Galera-replikering er relativt ny sammenlignet med MySQL-replikering, som er indbygget understøttet siden MySQL v3.23. Selvom MySQL-replikering er designet til master-slave envejsreplikering, kan den konfigureres som en aktiv master-master-opsætning med tovejsreplikering. Selvom det er nemt at sætte op, og nogle use cases kan drage fordel af dette "hack", er der en række forbehold. På den anden side er Galera cluster en anden type teknologi at lære og administrere. Er det det værd?
I dette blogindlæg skal vi sammenligne master-master replikering med Galera cluster.
Replikeringskoncepter
Før vi hopper ind i sammenligningen, lad os forklare de grundlæggende begreber bag disse to replikeringsmekanismer.
Generelt genererer enhver ændring af MySQL-databasen en hændelse i binært format. Denne hændelse transporteres til de andre noder afhængigt af den valgte replikeringsmetode - MySQL-replikering (native) eller Galera-replikering (patchet med wsrep API).
MySQL-replikering
Følgende diagrammer illustrerer datastrømmen for en vellykket transaktion fra en node til en anden, når du bruger MySQL-replikering:
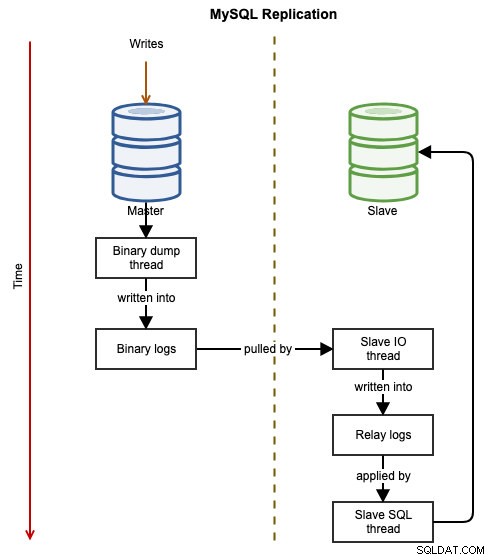
Den binære hændelse skrives ind i masterens binære log. Slaven/slaverne via slave_IO_thread vil trække de binære hændelser fra masterens binære log og replikere dem til dens relælog. slave_SQL_tråden vil derefter anvende hændelsen fra relæloggen asynkront. På grund af replikeringens asynkrone natur er slaveserveren ikke garanteret at have dataene, når masteren udfører ændringen.
Ideelt set vil MySQL-replikering have slaven til at blive konfigureret som en skrivebeskyttet server ved at indstille read_only=ON eller super_read_only=ON. Dette er en forholdsregel for at beskytte slaven mod utilsigtede skrivninger, som kan føre til datainkonsistens eller fejl under master failover (f.eks. fejlagtige transaktioner). I en master-master aktiv-aktiv replikeringsopsætning skal skrivebeskyttet imidlertid være deaktiveret på den anden master for at tillade, at skrivninger kan behandles samtidigt. Den primære master skal konfigureres til at replikere fra den sekundære master ved at bruge CHANGE MASTER-sætningen for at aktivere cirkulær replikering.
Galera-replikering
Følgende diagrammer illustrerer datareplikeringsflowet for en vellykket transaktion fra én node til en anden for Galera Cluster:
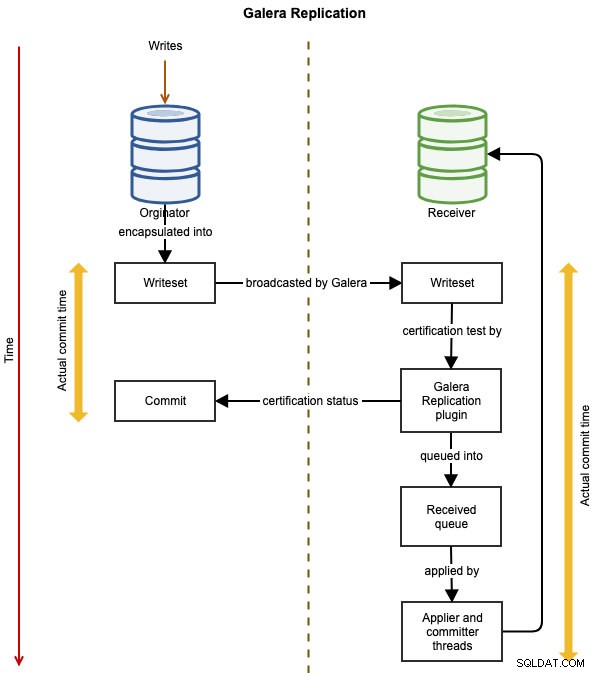
Hændelsen indkapsles i et skrivesæt og udsendes fra originalknudepunktet til de andre knudepunkter i klyngen ved hjælp af Galera-replikering. Skrivesættet gennemgår certificering på hver Galera-knude, og hvis det passerer, vil applier-trådene anvende skrivesættet asynkront. Dette betyder, at slaveserveren i sidste ende vil blive konsistent, efter aftale med alle deltagende noder i global total bestilling. Det er logisk synkront, men selve skrivningen og committeringen til tablespacet sker uafhængigt og dermed asynkront på hver node med garanti for, at ændringen udbredes på alle noder.
Undgåelse af primær nøglekollision
For at implementere MySQL-replikering i master-master-opsætningen, skal man justere den automatiske stigningsværdi for at undgå primærnøglekollision for INSERT mellem to eller flere replikerende mastere. Dette gør det muligt for den primære nøgleværdi på mastere at sammenflette hinanden og forhindre, at det samme automatiske inkrementnummer bruges to gange på en af noderne. Denne adfærd skal konfigureres manuelt, afhængigt af antallet af mastere i replikeringsopsætningen. Værdien af auto_increment_increment er lig med antallet af replikerende mastere og auto_increment_offset skal være unik mellem dem. For eksempel skulle følgende linjer eksistere inde i den tilsvarende my.cnf:
Master1:
log-slave-updates
auto_increment_increment=2
auto_increment_offset=1Master2:
log-slave-updates
auto_increment_increment=2
auto_increment_offset=2Ligeledes bruger Galera Cluster det samme trick til at undgå primærnøglekollisioner ved at kontrollere den automatiske stigningsværdi og forskyde automatisk med wsrep_auto_increment_control variabel. Hvis indstillet til 1 (standard), justeres automatisk auto_increment_increment og auto_increment_offset variable i henhold til klyngens størrelse, og hvornår klyngens størrelse ændres. Dette undgår replikeringskonflikter på grund af auto_increment. I et master-slave-miljø kan denne variabel indstilles til OFF.
Konsekvensen af denne konfiguration er, at den automatiske stigningsværdi ikke vil være i sekventiel rækkefølge, som vist i følgende tabel for en Galera-klynge med tre knudepunkter:
| Knude | auto_increment_increment | auto_increment_offset | Automatisk stigningsværdi |
|---|---|---|---|
| Node 1 | 3 | 1 | 1, 4, 7, 10, 13, 16... |
| Node 2 | 3 | 2 | 2, 5, 8, 11, 14, 17... |
| Node 3 | 3 | 3 | 3, 6, 9, 12, 15, 18... |
Hvis et program udfører indsættelseshandlinger på følgende noder i følgende rækkefølge:
- Node1, Node3, Node2, Node3, Node3, Node1, Node3 ..
Derefter vil den primære nøgleværdi, der vil blive gemt i tabellen, være:
- 1, 6, 8, 9, 12, 13, 15 ..
Simpelthen sagt, når du bruger master-master-replikering (MySQL-replikering eller Galera), skal din applikation være i stand til at tolerere ikke-sekventielle auto-increment-værdier i sit datasæt.
For ClusterControl-brugere skal du være opmærksom på, at den understøtter implementering af MySQL master-master-replikering med en grænse på to mastere pr. replikeringsklynge, kun for aktiv-passiv opsætning. Derfor konfigurerer ClusterControl ikke bevidst masterne med auto_increment_increment og auto_increment_offset variabler.
Datakonsistens
Galera Cluster kommer med sin flow-kontrolmekanisme, hvor hver node i klyngen skal følge med, når de replikeres, ellers bliver alle andre noder nødt til at sænke farten for at tillade den langsomste node at indhente. Dette minimerer dybest set sandsynligheden for slavelag, selvom det stadig kan ske, men ikke så signifikant som i MySQL-replikering. Som standard tillader Galera, at noder er mindst 16 transaktioner bagud i anvendelsen gennem variabel gcs.fc_limit . Hvis du vil foretage kritiske læsninger (en SELECT, der skal returnere de mest opdaterede oplysninger), vil du sandsynligvis bruge sessionsvariablen wsrep_sync_wait .
Galera Cluster på den anden side kommer med en beskyttelse mod datainkonsistens, hvorved en node bliver smidt ud af klyngen, hvis den undlader at anvende noget skrivesæt af en eller anden grund. For eksempel, når en Galera-node ikke anvender skrivesæt på grund af intern fejl fra den underliggende lagermotor (MySQL/MariaDB), vil noden trække sig ud af klyngen med følgende fejl:
150305 16:13:14 [ERROR] WSREP: Failed to apply trx 1 4 times
150305 16:13:14 [ERROR] WSREP: Node consistency compromized, aborting..For at rette op på datakonsistensen skal den fornærmende node synkroniseres igen, før den får lov til at slutte sig til klyngen. Dette kan gøres manuelt eller ved at slette databiblioteket for at udløse snapshot-tilstandsoverførsel (fuld synkronisering fra en donor).
MySQL master-master-replikering håndhæver ikke datakonsistensbeskyttelse, og en slave har lov til at divergere, f.eks. replikere en delmængde af data eller halte bagud, hvilket gør slaven inkonsistent med masteren. Den er designet til at replikere data i ét flow - fra master ned til slaverne. Datakonsistenstjek skal udføres manuelt eller via eksterne værktøjer som Percona Toolkit pt-table-checksum eller mysql-replikerings-tjek.
Konfliktløsning
Generelt tillader master-master (eller multi-master eller tovejs) replikering mere end ét medlem i klyngen til at behandle skrivninger. Med MySQL-replikering, i tilfælde af replikeringskonflikt, stopper slavens SQL-tråd simpelthen med at anvende den næste forespørgsel, indtil konflikten er løst, enten ved manuelt at springe replikeringshændelsen over, rette de stødende rækker eller gensynkronisere slaven. Simpelthen sagt er der ingen automatisk konfliktløsningsunderstøttelse til MySQL-replikering.
Galera Cluster giver et bedre alternativ ved at prøve den fornærmende transaktion igen under replikering. Ved at bruge wsrep_retry_autocommit variabel, kan man instruere Galera til automatisk at prøve en mislykket transaktion igen på grund af klyngeomfattende konflikter, før en fejl returneres til klienten. Hvis indstillet til 0, vil der ikke blive forsøgt genforsøg, mens en værdi på 1 (standard) eller mere angiver antallet af genforsøg. Dette kan være nyttigt for at hjælpe applikationer, der bruger autocommit for at undgå dødvande.
Knudekonsensus og failover
Galera bruger Group Communication System (GCS) til at kontrollere nodekonsensus og tilgængelighed mellem klyngemedlemmer. Hvis en node er usund, bliver den automatisk smidt ud af klyngen efter gmcast.peer_timeout værdi, standard til 3 sekunder. En sund Galera-knude i "Synced"-tilstand anses for at være en pålidelig node til at betjene læsninger og skrivninger, mens andre ikke er det. Dette design forenkler i høj grad procedurer for sundhedstjek fra de øverste niveauer (belastningsbalancer eller applikation).
I MySQL-replikering er en master ligeglad med sine slave(r), mens en slave kun har konsensus med sin eneste master via slave_IO_thread proces, når de binære hændelser replikeres fra masterens binære log. Hvis en master går ned, vil dette bryde replikeringen, og et forsøg på at genetablere linket vil blive gjort hver slave_net_timeout (standard til 60 sekunder). Fra applikations- eller belastningsbalanceringsperspektivet skal sundhedstjekprocedurerne for replikeringsslave mindst omfatte kontrol af følgende tilstand:
- Seconds_Behind_Master
- Slave_IO_Running
- Slave_SQL_Running
- skrivebeskyttet variabel
- super_read_only variabel (MySQL 5.7.8 og nyere)
Med hensyn til failover er master-master-replikering og Galera-noder generelt lige store. De har det samme datasæt (omend du kan replikere en delmængde af data i MySQL-replikering, men det er ualmindeligt for master-master) og deler den samme rolle som mastere, der er i stand til at håndtere læsning og skrivning samtidigt. Derfor er der faktisk ingen failover fra databasens synspunkt på grund af denne ligevægt. Kun fra applikationssiden ville det kræve failover for at springe de uoperative noder over. Husk, at fordi MySQL-replikering er asynkron, er det muligt, at ikke alle de ændringer, der er foretaget på masteren, er blevet spredt til den anden master.
Knudeklargøring
Processen med at bringe en node i synkronisering med klyngen, før replikering starter, er kendt som klargøring. I MySQL-replikering er klargøring af en ny node en manuel proces. Man skal tage en sikkerhedskopi af masteren og gendanne den til den nye node, før man opsætter replikeringslinket. For en eksisterende replikeringsknude, hvis masterens binære logfiler er blevet roteret (baseret på expire_logs_days , standard til 0 betyder ingen automatisk fjernelse), skal du muligvis genaktivere noden ved hjælp af denne procedure. Der er også eksterne værktøjer som Percona Toolkit pt-table-sync og ClusterControl til at hjælpe dig med dette. ClusterControl understøtter gensynkronisering af en slave med kun to klik. Du har muligheder for at gensynkronisere ved at tage en sikkerhedskopi fra den aktive master eller en eksisterende sikkerhedskopi.
I Galera er der to måder at gøre dette på - incremental state transfer (IST) eller state snapshot transfer (SST). IST-processen er den foretrukne metode, hvor kun de manglende transaktioner overføres fra en donors cache. SST-processen svarer til at tage en fuld backup fra donoren, den er normalt ret ressourcekrævende. Galera bestemmer automatisk, hvilken synkroniseringsproces, der skal udløses, baseret på deltagerens tilstand. I de fleste tilfælde, hvis en node ikke slutter sig til en klynge, skal du blot slette MySQL-datafilen for den problematiske node og starte MySQL-tjenesten. Galera-klargøringsprocessen er meget enklere, den er meget praktisk, når du skalerer din klynge ud eller genindfører en problematisk node tilbage i klyngen.
Løst koblet vs tæt koblet
MySQL-replikering fungerer meget godt selv på tværs af langsommere forbindelser og med forbindelser, der ikke er kontinuerlige. Det kan også bruges på tværs af forskellige hardware, miljøer og operativsystemer. De fleste lagringsmotorer understøtter det, inklusive MyISAM, Aria, MEMORY og ARCHIVE. Denne løst koblede opsætning tillader MySQL master-master replikering at fungere godt i et blandet miljø med færre begrænsninger.
Galera-noder er tæt koblede, hvor replikeringsydelsen er lige så hurtig som den langsomste knude. Galera bruger en flowkontrolmekanisme til at kontrollere replikationsflowet blandt medlemmer og eliminere enhver slaveforsinkelse. Replikeringen kan være hurtig eller langsom på hver knude og justeres automatisk af Galera. Det anbefales derfor at bruge ensartede hardwarespecifikationer for alle Galera-noder, især med hensyn til CPU, RAM, diskundersystem, netværksinterfacekort og netværksforsinkelse mellem noder i klyngen.
Konklusioner
Sammenfattende er Galera Cluster overlegen sammenlignet med MySQL master-master-replikering på grund af dens synkrone replikeringsunderstøttelse med stærk konsistens plus mere avancerede funktioner som automatisk medlemskontrol, automatisk node-provisioning og multi-threaded slaves. I sidste ende afhænger dette af, hvordan applikationen interagerer med databaseserveren. Nogle ældre applikationer bygget til en selvstændig databaseserver fungerer muligvis ikke godt på en klynget opsætning.
For at forenkle vores punkter ovenfor, retfærdiggør følgende grunde, hvornår man skal bruge MySQL master-master replikering:
- Ting, der ikke understøttes af Galera:
- Replikering for ikke-InnoDB/XtraDB-tabeller som MyISAM, Aria, MEMORY eller ARCHIVE.
- XA-transaktioner.
- Udsagnsbaseret replikering mellem mastere (f.eks. når båndbredden er meget dyr).
- Tilhænger af eksplicit låsning som LOCK TABLES-sætning.
- Den generelle forespørgselslog og den langsomme forespørgselslog skal dirigeres til en tabel i stedet for en fil.
- Løst koblet opsætning, hvor hardwarespecifikationerne, softwareversionen og forbindelseshastigheden er væsentligt forskellige på hver master.
- Når du allerede har en MySQL-replikeringskæde, og du vil tilføje en anden aktiv master/backup-master til redundans for at fremskynde failover- og retableringstiden i tilfælde af, at en af masterne ikke er tilgængelig.
- Hvis din applikation ikke kan ændres til at omgå Galera Cluster-begrænsninger, og det ikke er en mulighed at have en MySQL-bevidst load balancer som ProxySQL eller MaxScale.
Grunde til at vælge Galera Cluster frem for MySQL master-master replikering:
- Evne til sikkert at skrive til flere mestre.
- Datakonsistens administreres (og garanteres) automatisk på tværs af databaser.
- Nye databasenoder kan nemt introduceres og synkroniseres.
- Fejl eller uoverensstemmelser registreres automatisk.
- Generelt mere avancerede og robuste funktioner med høj tilgængelighed.