Hvorfor vælge MySQL-replikering?
Nogle grundlæggende ting først om replikeringsteknologien. MySQL-replikering er ikke kompliceret! Det er nemt at implementere, overvåge og tune, da der er forskellige ressourcer, du kan udnytte - google er én. MySQL-replikering indeholder ikke mange konfigurationsvariabler, der skal tunes. SQL_THREAD og IO_THREADs logiske fejl er ikke så svære at forstå og rette. MySQL-replikering er meget populær i dag og tilbyder en enkel måde at implementere database High Availability på. Kraftige funktioner såsom GTID (Global Transaction Identifier) i stedet for den gammeldags binære logposition eller tabsfri semisynkron replikering gør den mere robust.
Som vi så i et tidligere indlæg, er netværksforsinkelse en stor udfordring, når du skal vælge en løsning med høj tilgængelighed. Brug af MySQL-replikering giver fordelen ved ikke at være så følsom over for latency. Den implementerer ikke nogen certificeringsbaseret replikering, i modsætning til Galera Cluster bruger gruppekommunikation og transaktionsbestillingsteknikker til at opnå synkron replikering. Det har således ikke noget krav om, at alle noderne skal certificere et skrivesæt, og det er ikke nødvendigt at vente før en commit på den anden slave eller replika.
At vælge den traditionelle MySQL-replikering med asynkron primær-sekundær tilgang giver dig hurtighed, når det kommer til at håndtere transaktioner inde fra din master; det behøver ikke at vente på, at slaverne synkroniserer eller udfører transaktioner. Opsætningen har typisk en primær (master) og en eller flere sekundære (slaver). Derfor er det et delt-intet-system, hvor alle servere har en fuld kopi af dataene som standard. Selvfølgelig er der ulemper. Dataintegritet kan være et problem, hvis dine slaver ikke kunne replikere på grund af SQL- og I/O-trådfejl eller nedbrud. Alternativt, for at løse problemer med dataintegritet, kan du vælge at implementere MySQL-replikering som semi-synkron (eller kaldet tabsfri semi-synkronisering i MySQL 5.7). Hvordan dette virker er, at masteren er nødt til at vente, indtil en replika anerkender alle hændelser i transaktionen. Det betyder, at den skal afslutte sin skrivning til en relælog og skylle til disk, før den sender tilbage til masteren med et ACK-svar. Med semi-synkron replikering aktiveret, skal tråde eller sessioner i masteren vente på bekræftelse fra en replika. Når den først får et ACK-svar fra replikaen, kan den forpligte transaktionen. Illustrationen nedenfor viser, hvordan MySQL håndterer semi-synkron replikering.
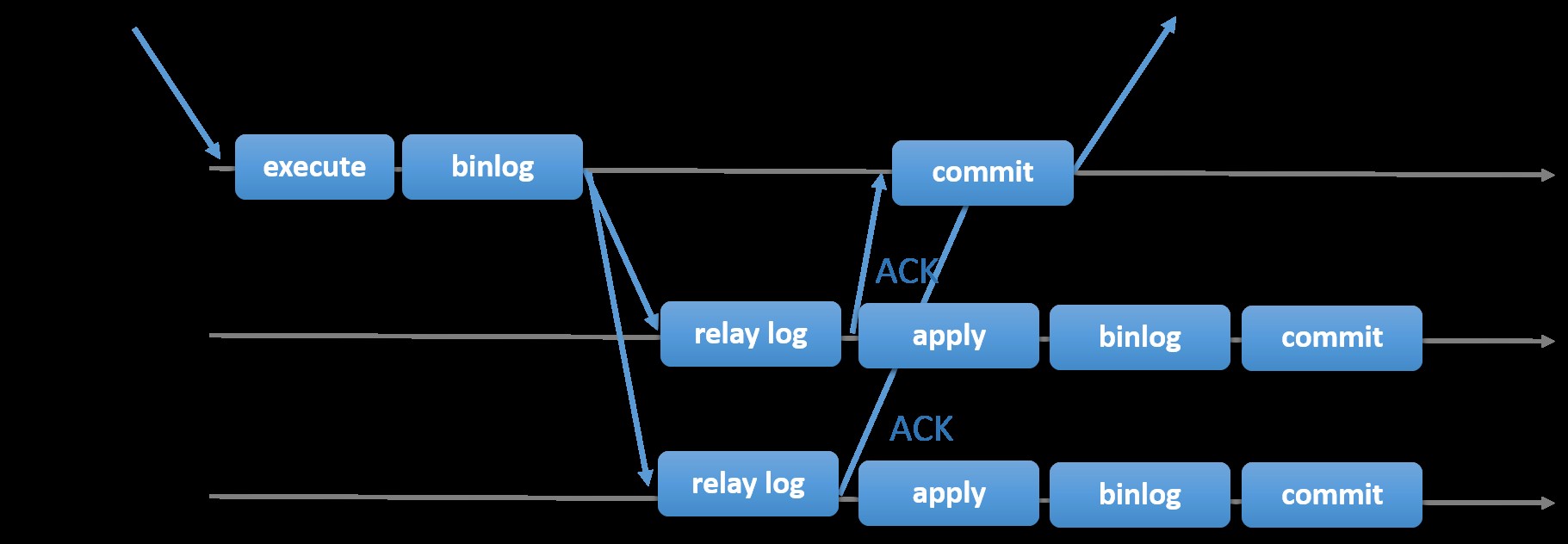 Billede med tilladelse fra MySQL-dokumentation
Billede med tilladelse fra MySQL-dokumentation Med denne implementering er alle forpligtede transaktioner allerede replikeret til mindst én slave i tilfælde af et masternedbrud. Selv om semi-synkron ikke i sig selv repræsenterer en højtilgængelig løsning, men det er en komponent til din løsning. Det er bedst, at du kender dine behov og justerer din semi-synkroniserede implementering i overensstemmelse hermed. Derfor, hvis noget datatab er acceptabelt, kan du i stedet bruge den traditionelle asynkrone replikering.
GTID-baseret replikering er nyttig for DBA'en, da det forenkler opgaven at lave en failover, især når en slave peges på en anden master eller ny master. Dette betyder, at med en simpel MASTER_AUTO_POSITION=1 efter indstilling af de korrekte værts- og replikeringsoplysninger, vil den begynde at replikere fra masteren uden behov for at finde og specificere de korrekte binære log x &y-positioner. Tilføjelse af understøttelse af parallel replikering booster også replikeringstrådene, da det øger hastigheden til at behandle hændelser fra relæloggen.
MySQL-replikering er således et godt valg komponent frem for andre HA-løsninger, hvis det passer til dine behov.
Topologier til MySQL-replikering
Implementering af MySQL-replikering i et multicloud-miljø med GCP (Google Cloud Platform) og AWS er stadig den samme tilgang, hvis du skal replikere på stedet.
Der er forskellige topologier, du kan opsætte og implementere.
Master med slavereplikering (enkelt replikering)
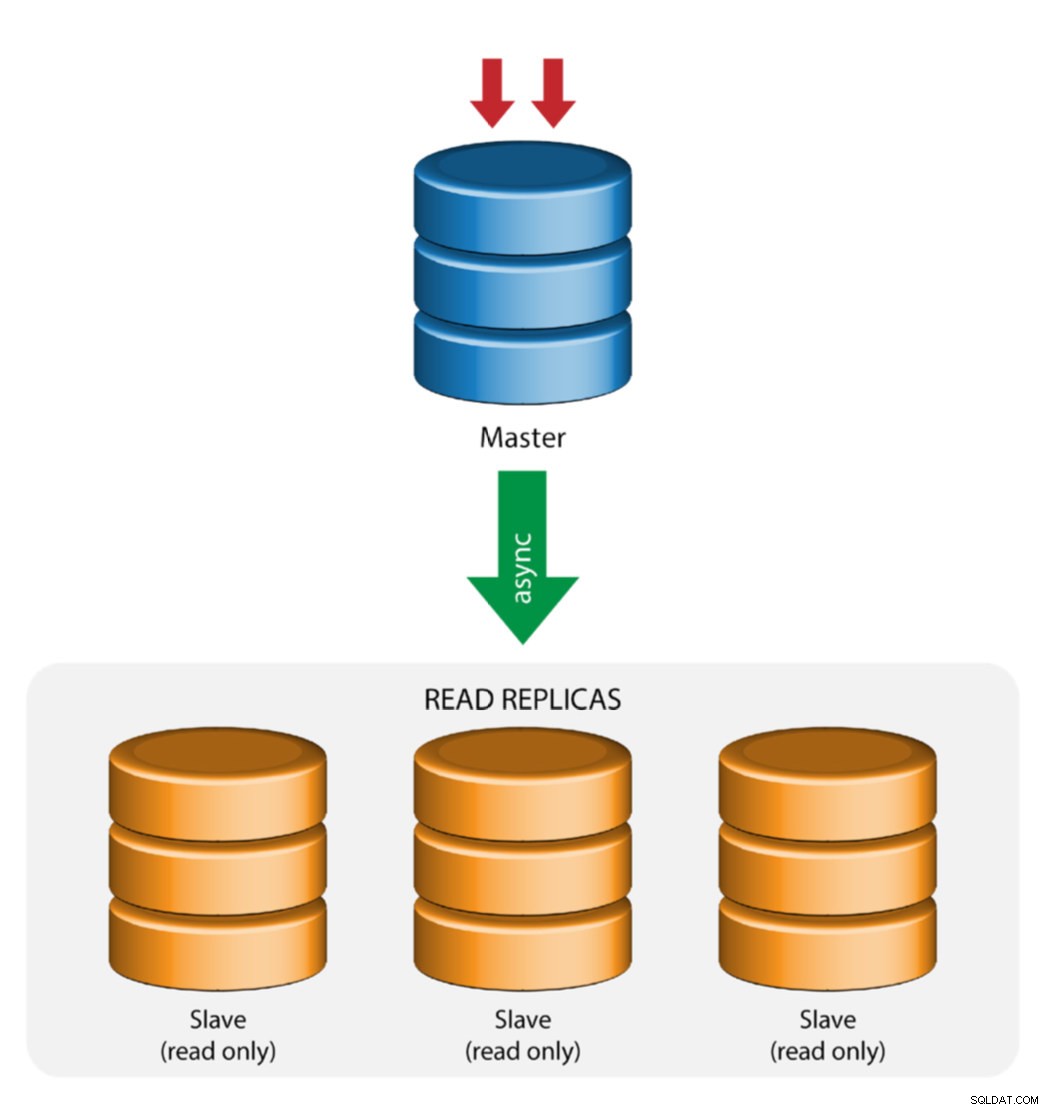
Dette er den mest ligetil MySQL-replikationstopologi. En master modtager skrivninger, en eller flere slaver replikerer fra den samme master via asynkron eller semisynkron replikering. Hvis den udpegede master går ned, skal den mest opdaterede slave forfremmes som ny master. De resterende slaver genoptager replikeringen fra den nye master.
Master med relæslaver (kædereplikering)
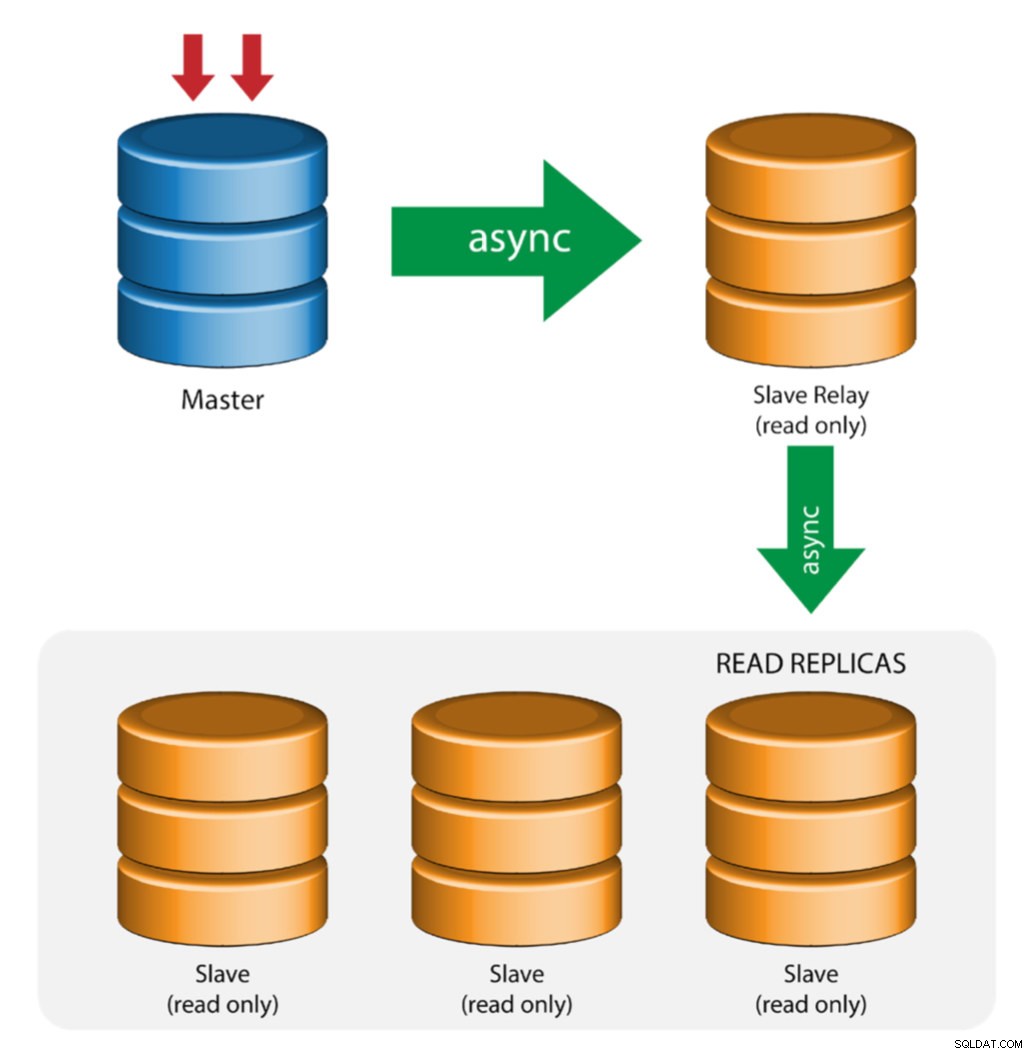
Denne opsætning bruger en mellemliggende master til at fungere som et relæ til de andre slaver i replikationskæden. Når der er mange slaver forbundet til en master, kan masterens netværksgrænseflade blive overbelastet. Denne topologi gør det muligt for læsereplikaerne at trække replikeringsstrømmen fra relæserveren for at aflaste masterserveren. På slaverelæserveren skal binær logning og log_slave_updates være aktiveret, hvorved opdateringer modtaget af slaveserveren fra masterserveren logges på slavens egen binære log.
Brug af slaverelæ har sine problemer:
- log_slave_updates har en vis ydeevnestraf.
- Replikeringsforsinkelse på slaverelæserveren vil generere forsinkelse på alle dens slaver.
- Skyndige transaktioner på slaverelæserveren vil inficere alle dens slaver.
- Hvis en slave-relæserver fejler, og du ikke bruger GTID, stopper alle dens slaver med at replikere, og de skal geninitialiseres.
Master med Active Master (cirkulær replikering)
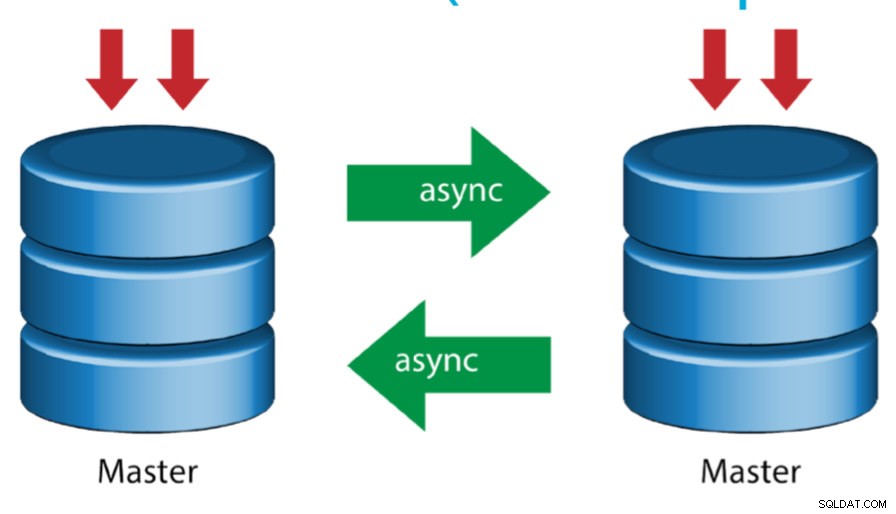
Også kendt som ringtopologi kræver denne opsætning to eller flere MySQL-servere, der fungerer som master. Alle mastere modtager skrivninger og genererer binlogs med nogle få forbehold:
- Du skal indstille automatisk stigningsforskydning på hver server for at undgå primærnøglekollisioner.
- Der er ingen konfliktløsning.
- MySQL-replikering understøtter i øjeblikket ikke nogen låseprotokol mellem master og slave for at garantere atomiciteten af en distribueret opdatering på tværs af to forskellige servere.
- Almindelig praksis er kun at skrive til én master, og den anden master fungerer som en hot-standby node. Alligevel, hvis du har slaver under det niveau, skal du skifte til den nye master manuelt, hvis den udpegede master fejler.
- ClusterControl understøtter denne topologi (vi anbefaler ikke flere forfattere i en replikeringsopsætning). Se denne tidligere blog om, hvordan du implementerer med ClusterControl.
Master med Backup Master (Multiple Replikering)
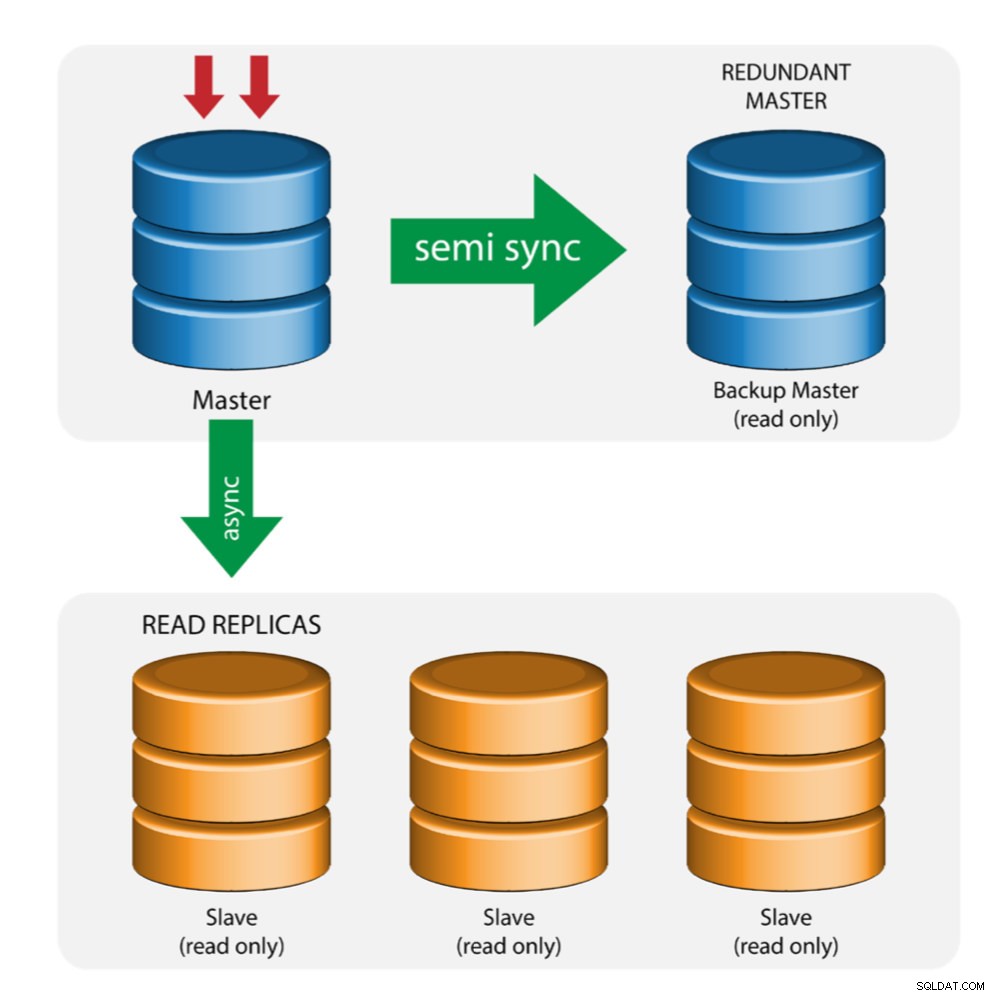
Masteren skubber ændringer til en backup-master og til en eller flere slaver. Semi-synkron replikering bruges mellem master og backup master. Master sender opdatering til backup master og venter med transaktionsbekræftelse. Backup master får opdateringer, skriver til sin relælog og skyller til disk. Backup-masteren bekræfter derefter modtagelsen af transaktionen til masteren og fortsætter med transaktionsbekræftelse. Semi-synkron replikering har en præstationspåvirkning, men risikoen for datatab er minimeret.
Denne topologi fungerer godt, når der udføres master-failover i tilfælde af, at masteren går ned. Backup-masteren fungerer som en varm-standby-server, da den har den højeste sandsynlighed for at have opdaterede data sammenlignet med andre slaver.
Flere mastere til enkelt slave (multikilde replikering)
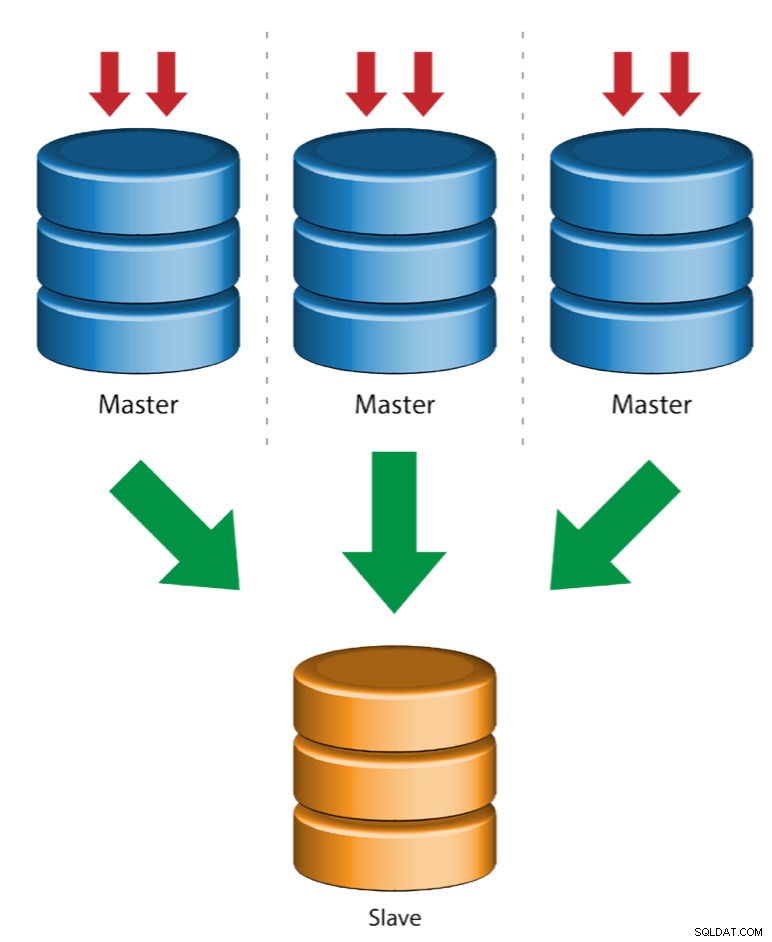
Multi-Source Replikering gør det muligt for en replikeringsslave at modtage transaktioner fra flere kilder samtidigt. Multi-source replikering kan bruges til at sikkerhedskopiere flere servere til en enkelt server, til at flette tabel shards og konsolidere data fra flere servere til en enkelt server.
MySQL og MariaDB har forskellige implementeringer af multi-source replikering, hvor MariaDB skal have GTID med gtid-domain-id konfigureret til at skelne de oprindelige transaktioner, mens MySQL bruger en separat replikeringskanal for hver master, slaven replikerer fra. I MySQL kan mastere i en multikilde-replikeringstopologi konfigureres til at bruge enten global transaktionsidentifikator (GTID)-baseret replikering eller binær log-positionsbaseret replikering.
Mere om MariaDB multi source replikering kan findes i dette blogindlæg. For MySQL, se venligst MySQL-dokumentationen.
Galera med replikeringsslave (hybrid replikering)
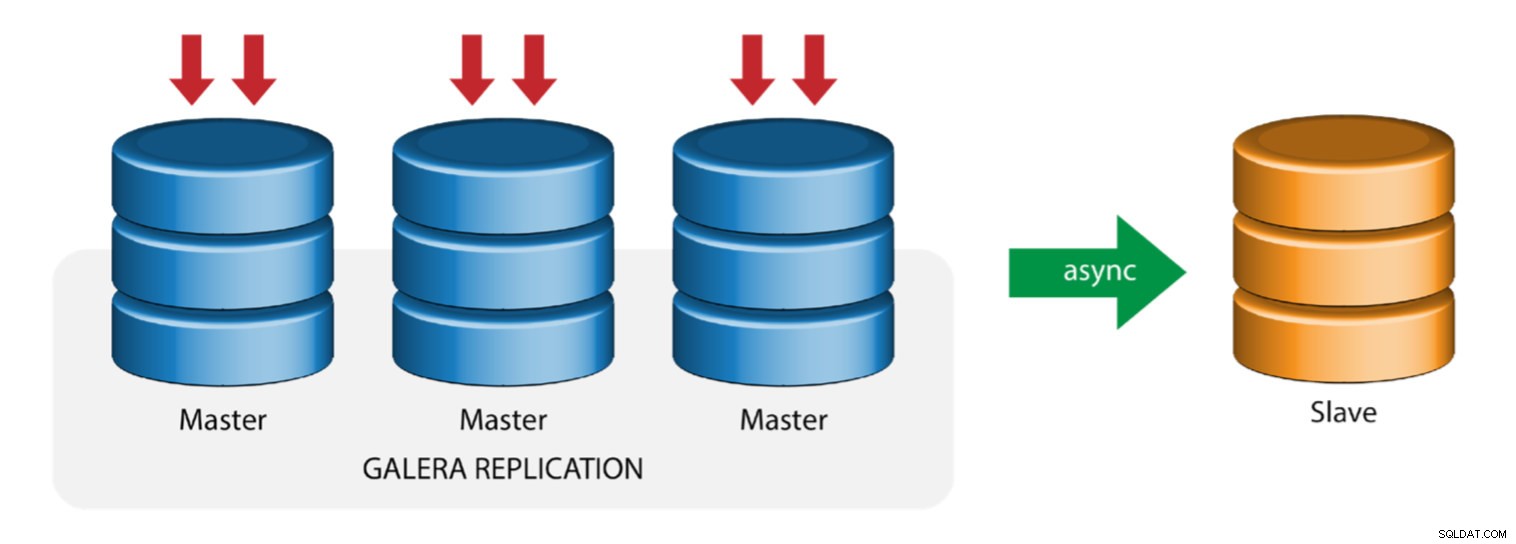
Hybrid replikering er en kombination af MySQL asynkron replikering og praktisk talt synkron replikering leveret af Galera. Implementeringen er nu forenklet med implementeringen af GTID i MySQL-replikering, hvor opsætning og udførelse af master-failover er blevet en ligetil proces på slavesiden.
Galera-klyngeydelsen er lige så hurtig som den langsomste knude. At have en asynkron replikeringsslave kan minimere indvirkningen på klyngen, hvis du sender langvarige rapporterings-/OLAP-forespørgsler til slaven, eller hvis du udfører tunge job, der kræver låse som mysqldump. Slaven kan også tjene som en live backup for onsite og offsite katastrofegendannelse.
Hybrid replikering understøttes af ClusterControl, og du kan implementere den direkte fra ClusterControl UI. For mere information om, hvordan du gør dette, læs venligst blogindlæggene - Hybrid replikering med MySQL 5.6 og Hybrid replikering med MariaDB 10.x.
Forberedelse af GCP- og AWS-platforme
Problemet "den virkelige verden"
I denne blog vil vi demonstrere og bruge "Multiple Replication"-topologien, hvor instanser på to forskellige offentlige cloud-platforme vil kommunikere ved hjælp af MySQL-replikering i forskellige regioner og på forskellige tilgængelighedszoner. Dette scenarie er baseret på et problem i den virkelige verden, hvor en organisation ønsker at bygge deres infrastruktur på flere cloud-platforme for skalerbarhed, redundans, robusthed/fejltolerance. Lignende koncepter vil gælde for MongoDB eller PostgreSQL.
Lad os overveje en amerikansk organisation med en oversøisk afdeling i Sydøstasien. Vores trafik er høj i den asiatisk-baserede region. Latency skal være lav, når der tages hensyn til skrivninger og læsninger, men samtidig kan den amerikansk-baserede region også hente registreringer fra den asiatisk-baserede trafik.
The Cloud Architecture Flow
I dette afsnit vil jeg diskutere det arkitektoniske design. For det første ønsker vi at tilbyde et meget sikkert lag, som vores Google Compute og AWS EC2 noder kan kommunikere, opdatere eller installere pakker fra internettet til, sikkert, meget tilgængeligt, hvis en AZ (Availability Zone) går ned, kan replikere og kommunikere til en anden cloud-platform over et sikret lag. Se billedet nedenfor for illustration:

Baseret på illustrationen ovenfor, under AWS-platformen, kører alle noder på forskellige tilgængelighedszoner. Den har et privat og offentligt undernet, hvor alle beregningsknudepunkter er på et privat undernet. Derfor kan den gå uden for internettet for at trække og opdatere sine systempakker, når det er nødvendigt. Den har en VPN-gateway, som den skal interagere med GCP på den kanal, der går uden om internettet, men gennem en sikker og privat kanal. Samme som GCP er alle computerknudepunkter i forskellige tilgængelighedszoner, brug NAT Gateway til at opdatere systempakker, når det er nødvendigt, og brug VPN-forbindelse til at interagere med AWS-noder, som er hostet i en anden region, det vil sige Asia Pacific (Singapore). På den anden side er den USA-baserede region hostet under us-east1. For at få adgang til noderne fungerer en node i arkitekturen som bastion-node, som vi vil bruge den til som springvært og installere ClusterControl. Dette vil blive behandlet senere i denne blog.
Opsætning af GCP- og AWS-miljøer
Når du registrerer din første GCP-konto, leverer Google en standard VPC-konto (Virtual Private Cloud). Derfor er det bedst at oprette en separat VPC end standarden og tilpasse den efter dine behov.
Vores mål her er at placere beregningsknuderne i private undernet, ellers vil noder ikke blive sat op med offentlig IPv4. Derfor skal begge offentlige skyer være i stand til at tale med hinanden. AWS- og GCP-beregningsknuderne fungerer med forskellige CIDR'er som tidligere nævnt. Derfor er her følgende CIDR:
AWS Compute Nodes: 172.21.0.0/16
GCP Compute Nodes: 10.142.0.0/20
I denne AWS-opsætning tildelte vi tre undernet, som ikke har nogen internet-gateway men NAT-gateway; og et undernet, som har en internetgateway. Hvert af disse undernet hostes individuelt i forskellige tilgængelighedszoner (AZ).
ap-southeast-1a =172.21.1.0/24
ap-sydøst-1b =172.21.8.0/24
ap-southeast-1c =172.21.24.0/24
Mens du er i GCP, bruges standardundernet, der er oprettet i en VPC under us-east1, som er 10.142.0.0/20 CIDR. Derfor er disse trin, du kan følge for at konfigurere din multi-offentlige cloud-platform.
-
Til denne øvelse oprettede jeg en VPC i us-east1-regionen med følgende undernet på 10.142.0.0/20. Se nedenfor:

-
Reserver en statisk IP. Dette er den IP, som vi vil konfigurere som en kundegateway i AWS
-
Da vi har undernet på plads (tilvejebragt som subnet-us-east1 ), gå til GCP -> VPC-netværk -> VPC-netværk og vælg den VPC, du har oprettet, og gå til Firewall-reglerne . Tilføj reglerne i dette afsnit ved at specificere din ind- og udgang. Dybest set er disse indgående/udgående regler i AWS eller din firewall for indgående og udgående forbindelser. I denne opsætning åbnede jeg alle TCP-protokoller fra CIDR-intervallet, der er sat i min AWS og GCP VPC for at gøre det enklere til formålet med denne blog. Derfor er dette ikke den optimale måde for sikkerhed. Se billedet nedenfor:
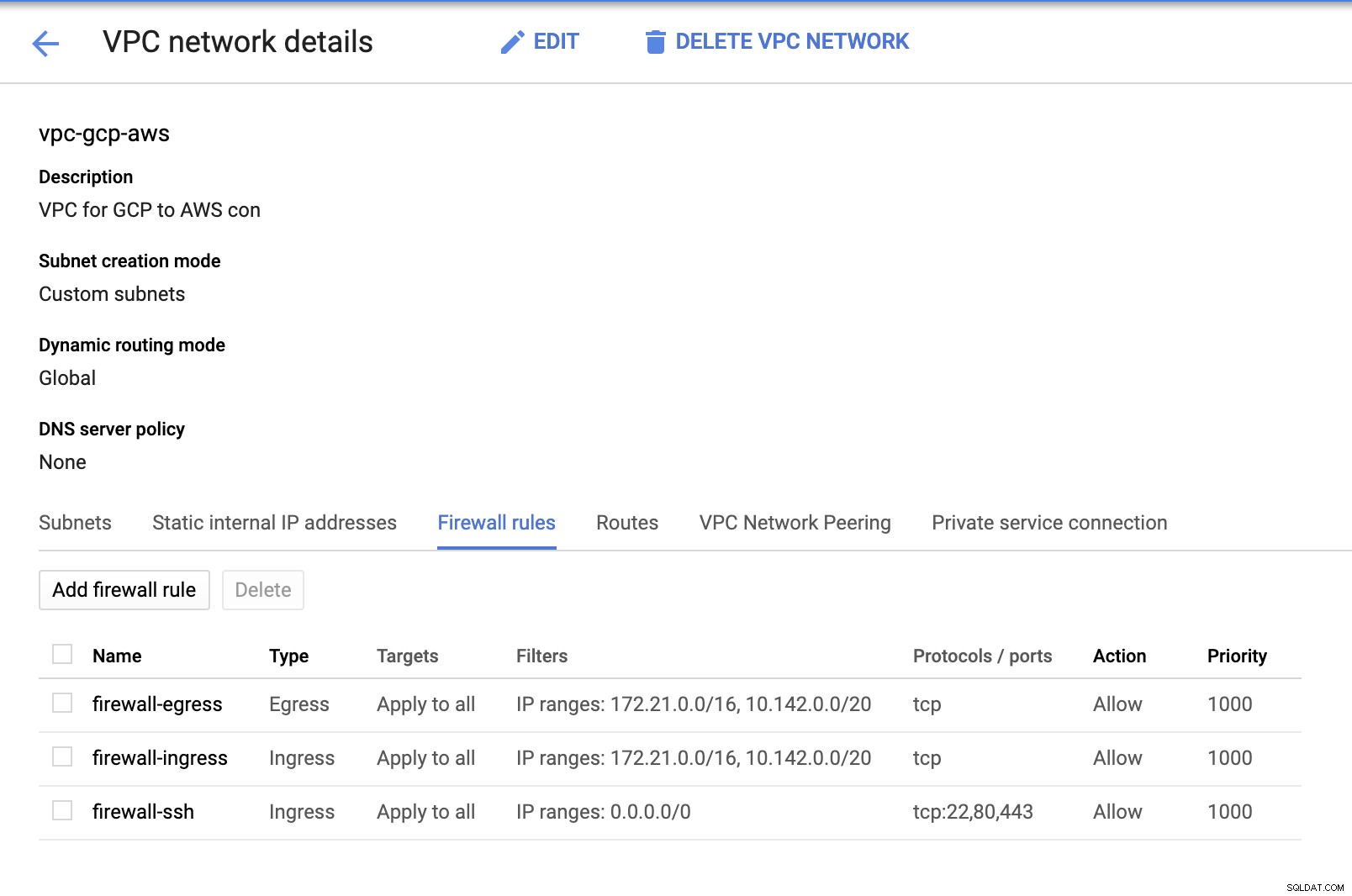
Firewall-ssh her vil blive brugt til at tillade ssh, HTTP og HTTPS indgående forbindelser.
-
Skift nu til AWS og opret en VPC. Til denne blog brugte jeg CIDR (Classless Inter-Domain Routing) 172.21.0.0/16
-
Opret de undernet, som du skal tildele dem til i hver AZ (Availability Zone); og mindst reserver ét undernet til et offentligt undernet, som vil håndtere NAT-gatewayen, og resten er til EC2-noder.

-
Opret derefter din rutetabel og sørg for, at "Destination" og "Targets" er indstillet korrekt. Til denne blog har jeg lavet 2 rutetabeller. En som vil håndtere de 3 AZ, som mine computerknudepunkter vil blive tildelt individuelt og vil blive tildelt uden en internetgateway, da den ikke vil have nogen offentlig IP. Så vil den anden håndtere NAT-gatewayen og vil have en internetgateway, som vil være i det offentlige undernet. Se billedet nedenfor:

og som nævnt viser min eksempeldestination for privat rute, der håndterer 3 undernet, at have et NAT Gateway-mål plus et Virtual Gateway-mål, som jeg vil nævne senere i de indgående trin.

-
Derefter skal du oprette en "Internet Gateway" og tildele den til den VPC, der tidligere blev oprettet i AWS VPC-sektionen. Denne internetgateway skal kun indstilles som destination til det offentlige undernet, da det vil være den tjeneste, der skal oprette forbindelse til internettet. Naturligvis står navnet for som en internetgateway-tjeneste.
-
Opret derefter en "NAT Gateway". Når du opretter en "NAT Gateway", skal du sikre dig, at du har tildelt din NAT til et offentligt vendt undernet. NAT-gatewayen er din kanal til at få adgang til internettet fra dit private undernet eller EC2-noder, der ikke har nogen offentlig IPv4 tildelt. Opret eller tildel derefter en EIP (Elastic IP), da det i AWS kun er computerknudepunkter, der har offentlig IPv4 tildelt, der kan oprette forbindelse direkte til internettet.
-
Nu under VPC -> Sikkerhed -> Sikkerhedsgrupper (SG) , vil din oprettede VPC have en standard SG. Til denne opsætning oprettede jeg "Inbound Rules" med kilder tildelt for hver CIDR, dvs. 10.142.0.0/20 i GCP og 172.21.0.0/16 i AWS. Se nedenfor:

For "Udgående regler" kan du lade det være som det er, da tildeling af regler til "Indgående regler" er bilateralt, hvilket betyder, at det også åbner for "Udgående regler". Vær opmærksom på, at dette ikke er den optimale måde at indstille din sikkerhedsgruppe på; men for at gøre det nemmere for denne opsætning har jeg også lavet et bredere spektrum af portområde og kilde. Også at protokollen kun er specifik for TCP-forbindelser, da vi ikke vil beskæftige os med UDP for denne blog.
Derudover kan du forlade dine VPC -> Sikkerhed -> Netværks-ACL'er uberørt, så længe den ikke NÆGTER nogen tcp-forbindelser fra CIDR angivet i din kilde. -
Dernæst opsætter vi VPN-konfigurationen, som vil blive hostet under AWS-platformen. Under VPC -> Kundegateways , opret gatewayen ved hjælp af den statiske IP-adresse, der blev oprettet tidligere i det forrige trin. Tag et kig på billedet nedenfor:
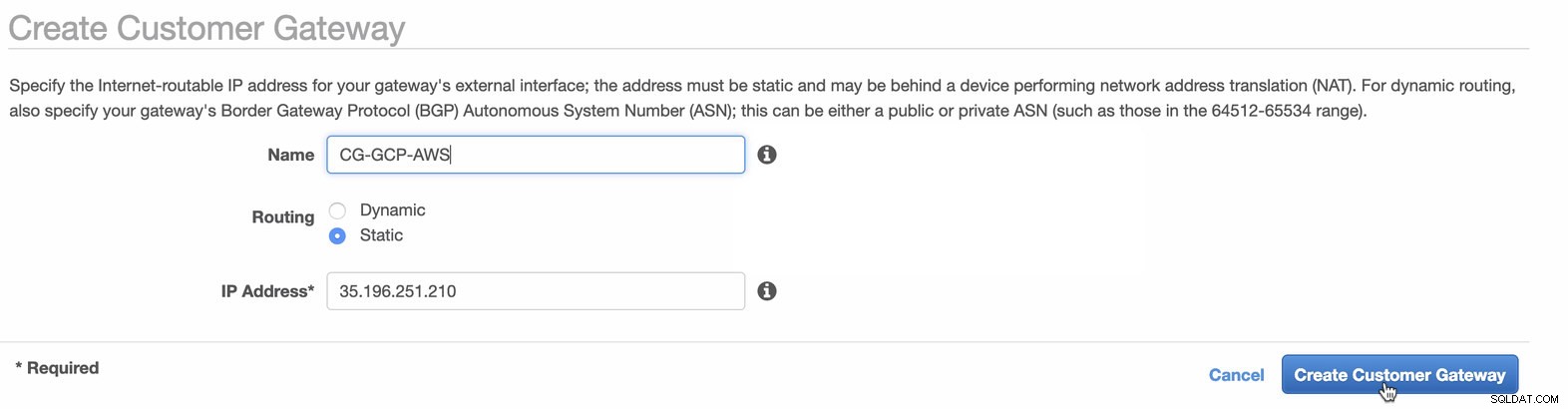
-
Opret derefter en Virtual Private Gateway og vedhæft denne til den aktuelle VPC, som vi oprettede tidligere i det forrige trin. Se billedet nedenfor:

-
Opret nu en VPN-forbindelse, som vil blive brugt til site-to-site-forbindelsen mellem AWS og GCP. Når du opretter en VPN-forbindelse, skal du sørge for, at du har valgt den korrekte Virtual Private Gateway og den Customer Gateway, som vi oprettede i de foregående trin. Se billedet nedenfor:
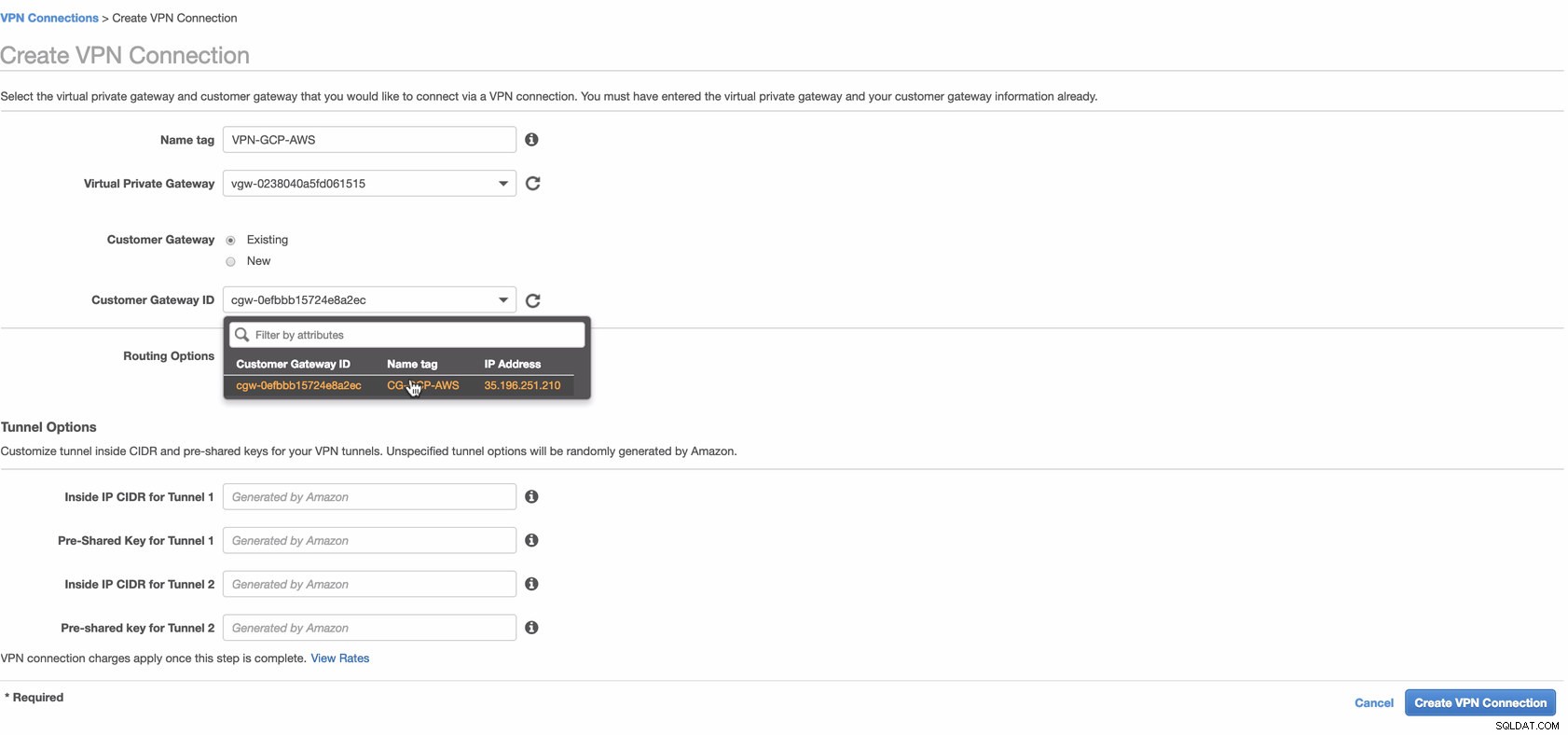
Dette kan tage noget tid, mens AWS opretter din VPN-forbindelse. Når din VPN-forbindelse derefter er klargjort, vil du måske undre dig over, hvorfor den under fanen Tunnel (når du har valgt din VPN-forbindelse), vil vise, at Udvendig IP-adresse er nede. Dette er normalt, da der endnu ikke er oprettet forbindelse fra klienten. Tag et kig på eksempelbilledet nedenfor:

Når VPN-forbindelsen er klar, skal du vælge din oprettede VPN-forbindelse og downloade konfigurationen. Den indeholder dine legitimationsoplysninger, der er nødvendige for de følgende trin for at oprette en site-to-site VPN-forbindelse med klienten.
Bemærk: Hvis du har konfigureret din VPN, hvor IPSEC ER OP men Status er NED ligesom billedet nedenfor

dette skyldes sandsynligvis forkerte værdier indstillet til de specifikke parametre under opsætning af din BGP-session eller cloud-router. Tjek det ud her for fejlfinding af din VPN.
-
Da vi har en VPN-forbindelse klar hostet i AWS, lad os oprette en VPN-forbindelse i GCP. Lad os nu gå tilbage til GCP og konfigurere klientforbindelsen der. I GCP skal du gå til GCP -> Hybrid Connectivity -> VPN . Sørg for, at du vælger den korrekte region, som er på denne blog, vi bruger us-east1 . Vælg derefter den statiske IP-adresse, der blev oprettet i de foregående trin. Se billedet nedenfor:
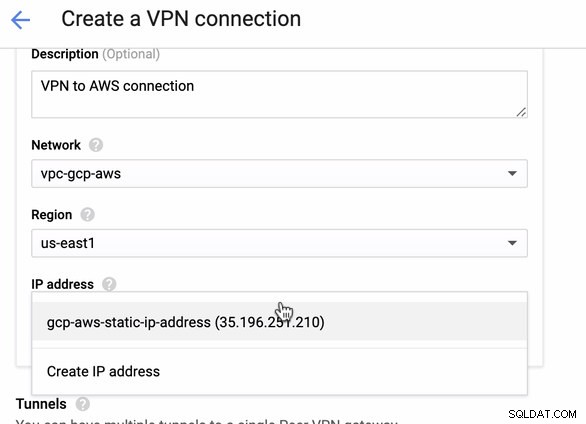
Derefter i Tunnellerne sektion, er det her, du skal konfigurere baseret på de downloadede legitimationsoplysninger fra den AWS VPN-forbindelse, du oprettede tidligere. Jeg foreslår at tjekke denne nyttige guide fra Google. For eksempel er en af tunnelerne under opsætning vist på billedet nedenfor:
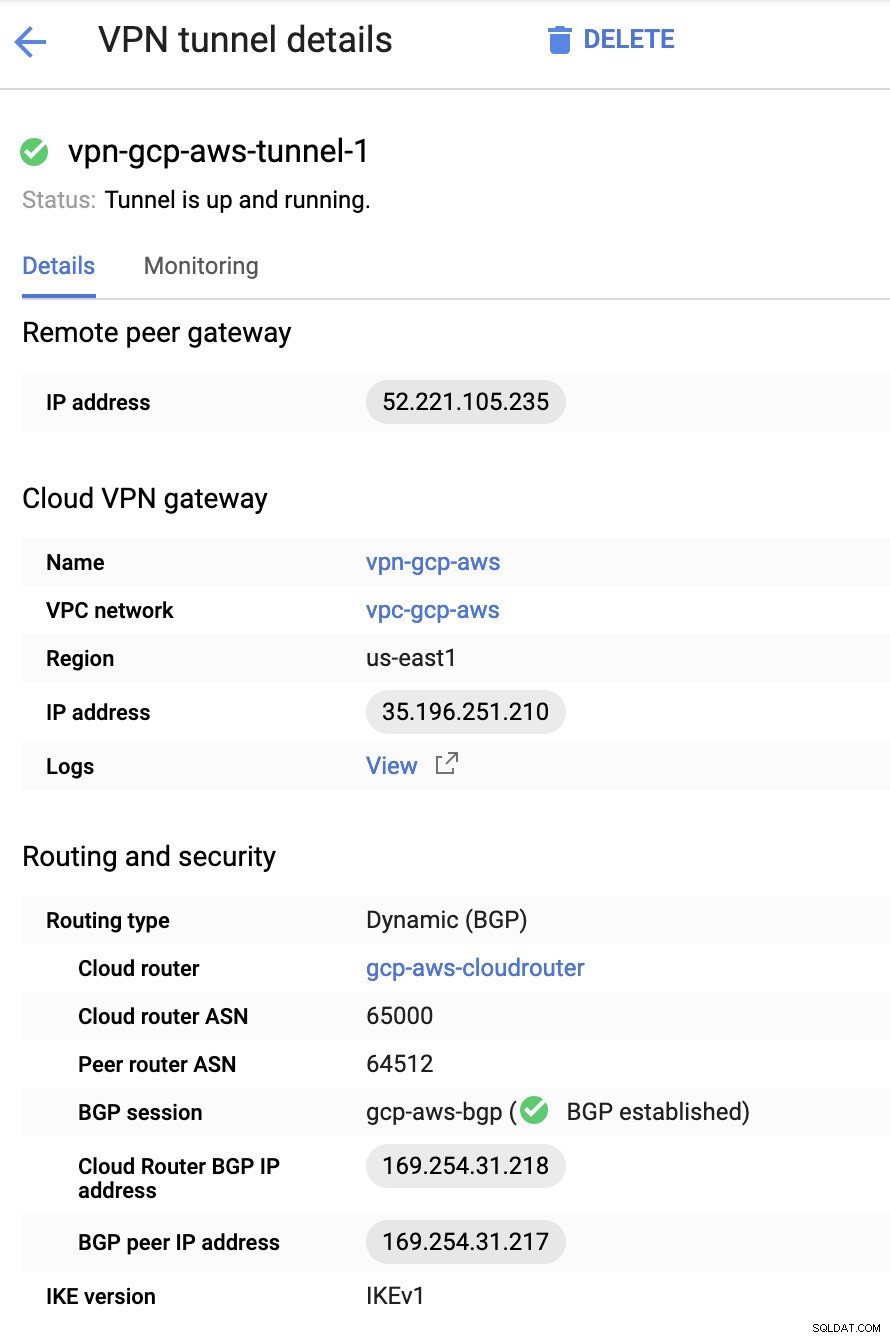
Grundlæggende er de vigtigste ting her følgende:
- Remote Peer Gateway:IP-adresse - Dette er IP-adressen for VPN-serveren angivet under Tunneldetaljer -> Udvendig IP-adresse . Dette skal ikke forveksles med den statiske IP, vi oprettede under GCP. Det er Cloud VPN-gatewayen -> IP-adressen dog.
- Cloud router ASN - Som standard bruger AWS 65000. Men sandsynligvis vil du få disse oplysninger fra den downloadede konfigurationsfil.
- Peer router ASN - Dette er Virtual Private Gateway ASN som findes i den downloadede konfigurationsfil.
- Cloud Router BGP IP-adresse - Dette er Kundegatewayen fundet i den downloadede konfigurationsfil.
- BGP peer IP-adresse - Dette er den Virtual Private Gateway fundet i den downloadede konfigurationsfil.
-
Tag et kig på eksemplet på konfigurationsfilen, jeg har nedenfor:
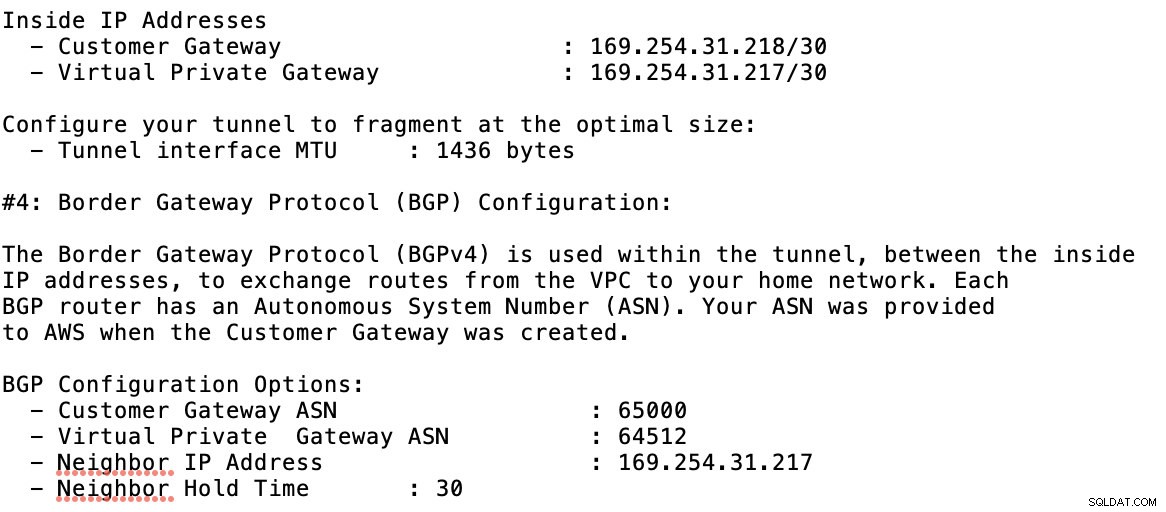
som du skal matche dette under tilføjelse af din tunnel under GCP -> Hybrid Connectivity -> VPN opsætning af forbindelse. Se billedet nedenfor, hvor jeg oprettede en cloud-router og en BGP-session under oprettelse af en prøvetunnel:
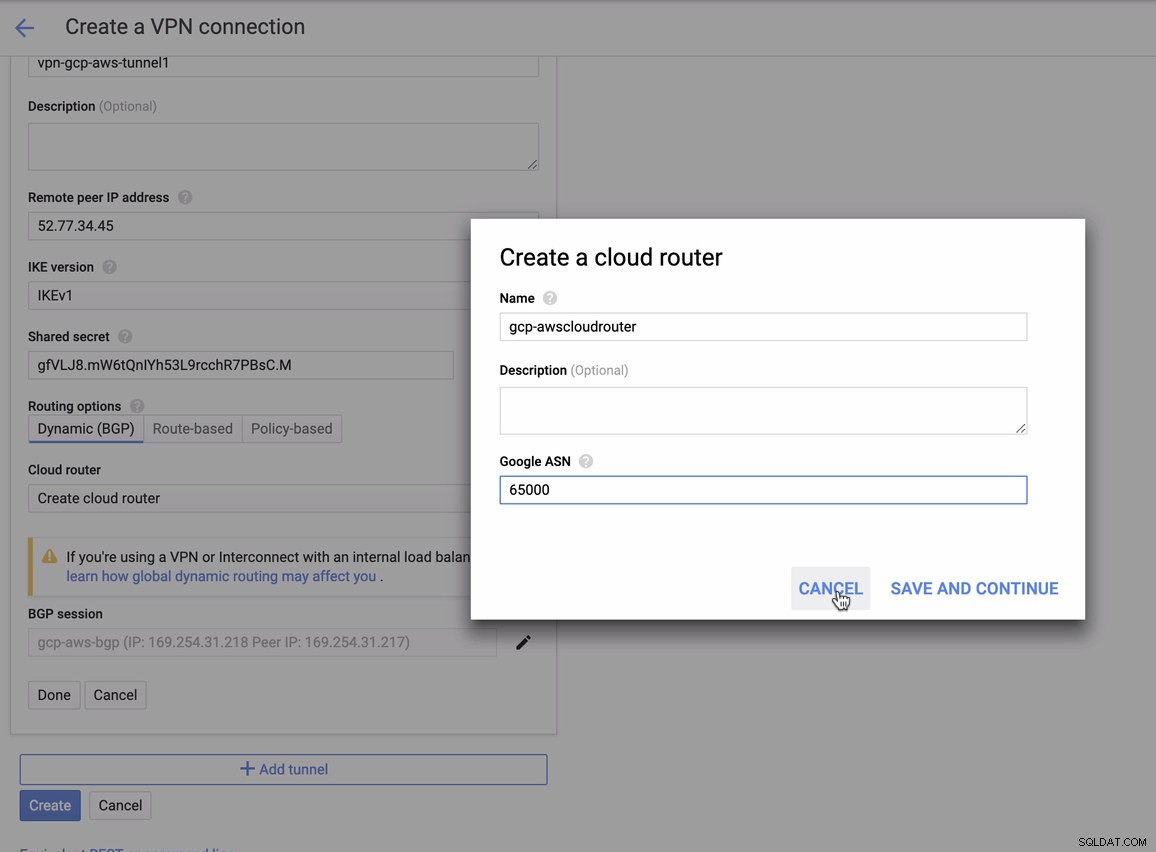
Derefter BGP session som,

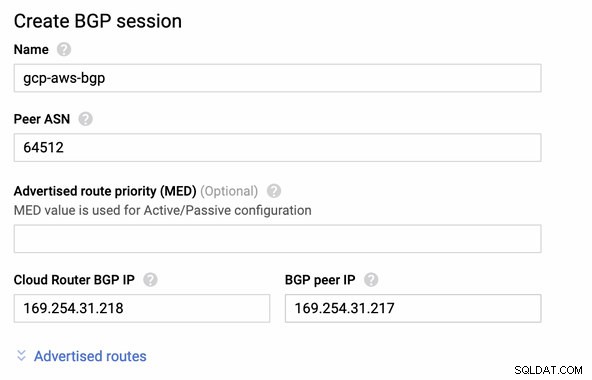
Bemærk: Den downloadede konfigurationsfil indeholder IPSec-konfigurationstunnelen, hvor AWS også indeholder to (2) VPN-servere klar til din forbindelse. Du skal konfigurere dem begge, så du har en høj tilgængelig opsætning. Når den er opsat for begge tunneler korrekt, vil AWS VPN-forbindelsen under fanen Tunneler vise, at både Udvendig IP-adresse er oppe. Se billedet nedenfor:

-
Til sidst, da vi har oprettet en Internet Gateway og NAT Gateway, skal du udfylde de offentlige og private undernet korrekt med korrekt Destination og Mål som bemærket på skærmbilledet fra tidligere trin. Dette kan konfigureres ved at gå til Tjenester -> Netværk og indholdslevering -> VPC -> Rutetabeller og vælg de oprettede rutetabeller nævnt fra de foregående trin. Se billedet nedenfor:
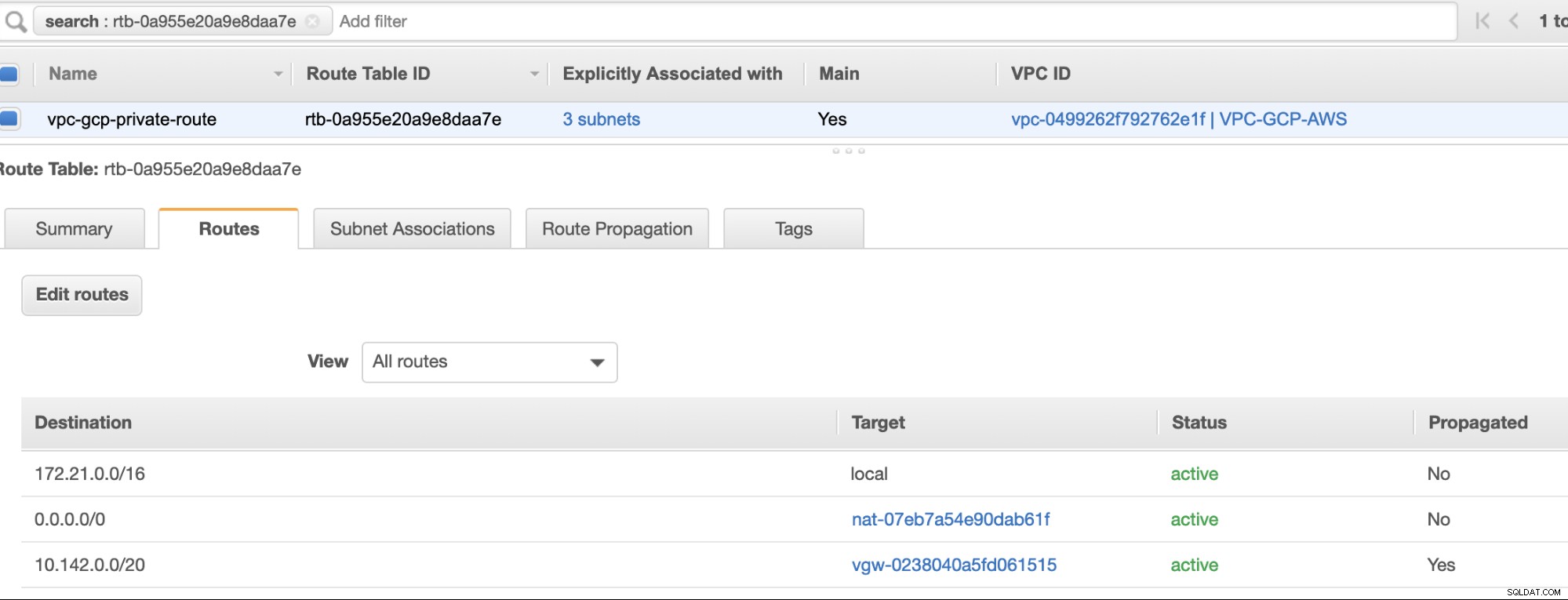
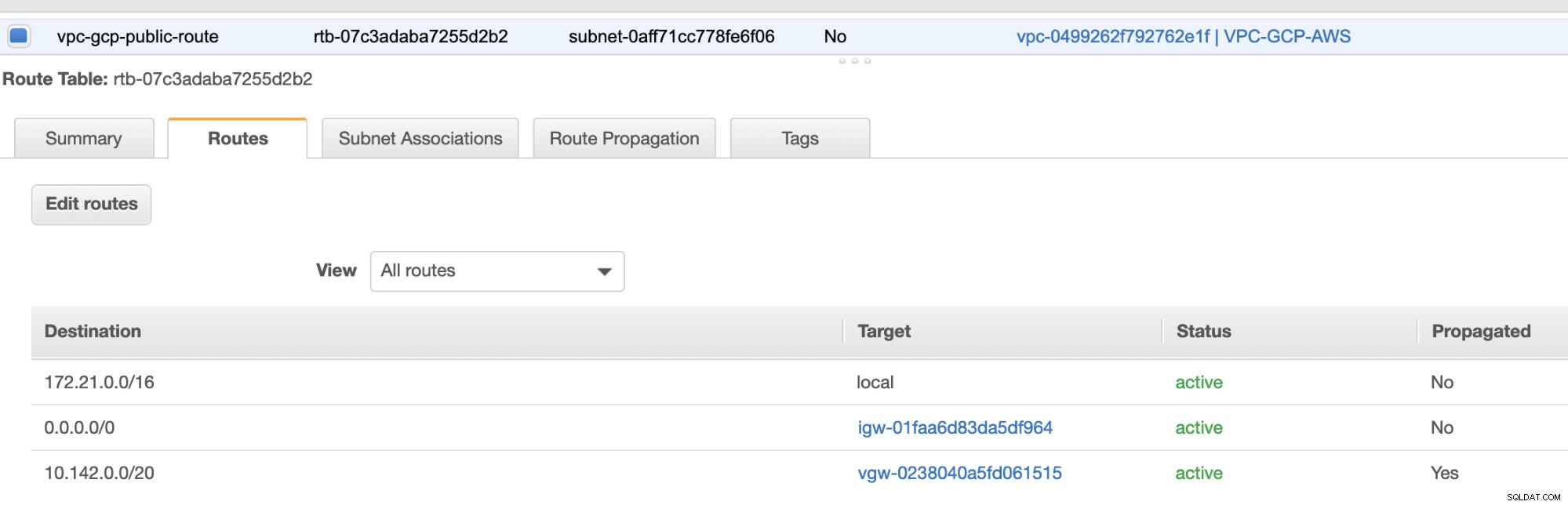
Som du har bemærket, er igw-01faa6d83da5df964 er den internetgateway, som vi har oprettet og bruges af den offentlige rute. Mens den private rutetabel har destination og mål sat til nat-07eb7a54e90dab61f og begge disse har Destination indstillet til 0.0.0.0/0, da det tillader forskellige IPv4-forbindelser. Glem heller ikke at indstille Ruteudbredelse korrekt for den virtuelle gateway som vist på skærmbilledet, som har et mål vgw-0238040a5fd061515 . Bare klik på Ruteudbredelse og indstil den til Ja ligesom på skærmbilledet nedenfor:
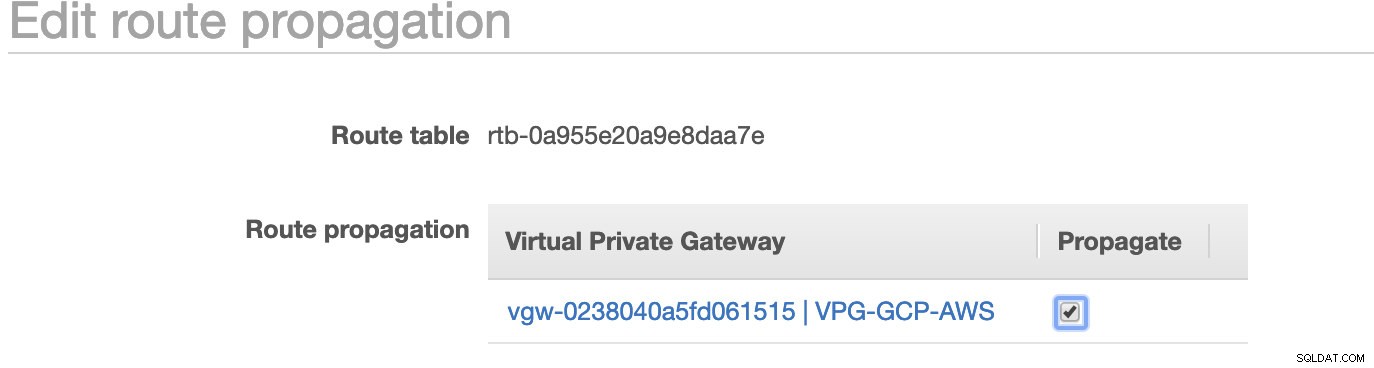
Dette er meget vigtigt, så forbindelsen fra de eksterne GCP-forbindelser vil rute til rutetabellerne i AWS, og der er ikke behov for yderligere manuelt arbejde. Ellers kan din GCP ikke oprette forbindelse til AWS.
Nu hvor vores VPN er oppe, fortsætter vi med at opsætte vores private noder inklusive bastion-værten.
Opsætning af Compute Engine Nodes
Opsætning af Compute Engine/EC2 noderne vil være hurtig og nem, da vi har alle opsætninger på plads. Jeg vil ikke gå ind i disse detaljer, men tjekke skærmbillederne nedenfor, da det forklarer opsætningen.
AWS EC2 noder :

GCP Compute Nodes :
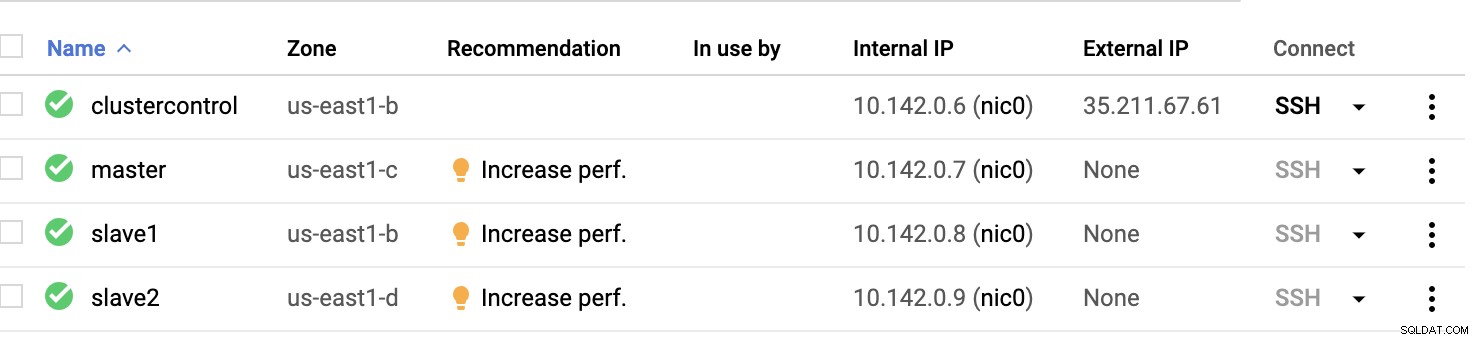
Dybest set på denne opsætning. Værten clustercontrol vil være bastion- eller springværten, og som ClusterControl vil blive installeret for. Det er klart, at alle noderne her ikke er internetadgængelige. De har ingen ekstern IPv4 tildelt, og noder kommunikerer gennem en meget sikker kanal ved hjælp af VPN.
Til sidst er alle disse noder fra AWS til GCP sat op med én ensartet systembruger med sudo-adgang, hvilket er nødvendigt i vores næste afsnit. Se, hvordan ClusterControl kan gøre dit liv lettere, når du er i multicloud og multi-region.
ClusterControl til redning!!!
Håndtering af flere noder og på forskellige offentlige cloud-platforme, plus på en anden "region" kan være en "virkelig-smertefuld-og-afskrækkende" opgave. Hvordan overvåger du det effektivt? ClusterControl fungerer ikke kun som din schweizerkniv, men også som din virtuelle DBA. Lad os nu se, hvordan ClusterControl kan gøre dit liv lettere.
Oprettelse af en klynge med flere replikeringer ved hjælp af ClusterControl
Lad os nu prøve at oprette en MariaDB master-slave-replikeringsklynge efter "Multiple Replication"-topologien.
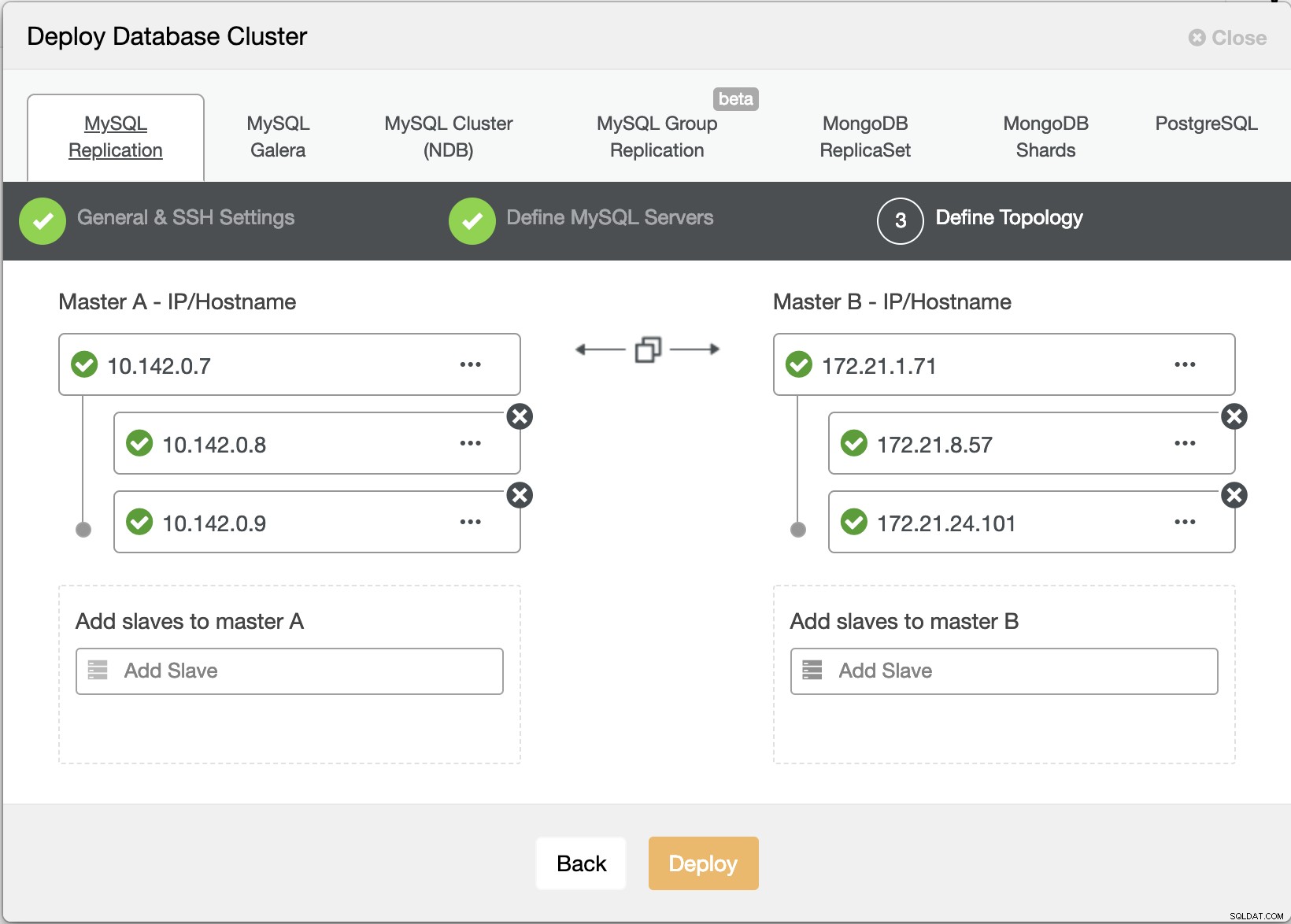 ClusterControl Deploy Wizard
ClusterControl Deploy Wizard Tryk på Deploy knappen installerer pakker og opsætter noderne i overensstemmelse hermed. Derfor et logisk billede af, hvordan topologien ville se ud:
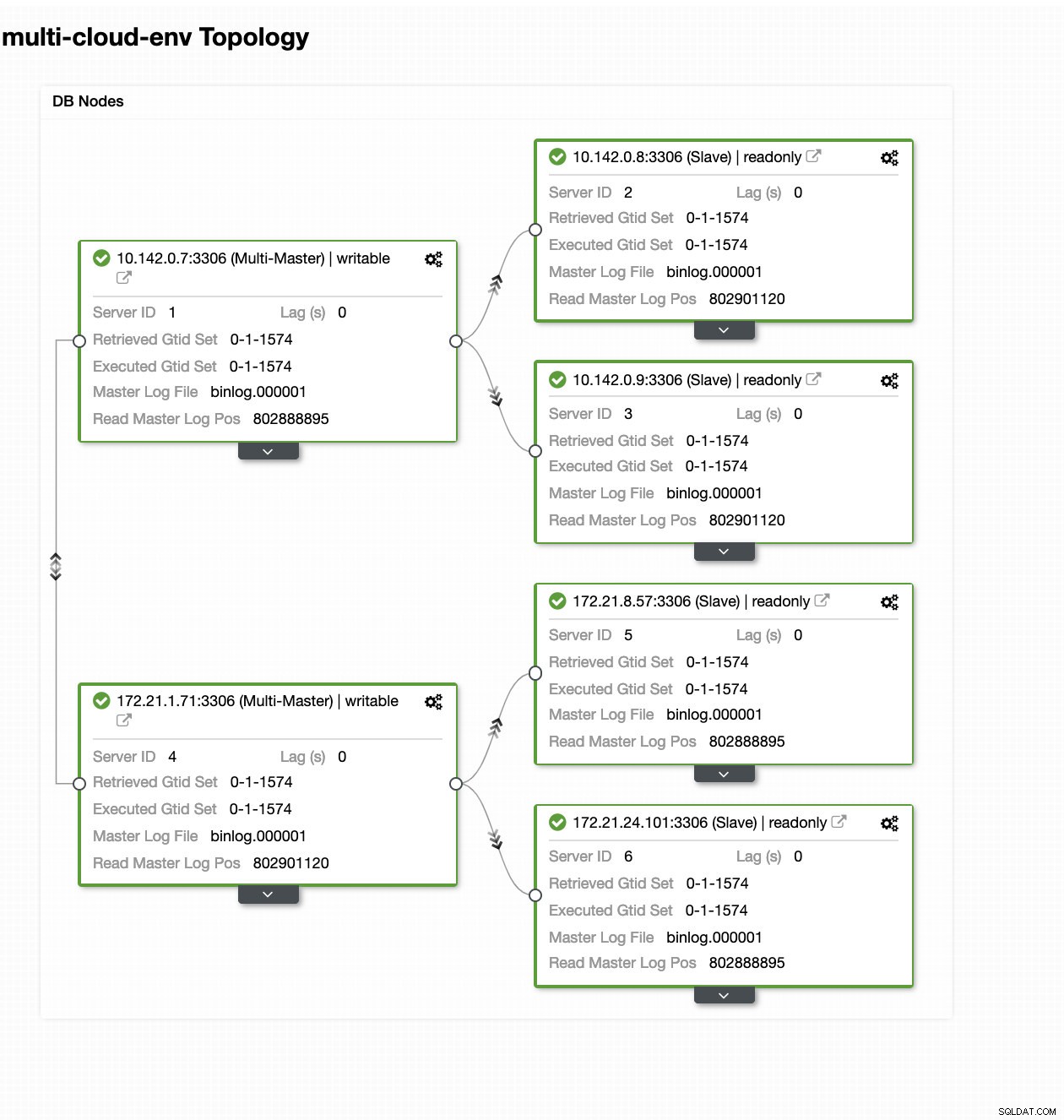 ClusterControl - Topologivisning
ClusterControl - Topologivisning Noderne 172.21.0.0/16 række IP'er replikerer fra sin master, der kører på GCP.
Hvad med at prøve at indlæse nogle skriverier på masteren? Eventuelle problemer med tilslutning eller latenstid kan generere slaveforsinkelse, du vil være i stand til at få øje på dette med ClusterControl. Se skærmbilledet nedenfor:
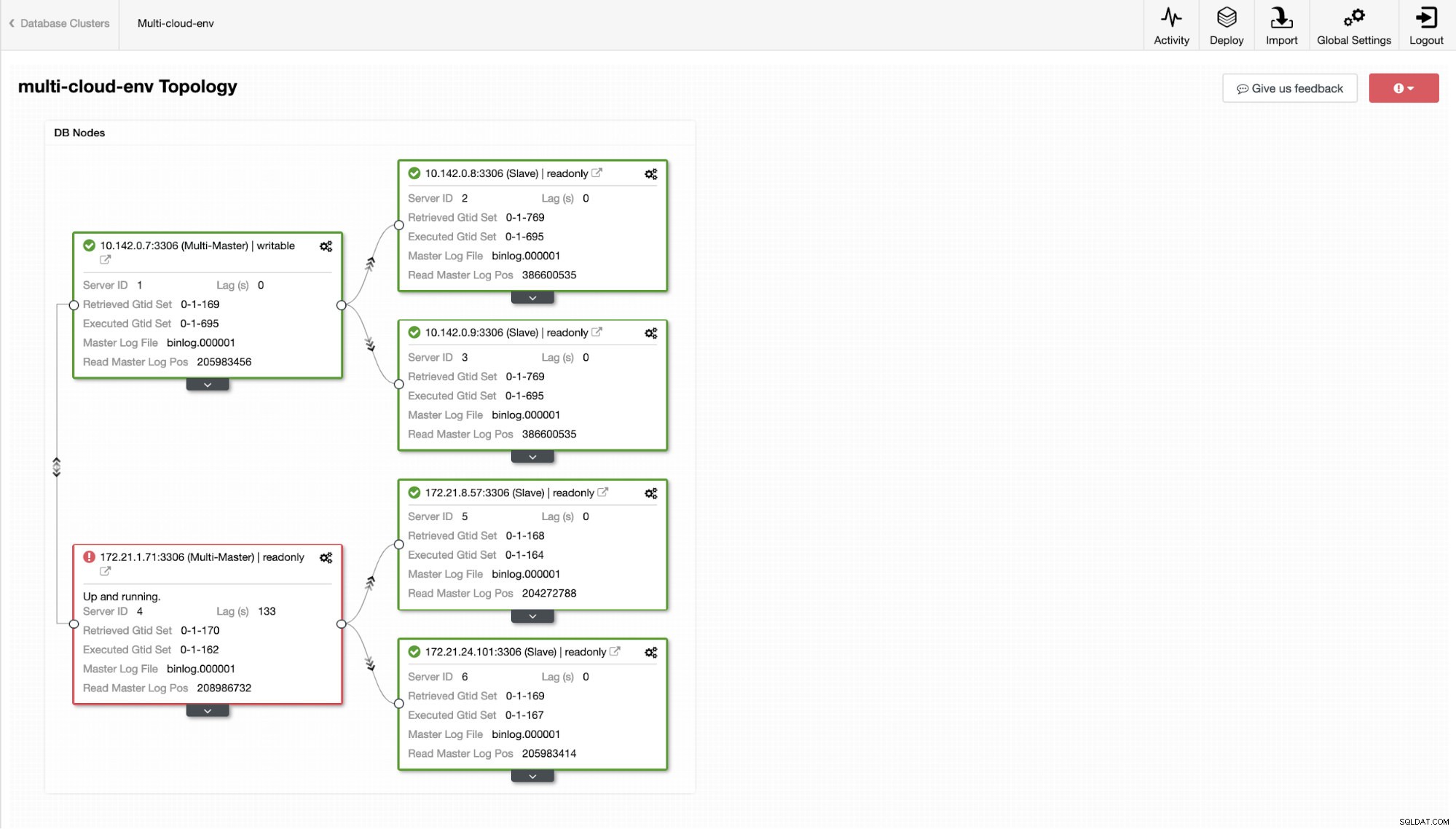
og som du kan se i øverste højre hjørne af skærmbilledet, bliver det rødt, da det indikerer, at der er registreret problemer. Derfor blev der sendt en alarm, mens dette problem er blevet opdaget. Se nedenfor:
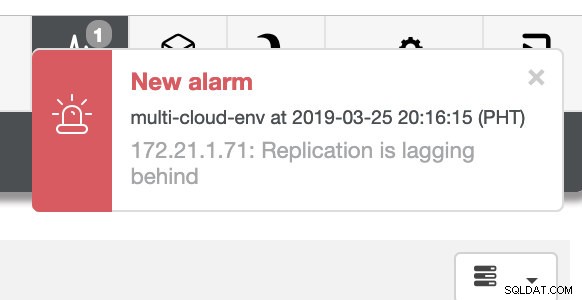
Vi er nødt til at grave i det her. Til finmasket overvågning har vi aktiveret agenter på databaseforekomsterne. Lad os tage et kig på Dashboardet.
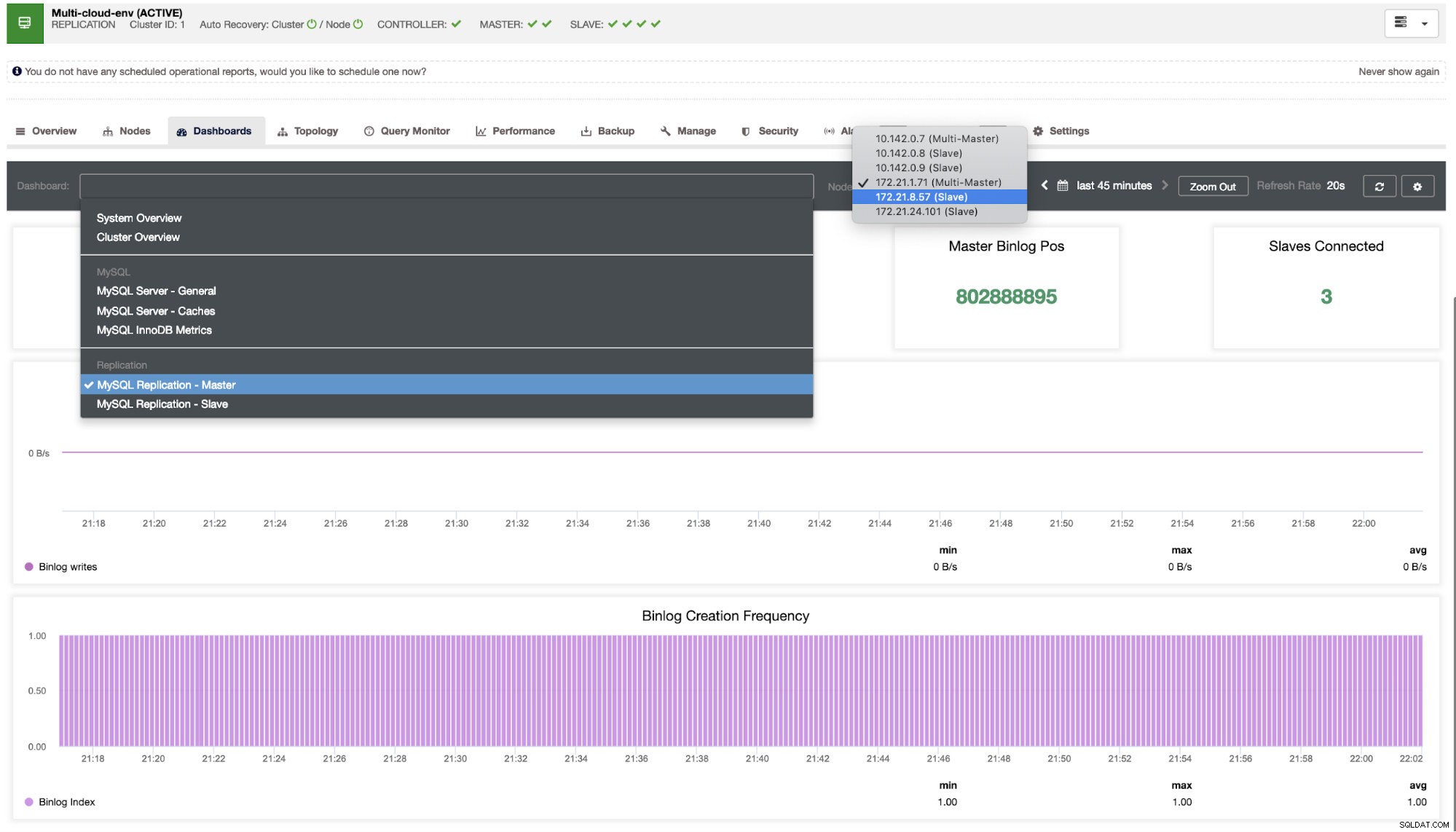
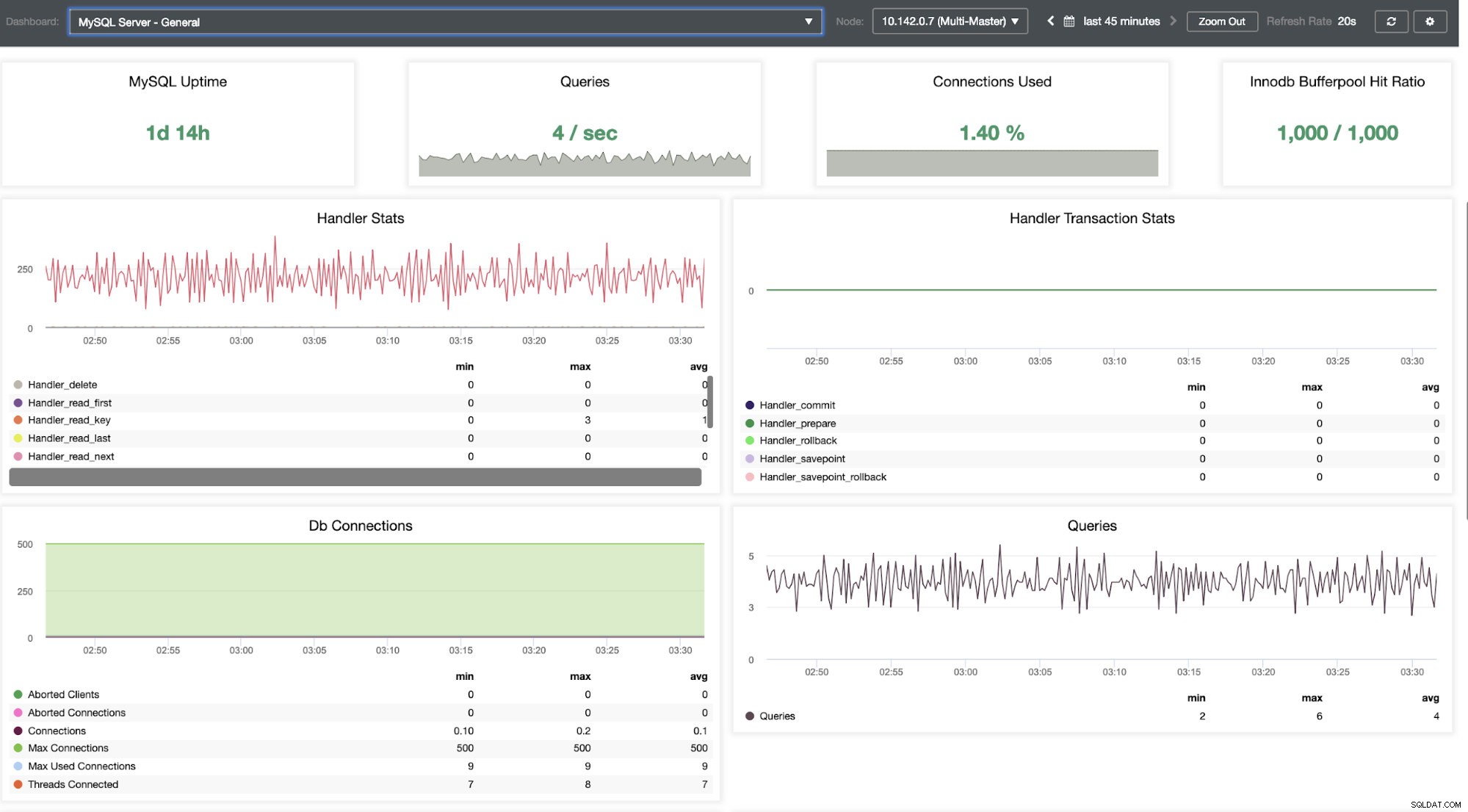
Det giver en super jævn oplevelse med hensyn til at overvåge dine noder.
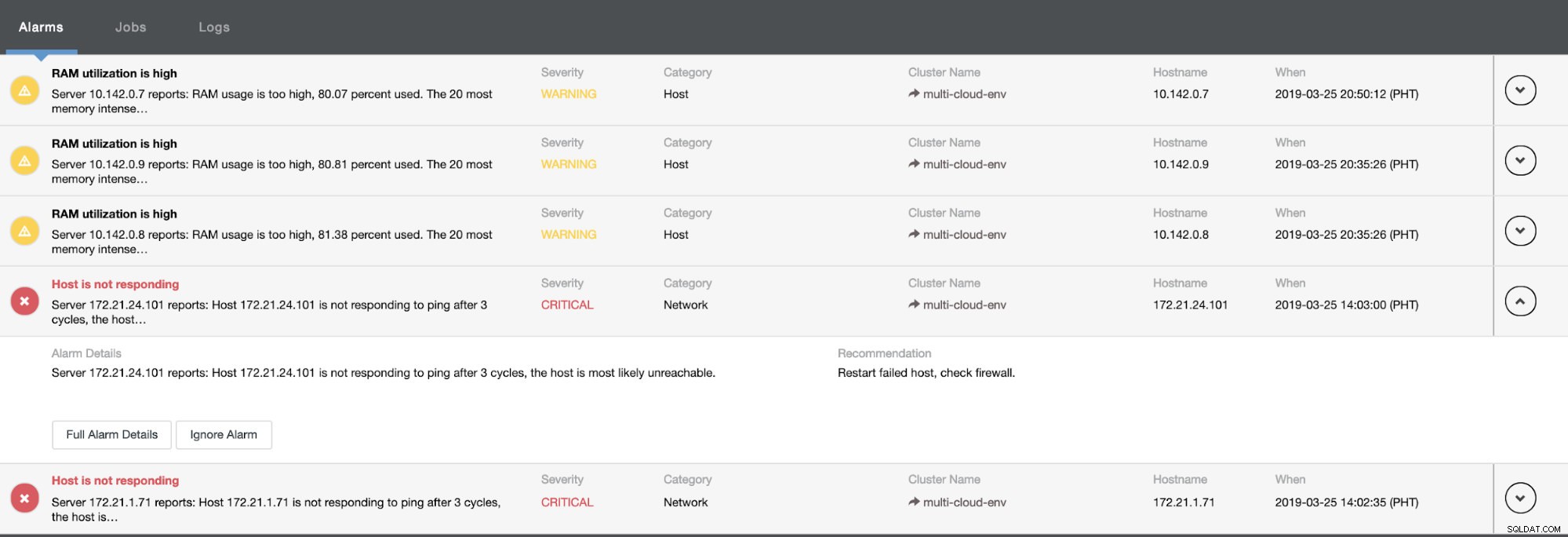
Det fortæller os, at udnyttelsen er høj, eller at værten ikke reagerer. Selvom dette kun var et ping svarfejl, kan du ignorere advarslen for at forhindre dig i at bombardere den. Derfor kan du 'fjerne ignorere' det, hvis det er nødvendigt ved at gå til Cluster -> Alarmer i Clustercontrol. Se nedenfor:
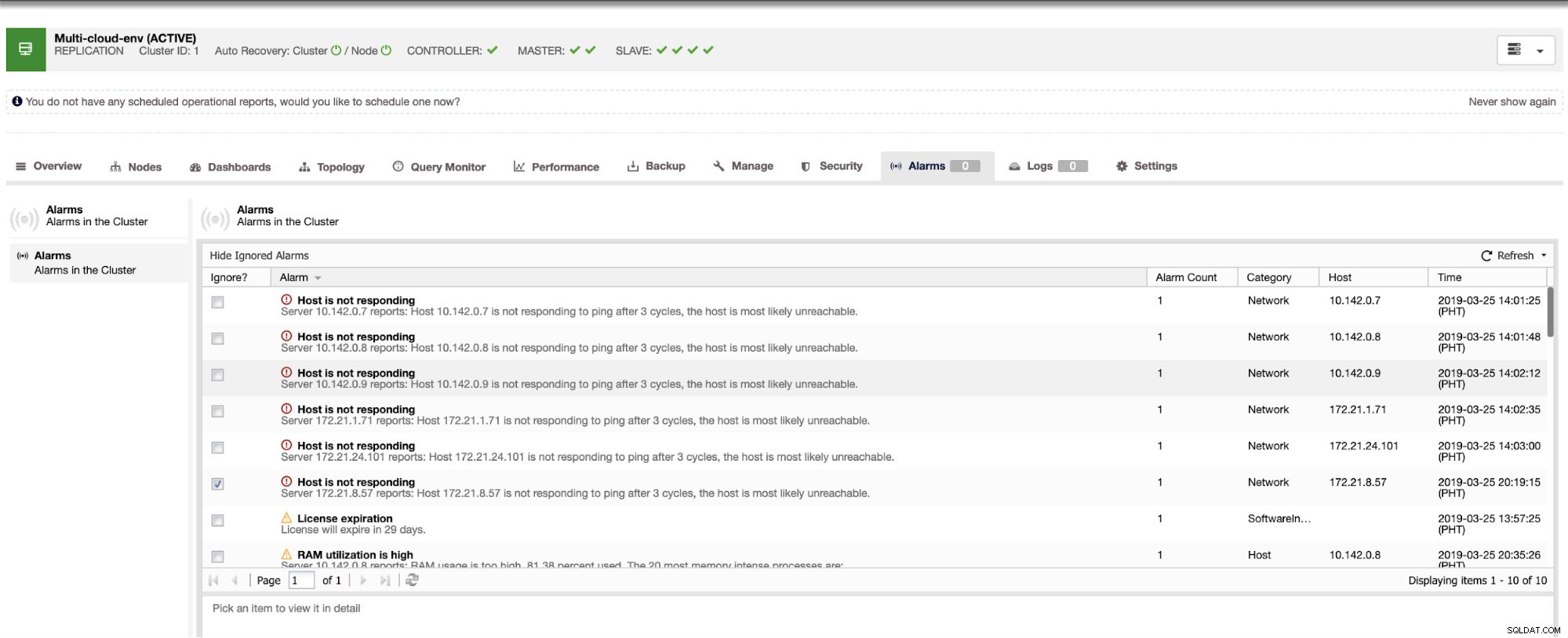
Håndtering af fejl og udførelse af failover
Lad os sige, at us-east1-masternoden fejlede eller kræver en større revision på grund af system- eller hardwareopgradering. Lad os sige, at dette er topologien lige nu (se billedet nedenfor):
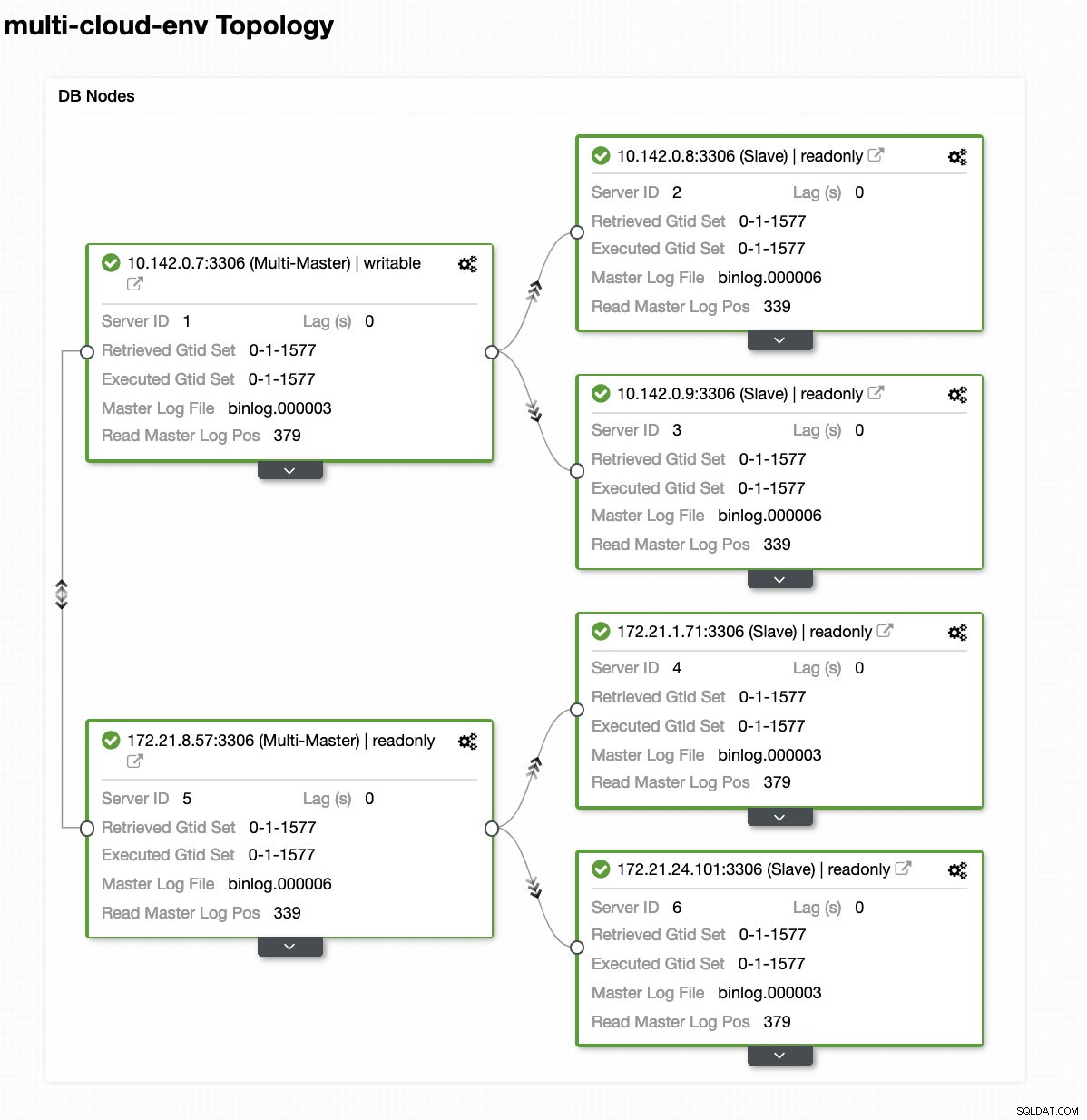
Lad os prøve at lukke vært 10.142.0.7, som er master under regionen us-east1. Se skærmbillederne nedenfor, hvordan ClusterControl reagerer på dette:
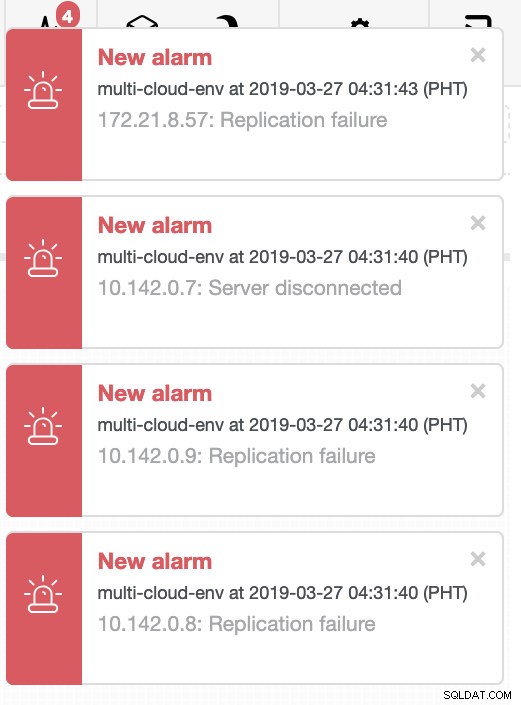
ClusterControl sender alarmer, når den registrerer uregelmæssigheder i klyngen. Derefter forsøger den at lave en failover til en ny master ved at vælge den rigtige kandidat (se billedet nedenfor):

Derefter tilsidesatte den den mislykkede master, som allerede er taget ud af klyngen (se billedet nedenfor):
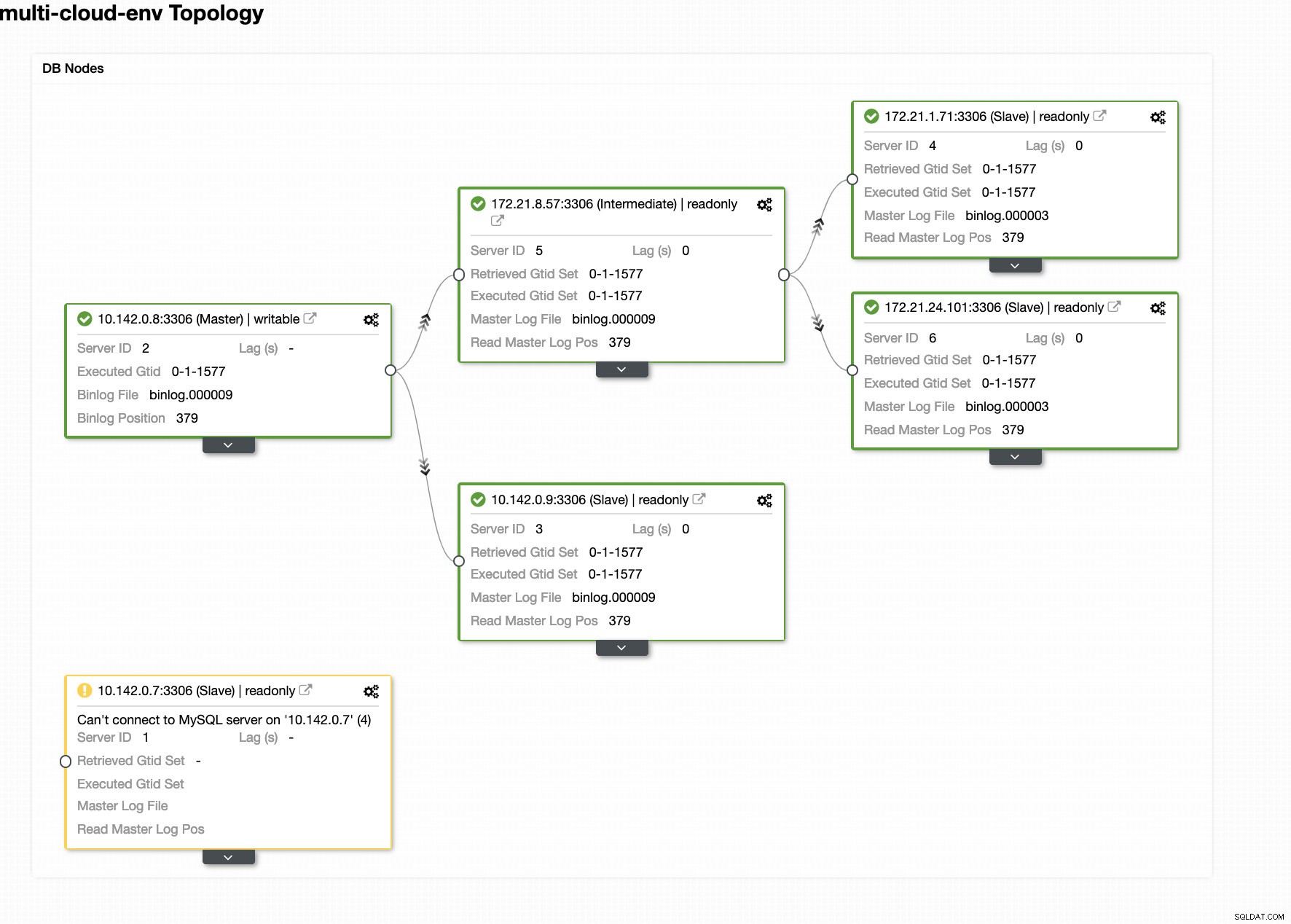
Dette er blot et glimt af, hvad ClusterControl kan gøre, der er andre fantastiske funktioner såsom sikkerhedskopiering, forespørgselsovervågning, implementering/administration af belastningsbalancere og mange flere!
Konklusion
Det kan være vanskeligt at administrere din MySQL-replikeringsopsætning i en multicloud. Der skal udvises stor omhu for at sikre vores opsætning, så forhåbentlig giver denne blog en idé om, hvordan man definerer undernet og beskytter databasenoderne. Efter sikkerhed er der en række ting at administrere, og det er her, ClusterControl kan være meget nyttigt.
Prøv det nu og lad os vide, hvordan det går. Du kan til enhver tid kontakte os her.