Dette blogindlæg er tredje del af serien af blogs om indekser i MySQL . I anden del af blogindlægsserien om MySQL-indekser dækkede vi indekser og lagringsmotorer og kom ind på nogle PRIMÆRE NØGLEovervejelser. Diskussionen omfattede, hvordan man matcher et kolonnepræfiks, nogle FULLTEXT-indeksovervejelser, og hvordan du bør bruge B-Tree-indekser med jokertegn, og hvordan du bruger ClusterControl til at overvåge dine forespørgslers ydeevne og efterfølgende indekser.
I dette blogindlæg vil vi gå ind på nogle flere detaljer om indekser i MySQL :vi vil dække hash-indekser, indekskardinalitet, indeksselektivitet, vi vil fortælle dig interessante detaljer om dækning af indekser, og vi vil også gennemgå nogle indekseringsstrategier. Og selvfølgelig vil vi komme ind på ClusterControl. Lad os begynde, skal vi?
Hash-indekser i MySQL
MySQL DBA'er og udviklere, der beskæftiger sig med MySQL, har også et andet trick i ærmet, hvad MySQL angår - hash-indekser er også en mulighed. Hash-indekser bruges ofte i MEMORY-motoren i MySQL - som med stort set alt i MySQL, har den slags indekser deres egne fordele og ulemper. Den største ulempe ved denne slags indekser er, at de kun bruges til lighedssammenligninger, der bruger =eller <=> operatorerne, hvilket betyder, at de ikke er virkelig nyttige, hvis du vil søge efter en række værdier, men den største fordel er at opslag er meget hurtige. Et par yderligere ulemper inkluderer det faktum, at udviklere ikke kan bruge et præfiks længst til venstre for nøglen til at finde rækker (hvis du vil gøre det, så brug B-Tree-indekser i stedet), det faktum, at MySQL ikke tilnærmelsesvis kan bestemme, hvor mange rækker der er mellem to værdier - hvis hash-indekser er i brug, kan optimeringsværktøjet heller ikke bruge et hash-indeks til at fremskynde ORDER BY-operationer. Husk på, at hash-indekser ikke er det eneste, MEMORY-motoren understøtter - MEMORY-motorer kan også have B-Tree-indekser.
Indeks kardinalitet i MySQL
Hvad angår MySQL-indekser, har du måske også hørt et andet udtryk gå rundt - dette udtryk kaldes indekskardinalitet. I meget enkle vendinger refererer indekskardinalitet til det unikke ved værdier gemt i en kolonne, der bruger et indeks. For at se indekskardinaliteten af et specifikt indeks kan du blot gå til fanen Struktur i phpMyAdmin og observere informationen der, eller du kan også udføre en VIS INDEKSER-forespørgsel:
mysql> SHOW INDEXES FROM demo_table;
+---------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| demo_table | 1 | demo | 1 | demo | A | 494573 | NULL | NULL | | BTREE | | |
+---------------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
1 row in set (0.00 sec)SHOW INDEXS-forespørgselsoutputtet, der kan ses ovenfor, som du kan se, har en masse felter, hvoraf et afbilder indekskardinaliteten:dette felt returnerer et estimeret antal unikke værdier i indekset - højere kardinalitet, jo større er chancen for, at forespørgselsoptimeringsværktøjet bruger indekset til opslag. Når det er sagt, så har indekskardinalitet også en bror - hans navn er indeksselektivitet.
Indekselektivitet i MySQL
En indeksselektivitet er antallet af distinkte værdier i forhold til antallet af poster i tabellen. Enkelt sagt definerer indeksselektivitet, hvor stramt et databaseindeks hjælper MySQL med at indsnævre søgningen efter værdier. En ideel indeksselektivitet er værdien af 1. En indeksselektivitet beregnes ved at dividere de forskellige værdier i en tabel med det samlede antal poster, for eksempel hvis du har 1.000.000 poster i din tabel, men kun 100.000 af dem er distinkte værdier , ville din indeksselektivitet være 0,1. Hvis du har 10.000 poster i din tabel, og 8.500 af dem er forskellige værdier, vil din indeksselektivitet være 0,85. Det er meget bedre. Du forstår pointen. Jo højere din indeksselektivitet er, jo bedre.
Dækker indekser i MySQL
Et dækkende indeks er en særlig type indeks i InnoDB. Når et dækkende indeks er i brug, er alle de påkrævede felter for en forespørgsel inkluderet, eller "dækket", af indekset, hvilket betyder, at du også kan høste fordelene ved kun at læse indekset i stedet for dataene. Hvis intet andet hjælper, kan et dækkende indeks være din billet til forbedret ydeevne. Nogle af fordelene ved at bruge dækkende indekser inkluderer:
-
Et af de vigtigste scenarier, hvor et dækkende indeks kan være nyttigt, omfatter visning af forespørgsler uden yderligere I/O-læsninger på store borde.
-
MySQL kan også få adgang til færre data på grund af det faktum, at indeksposter er mindre end rækkernes størrelse.
-
De fleste lagermotorer cachelagrer indekser bedre end data.
Oprettelse af dækkende indekser på en tabel er ret simpelt - dæk blot de felter, der tilgås af SELECT-, WHERE- og GROUP BY-sætninger:
ALTER TABLE demo_table ADD INDEX index_name(column_1, column_2, column_3);Husk på, at når du har med at dække indekser, er det meget vigtigt at vælge den korrekte rækkefølge af kolonner i indekset. For at dine dækkende indekser skal være effektive, skal du placere de kolonner, du bruger med WHERE-sætninger først, ORDER BY og GROUP BY næste og kolonnerne, der bruges med SELECT-sætningen, sidst.
Indekseringsstrategier i MySQL
At følge de råd, der er beskrevet i disse tre dele af blogindlæg om indekser i MySQL, kan give dig et rigtig godt grundlag, men der er også et par indekseringsstrategier, du måske vil bruge, hvis du vil virkelig udnytte kraften ved indekser i din MySQL-arkitektur. For at dine indekser skal overholde MySQL bedste praksis, skal du overveje:
-
Isolering af kolonnen, som du bruger indekset på - generelt bruger MySQL ikke indekser, hvis kolonnerne de bruges på er ikke isoleret. For eksempel vil en sådan forespørgsel ikke bruge et indeks, fordi det ikke er isoleret:
SELECT demo_column FROM demo_table WHERE demo_id + 1 = 10;
En sådan forespørgsel ville dog:
SELECT demo_column FROM demo_table WHERE demo_id = 10; -
Brug ikke indekser på de kolonner, du indekserer. For eksempel ville det ikke gøre meget gavn at bruge en forespørgsel som sådan, så det er bedre at undgå sådanne forespørgsler, hvis du kan:
SELECT demo_column FROM demo_table WHERE TO_DAYS(CURRENT_DATE) - TO_DAYS(column_date) <= 10; -
Hvis du bruger LIKE-forespørgsler sammen med indekserede kolonner, skal du undgå at sætte jokertegnet i begyndelsen af søgeforespørgslen, fordi på den måde vil MySQL heller ikke bruge et indeks. Det er i stedet for at skrive forespørgsler som denne:
SELECT * FROM demo_table WHERE demo_column LIKE ‘%search query%’;
Overvej at skrive dem sådan her:SELECT * FROM demo_table WHERE demo_column LIKE ‘search_query%’;
Den anden forespørgsel er bedre, fordi MySQL ved, hvad kolonnen begynder med og kan bruge indekser mere effektivt. Som med alt, kan EXPLAIN-sætningen dog være til stor hjælp, hvis du vil sikre dig, at dine indekser faktisk bruges af MySQL.
Brug af ClusterControl til at holde dine forespørgsler mere effektive
Hvis du ønsker at forbedre din MySQL-ydeevne, bør rådene ovenfor føre dig på rette vej. Hvis du dog føler, at du har brug for noget mere, så overvej ClusterControl til MySQL. En af de ting, som ClusterControl kan hjælpe dig med, omfatter præstationsstyring - som allerede nævnt i tidligere blogindlæg, kan ClusterControl også hjælpe dig med at holde dine forespørgsler, der yder bedst muligt hele tiden - det er fordi ClusterControl også inkluderer en forespørgsel monitor, der giver dig mulighed for at overvåge ydeevnen af dine forespørgsler, se langsomme, langvarige forespørgsler og også forespørgsler, der advarer dig om de mulige flaskehalse i din databaseydeevne, før du måske selv kan bemærke dem:
Du kan endda filtrere dine forespørgsler, så du kan foretage en antagelse, hvis et indeks blev brugt af en individuel forespørgsel eller ej:
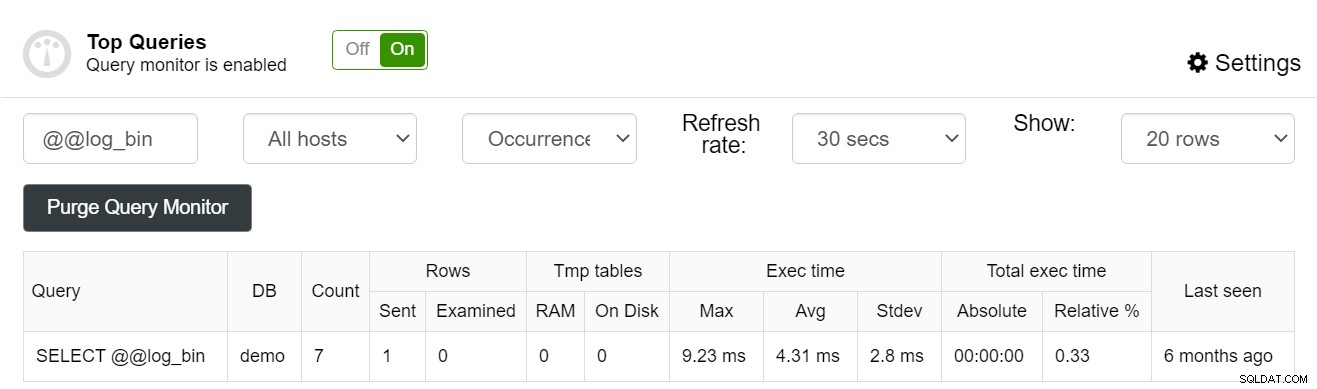
ClusterControl kan være et fantastisk værktøj til at forbedre din databaseydeevne, mens du slipper for vedligeholdelsesbesværet. For at lære mere om, hvad ClusterControl kan gøre for at forbedre ydeevnen af dine MySQL-instanser, kan du overveje at tage et kig på ClusterControl til MySQL-siden.
Oversigt
Som du sikkert kan se nu, er indekser i MySQL et meget komplekst dyr. For at vælge det bedste indeks til din MySQL-instans, ved, hvad indekser er, og hvad de gør, kend typerne af MySQL-indekser, kend deres fordele og ulemper, uddanne dig selv om, hvordan MySQL-indekser interagerer med storage-motorer, tag også et kig på ClusterControl for MySQL, hvis du føler, at automatisering af visse opgaver relateret til indekser i MySQL kan gøre din dag lettere.