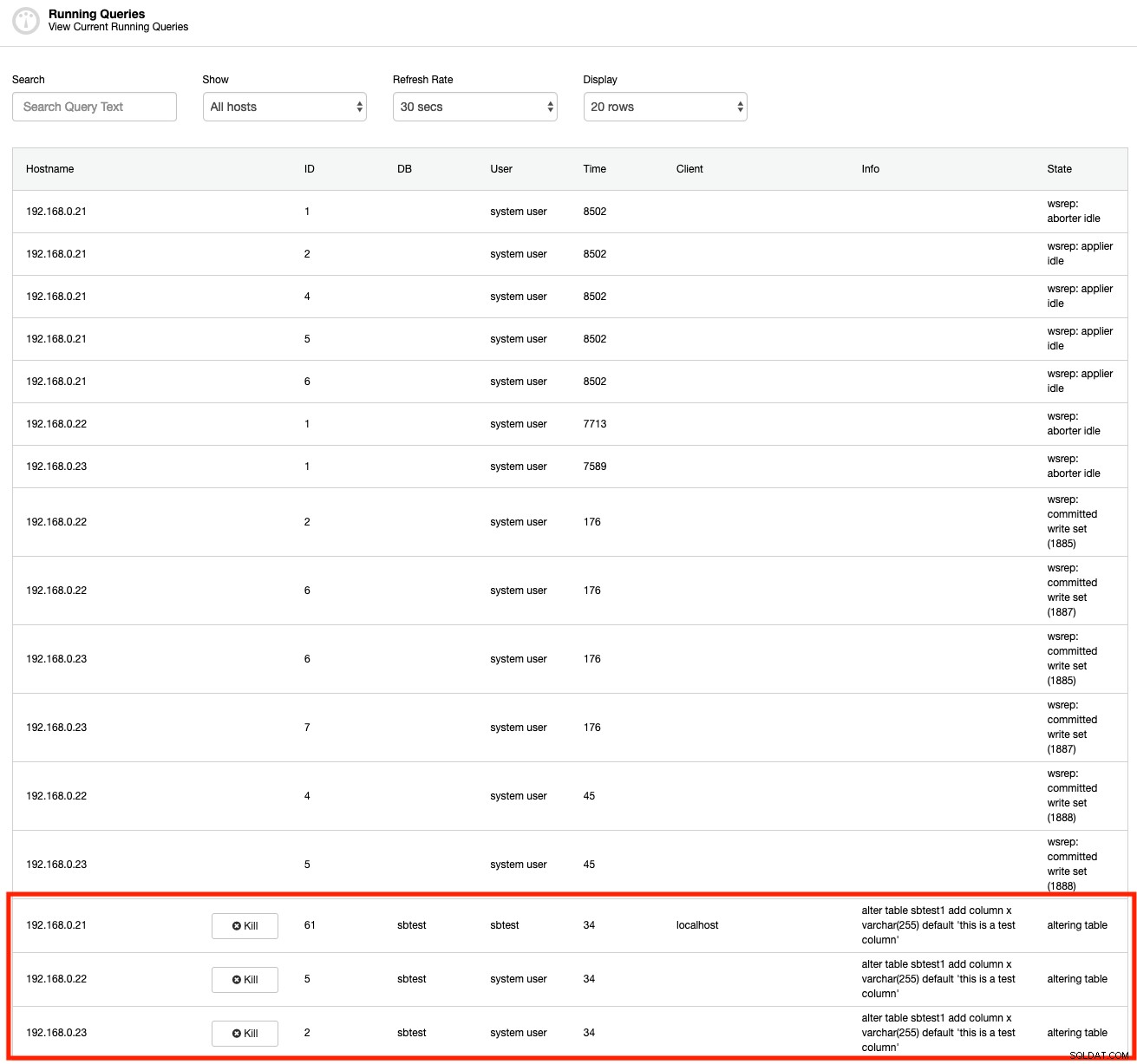
Som du kan se, kan vi straks se den stødende forespørgsel med det samme fra outputtet. Men hvor ofte stirrer vi på de processer? Dette er kun nyttigt, hvis du er opmærksom på den langvarige transaktion. Ellers ville du ikke vide det, før der sker noget - som at forbindelser hober sig op, eller serveren bliver langsommere end normalt.
Langsom forespørgselslog
Langsom forespørgselslog opfanger langsomme forespørgsler (SQL-sætninger, der tager mere end long_query_time sekunder at udføre), eller forespørgsler, der ikke bruger indekser til opslag (log_queries_not_using_indexes ). Denne funktion er ikke aktiveret som standard, og for at aktivere den skal du blot indstille følgende linjer og genstarte MySQL-serveren:
[mysqld]
slow_query_log=1
long_query_time=0.1
log_queries_not_using_indexes=1Den langsomme forespørgselslog kan bruges til at finde forespørgsler, der tager lang tid at udføre og derfor er kandidater til optimering. Det kan dog være en tidskrævende opgave at undersøge en lang langsom forespørgselslog. Der er værktøjer til at parse MySQL langsomme forespørgselslogfiler og opsummere deres indhold som mysqldumpslow, pt-query-digest eller ClusterControl Top Queries.
ClusterControl Top Queries opsummerer den langsomme forespørgsel ved hjælp af to metoder - MySQL langsom forespørgselslog eller Performance Schema:
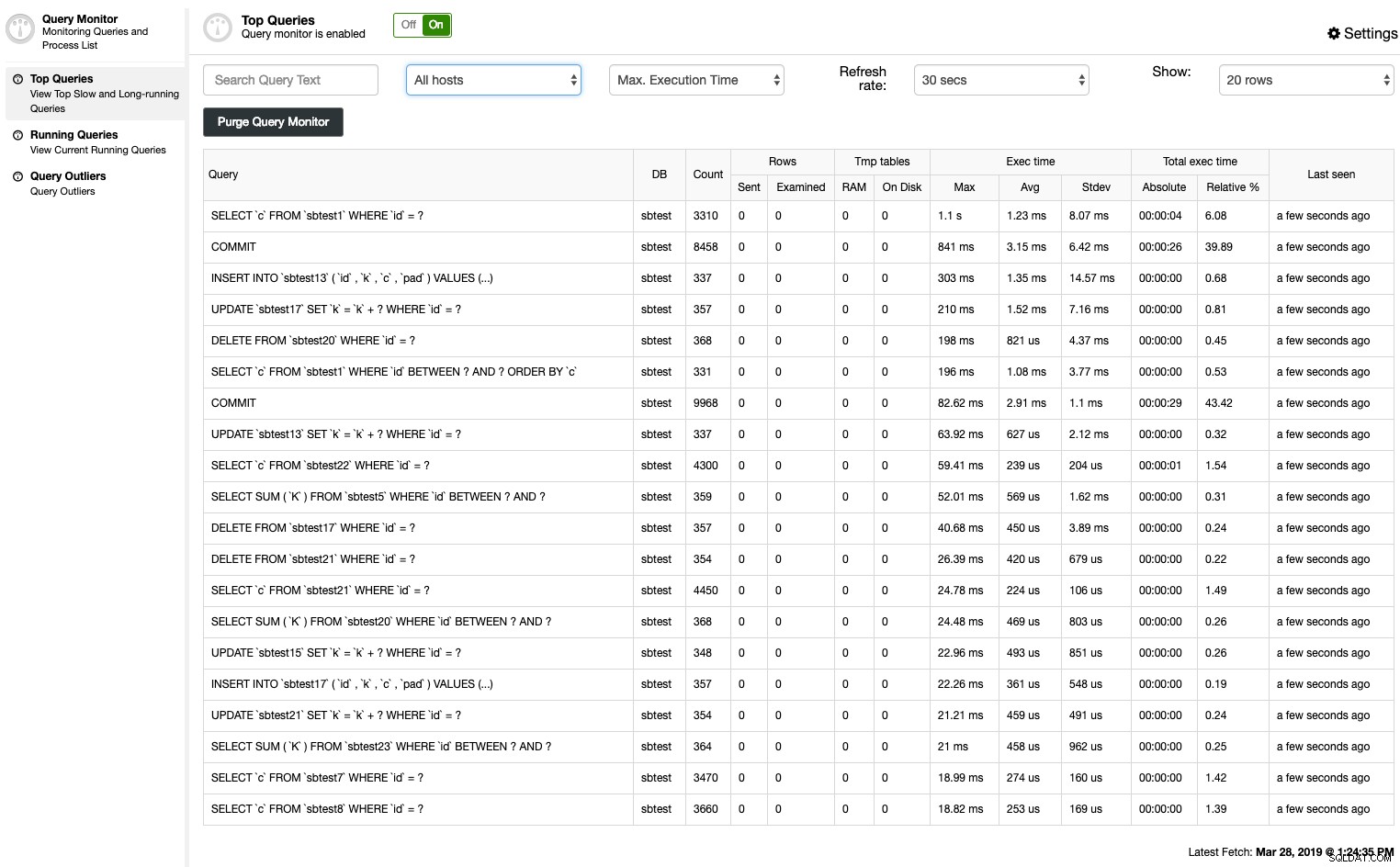
Du kan nemt se en oversigt over de normaliserede udsagnssammendrag, sorteret ud fra en række kriterier:
- Vært
- Forekomster
- Samlet udførelsestid
- Maksimal udførelsestid
- Gennemsnitlig udførelsestid
- Standardafvigelsestid
Vi har dækket denne funktion meget detaljeret i dette blogindlæg, Sådan bruges ClusterControl Query Monitor til MySQL, MariaDB og Percona Server.
Performanceskema
Performance Schema er et fantastisk værktøj, der er tilgængeligt til overvågning af MySQL Server-internal og udførelsesdetaljer på et lavere niveau. Følgende tabeller i Performance Schema kan bruges til at finde langsomme forespørgsler:
- events_statements_current
- events_statements_history
- events_statements_history_long
- events_statements_summary_by_digest
- events_statements_summary_by_user_by_event_name
- events_statements_summary_by_host_by_event_name
MySQL 5.7.7 og nyere inkluderer sys-skemaet, et sæt objekter, der hjælper DBA'er og udviklere med at fortolke data indsamlet af Performance Schema til en lettere forståelig form. Sys-skemaobjekter kan bruges til typiske tuning- og diagnosetilfælde.
ClusterControl leverer rådgivere, som er miniprogrammer, som du kan skrive ved hjælp af ClusterControl DSL (svarende til JavaScript) for at udvide ClusterControl-overvågningskapaciteterne tilpasset dine behov. Der er en række scripts inkluderet baseret på Performance Schema, som du kan bruge til at overvåge forespørgselsydeevne som I/O-vent, låseventetid og så videre. For eksempel under Administrer -> Udviklerstudie , gå til s9s -> mysql -> p_s -> top_tables_by_iowait.js og klik på knappen "Kompilér og kør". Du bør se output under fanen Beskeder for top 10 tabeller sorteret efter I/O-vent pr. server:
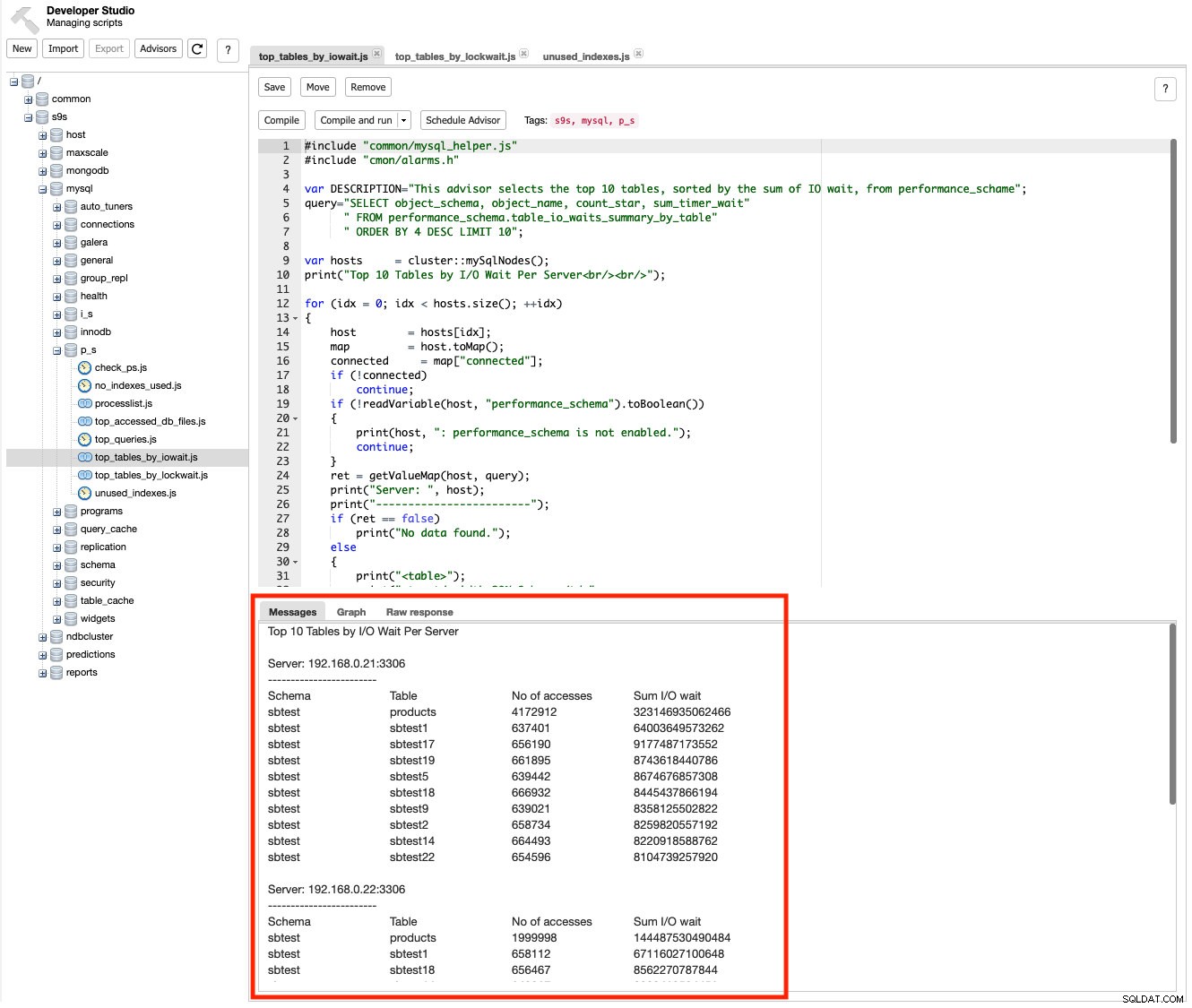
Der er en række scripts, som du kan bruge til at forstå information på lavt niveau, hvor og hvorfor langsommeligheden sker, såsom top_tables_by_lockwait.js , top_accessed_db_files.js og så videre.
ClusterControl - Registrering og advarsel ved langvarige forespørgsler
Med ClusterControl får du yderligere kraftfulde funktioner, som du ikke finder i standard MySQL-installationen. ClusterControl kan konfigureres til proaktivt at overvåge de kørende processer og udløse en alarm og sende meddelelse til brugeren, hvis den lange forespørgselstærskel overskrides. Dette kan konfigureres ved at bruge Runtime Configuration under Indstillinger:
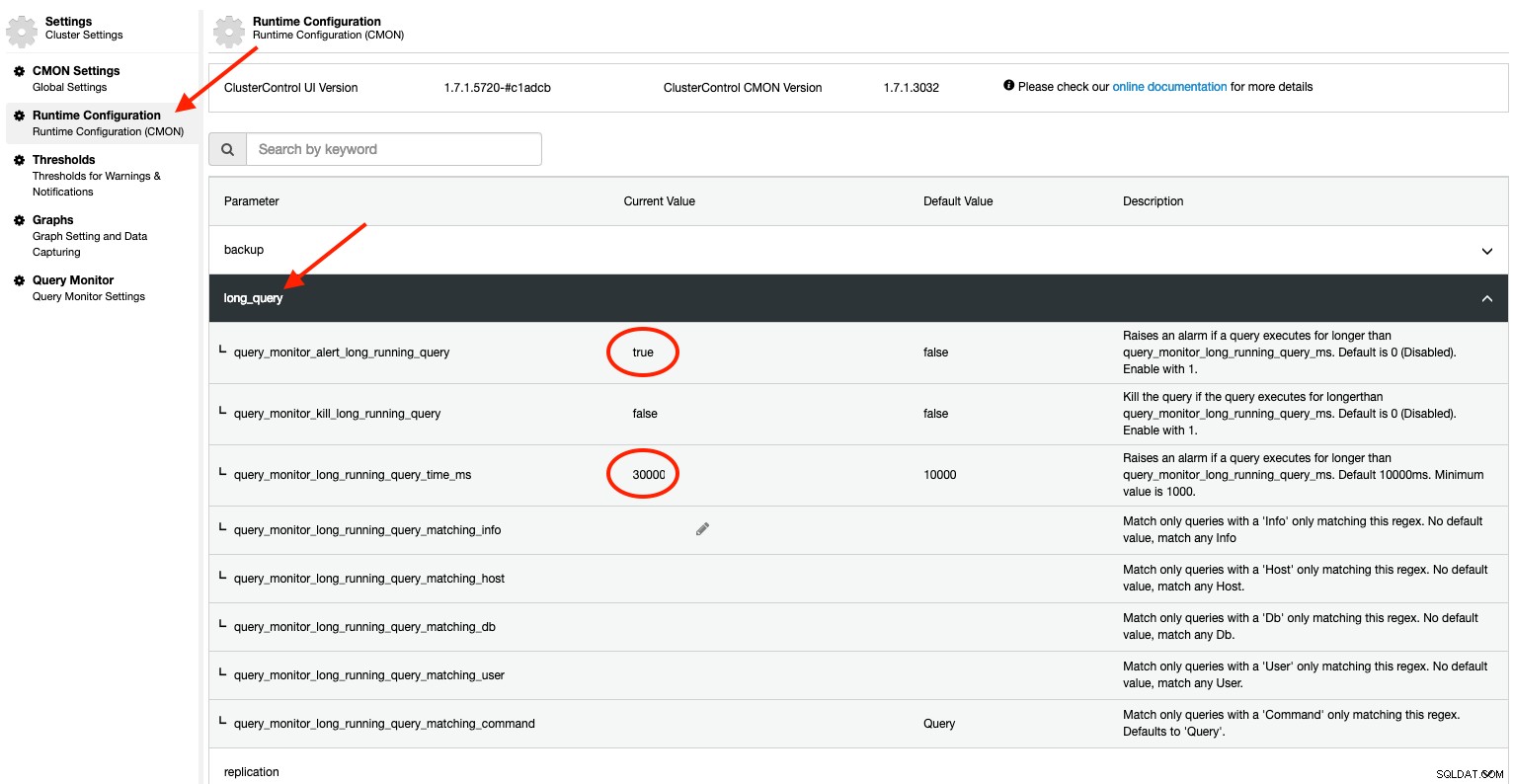
For før 1.7.1 er standardværdien for query_monitor_alert_long_running_query er falsk. Vi opfordrer brugeren til at aktivere dette ved at sætte det til 1 (sandt). For at gøre det vedvarende skal du tilføje følgende linje i /etc/cmon.d/cmon_X.cnf:
query_monitor_alert_long_running_query=1
query_monitor_long_running_query_ms=30000Eventuelle ændringer foretaget i Runtime Configuration anvendes med det samme, og der kræves ingen genstart. Du vil se noget som dette under Alarmsektionen, hvis en forespørgsel overstiger tærsklerne på 30000ms (30 sekunder):
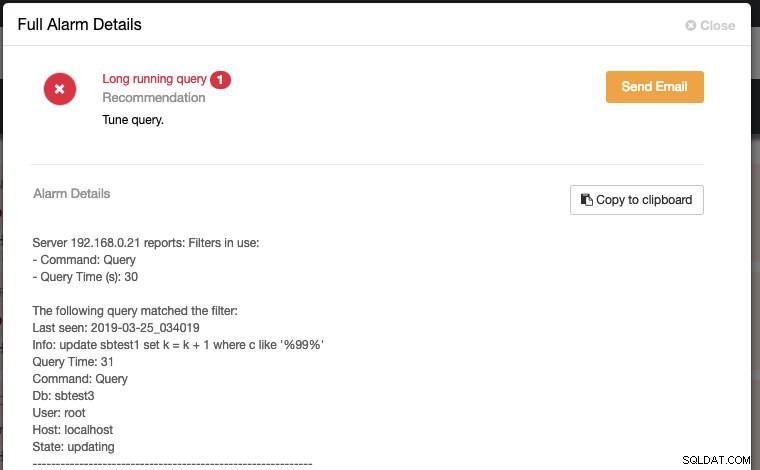
Hvis du konfigurerer e-mail-modtagerindstillingerne som "Lever" for DbComponent plus CRITICAL severity-kategorien (som vist på følgende skærmbillede):
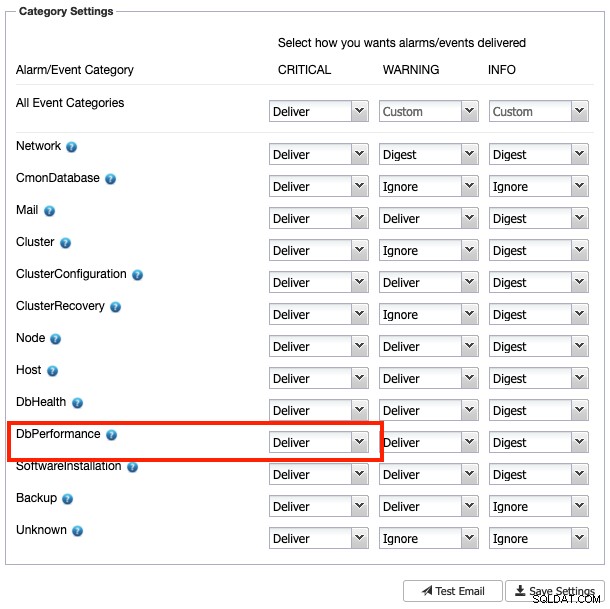
Du bør få en kopi af denne alarm i din e-mail. Ellers kan den videresendes manuelt ved at klikke på knappen "Send e-mail".
Desuden kan du bortfiltrere enhver form for proceslisteressourcer, der matcher bestemte kriterier med regulært udtryk (regex). Hvis du f.eks. ønsker, at ClusterControl skal registrere en langvarig forespørgsel for tre MySQL-brugere kaldet 'sbtest', 'myshop' og 'db_user1', skal følgende gøres:
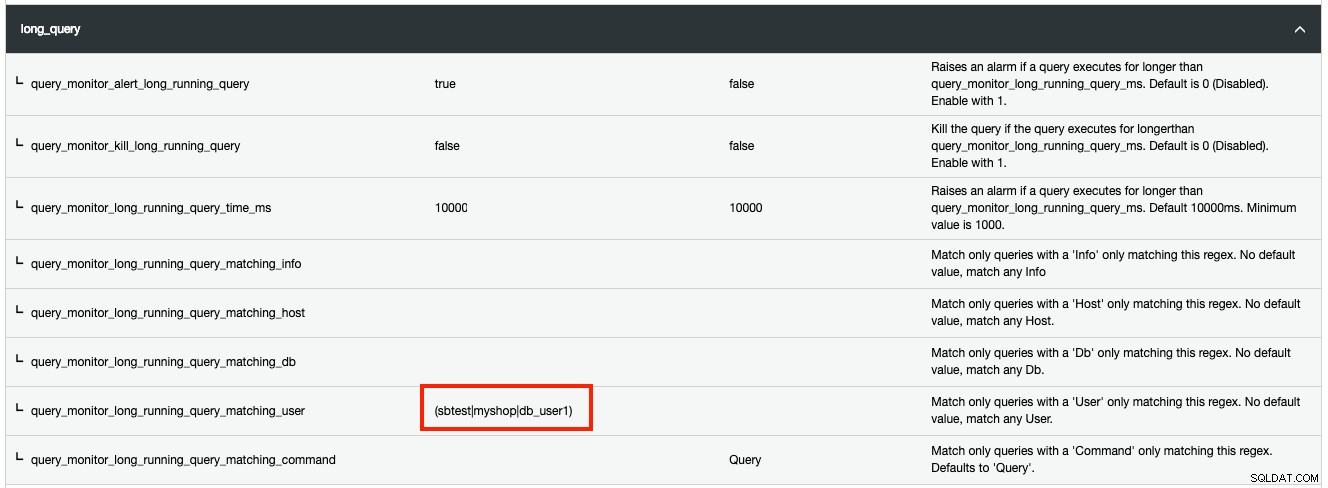
Eventuelle ændringer foretaget i Runtime Configuration anvendes med det samme, og der kræves ingen genstart.
Derudover vil ClusterControl liste alle deadlock-transaktioner sammen med InnoDB-statussen, da det foregik under Performance -> Transaction Log :
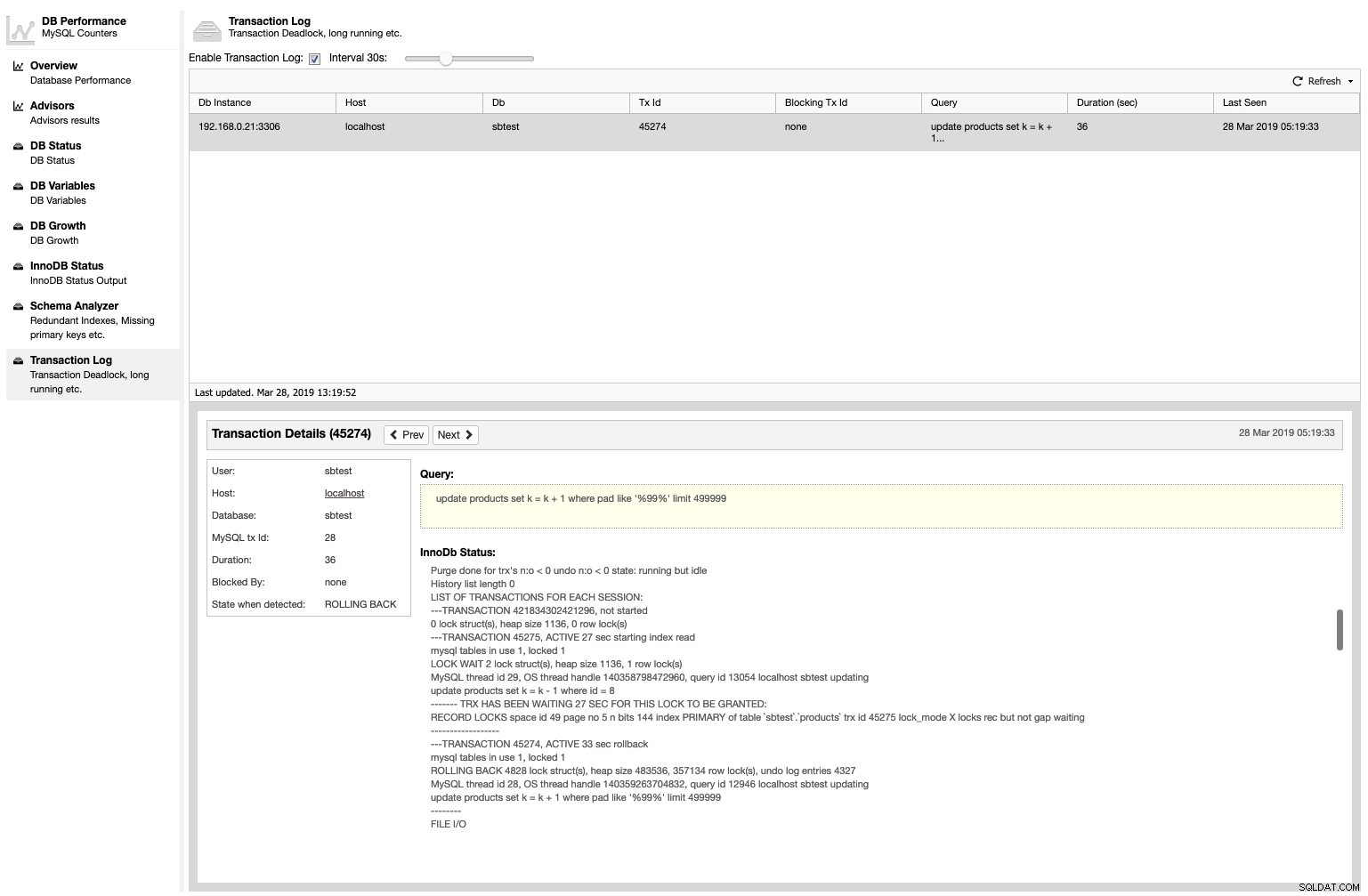
Denne funktion er ikke aktiveret som standard, da deadlock-detektion vil påvirke CPU-brug på databasenoder. For at aktivere det, skal du blot markere afkrydsningsfeltet "Aktiver transaktionslog" og angive det interval, du ønsker. For at gøre det vedvarende skal du tilføje variabel med værdi i sekunder inde i /etc/cmon.d/cmon_X.cnf:
db_deadlock_check_interval=30På samme måde, hvis du vil tjekke InnoDB-statussen, skal du blot gå til Ydeevne -> InnoDB-status , og vælg MySQL-serveren fra rullemenuen. For eksempel:
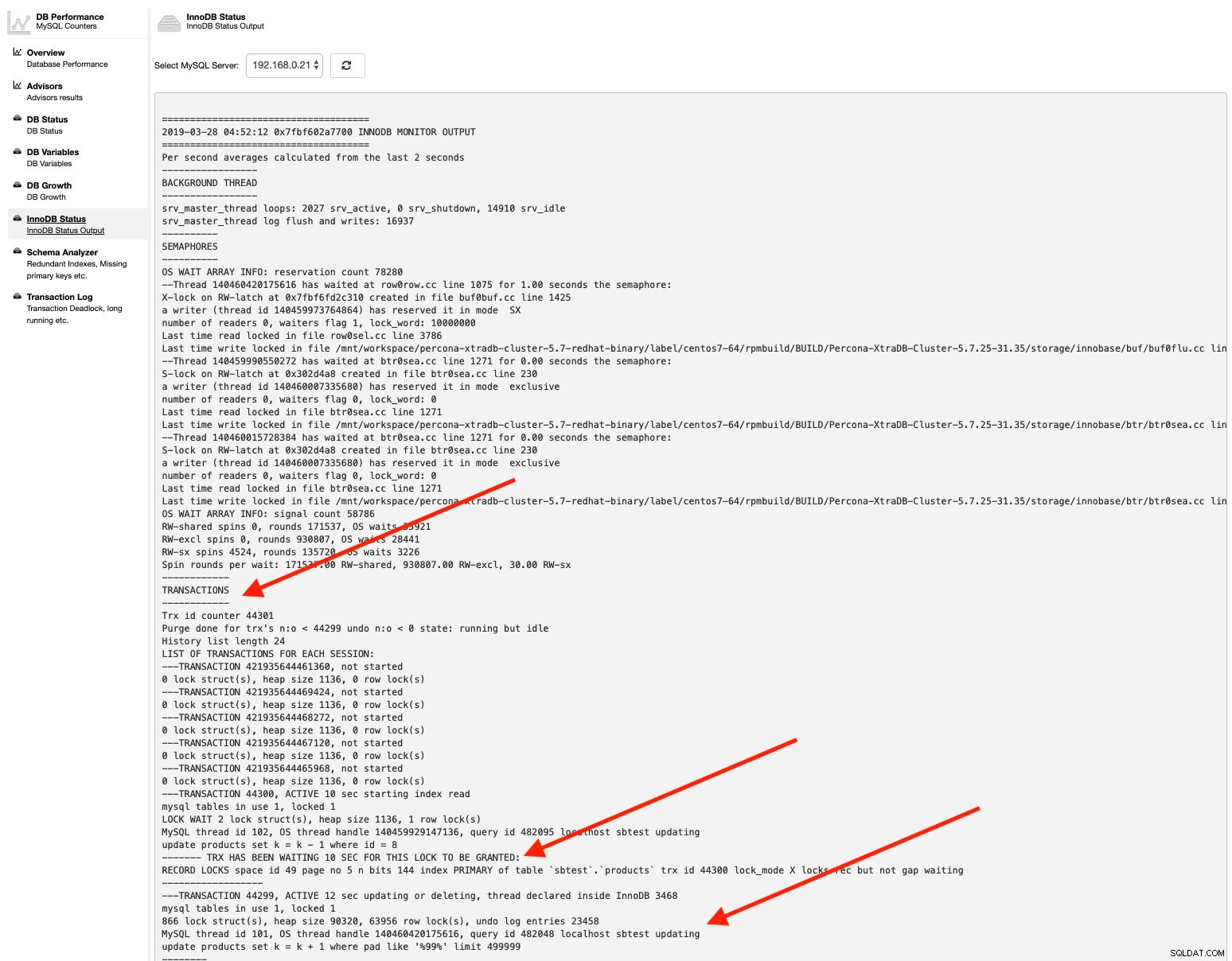
Så er vi i gang - alle de nødvendige oplysninger kan nemt hentes med et par klik.
Oversigt
Langvarige transaktioner kan føre til ydeevneforringelse, servernedbrud, maks. forbindelser og dødvande. Med ClusterControl kan du registrere langvarige forespørgsler direkte fra brugergrænsefladen uden at skulle undersøge hver eneste MySQL-node i klyngen.