TeamCity er en server til kontinuerlig integration og kontinuerlig levering bygget i Java. Den er tilgængelig som en cloud-tjeneste og på stedet. Som du kan forestille dig, er kontinuerlig integration og leveringsværktøjer afgørende for softwareudvikling, og deres tilgængelighed skal være upåvirket. Heldigvis kan TeamCity implementeres i en meget tilgængelig tilstand.
Dette blogindlæg vil dække forberedelse og implementering af et yderst tilgængeligt miljø for TeamCity.
Miljøet
TeamCity består af flere elementer. Der er en Java-applikation og en database, der sikkerhedskopierer det. Den bruger også agenter, der kommunikerer med den primære TeamCity-instans. Den meget tilgængelige udrulning består af flere TeamCity-instanser, hvor den ene fungerer som den primære og de andre sekundær. Disse forekomster deler adgang til den samme database og datamappen. Et nyttigt skema er tilgængeligt på TeamCity-dokumentationssiden, som vist nedenfor:

Som vi kan se, er der to delte elementer - datamappen og databasen. Vi skal sikre, at disse også er meget tilgængelige. Der er forskellige muligheder, som du kan bruge til at bygge en delt montering; vi vil dog bruge GlusterFS. Hvad angår databasen, vil vi bruge et af de understøttede relationelle databasestyringssystemer – PostgreSQL, og vi vil bruge ClusterControl til at bygge en høj tilgængelig stak baseret på den.
Sådan konfigureres GlusterFS
Lad os starte med det grundlæggende. Vi ønsker at konfigurere værtsnavne og /etc/hosts på vores TeamCity noder, hvor vi også vil implementere GlusterFS. For at gøre det skal vi konfigurere depotet til de nyeste pakker af GlusterFS på dem alle:
sudo add-apt-repository ppa:gluster/glusterfs-7
sudo apt updateSå kan vi installere GlusterFS på alle vores TeamCity noder:
sudo apt install glusterfs-server
sudo systemctl enable glusterd.service
example@sqldat.com:~# sudo systemctl start glusterd.service
example@sqldat.com:~# sudo systemctl status glusterd.service
● glusterd.service - GlusterFS, a clustered file-system server
Loaded: loaded (/lib/systemd/system/glusterd.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2022-02-21 11:42:35 UTC; 7s ago
Docs: man:glusterd(8)
Process: 48918 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 48919 (glusterd)
Tasks: 9 (limit: 4616)
Memory: 4.8M
CGroup: /system.slice/glusterd.service
└─48919 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO
Feb 21 11:42:34 node1 systemd[1]: Starting GlusterFS, a clustered file-system server...
Feb 21 11:42:35 node1 systemd[1]: Started GlusterFS, a clustered file-system server.GlusterFS bruger port 24007 til forbindelse mellem noderne; vi skal sørge for, at den er åben og tilgængelig for alle noderne.
Når forbindelsen er på plads, kan vi oprette en GlusterFS-klynge ved at køre fra én node:
example@sqldat.com:~# gluster peer probe node2
peer probe: success.
example@sqldat.com:~# gluster peer probe node3
peer probe: success.Nu kan vi teste, hvordan status ser ud:
example@sqldat.com:~# gluster peer status
Number of Peers: 2
Hostname: node2
Uuid: e0f6bc53-d47d-4db6-843b-9feea111a713
State: Peer in Cluster (Connected)
Hostname: node3
Uuid: c7d285d1-bcc8-477f-a3d7-7e56ff6bfd1a
State: Peer in Cluster (Connected)Det ser ud til, at alt er i orden, og forbindelsen er på plads.
Dernæst bør vi forberede en blokenhed, der skal bruges af GlusterFS. Dette skal udføres på alle noderne. Først skal du oprette en partition:
example@sqldat.com:~# echo 'type=83' | sudo sfdisk /dev/sdb
Checking that no-one is using this disk right now ... OK
Disk /dev/sdb: 30 GiB, 32212254720 bytes, 62914560 sectors
Disk model: VBOX HARDDISK
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
>>> Created a new DOS disklabel with disk identifier 0xbcf862ff.
/dev/sdb1: Created a new partition 1 of type 'Linux' and of size 30 GiB.
/dev/sdb2: Done.
New situation:
Disklabel type: dos
Disk identifier: 0xbcf862ff
Device Boot Start End Sectors Size Id Type
/dev/sdb1 2048 62914559 62912512 30G 83 Linux
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.Formater derefter den partition:
example@sqldat.com:~# mkfs.xfs -i size=512 /dev/sdb1
meta-data=/dev/sdb1 isize=512 agcount=4, agsize=1966016 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1
data = bsize=4096 blocks=7864064, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=3839, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0Til sidst skal vi på alle noderne oprette en mappe, der skal bruges til at montere partitionen og redigere fstab for at sikre, at den bliver monteret ved opstart:
example@sqldat.com:~# mkdir -p /data/brick1
echo '/dev/sdb1 /data/brick1 xfs defaults 1 2' >> /etc/fstabLad os nu bekræfte, at dette virker:
example@sqldat.com:~# mount -a && mount | grep brick
/dev/sdb1 on /data/brick1 type xfs (rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota)Nu kan vi bruge en af noderne til at oprette og starte GlusterFS-volumen:
example@sqldat.com:~# sudo gluster volume create teamcity replica 3 node1:/data/brick1 node2:/data/brick1 node3:/data/brick1 force
volume create: teamcity: success: please start the volume to access data
example@sqldat.com:~# sudo gluster volume start teamcity
volume start: teamcity: successBemærk venligst, at vi bruger værdien '3' til antallet af replikaer. Det betyder, at hvert bind vil eksistere i tre eksemplarer. I vores tilfælde vil hver mursten, hver /dev/sdb1-volumen på alle noder indeholde alle data.
Når volumerne er startet, kan vi bekræfte deres status:
example@sqldat.com:~# sudo gluster volume status
Status of volume: teamcity
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick node1:/data/brick1 49152 0 Y 49139
Brick node2:/data/brick1 49152 0 Y 49001
Brick node3:/data/brick1 49152 0 Y 51733
Self-heal Daemon on localhost N/A N/A Y 49160
Self-heal Daemon on node2 N/A N/A Y 49022
Self-heal Daemon on node3 N/A N/A Y 51754
Task Status of Volume teamcity
------------------------------------------------------------------------------
There are no active volume tasksSom du kan se, ser alt ok ud. Det, der er vigtigt, er, at GlusterFS valgte port 49152 til at få adgang til den volumen, og vi skal sikre, at den er tilgængelig på alle de noder, hvor vi vil montere den.
Det næste trin vil være at installere GlusterFS-klientpakken. Til dette eksempel skal vi have det installeret på de samme noder som GlusterFS-serveren:
example@sqldat.com:~# sudo apt install glusterfs-client
Reading package lists... Done
Building dependency tree
Reading state information... Done
glusterfs-client is already the newest version (7.9-ubuntu1~focal1).
glusterfs-client set to manually installed.
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.Dernæst skal vi oprette en mappe på alle noder, der skal bruges som en delt datamappe for TeamCity. Dette skal ske på alle noderne:
example@sqldat.com:~# sudo mkdir /teamcity-storageMonter til sidst GlusterFS-volumen på alle noderne:
example@sqldat.com:~# sudo mount -t glusterfs node1:teamcity /teamcity-storage/
example@sqldat.com:~# df | grep teamcity
node1:teamcity 31440900 566768 30874132 2% /teamcity-storageDette fuldender forberedelserne til delt opbevaring.
Opbygning af en meget tilgængelig PostgreSQL-klynge
Når opsætningen af delt lager for TeamCity er fuldført, kan vi nu bygge vores meget tilgængelige databaseinfrastruktur. TeamCity kan bruge forskellige databaser; vi vil dog bruge PostgreSQL i denne blog. Vi vil udnytte ClusterControl til at implementere og derefter administrere databasemiljøet.
TeamCitys guide til opbygning af multi-node-implementering er nyttig, men den ser ud til at udelade den høje tilgængelighed af alt andet end TeamCity. TeamCitys guide foreslår en NFS- eller SMB-server til datalagring, som i sig selv ikke har redundans og vil blive et enkelt fejlpunkt. Vi har løst dette ved at bruge GlusterFS. De nævner en delt database, da en enkelt databaseknude naturligvis ikke giver høj tilgængelighed. Vi skal bygge en ordentlig stak:

I vores tilfælde. den vil bestå af tre PostgreSQL-noder, en primær og to replikaer. Vi vil bruge HAProxy som en belastningsbalancer og bruge Keepalved til at administrere Virtual IP for at give et enkelt slutpunkt, som applikationen kan oprette forbindelse til. ClusterControl håndterer fejl ved at overvåge replikeringstopologien og udføre enhver påkrævet gendannelse efter behov, f.eks. genstart af mislykkede processer eller fejl over til en af replikaerne, hvis den primære node går ned.
For at starte vil vi implementere databasenoderne. Husk, at ClusterControl kræver SSH-forbindelse fra ClusterControl-knuden til alle de noder, den administrerer.

Derefter vælger vi en bruger, som vi vil bruge til at oprette forbindelse til database, dens adgangskode og PostgreSQL-versionen til at implementere:

Dernæst skal vi definere, hvilke noder der skal bruges til at implementere PostgreSQL :
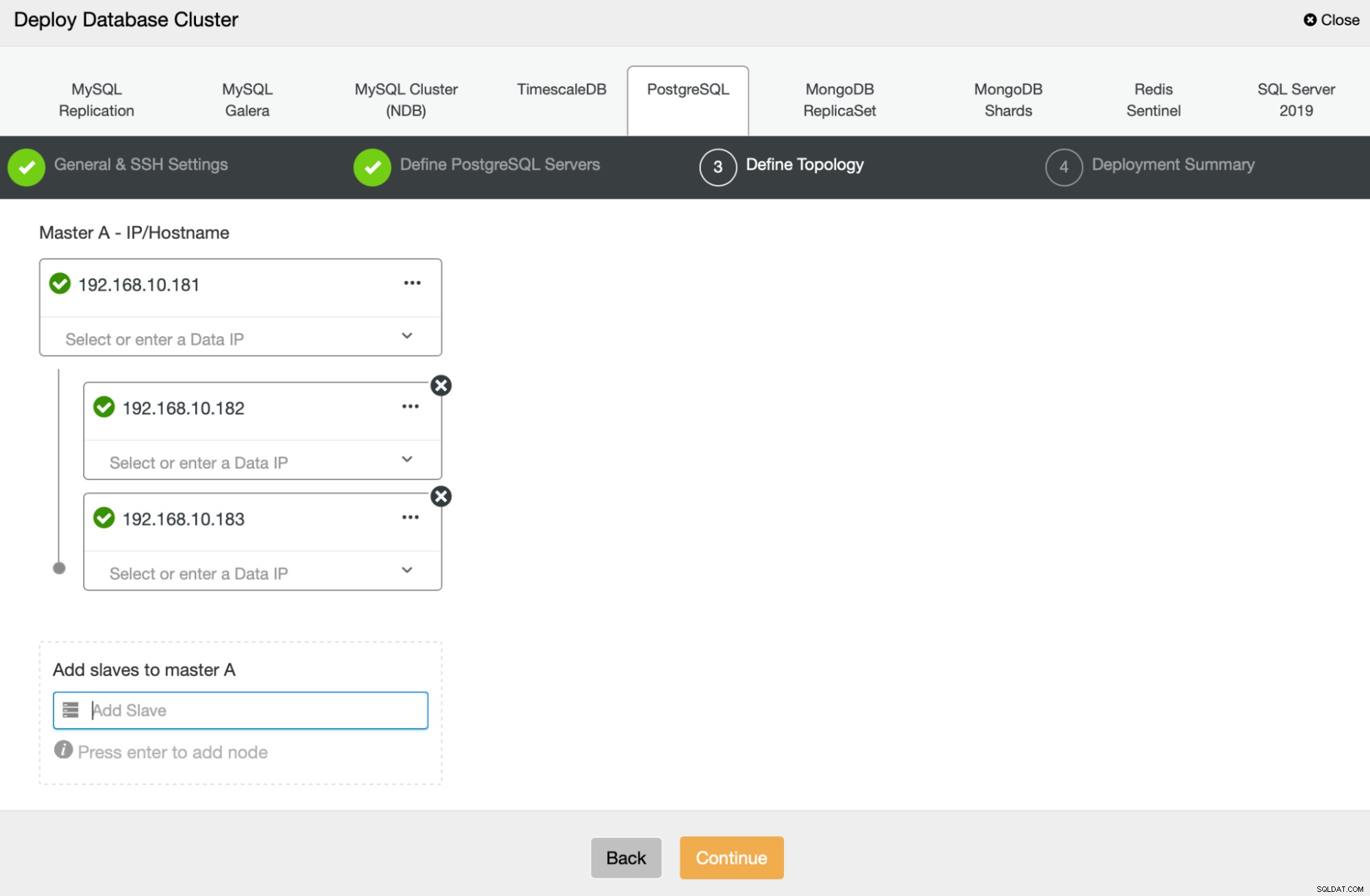
Til sidst kan vi definere, om noderne skal bruge asynkron eller synkron replikering. Den største forskel mellem disse to er, at synkron replikering sikrer, at hver transaktion, der udføres på den primære node, altid vil blive replikeret på replikaerne. Synkron replikering sænker dog også commit. Vi anbefaler at aktivere synkron replikering for den bedste holdbarhed, men du bør senere kontrollere, om ydeevnen er acceptabel.

Når vi har klikket på “Deploy”, starter et implementeringsjob. Vi kan overvåge dens fremskridt på fanen Aktivitet i ClusterControl UI. Vi skulle i sidste ende se, at jobbet er fuldført, og at klyngen blev implementeret med succes.

Implementer HAProxy-forekomster ved at gå til Administrer -> Load balancers. Vælg HAProxy som belastningsbalancer, og udfyld formularen. Det vigtigste valg er, hvor du vil implementere HAProxy. Vi brugte en databasenode i dette tilfælde, men i et produktionsmiljø vil du højst sandsynligt adskille belastningsbalancere fra databaseforekomster. Vælg derefter, hvilke PostgreSQL-noder der skal inkluderes i HAProxy. Vi vil have dem alle sammen.

Nu starter HAProxy-implementeringen. Vi vil gerne gentage det mindst én gang mere for at oprette to HAProxy-instanser til redundans. I denne udrulning besluttede vi at gå med tre HAProxy-belastningsbalancere. Nedenfor er et skærmbillede af indstillingsskærmen, mens du konfigurerer implementeringen af en anden HAProxy:
Når alle vores HAProxy-forekomster er oppe at køre, kan vi implementere Keepalived . Tanken her er, at Keepalved vil blive samlokaliseret med HAProxy og overvåge HAProxys proces. Et af tilfældene med fungerende HAProxy vil have Virtual IP tildelt. Denne VIP skal bruges af applikationen til at oprette forbindelse til databasen. Keepalived vil registrere, hvis den HAProxy bliver utilgængelig og flytte til en anden tilgængelig HAProxy-instans.
Implementeringsguiden kræver, at vi sender HAProxy-forekomster, som vi vil have Keelived til at overvåge. Vi skal også videregive IP-adressen og netværksgrænsefladen til VIP.

Det sidste og sidste trin vil være at oprette en database til TeamCity:

Med dette har vi afsluttet implementeringen af den meget tilgængelige PostgreSQL-klynge.
Deployering af TeamCity som multi-node
Det næste trin er at implementere TeamCity i et multi-node miljø. Vi vil bruge tre TeamCity-noder. Først skal vi installere Java JRE og JDK, der matcher kravene i TeamCity.
apt install default-jre default-jdkNu skal vi downloade TeamCity på alle noder. Vi installerer i en lokal, ikke delt mappe.
example@sqldat.com:~# cd /var/lib/teamcity-local/
example@sqldat.com:/var/lib/teamcity-local# wget https://download.jetbrains.com/teamcity/TeamCity-2021.2.3.tar.gzSå kan vi starte TeamCity på en af noderne:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh start
Spawning TeamCity restarter in separate process
TeamCity restarter running with PID 83162
Starting TeamCity build agent...
Java executable is found: '/usr/lib/jvm/default-java/bin/java'
Starting TeamCity Build Agent Launcher...
Agent home directory is /var/lib/teamcity-local/TeamCity/buildAgent
Agent Launcher Java runtime version is 11
Lock file: /var/lib/teamcity-local/TeamCity/buildAgent/logs/buildAgent.properties.lock
Using no lock
Done [83731], see log at /var/lib/teamcity-local/TeamCity/buildAgent/logs/teamcity-agent.logNår TeamCity er startet, kan vi få adgang til brugergrænsefladen og begynde implementeringen. I første omgang skal vi videregive databibliotekets placering. Dette er den delte bind, vi oprettede på GlusterFS.

Vælg derefter databasen. Vi skal bruge en PostgreSQL-klynge, som vi allerede har oprettet.

Download og installer JDBC-driveren:

Fyld derefter adgangsoplysninger. Vi bruger den virtuelle IP leveret af Keepalved. Bemærk venligst, at vi bruger port 5433. Dette er porten, der bruges til læse/skrive-backend af HAProxy; den vil altid pege mod den aktive primære knude. Vælg derefter en bruger og databasen, der skal bruges med TeamCity.

Når dette er gjort, begynder TeamCity at initialisere databasestrukturen.

Acceptér licensaftalen:

Opret endelig en bruger til TeamCity:

Det var det! Vi skulle nu være i stand til at se TeamCity GUI:

Nu skal vi konfigurere TeamCity i multi-node-tilstand. Først skal vi redigere opstartsscripts på alle noderne:
example@sqldat.com:~# vim /var/lib/teamcity-local/TeamCity/bin/runAll.shVi skal sørge for, at følgende to variabler eksporteres. Bekræft venligst, at du bruger det korrekte værtsnavn, IP og de korrekte mapper til lokal og delt lagring:
export TEAMCITY_SERVER_OPTS="-Dteamcity.server.nodeId=node1 -Dteamcity.server.rootURL=https://192.168.10.221 -Dteamcity.data.path=/teamcity-storage -Dteamcity.node.data.path=/var/lib/teamcity-local"
export TEAMCITY_DATA_PATH="/teamcity-storage"Når dette er gjort, kan du starte de resterende noder:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh startDu bør se følgende output i Administration -> Nodekonfiguration:En hovedknude og to standbynoder.

Husk venligst, at failover i TeamCity ikke er automatiseret. Hvis hovedknuden holder op med at fungere, skal du oprette forbindelse til en af de sekundære knudepunkter. For at gøre dette skal du gå til "Konfiguration af noder" og opgradere den til "Hoved"-knuden. Fra login-skærmen vil du se en tydelig indikation af, at dette er en sekundær node:

I "Nodes Configuration" vil du se, at den ene node har faldet fra klyngen:

Du modtager en besked om, at du ikke kan skrive til denne node. Bare rolig; skrivningen påkrævet for at fremme denne node til "hoved"-status vil fungere fint:

Klik på "Aktiver", og vi har med succes promoveret en sekundær TimeCity-node:

Når node1 bliver tilgængelig, og TeamCity startes igen på den node, vil vi se det slutte sig til klyngen igen:

Hvis du vil forbedre ydeevnen yderligere, kan du implementere HAProxy + Keepalved foran TeamCity UI for at give et enkelt indgangspunkt til GUI. Du kan finde detaljer om konfiguration af HAProxy for TeamCity i dokumentationen.
Afslutning
Som du kan se, er det ikke så svært at implementere TeamCity for høj tilgængelighed - det meste af det er blevet dækket grundigt i dokumentationen. Hvis du leder efter måder at automatisere noget af dette og tilføje en meget tilgængelig databasebackend, kan du overveje at evaluere ClusterControl gratis i 30 dage. ClusterControl kan hurtigt implementere og overvåge backend'en, hvilket giver automatisk failover, gendannelse, overvågning, sikkerhedskopiering og mere.
For flere tips om softwareudviklingsværktøjer og bedste praksis, se, hvordan du understøtter dit DevOps-team med deres databasebehov.
For at få de seneste nyheder og bedste praksis til at administrere din open source-baserede databaseinfrastruktur, så glem ikke at følge os på Twitter eller LinkedIn og abonnere på vores nyhedsbrev. Vi ses snart!