Galera-klyngen fremtvinger stærk datakonsistens, hvor alle noder i klyngen er tæt koblet. Selvom netværkssegmentering understøttes, er replikeringsydelsen stadig bundet af to faktorer:
-
Rundrejsetiden (RTT) til den fjerneste node i klyngen fra originalknuden.
-
Størrelsen af et skrivesæt, der skal overføres og certificeres for konflikt på modtagernoden.
Selv om der er måder at booste Galeras ydeevne på, er det ikke muligt at omgå disse to begrænsende faktorer.
Heldigvis blev Galera Cluster bygget oven på MySQL, som også kommer med en indbygget replikeringsfunktion (duh!). Både Galera-replikering og MySQL-replikering findes uafhængigt af den samme serversoftware. Vi kan bruge disse teknologier til at arbejde sammen, hvor al replikering i et datacenter vil være på Galera, mens inter-datacenter replikering vil være på standard MySQL Replikering. Slavestedet kan fungere som et hot-standby-sted, klar til at betjene data, når applikationerne er omdirigeret til backupstedet. Vi dækkede dette i en tidligere blog om MySQL-arkitekturer til katastrofeoprettelse.
Klynge-til-klynge-replikering blev introduceret i ClusterControl i version 1.7.4. I dette blogindlæg viser vi, hvor ligetil det er at opsætte replikering mellem to Galera-klynger (PXC 8.0). Derefter vil vi se på den mere udfordrende del:håndtering af fejl på både node- og klyngeniveau ved hjælp af ClusterControl; failover- og failback-operationer er afgørende for at bevare dataintegriteten på tværs af systemet.
Klyngeimplementering
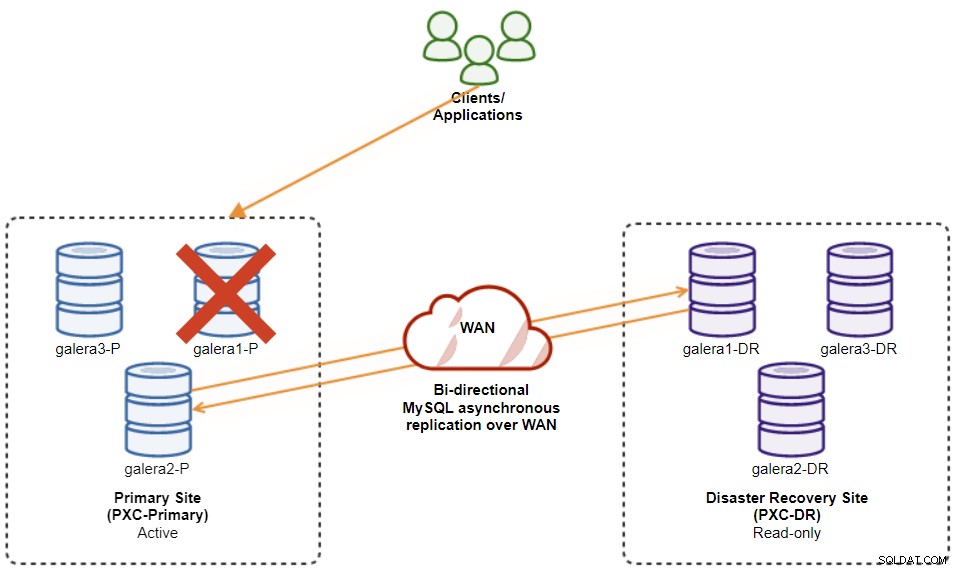
Af hensyn til vores eksempel har vi brug for mindst to klynger og to websteder – en til den primære og en anden til den sekundære. Det fungerer på samme måde som traditionel MySQL master-slave-replikering, men i større skala med tre databasenoder på hvert websted. Med ClusterControl ville du opnå dette ved at implementere en primær klynge efterfulgt af at implementere den sekundære klynge på katastrofegendannelsesstedet som en replika-klynge, replikeret af en tovejs asynkron replikering.
Følgende diagram illustrerer vores endelige arkitektur:

Vi har seks databasenoder i alt, tre på det primære websted og en anden tre på webstedet for gendannelse efter katastrofe. For at forenkle noderepræsentationen vil vi bruge følgende notationer:
-
Primært websted:
-
galera1-P - 192.168.11.171 (master)
-
galera2-P - 192.168.11.172
-
galera3-P - 192.168.11.173
-
-
Websted for katastrofegendannelse:
-
galera1-DR - 192.168.11.181 (slave)
-
galera2-DR - 192.168.11.182
-
galera3-DR - 192.168.11.183
-
Først skal du blot implementere den første klynge, og vi kalder den PXC-Primær. Åbn ClusterControl UI → Deploy → MySQL Galera, og indtast alle de nødvendige detaljer:
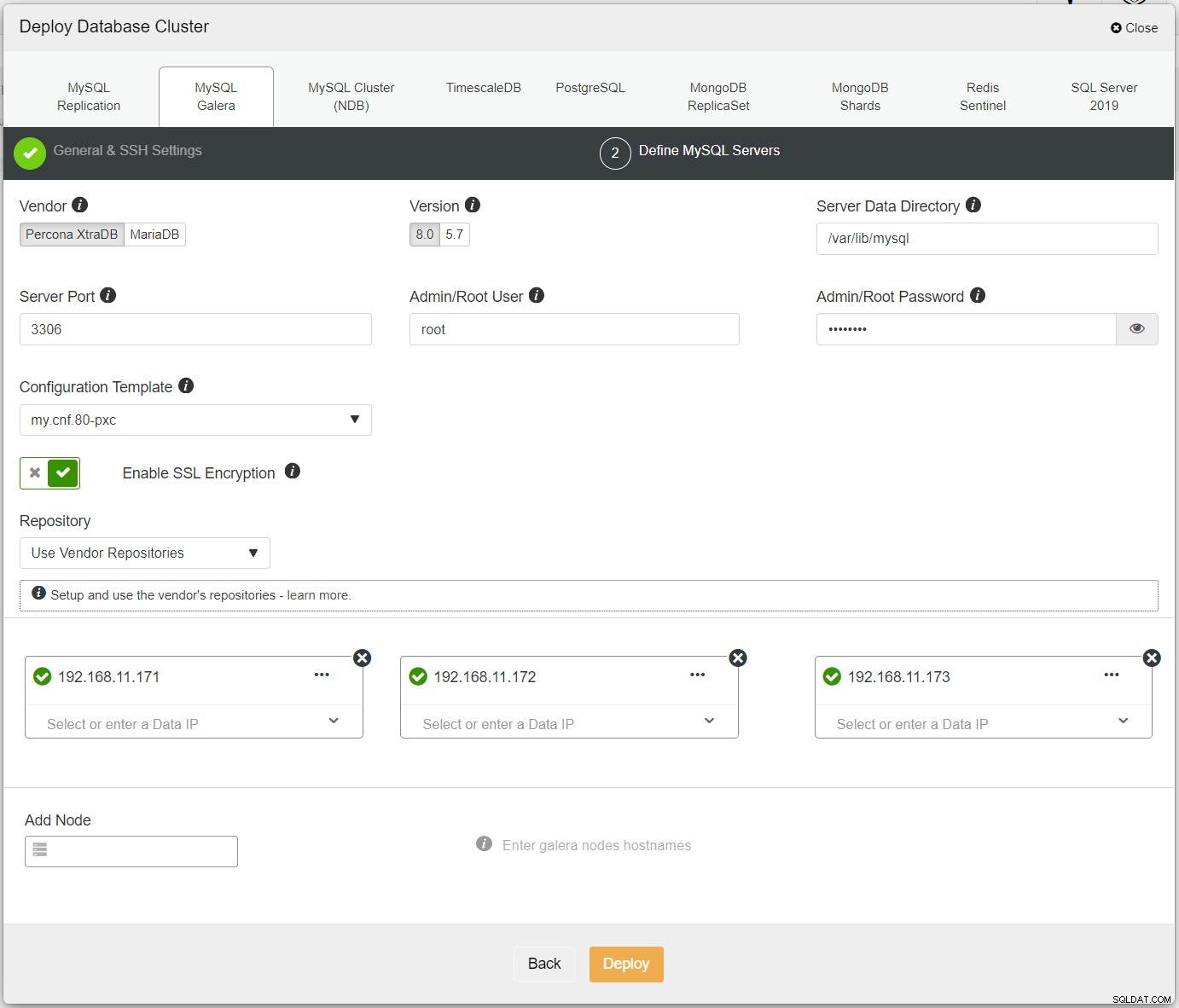
Sørg for, at hver specificeret node har et grønt flueben ved siden af, hvilket indikerer, at ClusterControl kan oprette forbindelse til værten via adgangskodefri SSH. Klik på Implementer og vent på, at implementeringen er fuldført. Når du er færdig, bør du se følgende klynge opført på klyngens dashboard-side:
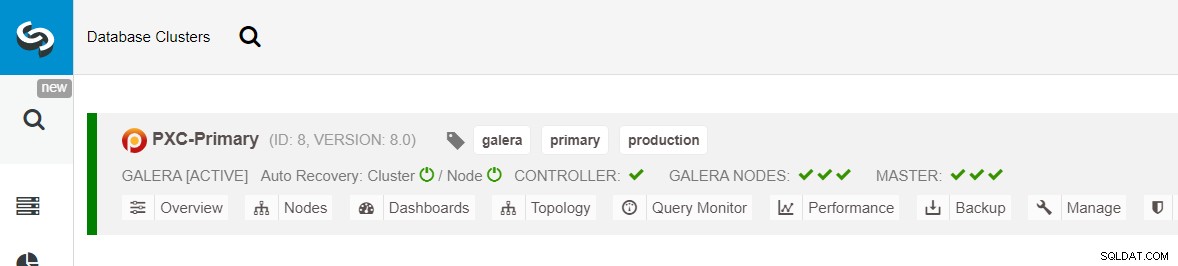
Dernæst vil vi bruge ClusterControl-funktionen kaldet Create Replica Cluster, tilgængelig fra rullemenuen Cluster Action:
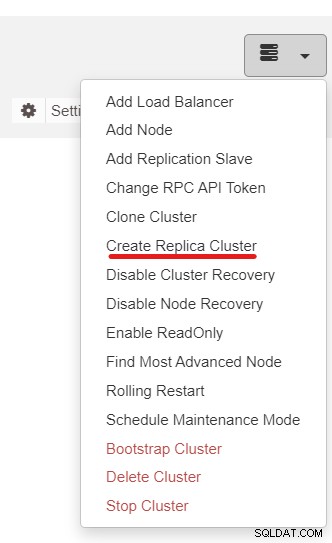
Du vil blive præsenteret for følgende sidebar-popup:
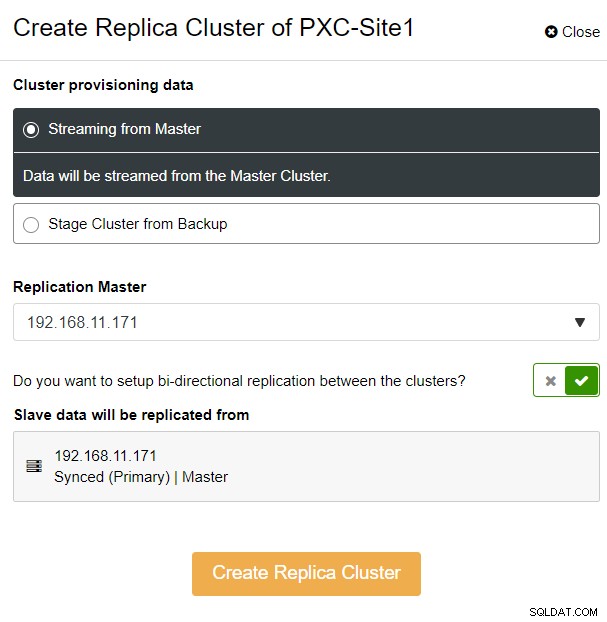
Vi valgte indstillingen "Streaming fra Master", hvor ClusterControl vil bruge valgt master til at synkronisere replikaklyngen og konfigurere replikeringen. Vær opmærksom på muligheden for tovejsreplikering. Hvis aktiveret, vil ClusterControl opsætte en tovejsreplikation mellem begge steder (cirkulær replikering). Den valgte master vil replikere fra den første master, der er defineret for replika-klyngen og omvendt. Denne opsætning vil minimere den nødvendige iscenesættelsestid ved gendannelse efter failover eller failback. Klik på "Create Replica Cluster", hvor ClusterControl åbner en ny implementeringsguide for replika-klyngen, som vist nedenfor:
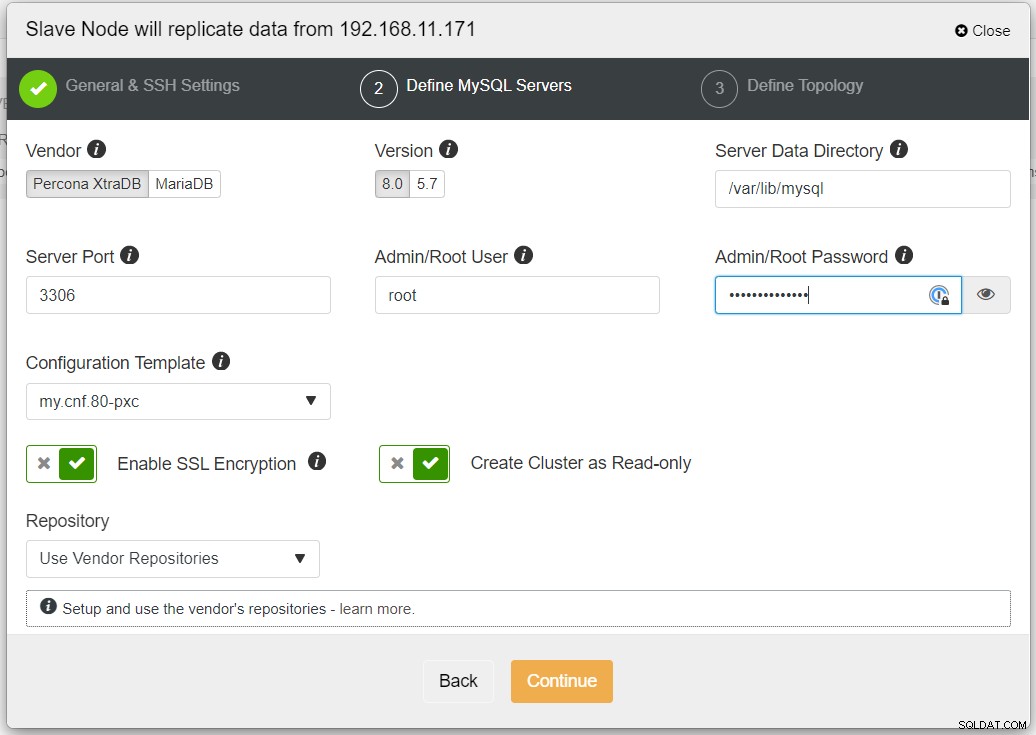
Det anbefales at aktivere SSL-kryptering, hvis replikeringen involverer ikke-pålidelige netværk som WAN, ikke-tunnelerede netværk eller internettet. Sørg også for, at "Opret klynge som skrivebeskyttet" er slået til. dette er beskyttelsen mod utilsigtet skrivning og en god indikator til let at skelne mellem den aktive klynge (læse-skrive) og den passive klynge (skrivebeskyttet).
Når du udfylder alle de nødvendige oplysninger, bør du nå følgende trin for at definere replika-klyngetopologien:
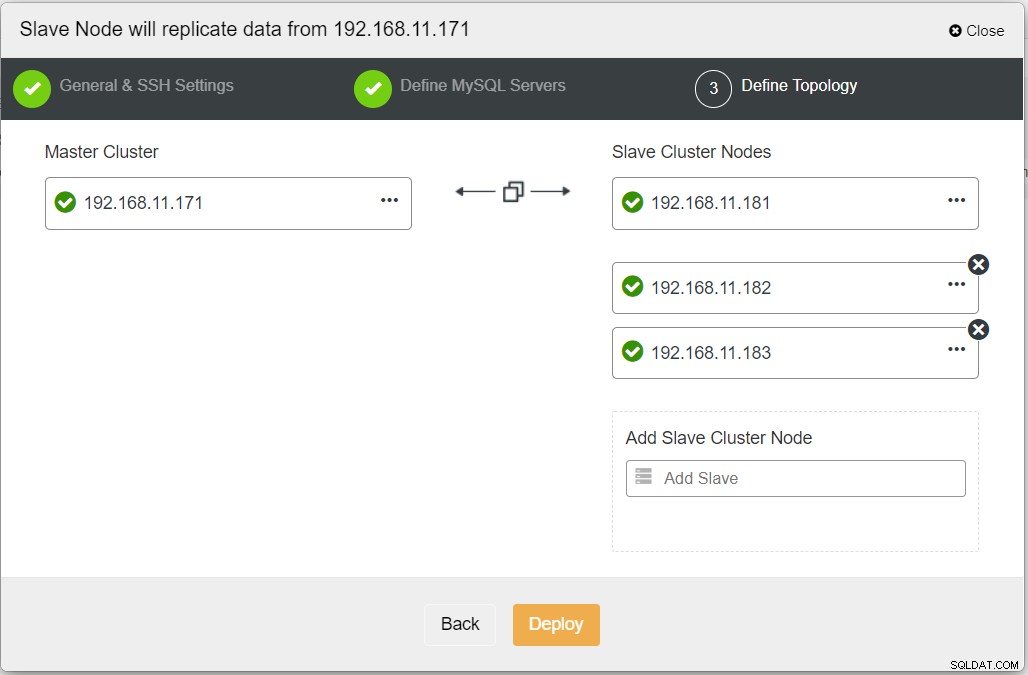
Fra ClusterControl-dashboardet, når implementeringen er færdig, bør du se DR-webstedet har en tovejs-pil forbundet med det primære websted:
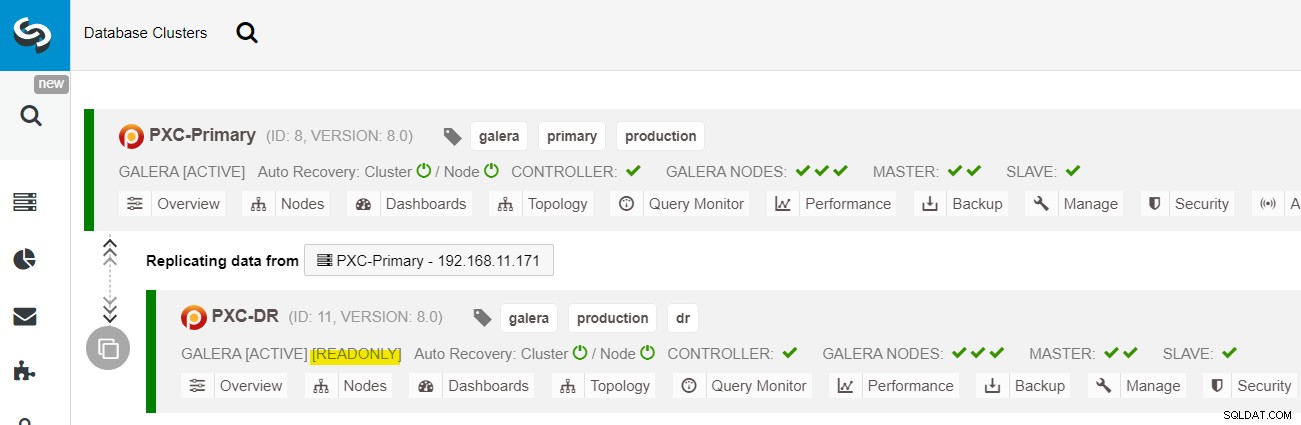
Implementeringen er nu fuldført. Applikationer bør kun sende skrivninger til det primære websted, da dette er det aktive websted, og DR-webstedet er konfigureret til skrivebeskyttet (fremhævet med gult). Aflæsninger kan sendes til begge steder, selvom DR-siden risikerer at halte bagud på grund af den asynkrone replikeringskarakter. Denne opsætning vil gøre de primære og katastrofegendannelsessteder uafhængige af hinanden, løst forbundet med asynkron replikering. En af Galera-knuderne på DR-webstedet vil være en slave, der replikerer fra en af Galera-knuderne (master) på det primære websted.
Vi har nu et system, hvor en klyngefejl på det primære websted ikke vil påvirke sikkerhedskopieringsstedet. Ydeevnemæssigt vil WAN-forsinkelse ikke påvirke opdateringer på den aktive klynge. Disse sendes asynkront til backupstedet.
Som en sidebemærkning er det også muligt at have en dedikeret slaveinstans som replikeringsrelæ i stedet for at bruge en af Galera-knuderne som slave.
Galera Node Failover-procedure
Hvis den nuværende master (galera1-P) fejler, og de resterende knudepunkter på det primære sted stadig er oppe, skal slaven på katastrofegendannelsesstedet (galera1-DR) dirigeres til alle tilgængelige mastere på det primære websted, som vist i følgende diagram:
Fra ClusterControl-klyngelisten kan du se, at klyngestatussen er forringet , og hvis du ruller over på udråbstegnsikonet, kan du se fejlen for den pågældende node (galera1-P):
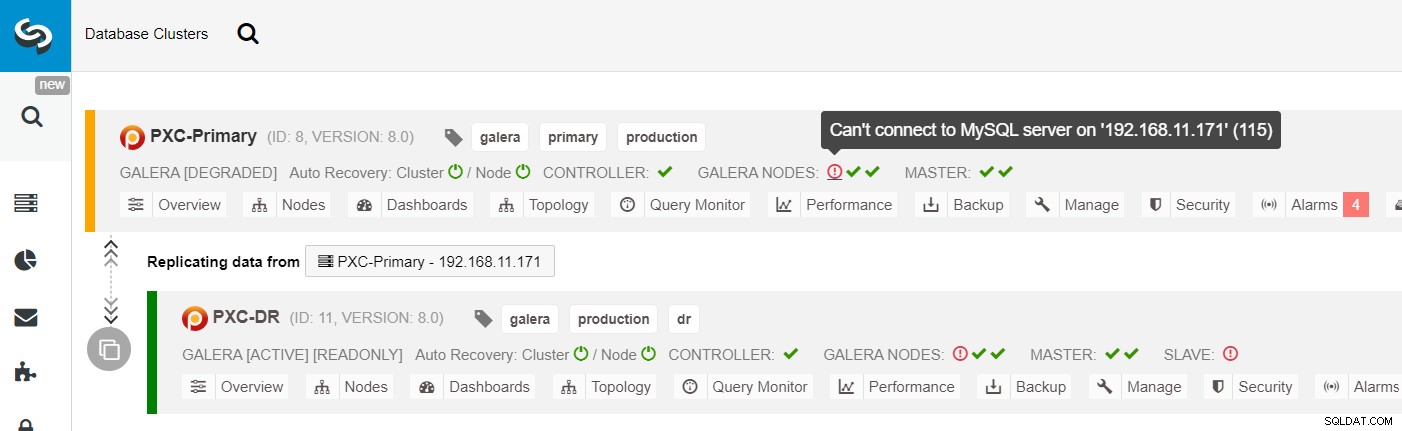
Med ClusterControl kan du blot gå til PXC-DR-klynge → Noder → vælg galera1-DR → Nodehandlinger → Genopbyg replikeringsslave, og du vil blive præsenteret for følgende konfigurationsdialog:
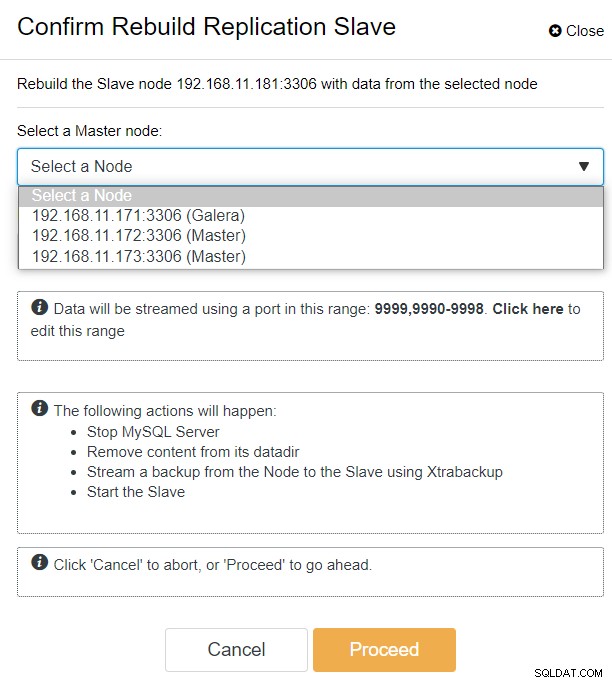
Vi kan se alle Galera-noder på det primære websted (192.168.11.17x ) fra rullelisten. Vælg den sekundære node, 192.168.11.172 (galera2-P), og klik på Fortsæt. ClusterControl konfigurerer derefter replikeringstopologien, som den skal være, og opsætter tovejsreplikering fra galera2-P til galera1-DR. Du kan bekræfte dette fra klyngens dashboard-side (markeret med gult):
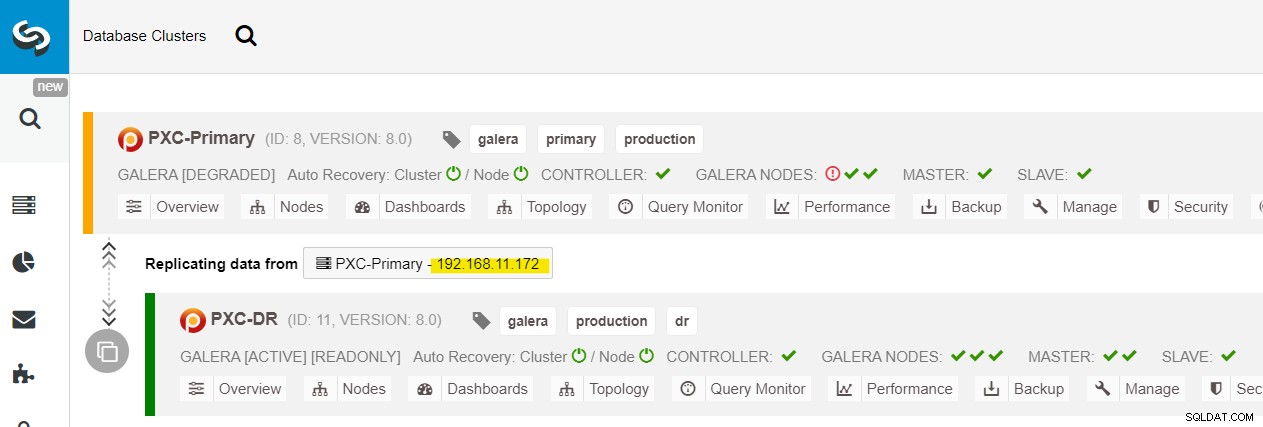
På dette tidspunkt tjener den primære klynge (PXC-Primary) stadig som den aktive klynge for denne topologi. Det bør ikke påvirke databasetjenestens oppetid for den primære klynge.
Galera Cluster Failover-procedure
Hvis den primære klynge går ned, går ned eller simpelthen mister forbindelse fra et applikationssynspunkt, kan applikationen dirigeres til DR-webstedet næsten øjeblikkeligt. SysAdmin skal blot deaktivere skrivebeskyttet på alle Galera-noder på katastrofegendannelsesstedet ved at bruge følgende sætning:
mysql> SET GLOBAL read_only = 0; -- repeat on galera1-DR, galera2-DR, galera3-DRFor ClusterControl-brugere kan du bruge ClusterControl UI → Noder → vælg DB-noden → Nodehandlinger → Deaktiver skrivebeskyttet. ClusterControl CLI er også tilgængelig ved at udføre følgende kommandoer på ClusterControl-noden:
$ s9s node --nodes="192.168.11.181" --cluster-id=11 --set-read-write
$ s9s node --nodes="192.168.11.182" --cluster-id=11 --set-read-write
$ s9s node --nodes="192.168.11.183" --cluster-id=11 --set-read-writeFailoveren til DR-webstedet er nu fuldført, og applikationerne kan begynde at sende skrivninger til PXC-DR-klyngen. Fra ClusterControl-brugergrænsefladen skulle du se noget som dette:
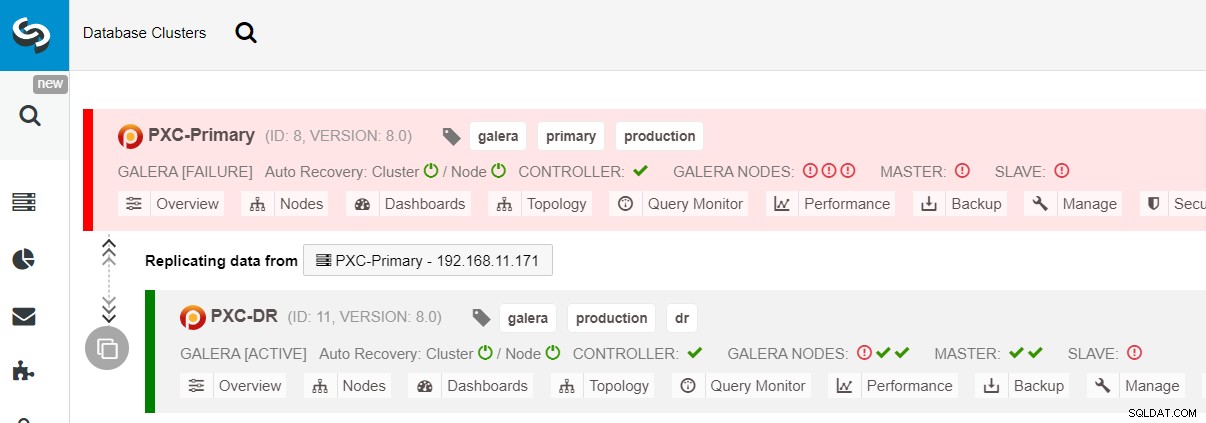
Følgende diagram viser vores arkitektur, efter at applikationen fejlede over til DR-webstedet :
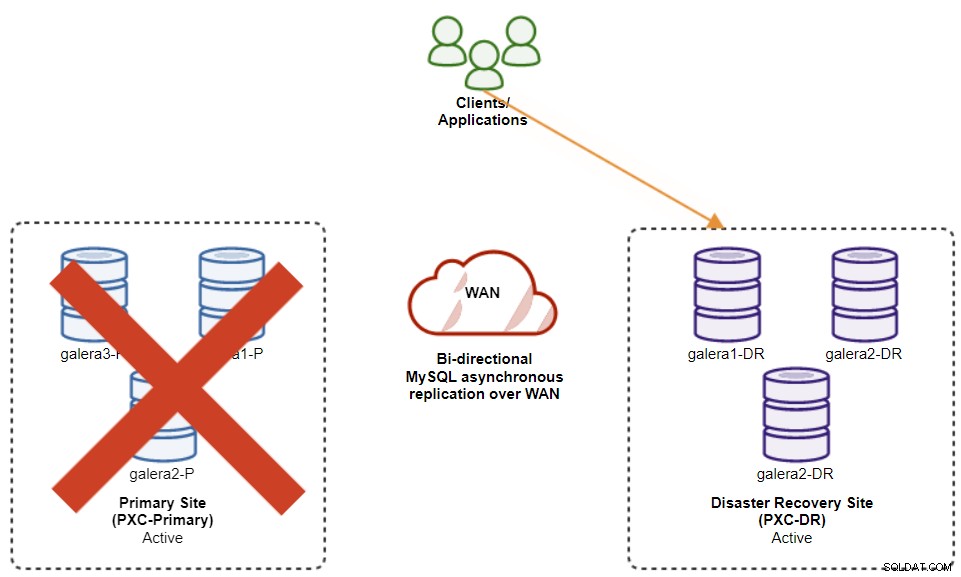
Forudsat at det primære websted stadig er nede, er der ingen replikering mellem websteder, indtil det primære websted kommer op igen.
Galera Cluster Failback-procedure
Når det primære websted kommer op, er det vigtigt at bemærke, at den primære klynge skal indstilles til skrivebeskyttet, så vi ved, at den aktive klynge er den, der er på webstedet for gendannelse af katastrofer. Fra ClusterControl, gå til klyngens rullemenu og vælg "Aktiver skrivebeskyttet", som vil aktivere skrivebeskyttet på alle noder i den primære klynge og opsummerer den aktuelle topologi som nedenfor:
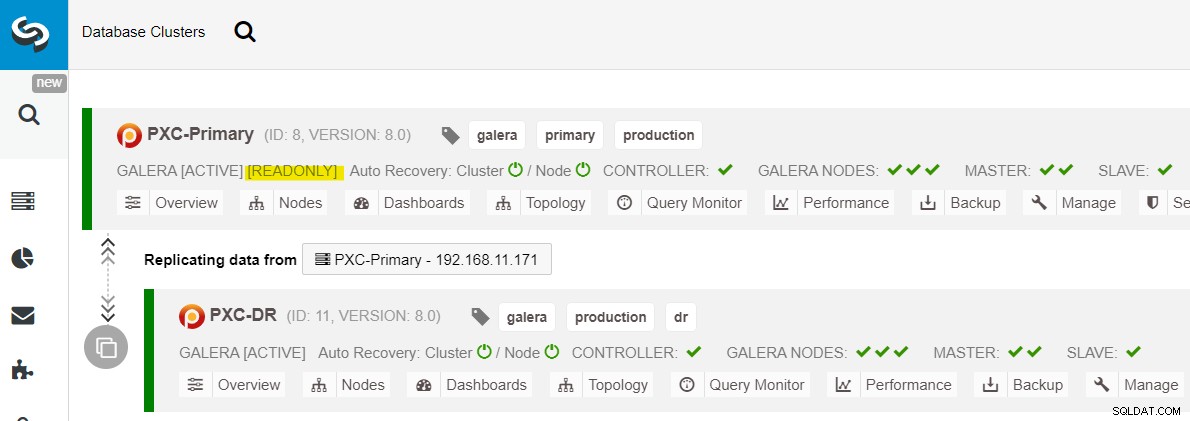
Sørg for, at alt er grønt, før du planlægger at starte cluster-fejlback-proceduren (grøn betyder, at alle noder er oppe og synkroniserede med hinanden). Hvis der f.eks. er en knude i forringende status, er den replikerende knude stadig bagud, eller kun nogle af knudepunkterne i den primære klynge var tilgængelige, skal du vente, indtil klyngen er fuldstændig gendannet, enten ved at vente på ClusterControls automatiske gendannelsesprocedurer at fuldføre, eller manuel indgriben.
På dette tidspunkt er den aktive klynge stadig DR's klynge, og den primære klynge fungerer som en sekundær klynge. Følgende diagram illustrerer den aktuelle arkitektur:
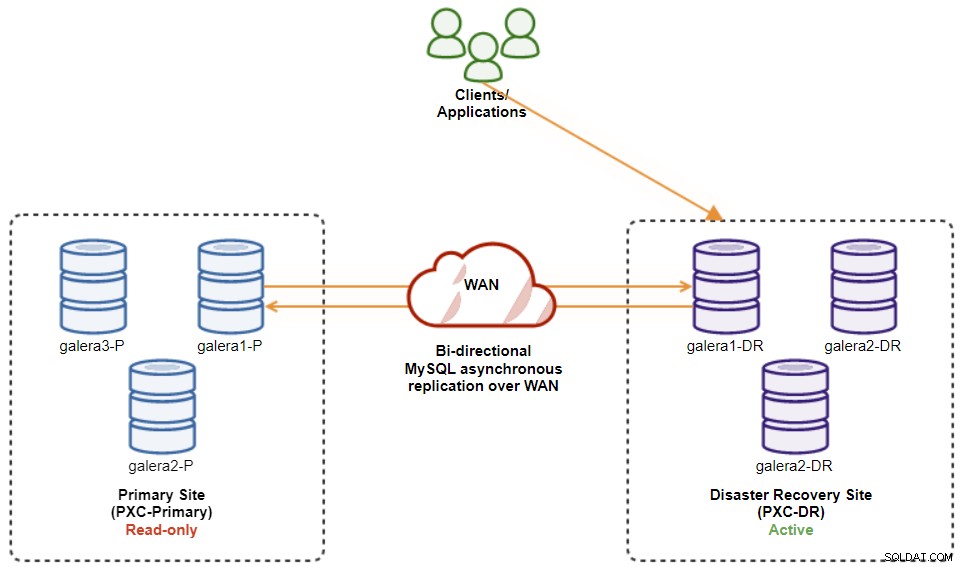
Den sikreste måde at failback til det primære websted på er at indstille skrivebeskyttet på DR's klynge, efterfulgt af deaktivering af skrivebeskyttet på Primær Site. Gå til ClusterControl UI → PXC-DR (rullemenu) → Aktiver skrivebeskyttet. Dette vil udløse et job til at indstille skrivebeskyttet på alle noder på DR's klynge. Gå derefter til ClusterControl UI → PXC-Primary → Noder, og deaktiver skrivebeskyttet på alle databasenoder i den primære klynge.
Du kan også forenkle ovenstående procedurer med ClusterControl CLI. Alternativt kan du udføre følgende kommandoer på ClusterControl-værten:
$ s9s cluster --cluster-id=11 --set-read-only # enable cluster-wide read-only
$ s9s node --nodes="192.168.11.171" --cluster-id=8 --set-read-write
$ s9s node --nodes="192.168.11.172" --cluster-id=8 --set-read-write
$ s9s node --nodes="192.168.11.173" --cluster-id=8 --set-read-writeNår det er gjort, er replikeringsretningen gået tilbage til dens oprindelige konfiguration, hvor PXC-Primary er den aktive klynge og PXC-DR er standby-klyngen. Følgende diagram illustrerer den endelige arkitektur efter cluster failback-operationen:
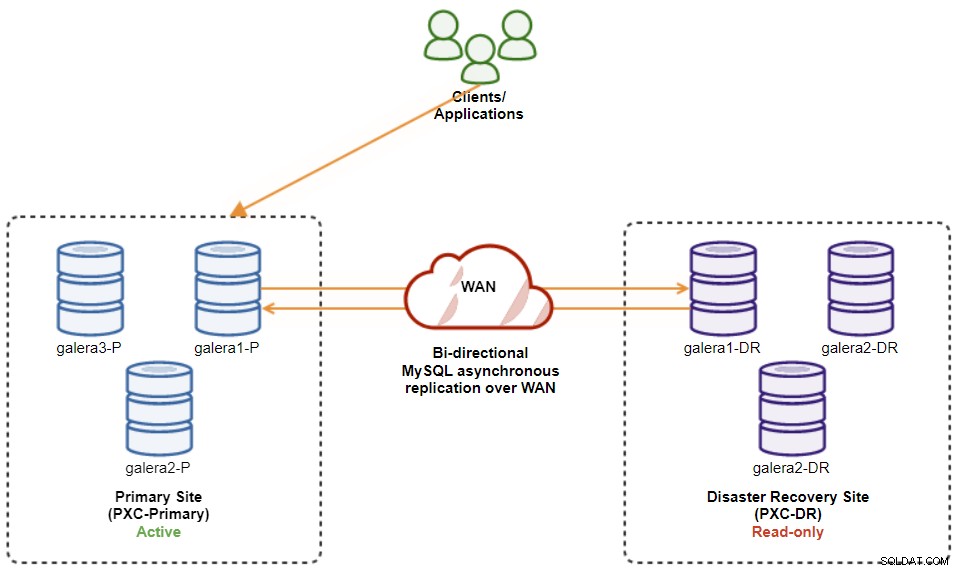
På dette tidspunkt er det nu sikkert at omdirigere applikationerne til at skrive på det primære websted.
Fordele ved klynge-til-klynge asynkron replikering
Klynge-til-klynge med asynkron replikering kommer med en række fordele:
-
Minimal nedetid under en database-failover-handling. Grundlæggende kan du omdirigere skrivningen næsten øjeblikkeligt til slave-webstedet, kun hvis du kan beskytte skrivninger til ikke at nå master-webstedet (da disse skrivninger ikke ville blive replikeret, og sandsynligvis vil blive overskrevet ved re-synkronisering fra DR-webstedet).
-
Ingen indvirkning af ydeevnen på det primære websted, da det er uafhængigt af sikkerhedskopieringsstedet (DR). Replikering fra master til slave udføres asynkront. Masterwebstedet genererer binære logfiler, slavestedet replikerer hændelserne og anvender hændelserne på et senere tidspunkt.
-
Katastrofegendannelseswebsteder kan bruges til andre formål, for eksempel backup af database, backup af binær log og rapportering, eller tunge analytiske forespørgsler (OLAP). Begge steder kan bruges samtidigt, bortset fra replikeringsforsinkelsen og skrivebeskyttede operationer på slavesiden.
-
DR-klyngen kunne potentielt køre på mindre instanser i et offentligt cloudmiljø, så længe de kan følge med med den primære klynge. Du kan opgradere forekomsterne, hvis det er nødvendigt. I visse scenarier kan det spare dig for nogle omkostninger.
-
Du behøver kun ét ekstra websted til Disaster Recovery sammenlignet med aktiv-aktiv Galera multi-site replikeringsopsætning, som kræver mindst tre aktive websteder for at fungere korrekt.
Ulemper ved klynge-til-klynge asynkron replikering
Der er også ulemper ved denne opsætning, afhængigt af om du bruger tovejs- eller envejsreplikering:
-
Der er en chance for at mangle nogle data under failover, hvis slaven var bagud, da replikering er asynkron. Dette kunne forbedres med semi-synkron og multi-threaded slavereplikering, omend der vil være et andet sæt udfordringer i vente (netværksoverhead, replikeringsgab osv.).
-
I envejsreplikering, på trods af at failover-procedurerne er ret enkle, kan failback-procedurerne være vanskelige og tilbøjelige til mennesker fejl. Det kræver en vis ekspertise i at skifte master/slave-rolle tilbage til det primære sted. Det anbefales at holde procedurerne dokumenterede, øve failover/failback-operationen regelmæssigt og bruge nøjagtige rapporterings- og overvågningsværktøjer.
-
Det kan være temmelig dyrt, da du skal konfigurere et tilsvarende antal noder på webstedet for gendannelse af katastrofer . Dette er ikke sort og hvidt, da omkostningsbegrundelsen normalt kommer fra kravene i din virksomhed. Med en vis planlægning er det muligt at maksimere brugen af databaseressourcer på begge steder, uanset databaserollerne.
Afslutning
Opsætning af asynkron replikering til dine MySQL Galera-klynger kan være en forholdsvis ligetil proces - så længe du forstår, hvordan man korrekt håndterer fejl på både node- og klyngeniveau. I sidste ende er failover- og failback-operationer afgørende for at sikre dataintegritet.
For flere tips om at designe dine Galera-klynger med failover- og failback-strategier i tankerne, tjek dette indlæg om MySQL-arkitekturer til gendannelse af katastrofer. Hvis du leder efter hjælp til at automatisere disse operationer, skal du evaluere ClusterControl gratis i 30 dage og følge trinene i dette indlæg.
Glem ikke at følge os på Twitter eller LinkedIn og abonner på vores nyhedsbrev, hold dig opdateret om de seneste nyheder og bedste praksis for styring af din open source-databaseinfrastruktur.