Tilbage i 2012 skrev jeg et blogindlæg her, hvor jeg fremhævede metoder til at beregne en median. I det indlæg beskæftigede jeg mig med den meget simple sag:Vi ønskede at finde medianen af en kolonne på tværs af en hel tabel. Det er blevet nævnt for mig flere gange siden da, at et mere praktisk krav er at beregne en opdelt median . Ligesom med det grundlæggende tilfælde er der flere måder at løse dette på i forskellige versioner af SQL Server; ikke overraskende, nogle klarer sig meget bedre end andre.
I det forrige eksempel havde vi bare generiske kolonner id og val. Lad os gøre dette mere realistisk og sige, at vi har sælgere og antallet af salg, de har foretaget i en periode. For at teste vores forespørgsler, lad os først oprette en simpel bunke med 17 rækker og kontrollere, at de alle producerer de resultater, vi forventer (SalesPerson 1 har en median på 7,5, og SalesPerson 2 har en median på 6,0):
CREATE TABLE dbo.Sales(SalesPerson INT, Amount INT); GO INSERT dbo.Sales WITH (TABLOCKX) (SalesPerson, Amount) VALUES (1, 6 ),(1, 11),(1, 4 ),(1, 4 ), (1, 15),(1, 14),(1, 4 ),(1, 9 ), (2, 6 ),(2, 11),(2, 4 ),(2, 4 ), (2, 15),(2, 14),(2, 4 );
Her er forespørgslerne, som vi skal teste (med meget flere data!) mod bunken ovenfor, såvel som med understøttende indekser. Jeg har kasseret et par forespørgsler fra den forrige test, som enten slet ikke blev skaleret eller ikke var knyttet særlig godt til partitionerede medianer (nemlig 2000_B, som brugte en #temp-tabel, og 2005_A, som brugte modstående række tal). Jeg har dog tilføjet et par interessante ideer fra en nylig artikel af Dwain Camps (@DwainCSQL), som byggede på mit tidligere indlæg.
SQL Server 2000+
Den eneste metode fra den tidligere tilgang, der fungerede godt nok på SQL Server 2000 til overhovedet at inkludere den i denne test, var "minimum af den ene halvdel, max af den anden" tilgang:
SELECT DISTINCT s.SalesPerson, Median = (
(SELECT MAX(Amount) FROM
(SELECT TOP 50 PERCENT Amount FROM dbo.Sales
WHERE SalesPerson = s.SalesPerson ORDER BY Amount) AS t)
+ (SELECT MIN(Amount) FROM
(SELECT TOP 50 PERCENT Amount FROM dbo.Sales
WHERE SalesPerson = s.SalesPerson ORDER BY Amount DESC) AS b)
) / 2.0
FROM dbo.Sales AS s; Jeg forsøgte ærligt talt at efterligne #temp table-versionen, som jeg brugte i det mere simple eksempel, men den skaleres slet ikke godt. Ved 20 eller 200 rækker fungerede det fint; ved 2000 tog det næsten et minut; ved 1.000.000 gav jeg op efter en time. Jeg har inkluderet det her for eftertiden (klik for at afsløre).
CREATE TABLE #x
(
i INT IDENTITY(1,1),
SalesPerson INT,
Amount INT,
i2 INT
);
CREATE CLUSTERED INDEX v ON #x(SalesPerson, Amount);
INSERT #x(SalesPerson, Amount)
SELECT SalesPerson, Amount
FROM dbo.Sales
ORDER BY SalesPerson,Amount OPTION (MAXDOP 1);
UPDATE x SET i2 = i-
(
SELECT COUNT(*) FROM #x WHERE i <= x.i
AND SalesPerson < x.SalesPerson
)
FROM #x AS x;
SELECT SalesPerson, Median = AVG(0. + Amount)
FROM #x AS x
WHERE EXISTS
(
SELECT 1
FROM #x
WHERE SalesPerson = x.SalesPerson
AND x.i2 - (SELECT MAX(i2) / 2.0 FROM #x WHERE SalesPerson = x.SalesPerson)
IN (0, 0.5, 1)
)
GROUP BY SalesPerson;
GO
DROP TABLE #x; SQL Server 2005+ 1
Dette bruger to forskellige vinduesfunktioner til at udlede en rækkefølge og et samlet antal af beløb pr. sælger.
SELECT SalesPerson, Median = AVG(1.0*Amount)
FROM
(
SELECT SalesPerson, Amount, rn = ROW_NUMBER() OVER
(PARTITION BY SalesPerson ORDER BY Amount),
c = COUNT(*) OVER (PARTITION BY SalesPerson)
FROM dbo.Sales
)
AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2)
GROUP BY SalesPerson; SQL Server 2005+ 2
Dette kom fra Dwain Camps' artikel, som gør det samme som ovenfor, på en lidt mere udførlig måde. Dette fjerner dybest set de interessante række(r) i hver gruppe.
;WITH Counts AS
(
SELECT SalesPerson, c
FROM
(
SELECT SalesPerson, c1 = (c+1)/2,
c2 = CASE c%2 WHEN 0 THEN 1+c/2 ELSE 0 END
FROM
(
SELECT SalesPerson, c=COUNT(*)
FROM dbo.Sales
GROUP BY SalesPerson
) a
) a
CROSS APPLY (VALUES(c1),(c2)) b(c)
)
SELECT a.SalesPerson, Median=AVG(0.+b.Amount)
FROM
(
SELECT SalesPerson, Amount, rn = ROW_NUMBER() OVER
(PARTITION BY SalesPerson ORDER BY Amount)
FROM dbo.Sales a
) a
CROSS APPLY
(
SELECT Amount FROM Counts b
WHERE a.SalesPerson = b.SalesPerson AND a.rn = b.c
) b
GROUP BY a.SalesPerson; SQL Server 2005+ 3
Dette var baseret på et forslag fra Adam Machanic i kommentarerne til mit tidligere indlæg, og også forbedret af Dwain i hans artikel ovenfor.
;WITH Counts AS
(
SELECT SalesPerson, c = COUNT(*)
FROM dbo.Sales
GROUP BY SalesPerson
)
SELECT a.SalesPerson, Median = AVG(0.+Amount)
FROM Counts a
CROSS APPLY
(
SELECT TOP (((a.c - 1) / 2) + (1 + (1 - a.c % 2)))
b.Amount, r = ROW_NUMBER() OVER (ORDER BY b.Amount)
FROM dbo.Sales b
WHERE a.SalesPerson = b.SalesPerson
ORDER BY b.Amount
) p
WHERE r BETWEEN ((a.c - 1) / 2) + 1 AND (((a.c - 1) / 2) + (1 + (1 - a.c % 2)))
GROUP BY a.SalesPerson; SQL Server 2005+ 4
Dette ligner "2005+ 1" ovenfor, men i stedet for at bruge COUNT(*) OVER() for at udlede tællingerne, udfører den en selvsammenføjning mod et isoleret aggregat i en afledt tabel.
SELECT SalesPerson, Median = AVG(1.0 * Amount)
FROM
(
SELECT s.SalesPerson, s.Amount, rn = ROW_NUMBER() OVER
(PARTITION BY s.SalesPerson ORDER BY s.Amount), c.c
FROM dbo.Sales AS s
INNER JOIN
(
SELECT SalesPerson, c = COUNT(*)
FROM dbo.Sales GROUP BY SalesPerson
) AS c
ON s.SalesPerson = c.SalesPerson
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2)
GROUP BY SalesPerson; SQL Server 2012+ 1
Dette var et meget interessant bidrag fra andre SQL Server MVP Peter "Peso" Larsson (@SwePeso) i kommentarerne til Dwains artikel; den bruger CROSS APPLY og den nye OFFSET / FETCH funktionalitet på en endnu mere interessant og overraskende måde end Itziks løsning på den enklere medianberegning.
SELECT d.SalesPerson, w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w(Median); SQL Server 2012+ 2
Endelig har vi den nye PERCENTILE_CONT() funktion introduceret i SQL Server 2012.
SELECT SalesPerson, Median = MAX(Median)
FROM
(
SELECT SalesPerson,Median = PERCENTILE_CONT(0.5) WITHIN GROUP
(ORDER BY Amount) OVER (PARTITION BY SalesPerson)
FROM dbo.Sales
)
AS x
GROUP BY SalesPerson; De rigtige tests
For at teste ydeevnen af ovenstående forespørgsler vil vi bygge en meget mere omfattende tabel. Vi kommer til at have 100 unikke sælgere med 10.000 salgsbeløb hver, for i alt 1.000.000 rækker. Vi kommer også til at køre hver forespørgsel mod heapen, som den er, med et tilføjet ikke-klynget indeks på (SalesPerson, Amount) , og med et klynget indeks på de samme kolonner. Her er opsætningen:
CREATE TABLE dbo.Sales(SalesPerson INT, Amount INT); GO --CREATE CLUSTERED INDEX x ON dbo.Sales(SalesPerson, Amount); --CREATE NONCLUSTERED INDEX x ON dbo.Sales(SalesPerson, Amount); --DROP INDEX x ON dbo.sales; ;WITH x AS ( SELECT TOP (100) number FROM master.dbo.spt_values GROUP BY number ) INSERT dbo.Sales WITH (TABLOCKX) (SalesPerson, Amount) SELECT x.number, ABS(CHECKSUM(NEWID())) % 99 FROM x CROSS JOIN x AS x2 CROSS JOIN x AS x3;
Og her er resultaterne af ovenstående forespørgsler mod heapen, det ikke-klyngede indeks og det klyngede indeks:
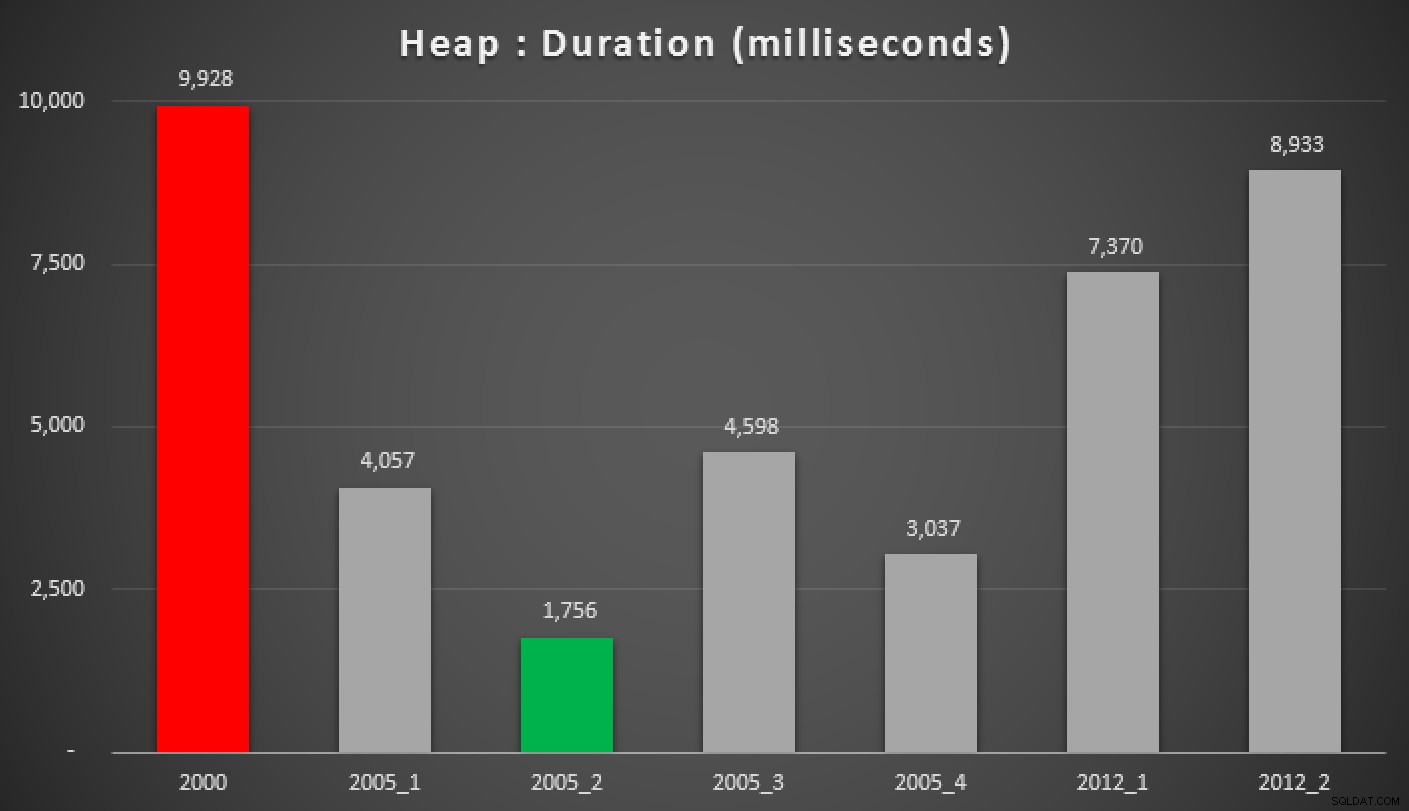
Varighed, i millisekunder, af forskellige grupperede mediantilgange (mod en bunke)
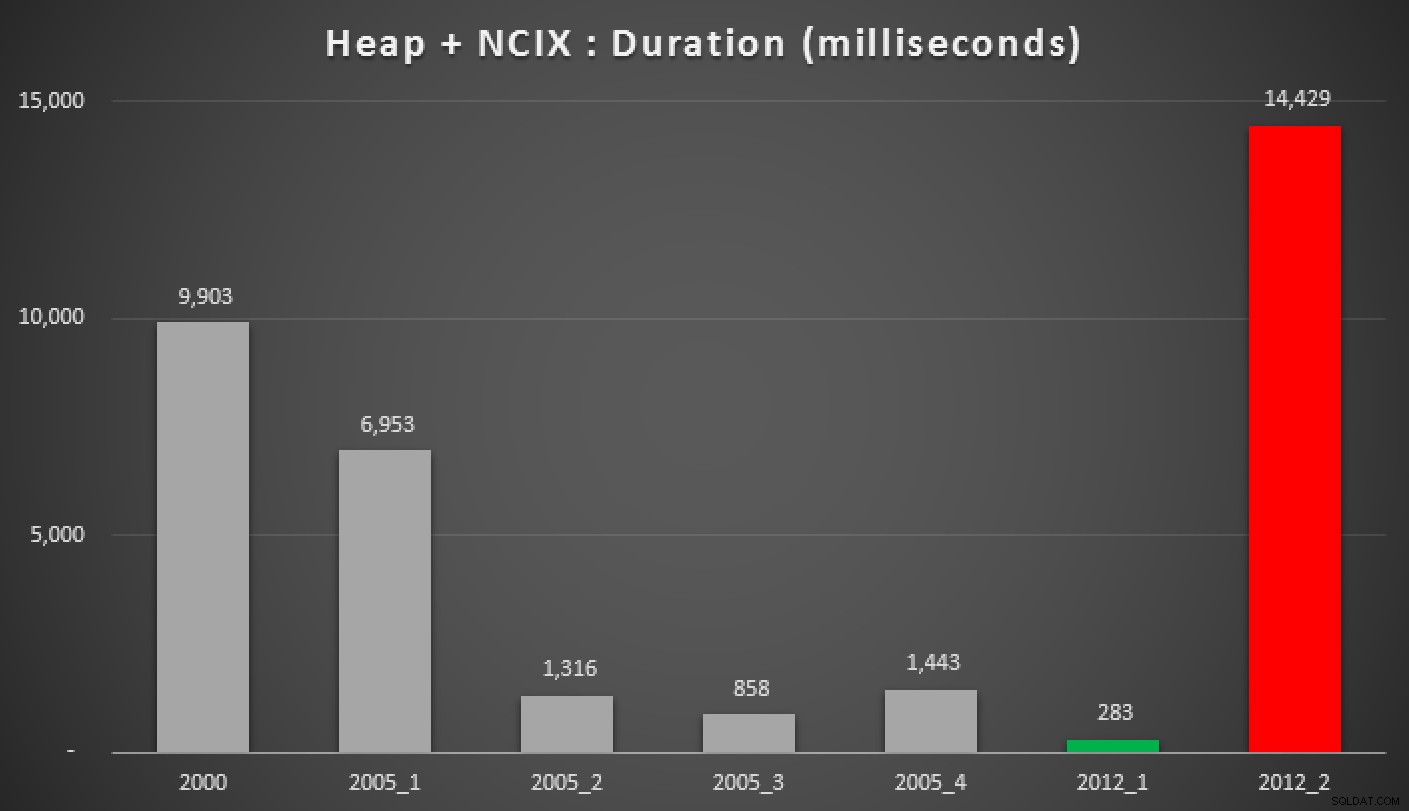
Varighed, i millisekunder, af forskellige grupperede mediantilgange (mod en bunke med et ikke-klynget indeks)
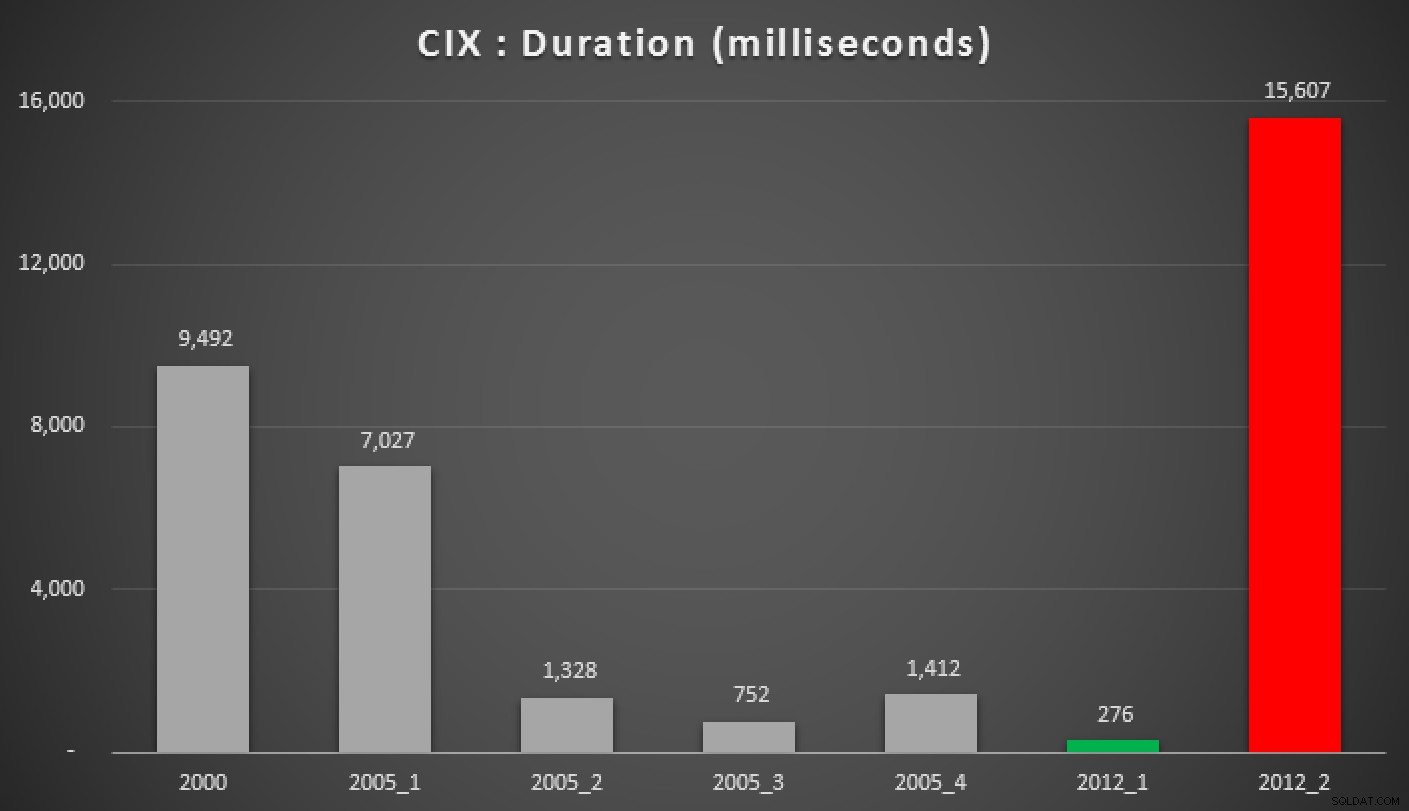
Varighed, i millisekunder, af forskellige grupperede mediantilgange (mod en klynget indeks)
Hvad med Hekaton?
Jeg var naturligvis nysgerrig, om denne nye funktion i SQL Server 2014 kunne hjælpe med nogen af disse forespørgsler. Så jeg oprettede en In-Memory-database, to In-Memory-versioner af Sales-tabellen (en med et hash-indeks på (SalesPerson, Amount) , og den anden på bare (SalesPerson) ), og kørte de samme tests igen:
CREATE DATABASE Hekaton; GO ALTER DATABASE Hekaton ADD FILEGROUP xtp CONTAINS MEMORY_OPTIMIZED_DATA; GO ALTER DATABASE Hekaton ADD FILE (name = 'xtp', filename = 'c:\temp\hek.mod') TO FILEGROUP xtp; GO ALTER DATABASE Hekaton SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT ON; GO USE Hekaton; GO CREATE TABLE dbo.Sales1 ( ID INT IDENTITY(1,1) PRIMARY KEY NONCLUSTERED, SalesPerson INT NOT NULL, Amount INT NOT NULL, INDEX x NONCLUSTERED HASH (SalesPerson, Amount) WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); GO CREATE TABLE dbo.Sales2 ( ID INT IDENTITY(1,1) PRIMARY KEY NONCLUSTERED, SalesPerson INT NOT NULL, Amount INT NOT NULL, INDEX x NONCLUSTERED HASH (SalesPerson) WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); GO ;WITH x AS ( SELECT TOP (100) number FROM master.dbo.spt_values GROUP BY number ) INSERT dbo.Sales1 (SalesPerson, Amount) -- TABLOCK/TABLOCKX not allowed here SELECT x.number, ABS(CHECKSUM(NEWID())) % 99 FROM x CROSS JOIN x AS x2 CROSS JOIN x AS x3; INSERT dbo.Sales2 (SalesPerson, Amount) SELECT SalesPerson, Amount FROM dbo.Sales1;
Resultaterne:
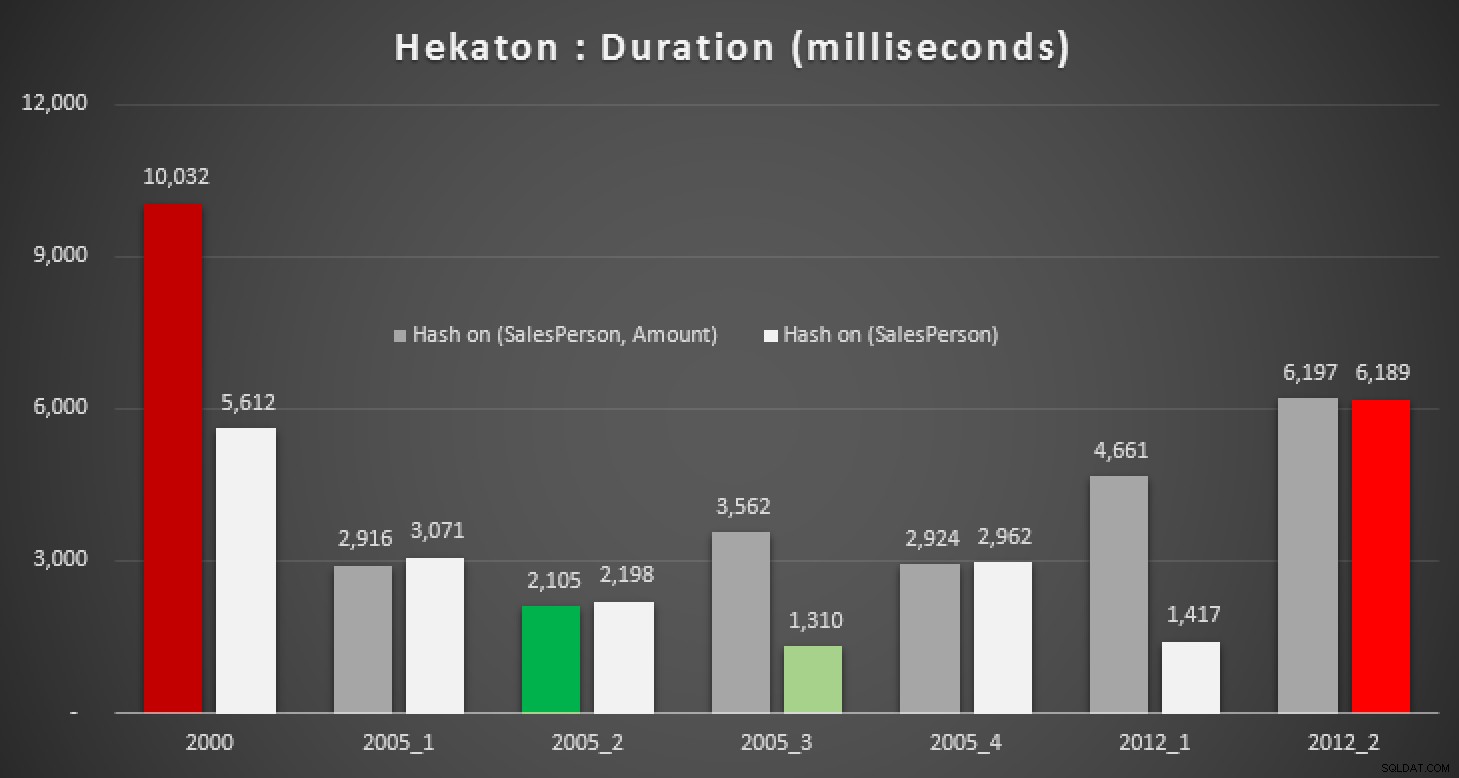
Varighed, i millisekunder, for forskellige medianberegninger mod In-Memory tabeller
Selv med det rigtige hash-indeks ser vi ikke rigtig væsentlige forbedringer i forhold til en traditionel tabel. Derudover vil det ikke være en let opgave at prøve at løse medianproblemet ved hjælp af en native-kompileret lagret procedure, da mange af de sprogkonstruktioner, der er brugt ovenfor, ikke er gyldige (jeg var også overrasket over et par af disse). Forsøg på at kompilere alle ovenstående forespørgselsvarianter gav denne parade af fejl; nogle forekom flere gange inden for hver procedure, og selv efter at have fjernet dubletter, er dette stadig lidt komisk:
Msg 10794, Level 16, State 47, Procedure GroupedMedian_2000Indstillingen 'DISTINCT' understøttes ikke med indbyggede kompilerede lagrede procedurer.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2000queries ( forespørgsler indlejret i en anden forespørgsel) understøttes ikke med oprindeligt kompilerede lagrede procedurer.
Besked 10794, niveau 16, tilstand 48, Procedure GroupedMedian_2000
Indstillingen 'PERCENT' understøttes ikke med oprindeligt kompilerede lagrede procedurer.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2005_1
Underforespørgsler (forespørgsler indlejret i en anden forespørgsel) understøttes ikke med oprindeligt kompilerede lagrede procedurer.
Msg 10794, Level 16, State 91 , Procedure GroupedMedian_2005_1
Den aggregerede funktion 'ROW_NUMBER' understøttes ikke med oprindeligt kompilerede lagrede procedurer.
Besked 10794, niveau 16, tilstand 56, Procedure GroupedMedian_2005_1
Operatøren 'IN' understøttes ikke native kompilerede lagrede procedurer.
Msg 12310, Niveau 16, State 36, Procedure GroupedMedian_2005_2
Common Table Expressions (CTE) understøttes ikke med native kompilerede lagrede procedurer.
Msg 12309, Level 16, State 35, Procedure GroupedMedian_2005_2
INSERT…VALUES…, der indsætter flere rækker, understøttes ikke med native kompilerede lagrede procedurer.
Msg 10794, Level 16, State 53, Procedure GroupedMedian_2005_2
Operatøren 'APPLY' er ikke understøttet med native kompilerede lagrede procedurer.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2005_2
Underforespørgsler (forespørgsler indlejret i en anden forespørgsel) understøttes ikke med oprindeligt kompilerede lagrede procedurer.
Msg 10794, Level 16, Procedure State 91 GroupedMedian_2005_2
Aggregeringsfunktionen 'ROW_NUMBER' understøttes ikke med indbyggede kompilerede lagrede procedurer.
Msg 12310, Level 16, State 36, Procedure GroupedMedian_2005_3
Common Table Expressions (CTE) er almindelige tabeludtryk (CTE) understøttes ikke med indbygget kompilerede lagrede procedurer.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2005_3
Underforespørgsler (forespørgsler indlejret i en anden forespørgsel) understøttes ikke med indbygget kompilerede lagrede procedurer.
Msg 10794, Level 16, State , Procedure GroupedMedian_2005_3
Den aggregerede funktion 'ROW_NUMBER' er ikke understøttet med indbygget kompilerede lagrede procedurer.
Besked 10794, niveau 16, tilstand 53, Procedure GroupedMedian_2005_3
Operatøren 'APPLY' er ikke understøttet med native kompilerede lagrede procedurer.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2005_4
Underforespørgsler (forespørgsler indlejret i en anden forespørgsel) understøttes ikke med native kompilerede lagrede procedurer.
Msg 10794, Level 16, State 91, Procedure GroupedMedian_2005_4
Aggregeringsfunktionen 'ROW_NUMBER' er ikke understøttet med indbyggede kompilerede lagrede procedurer.
Besked 10794, Level 16, State 56, Procedure GroupedMedian-operatoren /5_
5__20 'IN' understøttes ikke med indbygget kompileret stor red procedurer.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2012_1
Underforespørgsler (forespørgsler indlejret i en anden forespørgsel) understøttes ikke med indbygget kompilerede lagrede procedurer.
Msg 10794, Niveau 16, tilstand 38, Procedure GroupedMedian_2012_1
Operatøren 'OFFSET' understøttes ikke med oprindeligt kompilerede lagrede procedurer.
Besked 10794, Niveau 16, State 53, Procedure GroupedMedian_2012_1
Operatøren 'APPLY understøttes ikke med native kompilerede lagrede procedurer.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2012_2
Underforespørgsler (forespørgsler indlejret i en anden forespørgsel) understøttes ikke med native kompilerede lagrede procedurer.
Msg 10794, Level 16, State 90, Procedure GroupedMedian_2012_2
Aggregeringsfunktionen 'PERCENTILE_CONT' understøttes ikke med oprindeligt kompilerede lagrede procedurer.
Som skrevet i øjeblikket, kunne ikke én af disse forespørgsler overføres til en native-kompileret lagret procedure. Måske noget at se nærmere på for endnu et opfølgende indlæg.
Konklusion
Kassering af Hekaton-resultaterne, og når et understøttende indeks er til stede, Peter Larssons forespørgsel ("2012+ 1") ved hjælp af OFFSET/FETCH kom ud som den fjern-og-væk-vinder i disse tests. Selvom det var lidt mere komplekst end den tilsvarende forespørgsel i de ikke-opdelte test, matchede dette de resultater, jeg observerede sidste gang.
I de samme tilfælde er 2000 MIN/MAX tilgang og 2012's PERCENTILE_CONT() kom ud som rigtige hunde; igen, ligesom mine tidligere tests mod det enklere tilfælde.
Hvis du ikke er på SQL Server 2012 endnu, så er din næstbedste mulighed "2005+ 3" (hvis du har et understøttende indeks) eller "2005+ 2", hvis du har at gøre med en heap. Beklager, jeg var nødt til at finde på et nyt navneskema for disse, mest for at undgå forvirring med metoderne i mit tidligere indlæg.
Dette er selvfølgelig mine resultater i forhold til et meget specifikt skema og datasæt – som med alle anbefalinger bør du teste disse tilgange mod dit skema og data, da andre faktorer kan påvirke forskellige resultater.
En anden bemærkning
Ud over at være en dårlig performer og ikke understøttes i oprindeligt kompilerede lagrede procedurer, er der et andet smertepunkt på PERCENTILE_CONT() er, at det ikke kan bruges i ældre kompatibilitetstilstande. Hvis du prøver, får du denne fejlmeddelelse:
PERCENTILE_CONT-funktionen er ikke tilladt i den aktuelle kompatibilitetstilstand. Det er kun tilladt i 110-tilstand eller højere.