I dette blogindlæg vil vi analysere 6 forskellige fejlscenarier i produktionsdatabasesystemer, lige fra enkeltserverproblemer til multi-datacenter failover-planer. Vi vil lede dig gennem gendannelses- og failover-procedurer for det respektive scenarie. Forhåbentlig vil dette give dig en god forståelse af de risici, du kan stå over for, og ting du skal overveje, når du designer din infrastruktur.
Databaseskema beskadiget
Lad os starte med installation af enkelt node - en databaseopsætning i den enkleste form. Nem at implementere, til den laveste pris. I dette scenarie kører du flere applikationer på den enkelte server, hvor hvert af databaseskemaerne tilhører den forskellige applikation. Fremgangsmåden til gendannelse af et enkelt skema vil afhænge af flere faktorer.
- Har jeg nogen sikkerhedskopi?
- Har jeg en sikkerhedskopi, og hvor hurtigt kan jeg gendanne den?
- Hvilken slags lagermotor er i brug?
- Har jeg en PITR-kompatibel (point in time recovery) backup?
Datakorruption kan identificeres af mysqlcheck.
mysqlcheck -uroot -p Erstat DATABASE med navnet på databasen, og erstat TABLE med navnet på den tabel, du vil kontrollere:
mysqlcheck -uroot -p
Mysqlcheck kontrollerer den angivne database og tabeller. Hvis en tabel består kontrollen, viser mysqlcheck OK for tabellen. I eksemplet nedenfor kan vi se, at tabellen løn kræver gendannelse.
employees.departments OKemployees.dept_emp OKemployees.dept_manager OKemployees.employees OKemployees.salariesAdvarsel:Tablespace mangler for tabellen 'employees/salaris'Fejl:Tabel 'employees.salarys' eksisterer ikke i enginestatus:Employees. titler OK
For en enkelt nodeinstallation uden yderligere DR-servere ville den primære tilgang være at gendanne data fra backup. Men dette er ikke det eneste, du skal overveje. At have flere databaseskemaer under samme instans forårsager et problem, når du skal bringe din server ned for at gendanne data. Et andet spørgsmål er, om du har råd til at rulle alle dine databaser tilbage til den sidste backup. I de fleste tilfælde ville det ikke være muligt.
Der er nogle undtagelser her. Det er muligt at gendanne en enkelt tabel eller database fra den sidste sikkerhedskopi, når der ikke er behov for gendannelse af tidspunkter. En sådan proces er mere kompliceret. Hvis du har mysqldump, kan du udtrække din database fra den. Hvis du kører binære sikkerhedskopier med xtradbackup eller mariabackup, og du har aktiveret tabel pr. fil, så er det muligt.
Her er, hvordan du kontrollerer, om du har aktiveret en tabel pr. fil.
mysql> SET GLOBAL innodb_file_per_table=1;
Med innodb_file_per_table aktiveret, kan du gemme InnoDB-tabeller i en tbl_name .ibd-fil. I modsætning til MyISAM-lagringsmotoren, med dens separate tbl_name .MYD- og tbl_name .MYI-filer til indekser og data, gemmer InnoDB dataene og indekserne sammen i en enkelt .ibd-fil. For at tjekke din lagermotor skal du køre:
mysql> vælg table_name, engine fra information_schema.tables, hvor table_name='table_name' og table_schema='database_name';
eller direkte fra konsollen:
[eksempel@sqldat.com ~]# mysql -u -p -D -e "vis tabelstatus\G"Indtast adgangskode:********** ****************** 1. række *************************** Navn:test1 Motor:InnoDB Version:10 Row_format:Dynamic Rows:12 Avg_row_length:1365 Data_length:16384Max_data_length:0 Index_length:0 Data_free:0 Auto_increment:NULL Create_time:2018-07_time:2018-07_5_time:NULL_time:NULL_time:NULL_1 Kontrolsum:NULL Create_options:Kommentar:
For at gendanne tabeller fra xtradbackup skal du igennem en eksportproces. Sikkerhedskopiering skal forberedes, før den kan gendannes. Eksporten sker i forberedelsesfasen. Når en fuld sikkerhedskopi er oprettet, skal du køre standard forberedelsesprocedure med det ekstra flag --export :
innobackupex --apply-log --export /u01/backup
Dette vil oprette yderligere eksportfiler, som du vil bruge senere i importfasen. For at importere en tabel til en anden server skal du først oprette en ny tabel med samme struktur som den, der vil blive importeret på den server:
mysql> CREATE TABLE corrupted_table (...) ENGINE=InnoDB;
kasser tablespacet:
mysql> ÆNDRINGSTABEL mydatabase.mytable KASSER TABELPLADS;
Kopier derefter filerne mytable.ibd og mytable.exp til databasens hjem, og importer dens tablespace:
mysql> ÆNDRINGSTABEL mydatabase.mytable IMPORTER TABLESPACE;
Men for at gøre dette på en mere kontrolleret måde, vil anbefalingen være at gendanne en database backup i en anden instans/server og kopiere det nødvendige tilbage til hovedsystemet. For at gøre det skal du køre installationen af mysql-forekomsten. Dette kunne gøres enten på den samme maskine - men det kræver en større indsats at konfigurere på en måde, så begge instanser kan køre på den samme maskine - for eksempel ville det kræve forskellige kommunikationsindstillinger.
Du kan kombinere både opgavegendannelse og installation ved hjælp af ClusterControl.
ClusterControl vil lede dig gennem de tilgængelige sikkerhedskopier on-prem eller i skyen, lader dig vælge det nøjagtige tidspunkt for en gendannelse eller den præcise logposition og installere en ny databaseinstans, hvis det er nødvendigt.
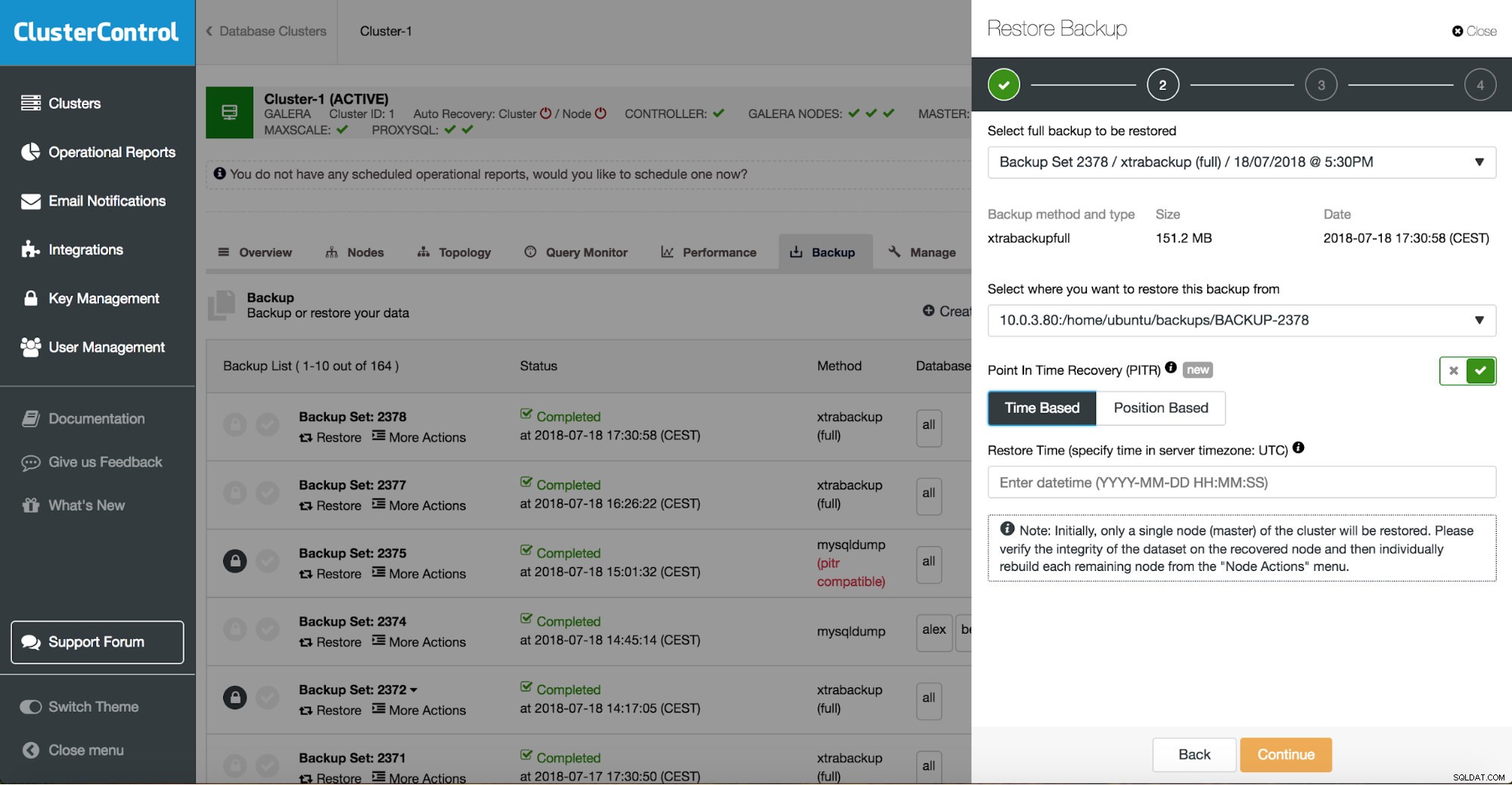 ClusterControl-tidspunktgendannelse
ClusterControl-tidspunktgendannelse 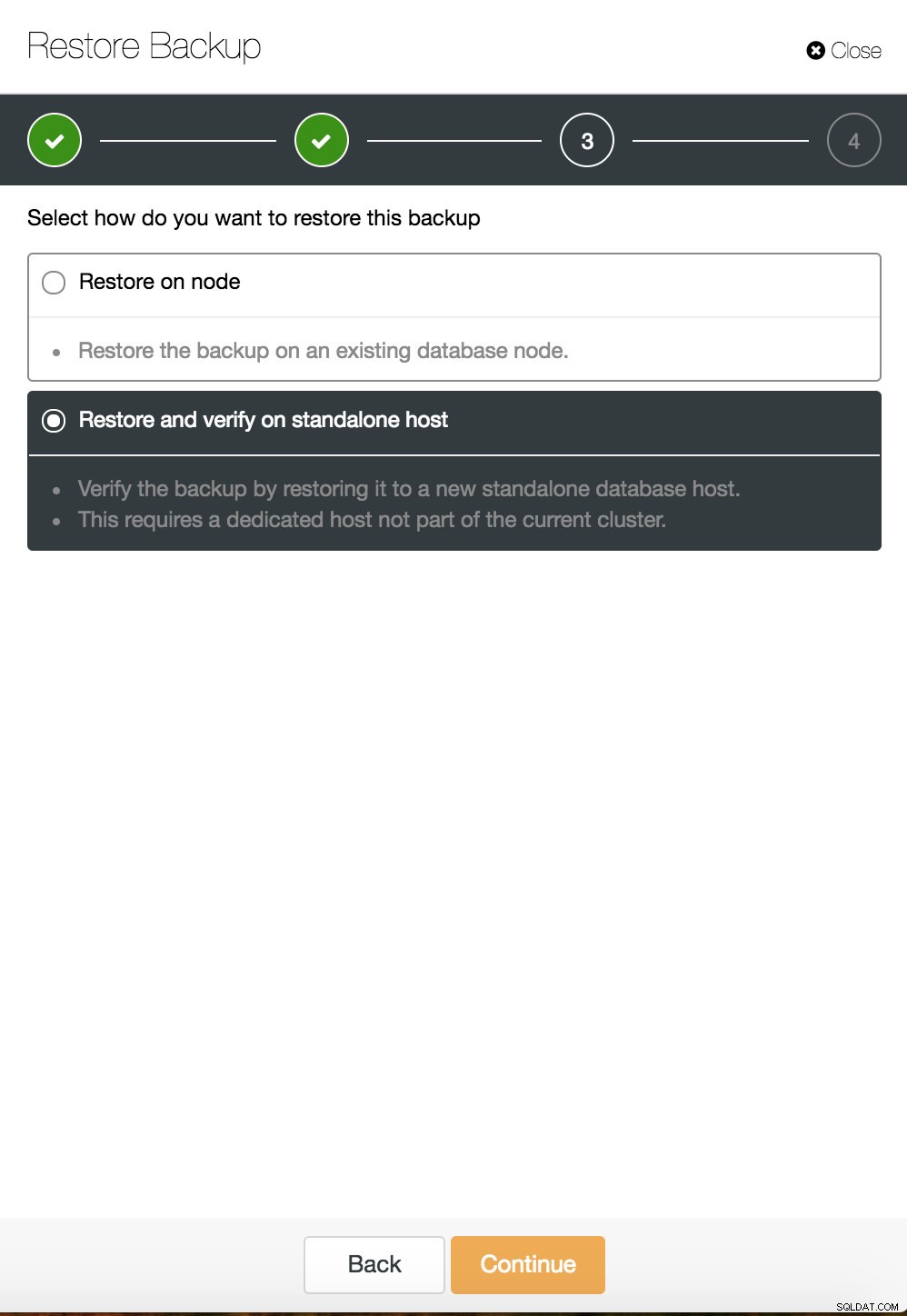 ClusterControl gendan og verificere på en selvstændig vært
ClusterControl gendan og verificere på en selvstændig vært 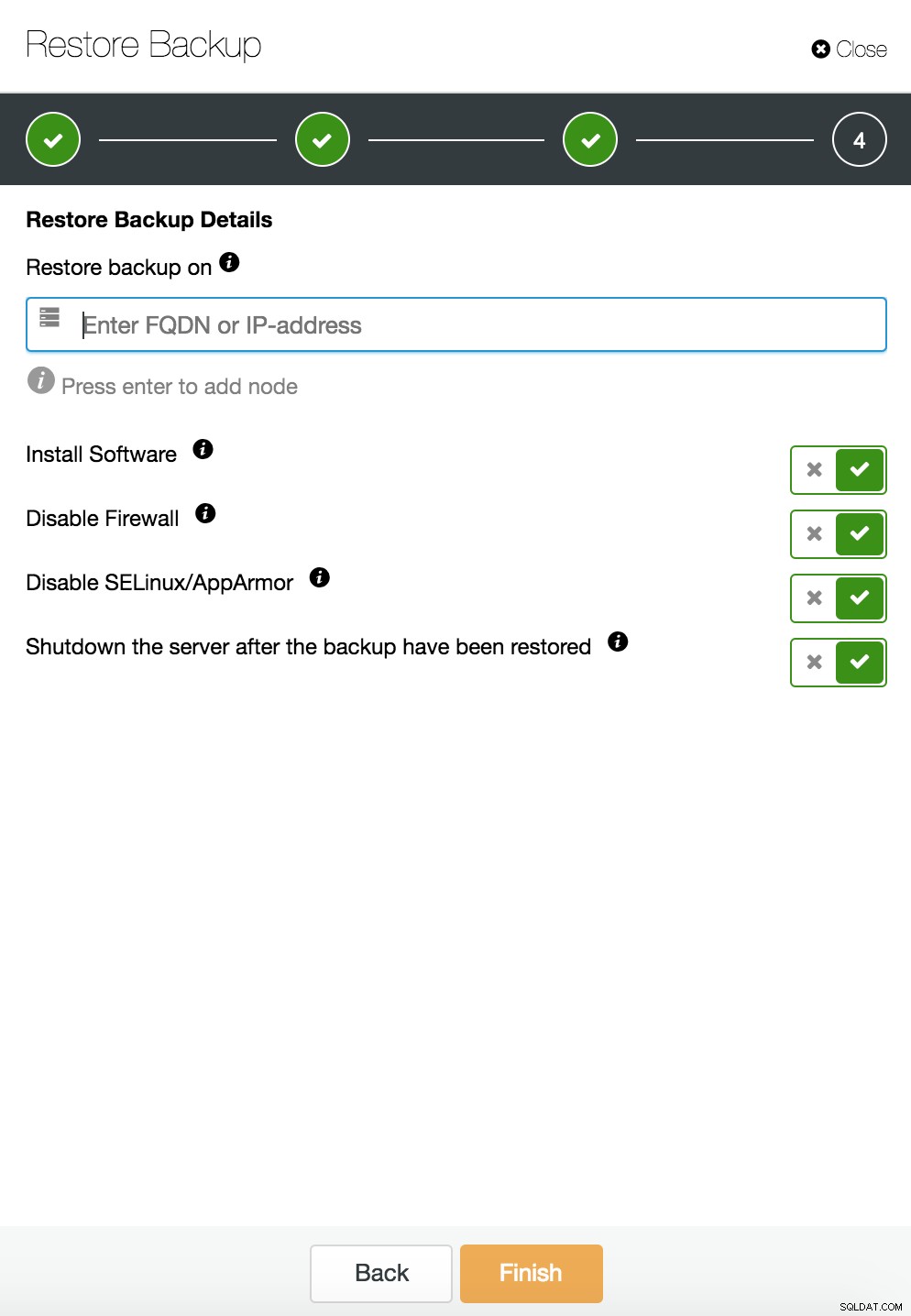 CusterControl gendan og verificere på en selvstændig vært. Installationsmuligheder.
CusterControl gendan og verificere på en selvstændig vært. Installationsmuligheder.
Du kan finde flere oplysninger om datagendannelse i bloggen Min MySQL-database er beskadiget... Hvad gør jeg nu?
Databaseforekomst beskadiget på den dedikerede server
Defekter i den underliggende platform er ofte årsagen til databasekorruption. Din MySQL-instans er afhængig af en række ting til at gemme og hente data - diskundersystem, controllere, kommunikationskanaler, drivere og firmware. Et nedbrud kan påvirke dele af dine data, mysql-binære filer eller endda backup-filer, som du gemmer på systemet. For at adskille forskellige applikationer kan du placere dem på dedikerede servere.
Forskellige applikationsskemaer på separate systemer er en god idé, hvis du har råd til dem. Man kan sige, at det er spild af ressourcer, men der er en chance for, at forretningspåvirkningen bliver mindre, hvis kun én af dem går ned. Men selv da skal du beskytte din database mod tab af data. At gemme backup på den samme server er ikke en dårlig idé, så længe du har en kopi et andet sted. I disse dage er cloud storage et glimrende alternativ til tape backup.
ClusterControl giver dig mulighed for at opbevare en kopi af din backup i skyen. Det understøtter upload til de 3 bedste cloud-udbydere - Amazon AWS, Google Cloud og Microsoft Azure.
Når du har gendannet din fulde sikkerhedskopi, vil du måske gerne gendanne den til et bestemt tidspunkt. Point-in-time gendannelse vil bringe serveren opdateret til et nyere tidspunkt, end da den fulde backup blev taget. For at gøre det skal du have dine binære logfiler aktiveret. Du kan tjekke tilgængelige binære logfiler med:
mysql> VIS BINÆRE LOGS;
Og aktuel logfil med:
VIS MASTERSTATUS;
Derefter kan du fange inkrementelle data ved at overføre binære logfiler til sql-fil. Manglende handlinger kan derefter udføres igen.
mysqlbinlog --start-position='14231131' --verbose /var/lib/mysql/binlog.000010 /var/lib/mysql/binlog.000011 /var/lib/mysql/binlog.000012 / var/lib/mysql/binlog.000013 /var/lib/mysql/binlog.000015> binlog.out
Det samme kan gøres i ClusterControl.
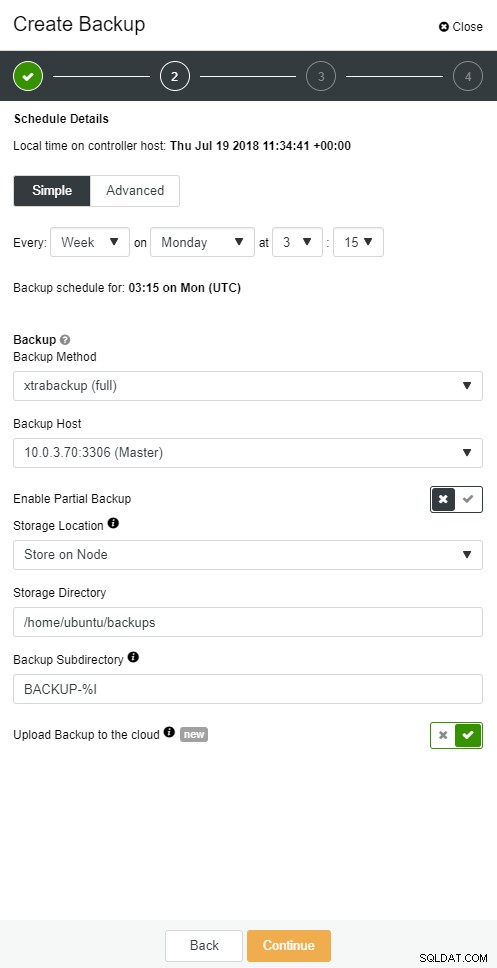 ClusterControl cloud backup
ClusterControl cloud backup 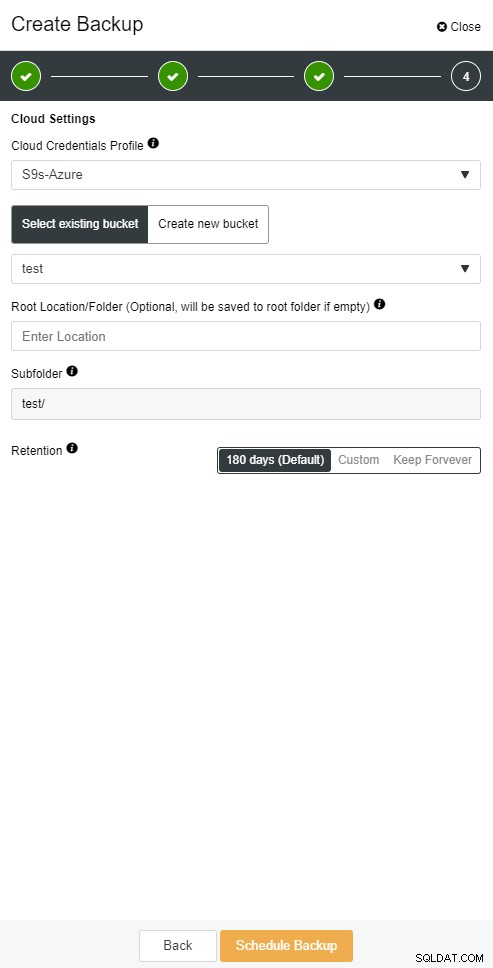 ClusterControl cloud backup
ClusterControl cloud backup Databaseslave går ned
Ok, så du har din database kørende på en dedikeret server. Du har oprettet en sofistikeret sikkerhedskopieringsplan med en kombination af fulde og trinvise sikkerhedskopier, uploader dem til skyen og gemmer den seneste sikkerhedskopiering på lokale diske for hurtig gendannelse. Du har forskellige politikker til opbevaring af sikkerhedskopier - kortere for sikkerhedskopier, der er gemt på lokale diskdrivere og udvidet til dine sikkerhedskopier i skyen.
Det lyder som om du er godt forberedt på et katastrofescenarie. Men når det kommer til gendannelsestiden, opfylder den muligvis ikke din virksomheds behov.
Du har brug for en hurtig failover-funktion. En server, der vil være oppe og køre ved at anvende binære logfiler fra masteren, hvor skrivning sker. Master/Slave-replikering starter et nyt kapitel i failover-scenariet. Det er en hurtig metode til at bringe din applikation tilbage til live, hvis du mestrer går ned.
Men der er få ting at overveje i failover-scenariet. Den ene er at opsætte en forsinket replikeringsslave, så du kan reagere på fede fingerkommandoer, der blev udløst på masterserveren. En slaveserver kan halte bagud masteren med mindst en specificeret tid. Standardforsinkelsen er 0 sekunder. Brug indstillingen MASTER_DELAY for SKIFT MASTER TIL for at indstille forsinkelsen til N sekunder:
SKIFT MASTER TIL MASTER_DELAY =N;
For det andet er at aktivere automatiseret failover. Der er mange automatiserede failover-løsninger på markedet. Du kan konfigurere automatisk failover med kommandolinjeværktøjer som MHA, MRM, mysqlfailover eller GUI Orchestrator og ClusterControl. Når det er konfigureret korrekt, kan det reducere dit udfald betydeligt.
ClusterControl understøtter automatiseret failover for MySQL-, PostgreSQL- og MongoDB-replikeringer samt multi-master klyngeløsninger Galera og NDB.
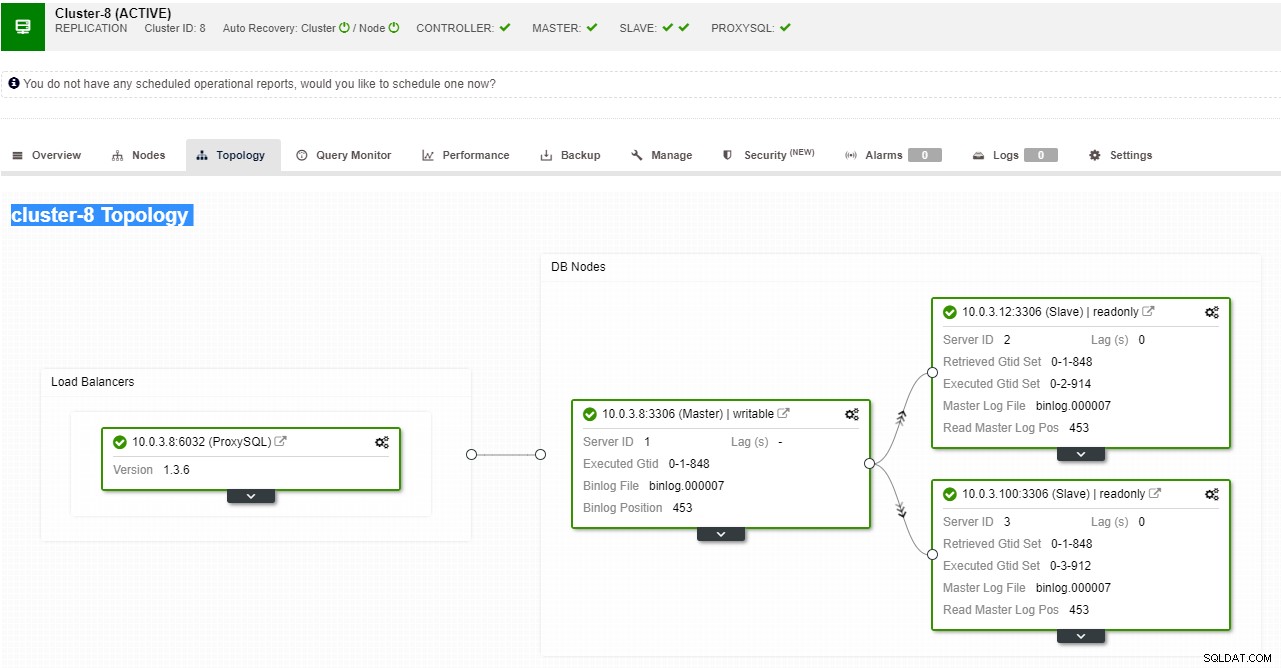 ClusterControl replikeringstopologivisning
ClusterControl replikeringstopologivisning
Når en slaveknude går ned, og serveren halter alvorligt bagud, vil du måske genopbygge din slaveserver. Slave-genopbygningsprocessen ligner gendannelse fra backup.
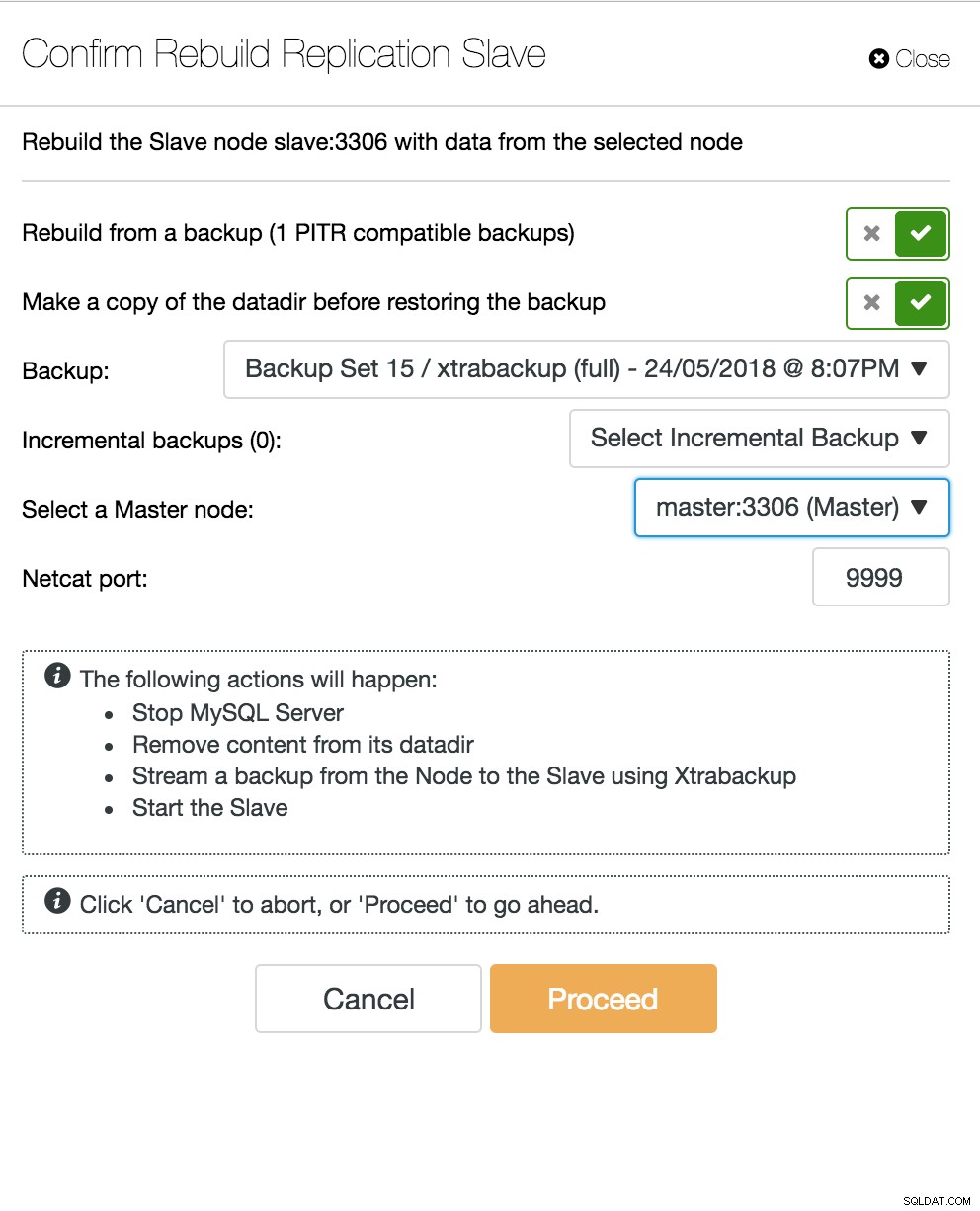 ClusterControl genopbygge slave
ClusterControl genopbygge slave Database Multi-Master Server går ned
Nu når du har slaveserver, der fungerer som en DR-node, og din failover-proces er velautomatiseret og testet, bliver dit DBA-liv mere behageligt. Det er rigtigt, men der er et par gåder mere at løse. Computerkraft er ikke gratis, og dit virksomhedsteam kan bede dig om at bruge din hardware bedre. Du vil måske bruge din slaveserver ikke kun som passiv server, men også til at betjene skriveoperationer.
Du vil måske derefter undersøge en multi-master replikeringsløsning. Galera Cluster er blevet en almindelig mulighed for MySQL og MariaDB med høj tilgængelighed. Og selvom det nu er kendt som en troværdig erstatning for traditionelle MySQL master-slave arkitekturer, er det ikke en drop-in erstatning.
Galera-klyngen har en delt ingenting-arkitektur. I stedet for delte diske bruger Galera certificeringsbaseret replikering med gruppekommunikation og transaktionsbestilling for at opnå synkron replikering. En databaseklynge bør kunne overleve et tab af en node, selvom det opnås på forskellige måder. I tilfælde af Galera er det kritiske aspekt antallet af noder. Galera kræver et kvorum for at forblive operationelt. En klynge med tre knudepunkter kan overleve sammenbruddet af en knude. Med flere noder i din klynge kan du overleve flere fejl.
Gendannelsesprocessen er automatiseret, så du ikke behøver at udføre nogen failover-operationer. Men den gode praksis ville være at dræbe noder og se, hvor hurtigt du kan bringe dem tilbage. For at gøre denne operation mere effektiv kan du ændre størrelsen på galera-cachen. Hvis galera-cachestørrelsen ikke er korrekt planlagt, skal din næste opstartsknude tage en fuld backup i stedet for kun at mangle skrivesæt i cachen.
Failover-scenariet er simpelt som at starte forekomsten. Baseret på dataene i galera-cachen vil opstartsknuden udføre SST (gendan fra fuld backup) eller IST (anvend manglende skrivesæt). Dette er dog ofte forbundet med menneskelig indgriben. Hvis du vil automatisere hele failover-processen, kan du bruge ClusterControls autorecovery-funktionalitet (node- og klyngeniveau).
 ClusterControl cluster autorecovery
ClusterControl cluster autorecovery
Estimer galera cache størrelse:
MariaDB [(ingen)]> SET @start :=(SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); sove (60); SET @end :=(SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME SOM 'WSREP%bytes'); SET @gcache :=(SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size =',-1), 'M', 1)); VÆLG ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 som `MB/time`, @gcache som `gcache Size(MB) `, ROUND(@gcache/round((@end - @start),2),2) som `Tid til fuld(minutter)`;
For at gøre failover mere konsekvent bør du aktivere gcache.recover=yes i mycnf. Denne mulighed vil genoplive galera-cachen ved genstart. Dette betyder, at noden kan fungere som DONOR og servicere manglende skrivesæt (faciliterer IST i stedet for at bruge SST).
2018-07-20 8:59:44 139656049956608 [Bemærk] WSREP:Kvorumsresultater:version =4, komponent =PRIMÆR, conf_id =2, medlemmer =2/3 (sammensluttet/total), act_id =12810, sidste_appl. =0, protokoller =0/7/3 (gcs/repl/appl), gruppe UUID =49eca8f8-0e3a-11e8-be4a-e7e3fe48cb692018-07-20 8:59:44 139656049956608EP [:Note interval]SR:Note interval [28, 28]2018-07-20 8:59:44 139656049956608 [Bemærk] WSREP:Forsøger at fortsætte uafbrudt monitor2018-07-20 8:59:44 139657311033088:Ny tilstand:8f-4 cluster WSREP:Ny tilstand:8f 0e3a-11e8-be4a-e7e3fe48cb69:12810, visning # 3:Primær, antal noder:3, mit indeks:1, protokol version 3
Proxy SQL node går ned
Hvis du har en virtuel IP-opsætning, skal du blot pege din ansøgning til den virtuelle IP-adresse, og alt skal være korrekt forbindelsesmæssigt. Det er ikke nok at have dine databaseforekomster på tværs af flere datacentre, du har stadig brug for dine applikationer for at få adgang til dem. Antag, at du har skaleret antallet af læste replikaer ud, vil du måske også implementere virtuelle IP'er for hver af disse læste replikaer på grund af vedligeholdelses- eller tilgængelighedsårsager. Det kan blive en besværlig pulje af virtuelle IP'er, som du skal administrere. Hvis en af disse læste replikaer står over for et nedbrud, skal du gentildele den virtuelle IP til den anden vært, ellers vil din applikation oprette forbindelse til enten en vært, der er nede, eller i værste fald en server med forældede data.
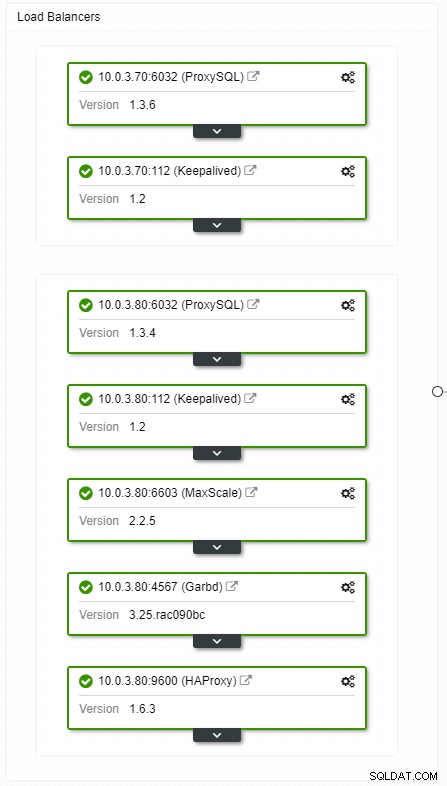 ClusterControl HA load balancers topologivisning
ClusterControl HA load balancers topologivisning
Nedbrud er ikke hyppige, men mere sandsynlige end servere, der går ned. Hvis en slave af en eller anden grund går ned, vil noget som ProxySQL omdirigere al trafikken til masteren med risiko for at overbelaste den. Når slaven kommer sig, vil trafikken blive omdirigeret tilbage til den. Normalt bør en sådan nedetid ikke tage mere end et par minutter, så den samlede sværhedsgrad er medium, selvom sandsynligheden også er medium.
For at få dine load balancer-komponenter overflødige, kan du bruge keepalived.
 ClusterControl:Implementer keepalived for ProxySQL load balancer
ClusterControl:Implementer keepalived for ProxySQL load balancer Datacenter går ned
Hovedproblemet med replikering er, at der ikke er nogen majoritetsmekanisme til at opdage en datacenterfejl og betjene en ny master. En af beslutningerne er at bruge Orchestrator/Raft. Orchestrator er en topologisupervisor, der kan kontrollere failovers. Når det bruges sammen med Raft, vil Orchestrator blive kvorumsbevidst. En af Orchestrator-instanserne vælges som leder og udfører gendannelsesopgaver. Forbindelsen mellem orkestratorknudepunktet korrelerer ikke med transaktionsdatabase-commits og er sparsom.
Orchestrator/Raft kan bruge ekstra instanser, som udfører overvågning af topologien. I tilfælde af netværkspartitionering vil de partitionerede Orchestrator-instanser ikke foretage sig nogen handling. Den del af Orchestrator-klyngen, som har kvorum, vil vælge en ny mester og foretage de nødvendige topologiændringer.
ClusterControl bruges til administration, skalering og, hvad der er vigtigst, nodegendannelse - Orchestrator ville håndtere failovers, men hvis en slave ville gå ned, vil ClusterControl sørge for, at den bliver gendannet. Orchestrator og ClusterControl vil være placeret i den samme tilgængelighedszone, adskilt fra MySQL-noderne, for at sikre, at deres aktivitet ikke bliver påvirket af netværksdelinger mellem tilgængelighedszoner i datacentret.
Sådan opsætter du asynkron replikering mellem MySQL Galera-klynger
HA for MySQL og MariaDB - Sammenligning af Master-Master-replikering med Galera Cluster