I sidste uge lavede jeg et par hurtige præstationssammenligninger, hvor jeg brugte den nye STRING_AGG() funktion mod den traditionelle FOR XML PATH tilgang jeg har brugt i evigheder. Jeg testede både udefineret/vilkårlig rækkefølge såvel som eksplicit rækkefølge og STRING_AGG() kom ud på toppen i begge tilfælde:
- SQL Server v.Next :STRING_AGG() Performance, del 1
Til disse test udelod jeg flere ting (ikke alle med vilje):
- Mikael Eriksson og Grzegorz Łyp påpegede begge, at jeg ikke brugte den absolut mest effektive
FOR XML PATHkonstruere (og for at være klar, det har jeg aldrig). - Jeg udførte ingen test på Linux; kun på Windows. Jeg forventer ikke, at de er meget forskellige, men da Grzegorz så meget forskellige varigheder, er det værd at undersøge nærmere.
- Jeg testede også kun, når output ville være en endelig, ikke-LOB-streng – hvilket jeg mener er det mest almindelige anvendelsestilfælde (jeg tror ikke, folk normalt vil sammenkæde hver række i en tabel i en enkelt kommasepareret streng, men det er derfor, jeg i mit tidligere indlæg bad om din(e) use case(s)).
- Til bestillingstesten oprettede jeg ikke et indeks, der kunne være nyttigt (eller prøvede noget, hvor alle data kom fra en enkelt tabel).
I dette indlæg vil jeg beskæftige mig med et par af disse genstande, men ikke dem alle.
TIL XML-STI
Jeg havde brugt følgende:
... FOR XML PATH, TYPE).value(N'.[1]', ...
Efter denne kommentar fra Mikael har jeg opdateret min kode til at bruge denne lidt anderledes konstruktion i stedet:
... FOR XML PATH(''), TYPE).value(N'text()[1]', ... Linux vs. Windows
I starten havde jeg kun gidet at køre test på Windows:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. Developer Edition (64-bit) on Windows Server 2016 Datacenter 6.3(Build 14393: ) (Hypervisor)
Men Grzegorz gjorde en fair pointe, at han (og formentlig mange andre) kun havde adgang til Linux-varianten af CTP 1.1. Så jeg tilføjede Linux til min testmatrix:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. on Linux (Ubuntu 16.04.1 LTS)
Nogle interessante, men fuldstændig tangentielle observationer:
@@VERSIONviser ikke udgaven i denne build, menSERVERPROPERTY('Edition')returnerer den forventedeDeveloper Edition (64-bit).- Baseret på de byggetider, der er kodet ind i binære filer, ser det ud til, at Windows- og Linux-versionerne nu er kompileret på samme tid og fra den samme kilde. Eller dette var en skør tilfældighed.
Uordrede tests
Jeg startede med at teste det vilkårligt ordnede output (hvor der ikke er nogen eksplicit defineret rækkefølge for de sammenkædede værdier). Efter Grzegorz brugte jeg WideWorldImporters (Standard), men udførte en joinforbindelse mellem Sales.Orders og Sales.OrderLines . Det fiktive krav her er at udskrive en liste over alle ordrer og sammen med hver ordre en kommasepareret liste over hver StockItemID .
Siden StockItemID er et heltal, kan vi bruge en defineret varchar , hvilket betyder, at strengen kan være på 8000 tegn, før vi skal bekymre os om at have brug for MAX. Da en int kan være en maks. længde på 11 (virkelig 10, hvis usigneret), plus et komma, betyder det, at en ordre skal understøtte omkring 8.000/12 (666) lagervarer i værste fald (f.eks. har alle StockItemID-værdier 11 cifre). I vores tilfælde er det længste ID 3 cifre, så indtil data bliver tilføjet, ville vi faktisk have brug for 8.000/4 (2.000) unikke lagervarer i en enkelt ordre for at retfærdiggøre MAX. I vores tilfælde er der kun 227 lagervarer i alt, så MAX er ikke nødvendigt, men det skal du holde øje med. Hvis en så stor streng er mulig i dit scenarie, skal du bruge varchar(max) i stedet for standarden (STRING_AGG() returnerer nvarchar(max) , men afkortes til 8.000 bytes, medmindre input er en MAX-type).
De indledende forespørgsler (for at vise eksempeloutput og for at observere varigheder for enkeltudførelser):
SET STATISTICS TIME ON;
GO
SELECT o.OrderID, StockItemIDs = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT o.OrderID,
StockItemIDs = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Sample output:
OrderID StockItemIDs
======= ============
1 67
2 50,10
3 114
4 206,130,50
5 128,121,155
Important SET STATISTICS TIME metrics (SQL Server Execution Times):
Windows:
STRING_AGG: CPU time = 217 ms, elapsed time = 405 ms.
FOR XML PATH: CPU time = 1954 ms, elapsed time = 2097 ms.
Linux:
STRING_AGG: CPU time = 627 ms, elapsed time = 472 ms.
FOR XML PATH: CPU time = 2188 ms, elapsed time = 2223 ms.
*/
Jeg ignorerede parse og kompilering af tidsdata fuldstændigt, da de altid var nøjagtig nul eller tæt nok på til at være irrelevante. Der var mindre afvigelser i udførelsestiderne for hver kørsel, men ikke meget – kommentarerne ovenfor afspejler det typiske delta i kørselstid (STRING_AGG syntes at drage lidt fordel af parallelitet der, men kun på Linux, mens FOR XML PATH ikke på nogen af platformene). Begge maskiner havde en enkelt socket, quad-core CPU allokeret, 8 GB hukommelse, out-of-the-box konfiguration og ingen anden aktivitet.
Så ville jeg teste i skala (simpelthen en enkelt session, der udfører den samme forespørgsel 500 gange). Jeg ønskede ikke at returnere alt output, som i ovenstående forespørgsel, 500 gange, da det ville have overvældet SSMS – og forhåbentlig ikke repræsenterer virkelige forespørgselsscenarier alligevel. Så jeg tildelte outputtet til variabler og målte bare den samlede tid for hver batch:
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID, @x = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID,
@x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); Jeg kørte de test tre gange, og forskellen var stor - næsten en størrelsesorden. Her er den gennemsnitlige varighed på tværs af de tre tests:
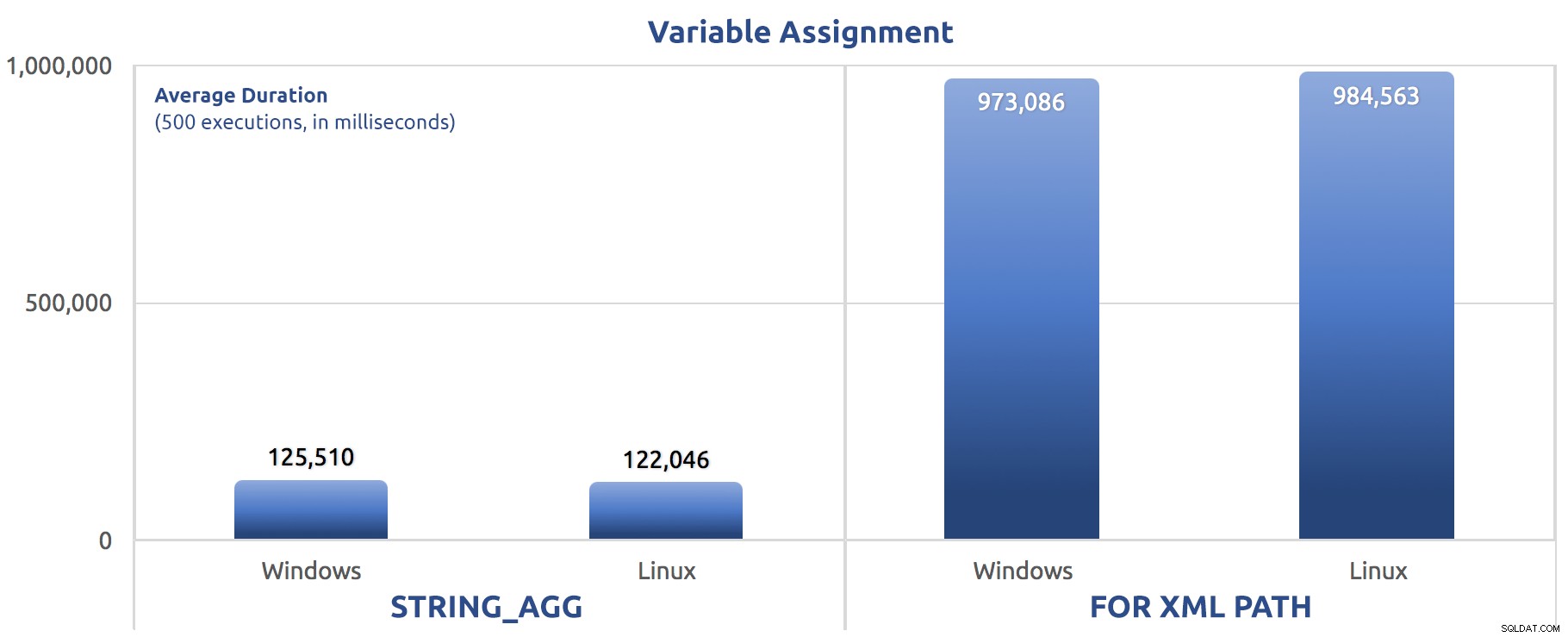 Gennemsnitlig varighed, i millisekunder, for 500 udførelser af variabel tildeling
Gennemsnitlig varighed, i millisekunder, for 500 udførelser af variabel tildeling
Jeg testede også en række andre ting på denne måde, mest for at sikre mig, at jeg dækkede de typer test, Grzegorz kørte (uden LOB-delen).
- Vælger kun længden af output
- Hent den maksimale længde af output (af en vilkårlig række)
- Valg af alt output i en ny tabel
Vælg kun længden af output
Denne kode løber blot gennem hver ordre, sammenkæder alle StockItemID-værdier og returnerer derefter kun længden.
SET STATISTICS TIME ON;
GO
SELECT LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 142 ms, elapsed time = 351 ms.
FOR XML PATH: CPU time = 1984 ms, elapsed time = 2120 ms.
Linux:
STRING_AGG: CPU time = 310 ms, elapsed time = 191 ms.
FOR XML PATH: CPU time = 2149 ms, elapsed time = 2167 ms.
*/ Til batchversionen brugte jeg igen variabel tildeling i stedet for at prøve at returnere mange resultatsæt til SSMS. Variabeltildelingen ville ende på en vilkårlig række, men dette kræver stadig fuld scanning, fordi den vilkårlige række ikke er valgt først.
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); Ydeevnemålinger for 500 eksekveringer:
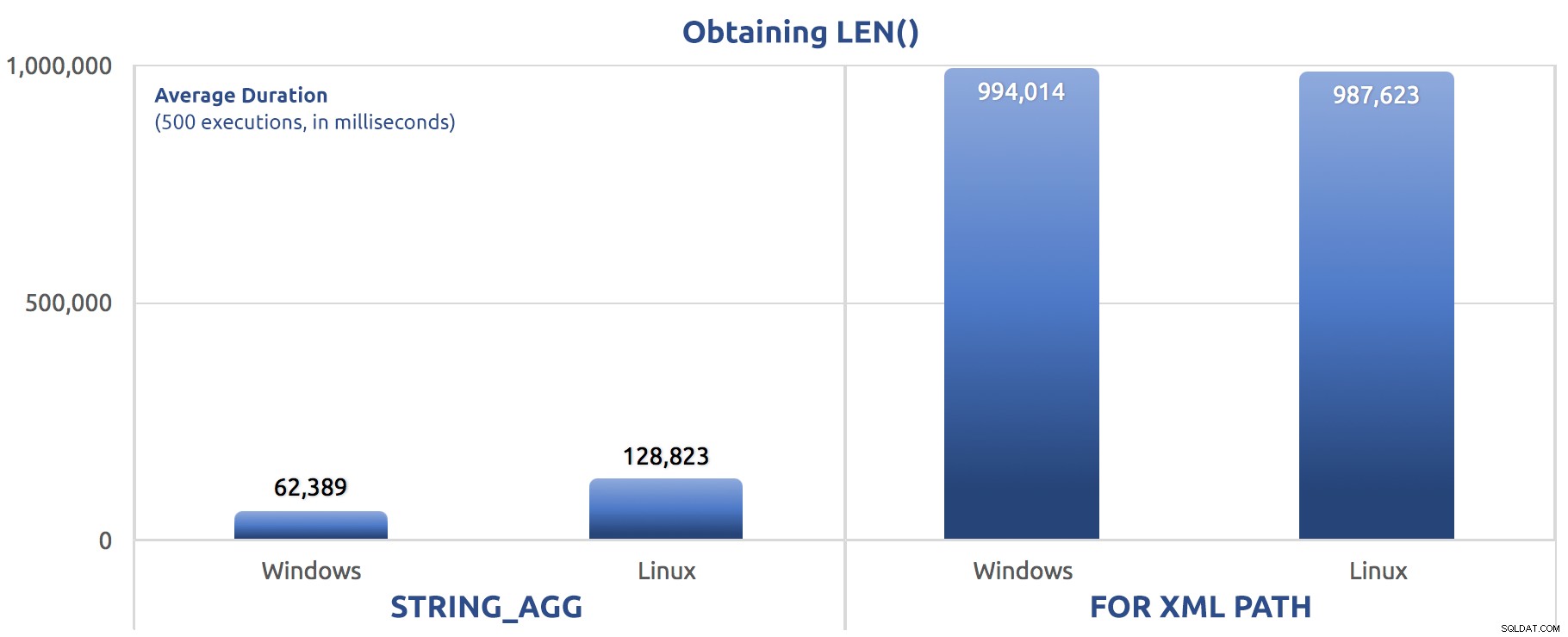 500 udførelser af tildeling af LEN() til en variabel
500 udførelser af tildeling af LEN() til en variabel
Igen ser vi FOR XML PATH er langt langsommere, både på Windows og Linux.
Valg af den maksimale længde af output
En lille variation i forhold til den forrige test, denne henter bare maksimum længden af det sammenkædede output:
SET STATISTICS TIME ON;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STUFF(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 188 ms, elapsed time = 48 ms.
FOR XML PATH: CPU time = 1891 ms, elapsed time = 907 ms.
Linux:
STRING_AGG: CPU time = 270 ms, elapsed time = 83 ms.
FOR XML PATH: CPU time = 2725 ms, elapsed time = 1205 ms.
*/ Og i skala tildeler vi bare det output til en variabel igen:
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STUFF
(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime(); Ydeevneresultater for 500 henrettelser var i gennemsnit over tre kørsler:
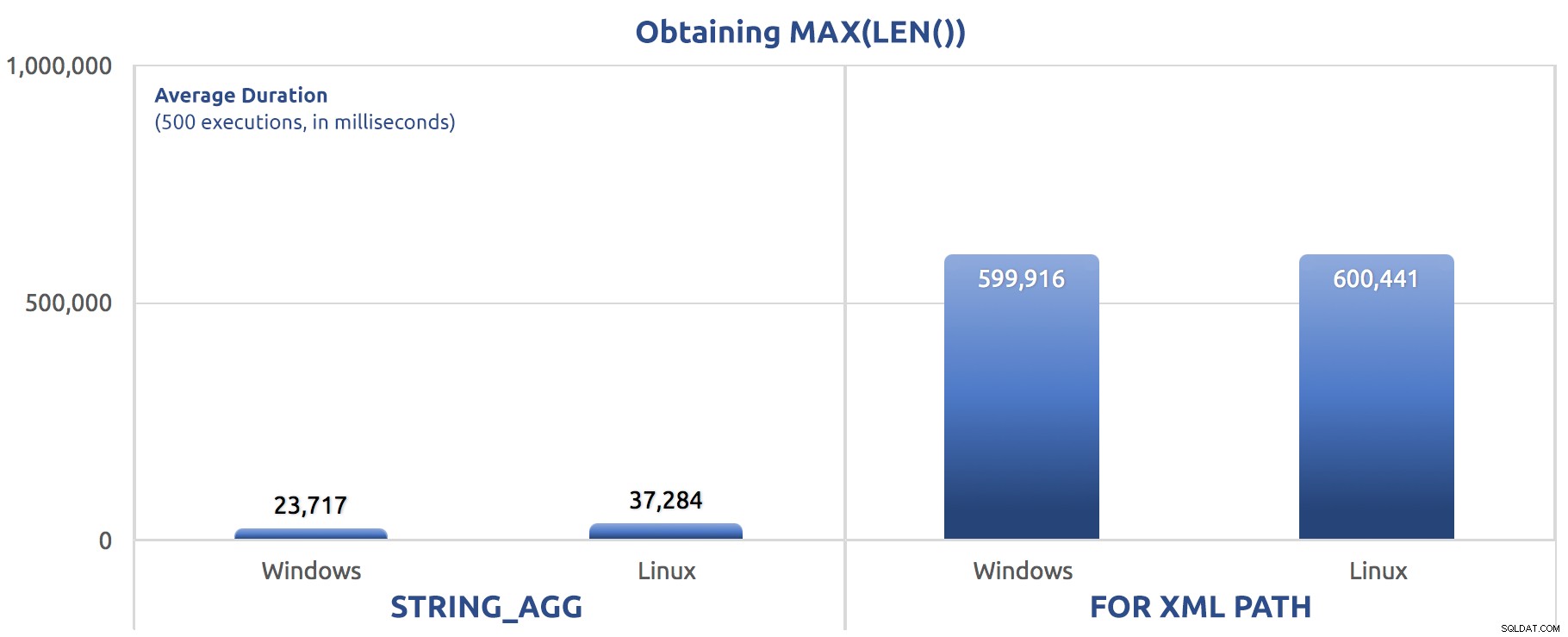 500 udførelser af tildeling af MAX(LEN()) til en variabel
500 udførelser af tildeling af MAX(LEN()) til en variabel
Du begynder måske at bemærke et mønster på tværs af disse tests – FOR XML PATH er altid en hund, selv med de præstationsforbedringer, der blev foreslået i mit tidligere indlæg.
VÆLG TIL
Jeg ville se, om sammenkædningsmetoden havde nogen indflydelse på skrivning dataene tilbage til disken, som det er tilfældet i nogle andre scenarier:
SET NOCOUNT ON;
GO
SET STATISTICS TIME ON;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_AGG;
SELECT o.OrderID, x = STRING_AGG(ol.StockItemID, ',')
INTO dbo.HoldingTank_AGG
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_XML;
SELECT o.OrderID, x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
INTO dbo.HoldingTank_XML
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 218 ms, elapsed time = 90 ms.
FOR XML PATH: CPU time = 4202 ms, elapsed time = 1520 ms.
Linux:
STRING_AGG: CPU time = 277 ms, elapsed time = 108 ms.
FOR XML PATH: CPU time = 4308 ms, elapsed time = 1583 ms.
*/
I dette tilfælde ser vi, at måske SELECT INTO var i stand til at drage fordel af en smule parallelitet, men alligevel ser vi FOR XML PATH kamp, med kørselstider en størrelsesorden længere end STRING_AGG .
Den batchede version har lige udskiftet SET STATISTICS-kommandoerne for SELECT sysdatetime(); og tilføjede den samme GO 500 efter de to hovedpartier som ved de foregående tests. Her er, hvordan det gik (igen, fortæl mig, hvis du har hørt denne før):
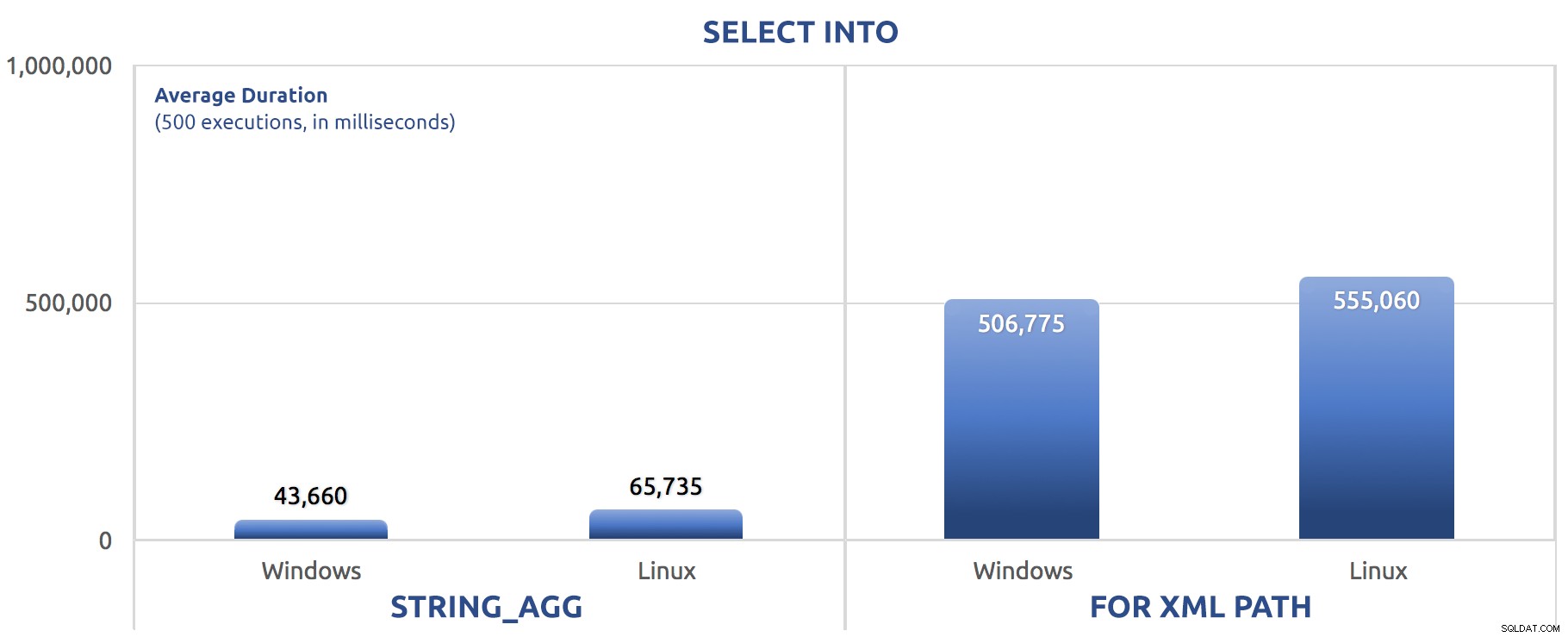 500 eksekveringer af SELECT INTO
500 eksekveringer af SELECT INTO
Bestilte test
Jeg kørte de samme tests ved hjælp af den ordnede syntaks, f.eks.:
... STRING_AGG(ol.StockItemID, ',')
WITHIN GROUP (ORDER BY ol.StockItemID) ...
... WHERE ol.OrderID = o.OrderID
ORDER BY ol.StockItemID
FOR XML PATH('') ... Dette havde meget lille indflydelse på noget som helst – det samme sæt af fire testrigge viste næsten identiske metrikker og mønstre over hele linjen.
Jeg vil være nysgerrig efter at se, om dette er anderledes, når det sammenkædede output er i ikke-LOB, eller hvor sammenkædningen skal bestille strenge (med eller uden et understøttende indeks).
Konklusion
For ikke-LOB-strenge , er det klart for mig, at STRING_AGG har en endegyldig fordel i forhold til FOR XML PATH , på både Windows og Linux. Bemærk, at for at undgå kravet om varchar(max) eller nvarchar(max) , Jeg brugte ikke noget, der ligner de test, Grzegorz kørte, hvilket ville have betydet, at alle værdierne fra en kolonne, på tværs af en hel tabel, blev sat sammen i en enkelt streng. I mit næste indlæg vil jeg tage et kig på brugssituationen, hvor outputtet af den sammenkædede streng muligvis kunne være større end 8.000 bytes, og så LOB-typer og konverteringer skulle bruges.