Mens SQL Server på Linux har stjålet næsten alle overskrifterne om v.Next, er der nogle andre interessante fremskridt, der kommer i den næste version af vores foretrukne databaseplatform. På T-SQL-fronten har vi endelig en indbygget måde at udføre grupperet strengsammenkædning på:STRING_AGG() .
Lad os sige, at vi har følgende enkle tabelstruktur:
CREATE TABLE dbo.Objects( [object_id] int, [object_name] nvarchar(261), CONSTRAINT PK_Objects PRIMARY KEY([object_id])); OPRET TABEL dbo.Columns( [object_id] int NOT NULL UDENLANDSKE NØGLEREFERENCER dbo.Objects([object_id]), column_name sysname, CONSTRAINT PK_Columns PRIMARY KEY ([object_id],column_name));
Til ydeevnetest skal vi udfylde dette ved hjælp af sys.all_objects og sys.all_columns . Men for en simpel demonstration først, lad os tilføje følgende rækker:
INSERT dbo.Objects([object_id],[object_name]) VALUES(1,N'Employees'),(2,N'Orders'); INSERT dbo.Columns([object_id],column_name) VALUES(1,N'EmployeeID'),(1,N'CurrentStatus'), (2,N'OrderID'),(2,N'OrderDate'),(2 ,N'CustomerID');
Hvis foraene er nogen indikation, er det et meget almindeligt krav at returnere en række for hvert objekt sammen med en kommasepareret liste over kolonnenavne. (Ekstrapoler det til enhver enhedstype, du modellerer på denne måde – produktnavne forbundet med en ordre, delnavne involveret i samlingen af et produkt, underordnede, der rapporterer til en leder osv.) Så for eksempel med ovenstående data ville vi ønsker output som dette:
objektkolonner--------- ----------------------------Medarbejdere EmployeeID,CurrentStatusOrders OrderID,OrderDate, Kunde-id
Den måde, vi ville opnå dette på i nuværende versioner af SQL Server, er sandsynligvis ved at bruge FOR XML PATH , som jeg demonstrerede at være den mest effektive uden for CLR i dette tidligere indlæg. I dette eksempel ville det se sådan ud:
VÆLG [objekt] =o.[objekt_navn], [kolonner] =TING(((SELECT N',' + c.column_name FROM dbo.Columns AS c WHERE c.[object_id] =o.[object_id] FOR XML PATH, TYPE ).value(N'.[1]',N'nvarchar(max)'),1,1,N'')FRA dbo.Objects AS o;
Forudsigeligt får vi det samme output som vist ovenfor. I SQL Server v.Next vil vi være i stand til at udtrykke dette mere enkelt:
VÆLG [objekt] =o.[object_name], [columns] =STRING_AGG(c.column_name, N',')FROM dbo.Objects AS oINNER JOIN dbo.Columns AS cON o.[object_id] =c.[ object_id]GRUPPER AF o.[objektnavn];
Igen giver dette nøjagtig samme output. Og vi var i stand til at gøre dette med en indbygget funktion og undgå både den dyre FOR XML PATH stillads og STUFF() funktion, der bruges til at fjerne det første komma (dette sker automatisk).
Hvad med ordre?
Et af problemerne med mange af kludge-løsningerne til grupperet sammenkædning er, at rækkefølgen af den kommaseparerede liste bør betragtes som vilkårlig og ikke-deterministisk.
For XML PATH løsning, demonstrerede jeg i et andet tidligere indlæg, at tilføjelse af en ORDER BY er trivielt og garanteret. Så i dette eksempel kunne vi sortere kolonnelisten efter kolonnenavn alfabetisk i stedet for at overlade det til SQL Server at sortere (eller ej):
VÆLG [objekt] =[objekt_navn], [kolonner] =TING( (VÆLG N',' +c.kolonnenavn FRA dbo.Columns AS c WHERE c.[objekt_id] =o.[objekt_id] BESTIL AF c. kolonnenavn -- skift kun FOR XML PATH, TYPE ).value(N'.[1]',N'nvarchar(max)'),1,1,N'')FRA dbo.Objects AS o;
Output:
objektkolonner--------- ----------------------------Medarbejdere CurrentStatus,EmployeeIDOrder CustomerID,OrderDate, Ordre-id
CTP 1.1 tilføjer WITHIN GROUP til STRING_AGG() , så ved at bruge den nye tilgang kan vi sige:
VÆLG [objekt] =o.[object_name], [columns] =STRING_AGG(c.column_name, N',') INDEN FOR GRUPPE (ORDER BY c.column_name) -- kun ændreFRA dbo.Objects AS oINNER JOIN dbo. Kolonner AS cON o.[object_id] =c.[object_id]GROUP BY o.[object_name];
Nu får vi de samme resultater. Bemærk, at ligesom en normal ORDER BY klausul, kan du tilføje flere rækkefølgekolonner eller udtryk i WITHIN GROUP () .
Okay, præstation allerede!
Ved at bruge quad-core 2,6 GHz-processorer, 8 GB hukommelse og SQL Server CTP1.1 (14.0.100.187) oprettede jeg en ny database, genskabte disse tabeller og tilføjede rækker fra sys.all_objects og sys.all_columns . Jeg sørgede for kun at inkludere objekter, der havde mindst én kolonne:
INSERT dbo.Objects([object_id], [object_name]) -- 656 rækker VÆLG [object_id], QUOTENAME(s.name) + N'.' + QUOTENAME(o.name) FRA sys.all_objects AS o INNER JOIN sys.schemas AS s ON o.[schema_id] =s.[schema_id] WHERE EXISTS (VÆLG 1 FRA sys.all_columns HVOR [object_id] =o.[object_id] ]); INSERT dbo.Columns([object_id], column_name) -- 8.085 rows SELECT [object_id], name FROM sys.all_columns AS c WHERE EXISTS (VÆLG 1 FRA dbo.Objects WHERE [object_id] =c.[object_id] ); før>På mit system gav dette 656 objekter og 8.085 kolonner (dit system kan give lidt forskellige tal).
Planerne
Lad os først sammenligne planerne og Tabel I/O-fanerne for vores to uordnede forespørgsler ved hjælp af Plan Explorer. Her er de overordnede runtime-metrics:
Runtime-metrics for XML PATH (øverst) og STRING_AGG() (nederst)
Den grafiske plan og tabel I/O fra
FOR XML PATHforespørgsel:
Plan og tabel I/O for XML PATH, ingen ordre
Og fra
STRING_AGGversion:
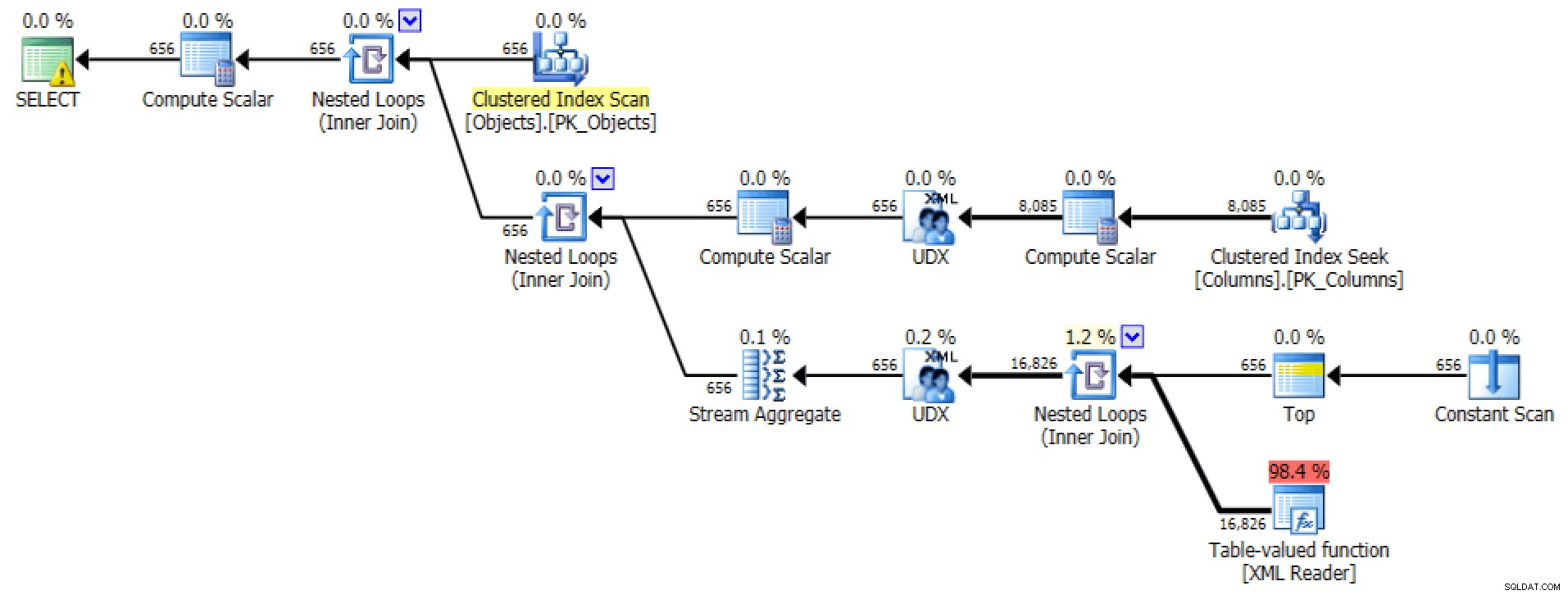
Plan og tabel I/O for STRING_AGG, ingen bestilling
For sidstnævnte forekommer den grupperede indekssøgning en smule bekymrende for mig. Dette virkede som et godt eksempel til at teste den sjældent brugte
FORCESCANtip (og nej, dette ville bestemt ikke hjælpeFOR XML PATHforespørgsel):VÆLG [objekt] =o.[objektnavn], [kolonner] =STRING_AGG(c.kolonnenavn, N',')FRA dbo.Objects AS oINNER JOIN dbo.Columns AS c WITH (FORCESCAN) -- tilføjet tip o .[object_id] =c.[object_id]GRUPPER AF o.[object_name];Nu ser planen og Tabel I/O-fanen masse ud bedre, i hvert fald ved første øjekast:
Plan og tabel I/O for STRING_AGG(), ingen bestilling, med FORCESCAN
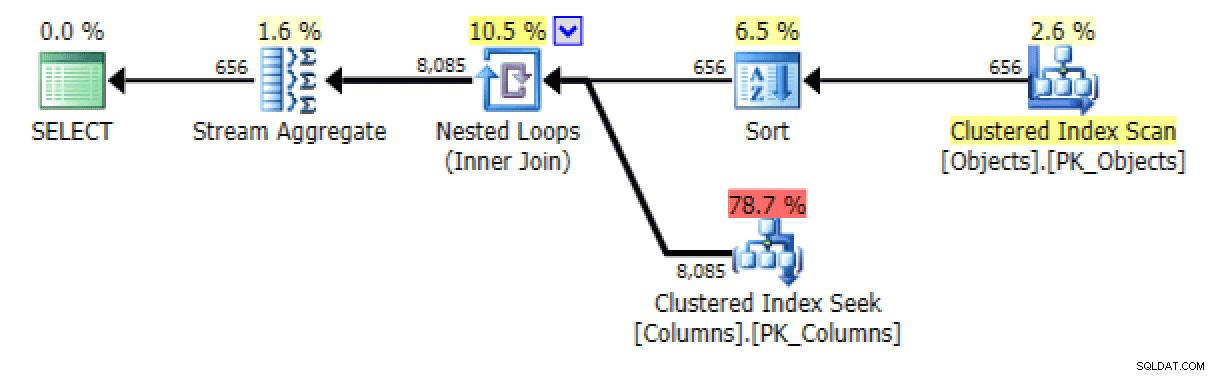
De bestilte versioner af forespørgslerne genererer nogenlunde de samme planer. For
FOR XML PATHversion, tilføjes en sortering:
Tilføjet sortering i FOR XML PATH-version
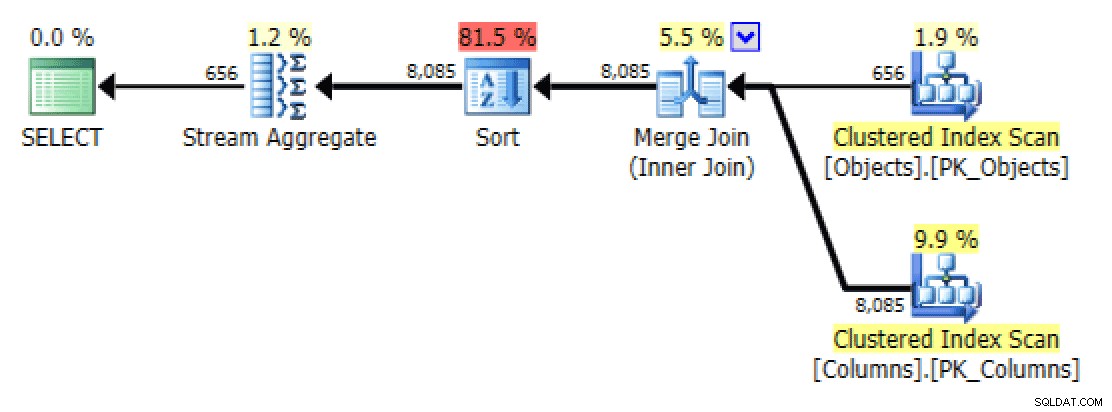
For
STRING_AGG(), vælges en scanning i dette tilfælde, selv udenFORCESCANtip, og der kræves ingen yderligere sorteringsoperation – så planen ser identisk ud medFORCESCANversion.I skala
At se på en plan og enkeltstående runtime-metrics kan måske give os en idé om, hvorvidt
STRING_AGG()yder bedre end den eksisterendeFOR XML PATHløsning, men en større test giver måske mere mening. Hvad sker der, når vi udfører den grupperede sammenkædning 5.000 gange?SELECT SYSDATETIME();GO DECLARE @x nvarchar(max);SELECT @x =STRING_AGG(c.column_name, N',') FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_id ] =c.[object_id] GRUPPER AF o.[object_name];GO 5000SELECT [string_agg, unordered] =SYSDATETIME();GO DECLARE @x nvarchar(max);SELECT @x =STRING_AGG(c.column_name, N',' ) FRA dbo.Objects AS o INNER JOIN dbo.Columns AS c WITH (FORCESCAN) ON o.[object_id] =c.[object_id] GROUP BY o.[object_name];GO 5000SELECT [string_agg, unordered, forcescan] =SYSDATETIME( ); GODECLARE @x nvarchar(max);SELECT @x =TING((SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] =o.[object_id] FOR XML PATH, TYPE).value (N'.[1]',N'nvarchar(max)'),1,1,N'')FRA dbo.Objects AS o;GO 5000SELECT [for xml-sti, uordnet] =SYSDATETIME(); GODECLARE @x nvarchar(max);SELECT @x =STRING_AGG(c.column_name, N',') INDEN FOR GRUPPE (ORDER BY c.column_name) FRA dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_id ] =c.[object_id] GROUP BY o.[object_name];GO 5000SELECT [string_agg, ordered] =SYSDATETIME(); GODECLARE @x nvarchar(max);SELECT @x =TING((SELECT N',' +c.column_name FRA dbo.Columns AS c WHERE c.[object_id] =o.[object_id] BESTILLE EFTER c.column_name FOR XML PATH , TYPE).value(N'.[1]',N'nvarchar(max)'),1,1,N'')FRA dbo.Objects AS oORDER BY o.[object_name];GO 5000SELECT [for xml-sti , bestilt] =SYSDATETIME();Efter at have kørt dette script fem gange tog jeg gennemsnittet af varighedstallene, og her er resultaterne:
Varighed (millisekunder) for forskellige grupperede sammenkædningstilgange
Vi kan se, at vores
FORCESCANhint gjorde virkelig tingene værre - mens vi flyttede omkostningerne væk fra clustered index search, var sorteringen faktisk meget værre, selvom de estimerede omkostninger anså dem for relativt ækvivalente. Endnu vigtigere kan vi se, atSTRING_AGG()tilbyder en ydeevnefordel, uanset om de sammenkædede strenge skal bestilles på en bestemt måde. Som medSTRING_SPLIT(), som jeg så på tilbage i marts, er jeg ret imponeret over, at denne funktion skaleres godt før "v1."Jeg har planlagt yderligere tests, måske til et fremtidigt indlæg:
- Når alle data kommer fra en enkelt tabel, med og uden et indeks, der understøtter bestilling
- Lignende ydeevnetest på Linux
I mellemtiden, hvis du har specifikke brugstilfælde til grupperet sammenkædning, bedes du dele dem nedenfor (eller e-mail mig på abertrand@sentryone.com). Jeg er altid åben for at sikre, at mine tests er så virkelige som muligt.