Høj tilgængelighed er en høj procentdel af tiden, som systemet fungerer og reagerer i overensstemmelse med virksomhedens behov. For produktionsdatabasesystemer er det typisk den højeste prioritet at holde den tæt på 100 %. Vi bygger databaseklynger for at eliminere alle enkeltstående fejl. Hvis en instans bliver utilgængelig, bør en anden node være i stand til at tage arbejdsbyrden og fortsætte derfra. I en perfekt verden ville en databaseklynge løse alle vores systemtilgængelighedsproblemer. Selvom alt kan se godt ud på papiret, er virkeligheden desværre ofte anderledes. Så hvor kan det gå galt?
Transaktionelle databasesystemer kommer med sofistikerede lagringsmotorer. At holde data konsistente på tværs af flere noder gør denne opgave meget sværere. Clustering introducerer en række nye variabler, der i høj grad afhænger af netværk og underliggende infrastruktur. Det er ikke ualmindeligt, at en selvstændig databaseinstans, der kørte fint på en enkelt node, pludselig yder dårligt i et klyngemiljø.
Blandt antallet af ting, der kan påvirke klyngens tilgængelighed, spiller latensproblemer en afgørende rolle. Men hvad er latensen? Er det kun relateret til netværket?
Udtrykket "latens" refererer faktisk til flere slags forsinkelser, der opstår i behandlingen af data. Det er, hvor lang tid det tager for et stykke information at flytte fra scene til en anden.
I dette blogindlæg vil vi se på de to vigtigste løsninger med høj tilgængelighed til MySQL og MariaDB, og hvordan de hver især kan blive påvirket af forsinkelsesproblemer.
I slutningen af artiklen tager vi et kig på moderne belastningsbalancere og diskuterer, hvordan de kan hjælpe dig med at løse nogle typer latensproblemer.
I en tidligere artikel skrev min kollega Krzysztof Książek om "Dealing with Unreliable Networks When Crafting an HA Solution for MySQL or MariaDB". Du vil finde tips, der kan hjælpe dig med at designe din produktionsklare HA-arkitektur og undgå nogle af de problemer, der er beskrevet her.
Master-Slave-replikering for høj tilgængelighed.
MySQL master-slave-replikering er sandsynligvis den mest populære databaseklyngetype på planeten. En af de vigtigste ting, du vil overvåge, mens du kører din master-slave-replikeringsklynge, er slaveforsinkelsen. Afhængigt af dine applikationskrav og den måde, du bruger din database på, kan replikeringsforsinkelsen (slavelag) bestemme, om dataene kan læses fra slaveknuden eller ej. Data begået på master, men endnu ikke tilgængelige på en asynkron slave betyder, at slaven har en ældre tilstand. Når det ikke er ok at læse fra en slave, skal du gå til masteren, og det kan påvirke applikationens ydeevne. I værste fald vil dit system ikke være i stand til at håndtere hele arbejdsbyrden på en master.
Slaveforsinkelse og forældede data
For at kontrollere status for master-slave-replikeringen skal du starte med nedenstående kommando:
SHOW SLAVE STATUS\G
MariaDB [(none)]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.3.100
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000021
Read_Master_Log_Pos: 5101
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 809
Relay_Master_Log_File: binlog.000021
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 5101
Relay_Log_Space: 1101
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3-1179
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
1 row in set (0.01 sec)Ved at bruge ovenstående information kan du bestemme, hvor god den samlede replikeringsforsinkelse er. Jo lavere værdi du ser i "Seconds_Behind_Master", jo bedre er dataoverførselshastigheden til replikering.
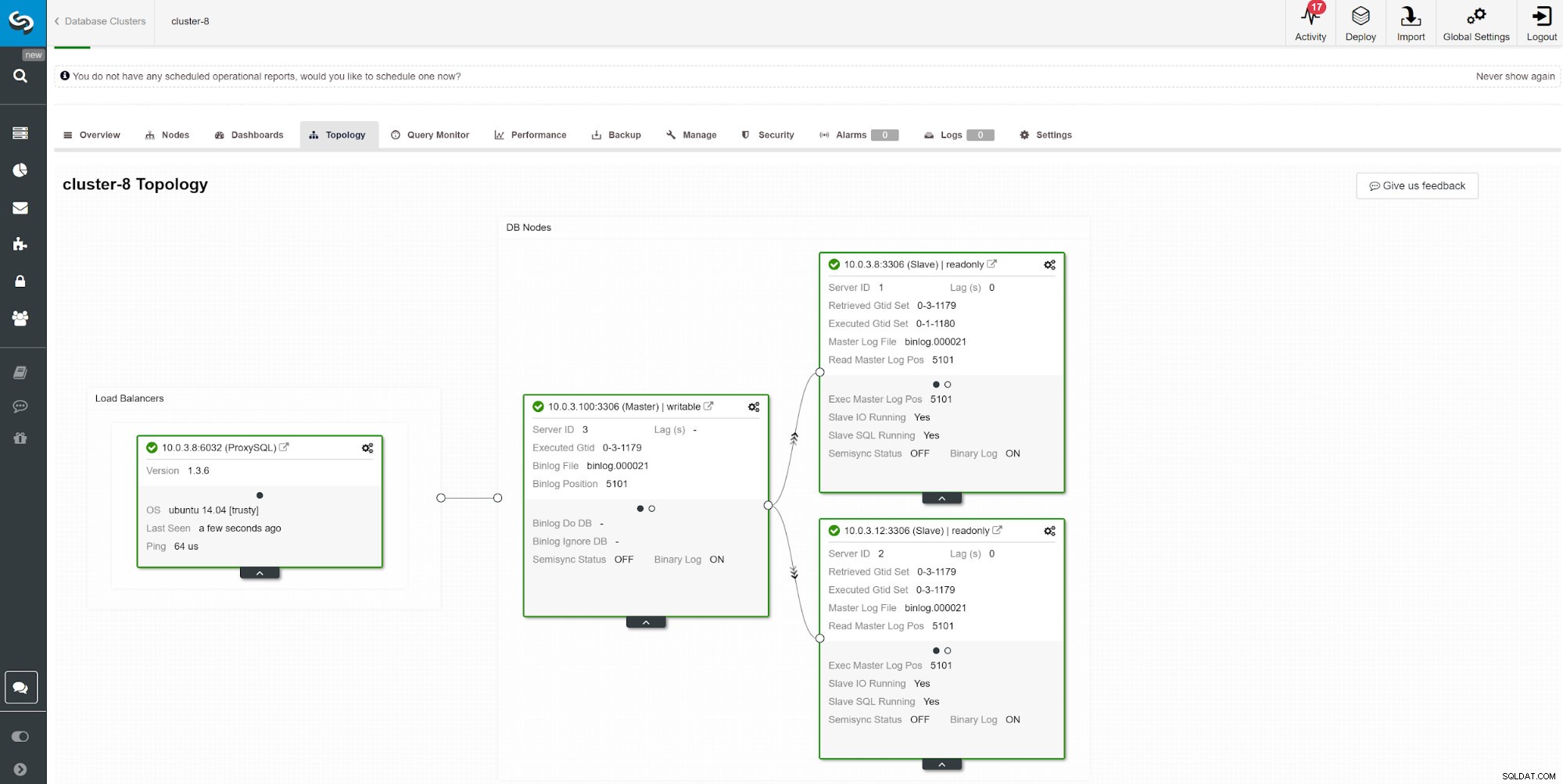 En anden måde at overvåge slaveforsinkelse på er at bruge ClusterControl-replikeringsovervågning. I dette skærmbillede kan vi se replikeringsstatussen for asymchoronous Master-Slave (2x) Cluster med ProxySQL.
En anden måde at overvåge slaveforsinkelse på er at bruge ClusterControl-replikeringsovervågning. I dette skærmbillede kan vi se replikeringsstatussen for asymchoronous Master-Slave (2x) Cluster med ProxySQL. Der er en række ting, der kan påvirke replikationstiden. Det mest oplagte er netværkets gennemløb og hvor meget data du kan overføre. MySQL kommer med flere konfigurationsmuligheder for at optimere replikeringsprocessen. De væsentlige replikationsrelaterede parametre er:
- Parallel gælder
- Logisk uralgoritme
- Kompression
- Selektiv master-slave-replikering
- Replikeringstilstand
Parallel gælder
Det er ikke ualmindeligt at begynde at tune replikering med aktivering af parallel proces. Grunden til det er som standard, MySQL går med sekventiel binær log-anvendelse, og en typisk databaseserver kommer med flere CPU'er til brug.
For at komme uden om sekventiel log, tilbyder både MariaDB og MySQL parallel replikering. Implementeringen kan variere fra leverandør og version. For eksempel. MySQL 5.6 tilbyder parallel replikering, så længe et skema adskiller forespørgslerne, mens MariaDB (startende version 10.0) og MySQL 5.7 begge kan håndtere parallel replikering på tværs af skemaer. Forskellige leverandører og versioner kommer med deres begrænsninger og funktioner, så tjek altid dokumentationen.
Udførelse af forespørgsler via parallelle slave-tråde kan fremskynde din replikeringsstrøm, hvis du skriver tungt. Men hvis du ikke er det, ville det være bedst at holde sig til den traditionelle enkelttrådede replikering. For at aktivere parallel behandling skal du ændre slave_parallel_workers til antallet af CPU-tråde, du vil involvere i processen. Det anbefales at holde værdien lavere end antallet af tilgængelige CPU-tråde.
Parallel replikering fungerer bedst med gruppeforpligtelser. Kør følgende forespørgsel for at kontrollere, om du har gruppeforpligtelser, der sker.
show global status like 'binlog_%commits';Jo større forholdet mellem disse to værdier jo bedre.
Logisk ur
Slave_parallel_type=LOGICAL_CLOCK er en implementering af en Lamport-uralgoritme. Når du bruger en multithreaded slave, specificerer denne variabel metoden, der bruges til at bestemme, hvilke transaktioner der må udføres parallelt på slaven. Variablen har ingen effekt på slaver, for hvilke multithreading ikke er aktiveret, så sørg for, at slave_parallel_workers er sat højere end 0.
MariaDB-brugere bør også tjekke optimistisk tilstand introduceret i version 10.1.3, da det også kan give dig bedre resultater.
GTID
MariaDB kommer med sin egen implementering af GTID. MariaDBs sekvens består af et domæne, server og transaktion. Domæner tillader replikering af flere kilder med et særskilt id. Forskellige domæne-id'er kan bruges til at replikere den del af data, der ikke er i orden (parallelt). Så længe det er okay for din applikation, kan dette reducere replikeringsforsinkelsen.
Den lignende teknik gælder for MySQL 5.7, som også kan bruge multisource master og uafhængige replikeringskanaler.
Kompression
CPU-kraft bliver billigere med tiden, så at bruge den til binlog-komprimering kan være en god mulighed for mange databasemiljøer. Parameteren slave_compressed_protocol fortæller MySQL at bruge komprimering, hvis både master og slave understøtter det. Som standard er denne parameter deaktiveret.
Fra MariaDB 10.2.3 kan udvalgte hændelser i den binære log komprimeres valgfrit for at gemme netværksoverførslerne.
Replikeringsformater
MySQL tilbyder flere replikeringstilstande. At vælge det rigtige replikeringsformat hjælper med at minimere tiden til at sende data mellem klyngeknuderne.
Multimaster-replikering for høj tilgængelighed
Nogle applikationer har ikke råd til at arbejde på forældede data.
I sådanne tilfælde vil du måske gennemtvinge konsistens på tværs af noderne med synkron replikering. At holde data synkrone kræver et ekstra plugin, og for nogle er den bedste løsning på markedet for det Galera Cluster.
Galera cluster kommer med wsrep API, som er ansvarlig for at transmittere transaktioner til alle noder og udføre dem i henhold til en klyngedækkende bestilling. Dette vil blokere for udførelsen af efterfølgende forespørgsler, indtil noden har anvendt alle skrivesæt fra sin applier-kø. Selvom det er en god løsning for konsistens, kan du ramme nogle arkitektoniske begrænsninger. De almindelige latensproblemer kan relateres til:
- Den langsomste node i klyngen
- Horisontal skalering og skriveoperationer
- Geolokaliserede klynger
- Høj ping
- Transaktionsstørrelse
Den langsomste node i klyngen
Ved design kan klyngens skriveydeevne ikke være højere end ydeevnen for den langsomste knude i klyngen. Start din klyngegennemgang ved at tjekke maskinens ressourcer og verificere konfigurationsfilerne for at sikre, at de alle kører på de samme ydeevneindstillinger.
Parallellisering
Parallelle tråde garanterer ikke bedre ydeevne, men det kan fremskynde synkroniseringen af nye noder med klyngen. Status wsrep_cert_deps_distance fortæller os den mulige grad af parallelisering. Det er værdien af den gennemsnitlige afstand mellem den højeste og laveste seqno-værdi, der eventuelt kan anvendes parallelt. Du kan bruge statusvariablen wsrep_cert_deps_distance til at bestemme det maksimalt mulige antal slavetråde.
Horisontal skalering
Ved at tilføje flere noder i klyngen har vi færre punkter, der kan fejle; dog skal informationen gå på tværs af multi-instanser, indtil den er begået, hvilket multiplicerer svartiderne. Hvis du har brug for skalerbare skrivninger, så overvej en arkitektur baseret på sharding. En god løsning kan være en Spider-lagringsmotor.
I nogle tilfælde kan du overveje at have én skribent ad gangen for at reducere information, der deles på tværs af klyngeknuderne. Det er relativt nemt at implementere, mens du bruger en load balancer. Når du gør dette manuelt, skal du sørge for at have en procedure til at ændre DNS-værdien, når din writer-node går ned.
Geolokaliserede klynger
Selvom Galera Cluster er synkront, er det muligt at implementere en Galera Cluster på tværs af datacentre. Synkron replikering som MySQL Cluster (NDB) implementerer en to-fase commit, hvor meddelelser sendes til alle noder i en klynge i en 'forbered' fase, og et andet sæt meddelelser sendes i en 'commit' fase. Denne tilgang er normalt ikke egnet til geografisk adskilte noder på grund af forsinkelserne i afsendelse af meddelelser mellem noder.
Høj ping
Galera Cluster med standardindstillingerne håndterer ikke godt høj netværksforsinkelse. Hvis du har et netværk med en node, der viser en høj pingtid, kan du overveje at ændre evs.send_window og evs.user_send_window parametre. Disse variabler definerer det maksimale antal datapakker i replikering ad gangen. For WAN-opsætninger kan variablen indstilles til en betydeligt højere værdi end standardværdien på 2. Det er almindeligt at sætte den til 512. Disse parametre er en del af wsrep_provider_options.
--wsrep_provider_options="evs.send_window=512;evs.user_send_window=512"Transaktionsstørrelse
En af de ting, du skal overveje, mens du kører Galera Cluster, er størrelsen på transaktionen. At finde balancen mellem transaktionsstørrelsen, ydeevnen og Galera-certificeringsprocessen er noget, du skal estimere i din ansøgning. Du kan finde mere information om det i artiklen How to Improve Performance of Galera Cluster for MySQL eller MariaDB af Ashraf Sharif.
Load Balancer Causal Consistence Reads
Selv med den minimerede risiko for dataforsinkelsesproblemer kan standard MySQL asynkron replikering ikke garantere konsistens. Det er stadig muligt, at dataene endnu ikke er replikeret til slave, mens din applikation læser dem derfra. Synkron replikering kan løse dette problem, men det har arkitekturbegrænsninger og passer muligvis ikke til dine applikationskrav (f.eks. intensive bulkskrivninger). Så hvordan overvinder man det?
Det første skridt til at undgå forældede datalæsning er at gøre applikationen opmærksom på replikeringsforsinkelse. Det er normalt programmeret i applikationskoden. Heldigvis er der moderne database-belastningsbalancere med understøttelse af adaptiv forespørgselsrouting baseret på GTID-sporing. De mest populære er ProxySQL og Maxscale.
ProxySQL 2.0
ProxySQL Binlog Reader giver ProxySQL mulighed for i realtid at vide, hvilket GTID der er blevet udført på hver MySQL-server, slaver og master selv. Takket være dette, når en klient udfører en læsning, der skal give kausale konsistenslæsninger, ved ProxySQL straks på hvilken server forespørgslen kan udføres. Hvis skrivningerne af en eller anden grund endnu ikke er udført på nogen slave, vil ProxySQL vide, at skribenten blev udført på master og sende læsningen dertil.
Maxscale 2.3
MariaDB introducerede casual læsninger i Maxscale 2.3.0. Den måde, det fungerer på, ligner ProxySQL 2.0. Dybest set, når causal_reads er aktiveret, vil enhver efterfølgende læsning udført på slaveservere blive udført på en måde, der forhindrer replikeringsforsinkelse i at påvirke resultaterne. Hvis slaven ikke har indhentet masteren inden for den konfigurerede tid, vil forespørgslen blive prøvet igen på masteren.