Kørsel af en Galera-klynge i en hybridsky bør bestå af mindst to forskellige geografiske websteder, der forbinder værter i den lokale eller private sky med dem i den offentlige sky. Uanset om du bruger ubrydelige private cloud- eller offentlige cloudplatforme, er Disaster Recovery (DR) virkelig et nøgleproblem. Dette handler ikke om at kopiere dine data til et backup-websted og være i stand til at gendanne dem, det handler om forretningskontinuitet og hvor hurtigt du kan gendanne tjenester, når katastrofen rammer.
I dette blogindlæg vil vi se nærmere på forskellige måder at designe dine Galera-klynger på til fejltolerance i et hybridt cloudmiljø.
Active-Active Setup
Galera Cluster bør køre med et ulige antal noder i en klynge og starter normalt med 3 noder. Dette skyldes, at Galera Cluster bruger kvorum til automatisk at bestemme den primære komponent, hvor et flertal af forbundne noder skulle være i stand til at betjene klyngen ad gangen, i tilfælde af at klyngepartitionering skete.
For en aktiv-aktiv opsætning af hybrid cloud-opsætning kræver Galera mindst 3 forskellige websteder, der danner en Galera-klynge på tværs af WAN. Generelt har du brug for et tredje websted til at fungere som voldgiftsdommer, stemme for beslutningsdygtighed og bevare den "primære komponent", hvis nogen af webstederne er utilgængelige. Dette kan sættes op som minimum en 3-node klynge på 3 forskellige steder (1 node pr. site), svarende til følgende diagram:
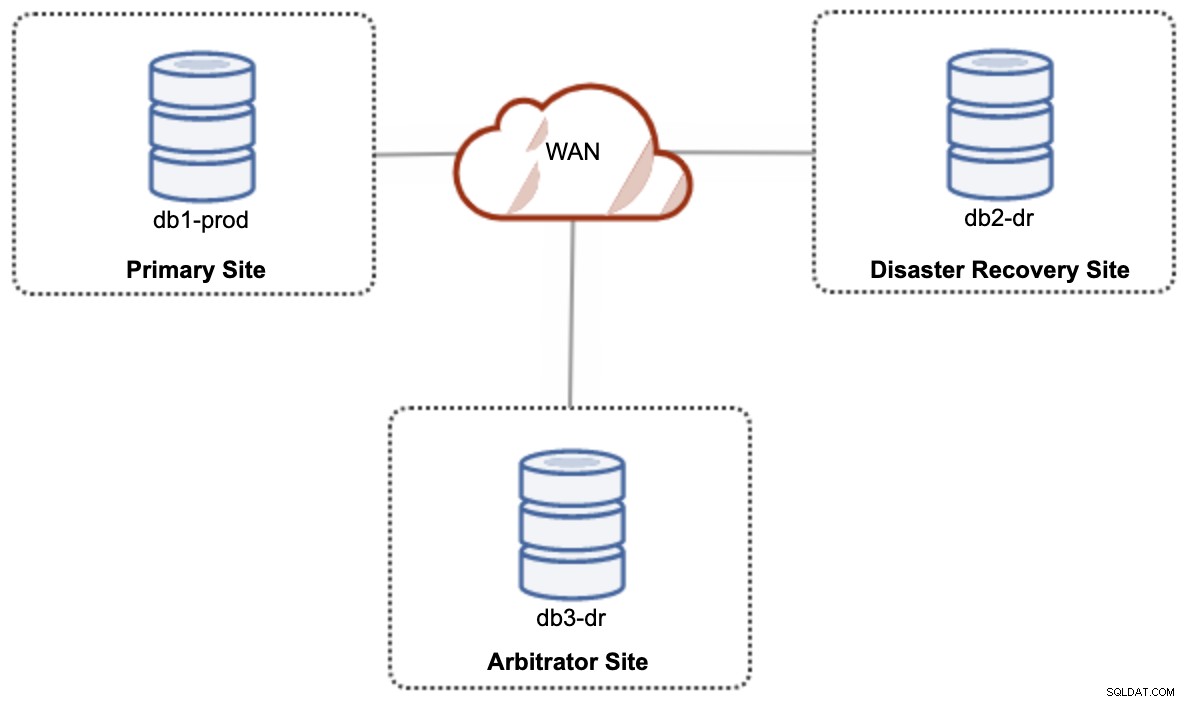
Men af hensyn til ydeevne og pålidelighed anbefales det at have en 7 -node-klynge, som vist i følgende diagram:
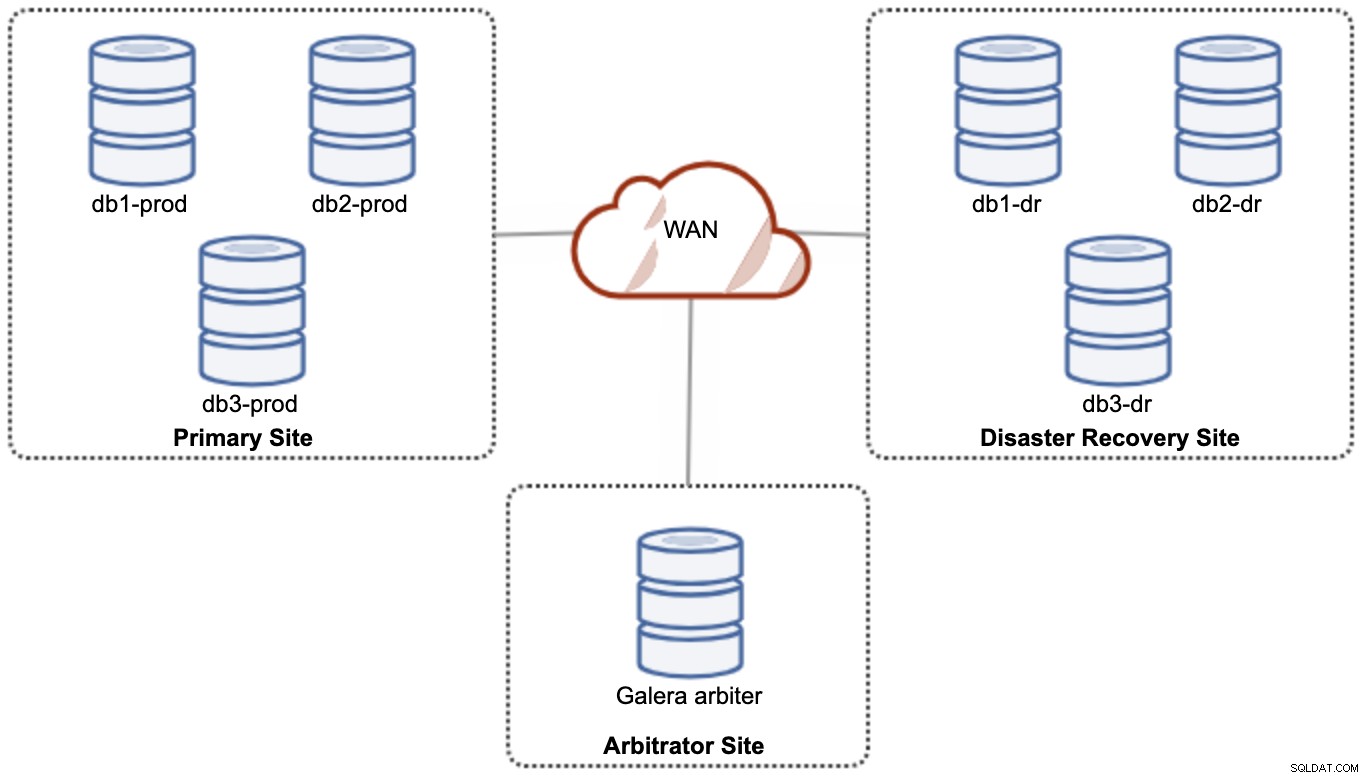
Dette anses for at være den bedste topologi til at understøtte en aktiv-aktiv opsætning, hvor DR-siden bør være tilgængelig næsten øjeblikkeligt uden nogen form for indgriben. Begge websteder kan modtage læsninger/skrivninger til enhver tid, forudsat at klyngen er i kvorum.
Det er dog meget dyrt at have 3 websteder og 7 databasenoder (den 7. knude kan erstattes med en garbd, da det er meget usandsynligt, at det bliver brugt til at levere data til klienterne/applikationerne). Dette er normalt ikke en populær udrulning i begyndelsen af projektet på grund af de enorme forudgående omkostninger og hvor følsom Galera-gruppens kommunikation og replikering over for netværksforsinkelse.
Aktiv-passiv opsætning
I en aktiv-passiv konfiguration kræves der mindst 2 websteder, og kun ét websted er aktivt ad gangen, kendt som det primære websted, og noderne på det sekundære websted replikerer kun data, der kommer fra det primære websted server/cluster. Til Galera Cluster kan vi bruge enten MySQL asynkron replikering (master-slave replikering), eller vi kan også bruge Galeras virtuelt synkrone replikering med en vis justering for at nedtone dens skrivesætreplikering til at fungere som asynkron replikering.
Det sekundære websted skal beskyttes mod utilsigtet skrivning ved at bruge skrivebeskyttet flag, applikations-firewall, omvendt proxy eller enhver anden måde, da datastrømmen altid kommer fra det primære til det sekundære websted, medmindre en failover har startet og promoveret det sekundære websted som det primære.
Brug af asynkron replikering
En god ting ved asynkron replikering er, at replikeringen ikke påvirker kildeserveren/klyngen, men det er tilladt at halte bagefter masteren. Denne opsætning vil gøre det primære og DR-sted uafhængige af hinanden, løst forbundet med asynkron replikering. Dette kan sættes op som minimum en 4-node klynge på 2 forskellige steder, svarende til følgende diagram:
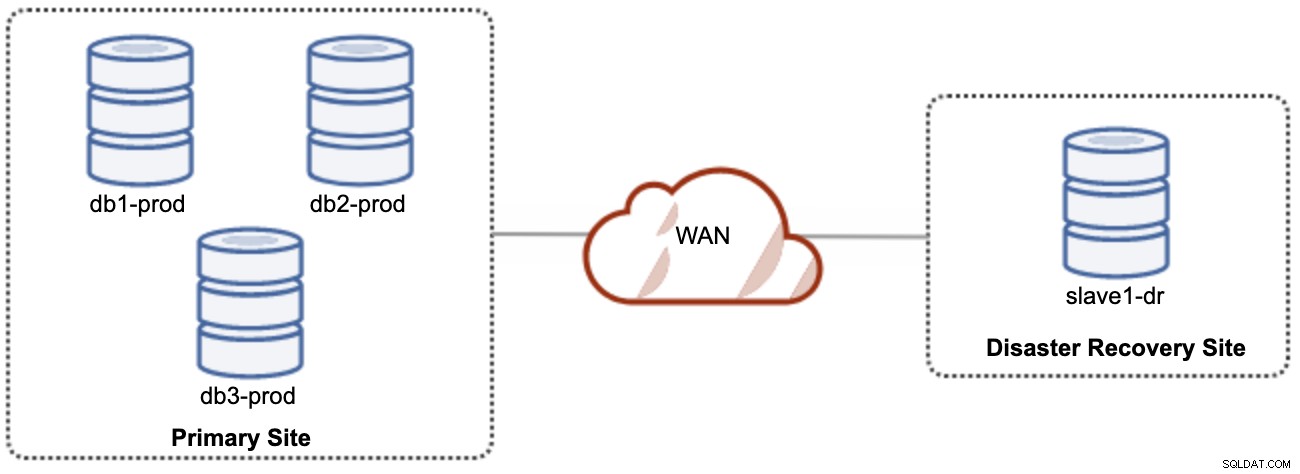
En af Galera-noderne på DR-webstedet vil være en slave, der replikeres fra en af Galera-knuderne (master) på det primære websted. Begge steder skal producere binære logfiler med GTID, og log_slave_updates er aktiveret - opdateringerne, der kommer fra den asynkrone replikeringsstrøm, vil blive anvendt på de andre noder i klyngen. Til produktionsbrug anbefaler vi dog at have to sæt klynger på begge steder, som vist i følgende diagram:
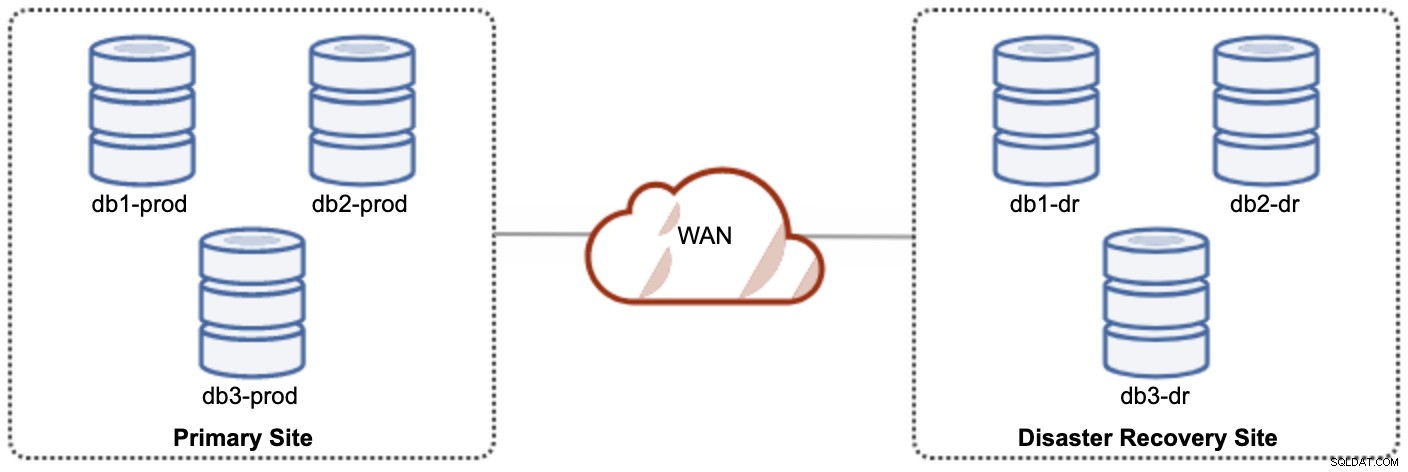
Ved at have to separate klynger vil de være løst koblet og ikke påvirke hinanden, f.eks. en klyngefejl på det primære websted vil ikke påvirke DR-stedet. Ydeevnemæssigt vil WAN-forsinkelse ikke påvirke opdateringer på den aktive klynge. Disse sendes asynkront til backupstedet. DR-klyngen kunne potentielt køre på mindre instanser i et offentligt cloudmiljø, så længe de kan følge med den primære klynge. Forekomsterne kan opgraderes, hvis det er nødvendigt. Programmer skal sende skrivninger til det primære websted, og det sekundære websted skal indstilles til at køre i skrivebeskyttet tilstand. Disaster recovery site kan bruges til andre formål som database backup, binær log backup og rapportering eller behandling af analytiske forespørgsler (OLAP).
På den negative side er der en chance for datatab under failover/fallback, hvis slaven haltede. Derfor anbefales det at aktivere semi-synkron replikering for at mindske risikoen for tab af data. Bemærk, at brug af semi-synkron replikering stadig ikke giver stærke garantier mod tab af data, sammenlignet med Galeras praktisk talt-synkrone replikering. Læs denne MySQL-manual omhyggeligt, for eksempel disse sætninger:
"Med semisynkron replikering, hvis kilden går ned, og en failover til en replika udføres, bør den mislykkede kilde ikke genbruges som replikeringskilden og skal kasseres. Den kan have transaktioner, der var ikke anerkendt af nogen replika, som derfor ikke blev begået før failoveren."
Failover-processen er ret ligetil. For at promovere katastrofegendannelsesstedet skal du blot slå skrivebeskyttet flag fra og begynde at dirigere applikationen til databasenoderne på DR-webstedet. Fallback-strategien er dog en smule vanskelig, og den kræver en vis ekspertise i at iscenesætte dataene på begge steder, skifte master/slave-rollen for en klynge og omdirigere slavereplikeringsflowet til den modsatte vej.
Brug af Galera Replication
For aktiv-passiv opsætning kan vi placere størstedelen af noderne placeret på det primære sted, mens mindretallet af noderne er placeret på katastrofegendannelsesstedet, som vist i følgende skærmbillede for en 3- node Galera Cluster:
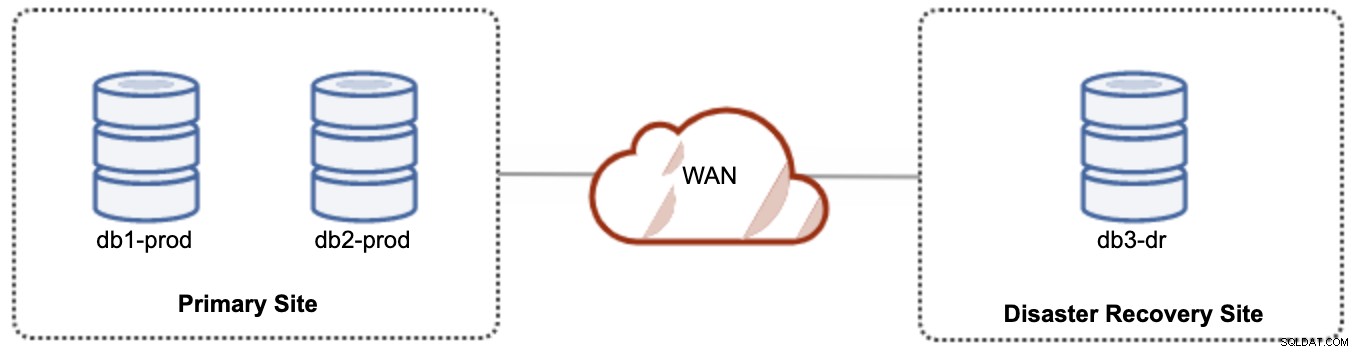
Hvis det primære websted er nede, vil klyngen fejle, da det er uden for kvorum. Galera-knuden på katastrofegendannelsesstedet (db3-dr) skal bootstrappes manuelt som en enkelt node primær komponent. Når det primære websted kommer op igen, skal begge noder på det primære websted (db1-prod og db2-prod) slutte sig til galera3 igen for at blive synkroniseret. At have en ret stor gcache burde hjælpe med at reducere risikoen for SST over WAN. Denne arkitektur er nem at sætte op og administrere og meget omkostningseffektiv.
Failover er manuel, da administratoren skal promovere den enkelte node som den primære komponent (bootstrap db3-dr eller brug sæt pc.bootstrap=1 i parameteren wsrep_provider_options. Der ville være nedetid i mellemtiden Ydeevne kan være et problem, da DR-webstedet kører med et mindre antal noder (da DR-webstedet altid er minoriteten) for at køre hele belastningen. Det kan være muligt at skalere ud med flere noder efter skift til DR site, men pas på den ekstra belastning.
Bemærk, at Galera Cluster er følsomt over for netværket på grund af dets praktisk talt synkrone karakter. Jo længere Galera-knudepunkterne er i en given klynge, desto højere latenstid og dens skriveevne til at distribuere og certificere skrivesættene. Hvis forbindelsen ikke er stabil, kan der nemt ske klyngepartitionering, hvilket kan udløse klyngesynkronisering på joiner-knudepunkterne. I nogle tilfælde kan dette introducere ustabilitet til klyngen. Dette kræver en smule tuning på Galera-parametre, som vist i dette blogindlæg, Deploying a Hybrid Infrastructure Environment for Percona XtraDB Cluster.
Sidste tanker
Galera Cluster er en fantastisk teknologi, der kan implementeres på forskellige måder - én klynge strækket sig over flere steder, flere klynger holdt synkroniseret via asynkron replikering, en blanding af synkron og asynkron replikering, og så videre. Den faktiske løsning vil blive dikteret af faktorer som WAN-latens, eventuel versus stærk datakonsistens og budget.