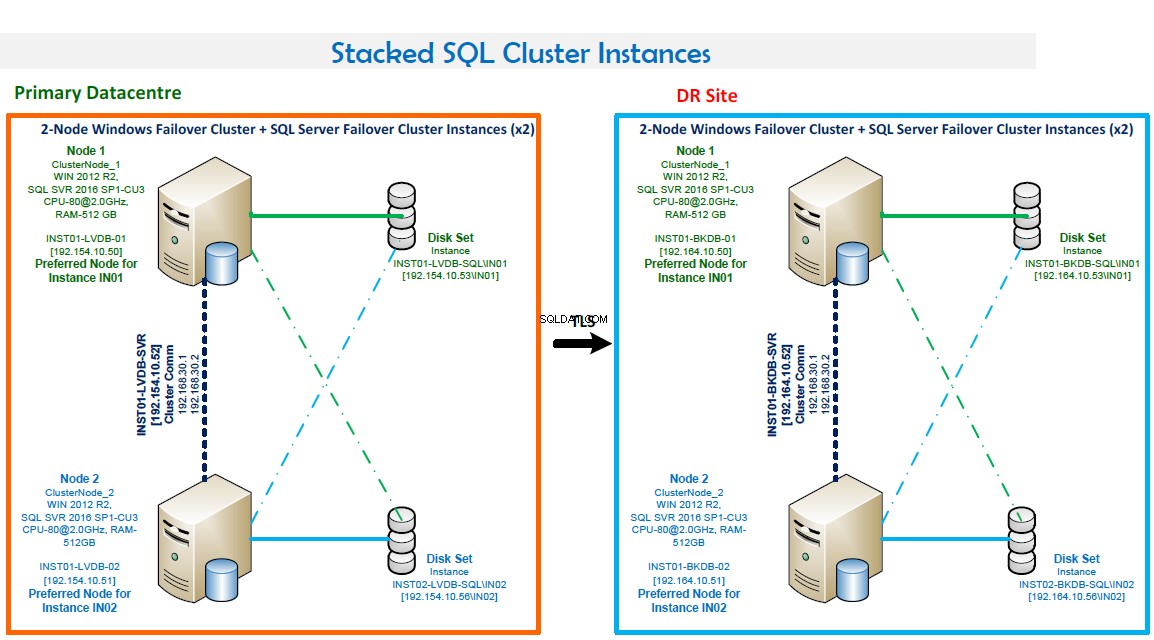
BEMÆRKNINGER:
- Windows Failover-klynge bestående af to noder.
- To SQL Server Failover Cluster Forekomster. Denne konfiguration optimerer hardwaren. IN01 foretrækkes på Node1, og IN02 foretrækkes på Node2.
- Portnumre:IN01 lytter på port 1435 og IN02 lytter på port 1436.
- Høj tilgængelighed. Begge noder bakker op om hinanden. Failover er automatisk i tilfælde af fejl.
- Kvorumstilstand er Node- og Disk-flertal.
- Sikkerhedskopiering af LAN på plads og rutinemæssig backup konfigureret ved hjælp af Veritas
Introduktion
Det er ikke ualmindeligt, at udviklere og projektledere kræver en ny forekomst af SQL Server for hver ny applikation eller tjeneste. Mens teknologier som virtualisering og Cloud har gjort det til en leg at opbygge nye instanser, gør nogle ældgamle teknikker indbygget i SQL Server det muligt at opnå lave behandlingstider, når der er behov for at levere en ny database til en ny tjeneste eller applikation. Denne tilstand kan skabes af en DBA, der kan designe og implementere en stor SQL Server-klynge, der er i stand til at understøtte de fleste SQL Server-databaser, som organisationen kræver. Der er yderligere fordele ved denne form for konsolidering, såsom lavere licensomkostninger, bedre styring og nem administration. I artiklen vil vi fremhæve nogle overvejelser, vi har haft mulighed for at opleve, når vi bruger klyngedannelse og stabling som et middel til at konsolidere SQL Server-databaser.
Klynger
Windows Server Failover Clustering er en meget velkendt High Availability Solution, som har overlevet mange versioner af Windows Server, og som Microsoft har til hensigt at blive ved med at investere i og forbedre. SQL Server Failover Cluster-instanser er afhængige af WSFC. Både Standard og Enterprise Editions af SQL Server understøtter SQL Server Failover Cluster Instances, men Standard Edition er begrænset til kun to noder. Konsolidering af databaser på en enkelt SQL Server FCI giver fordelene såsom:
- HA som standard — Alle databaser implementeret på en klynget SQL Server-instans er højst tilgængelige som standard! Når først en klynget instans er bygget, tages der hånd om nye implementeringer i form af HA før tid.
- Nem administration – Færre DBA'er kan bruge tid på at konfigurere, overvåge og om nødvendigt fejlfinde EN clustered instans, der understøtter mange applikationer. Korrekt, dokumentering af forekomsten er også gjort meget lettere, når man har at gøre med et stort miljø. Konfiguration af en Enterprise Backup-løsning til at håndtere alle databaser i dit miljø gøres lettere af det faktum, at du kun skal udføre denne konfiguration én gang, når du bruger konsoliderede forekomster.
- Overholdelse – Nøglekrav som patching og endda hærdning kan udføres én gang med minimal nedetid på et stort antal databaser i en enkelt administrativ indsats. I vores butik har vi brugt Transaction Log Shipping mellem grupperede forekomster i to datacentre for at sikre, at databaser er beskyttet mod risikoen for katastrofer.
- Standardisering – Håndhævelse af sådanne standarder som navnekonventioner, adgangsadministration, Windows-godkendelse, revision og politikbaseret administration er meget nemmere, når du kun har at gøre med et eller to miljøer afhængigt af størrelsen på din butik
Fortegnelse 1: Udtræk oplysninger om din instans
-- Extract Instance Details
-- Includes a Column to Check Whether Instance is Clustered
SELECT SERVERPROPERTY('MachineName') AS [MachineName]
, SERVERPROPERTY('ServerName') AS [ServerName]
, SERVERPROPERTY('InstanceName') AS [Instance]
, SERVERPROPERTY('IsClustered') AS [IsClustered]
, SERVERPROPERTY('ComputerNamePhysicalNetBIOS') AS [ComputerNamePhysicalNetBIOS]
, SERVERPROPERTY('Edition') AS [Edition]
, SERVERPROPERTY('ProductLevel') AS [ProductLevel]
, SERVERPROPERTY('ProductVersion') AS [ProductVersion]
, SERVERPROPERTY('ProcessID') AS [ProcessID]
, SERVERPROPERTY('Collation') AS [Collation]
, SERVERPROPERTY('IsFullTextInstalled') AS [IsFullTextInstalled]
, SERVERPROPERTY('IsIntegratedSecurityOnly') AS [IsIntegratedSecurityOnly]
, SERVERPROPERTY('IsHadrEnabled') AS [IsHadrEnabled]
, SERVERPROPERTY('HadrManagerStatus') AS [HadrManagerStatus]
, SERVERPROPERTY('IsXTPSupported') AS [IsXTPSupported];
Stabling
SQL Server understøtter op til halvtreds enkeltforekomster på én server og op til 25 Failover Cluster Instances på en Windows Server Failover Cluster. Forskellige versioner af SQL Server kan stables på det samme miljø for at give et robust miljø, der understøtter forskellige applikationer. I en sådan konfiguration kan opgradering af databaser tage form af blot at promovere dem fra én SQL Server-instans til den næste version i den samme klynge, indtil hardwaren ældes. En vigtig overvejelse at have i tankerne, når du stabler SQL Server, er, at du skal allokere hukommelse til hver instans på en sådan måde, at den samlede mængde hukommelse, der er allokeret, ikke overstiger den tilgængelige hukommelse på operativsystemet. Det andet punkt i denne retning er at sikre, at SQL Server-tjenestekontoen for hver forekomst skal have låsesiderne i hukommelsesrettigheder. Tildeling af låse sider i hukommelsen sikrer, at når SQL Server erhverver hukommelse, forsøger operativsystemet ikke at gendanne sådan hukommelse, når andre processer på serveren har brug for hukommelse. Opsætning af en defineret SQL Server-tjenestekonto, konfiguration af MAX_SERVER_MEMORY og tildeling af låsesider i hukommelsen er en vigtig trio, når du stabler SQL Server-forekomster.
Microsoft opkræver et par tusinde dollars pr. par CPU-kerner. Stabling af SQL Server-forekomster giver dig mulighed for at udnytte denne licensmodel ved at få forekomster til at dele det samme sæt CPU'er (sveder aktivet). Vi har allerede nævnt, at du kan stable forskellige versioner af SQL Server og dermed tage dig af ældre applikationer, der stadig kører versioner ældre end SQL Server 2016 for eksempel. Når du bruger forskellige udgaver af SQL Server, kan du overveje at bruge Processor Affinity som beskrevet af Glen Berry i denne artikel. Processor Affinity kan også bruges til at kontrollere, hvordan CPU-ressourcer deles mellem f.eks. ligesom du styrer hukommelsen. Stacking adresserer også sikkerhedsproblemer for applikationer, der skal bruge SA-kontoen for eksempel, eller konfigurationsproblemer for applikationer, der kræver en dedikeret instans, eller sådanne muligheder er en specifik kollation. Bekymring om ydeevnen af den delte TempDB er en anden grund til, at du måske ønsker at stable i stedet for at samle alle databaser på én klynget instans.
Det er værd at bemærke, at værdien af clustering som fremhævet tidligere strækker sig endnu længere med stabling. Når du f.eks. patcher en SQL Server-instans med flere FCI'er, kan alle FCI'er lappes på én gang.
Peger til note
Når du bruger clustering, vil visse konventioner gøre administration og styring af miljøet lidt lettere og svede aktiverne bedre. Vi vil kort komme ind på et par af dem:
- Nuværende klientværktøjer — Du kan opleve, at du får usædvanlige fejl, når du forsøger at administrere en SQL Server 2016-instans ved hjælp af SQL Server Management Studio 2012. Fejlene fortæller dig ikke specifikt, at problemet er klientværktøjets version. Vi har typisk SQL Server Management Studio 17.3-instans på den klient, vi ønsker at bruge til at oprette forbindelse til vores instanser.
- Navnekonventioner — En navnekonvention gør det nemt for dig at være sikker på, hvilken instans du arbejder på på et hvilket som helst tidspunkt. Ved at bruge aliaser kan du yderligere reducere byrden ved at huske lange instansnavne på slutbrugere, der har brug for adgang til databasen.
- Foretrukken node – At indstille en foretrukken node for hver SQL Server-rolle på Failover Cluster Manager er en god idé, en god måde at sikre, at processorkraften i alle dine Cluster Nodes bliver udnyttet. I vores butik, efter at have konfigureret foretrukne noder, konfigurerede vi rollen til at fejle tilbage mellem 0500 HRS og 0600 HRS i tilfælde af, at der er en utilsigtet failover.
- Transaktionslogforsendelse – Når du konfigurerer Disaster Recovery for FCI'er, er det fornuftigt at identificere alle UNC-stier ved hjælp af virtuelle navne, ikke navnene eller IP-adressen på klyngeknuderne. Dette sikrer, at tingene fortsætter med at fungere korrekt, hvis der opstår en failover. Det er også meget vigtigt at sikre, at SQL Server Agent-konti på begge websteder har fuld kontrol over disse stier.
Fortegnelse 2: Konfigurer overvågning for forsendelse af transaktionslog ved hjælp af e-mail
-- Create Table to Store Log Shipping Data
create table msdb dbo log_shipping_report
(status bit,
is_primary bit,
server sysname,
database_name sysname,
time_since_last_backup int,
last_backup_file nvarchar (500),
backup_threshold int,
is_backup_alert_enabled bit,
time_since_last_copy int,
last_copied_file nvarchar 500),
time_since_last_restore int,
last_restored_file nvarchar(500),
last_restored_latency int,
restore_threshold int,
is_restore_alert_enabled bit);
go
-- Create an SQL Agent Job with the Following Script
-- This will send an Email at Intervals determined by the job Schedule
-- The Job Should be Created on the Log Shipping Secondary Clustered Instance
-- This Job Requires that Database Mail is Enabled
truncate table msdb dbo log_shipping_report
go
insert into msdb dbo log_shipping_report
EXEC sp_help_log_shipping_monitor;
go
/*
select [server]
, database_name [database]
, time_since_last_copy [Last Copy Time]
, last_copied_file [Last Copied File]
, time_since_last_restore [Last Restore Time]
, last_restored_file [Last Restored File]
, restore_threshold [Restore Threshold]
, restore_threshold - time_since_last_restore [Restore Latency]
from msdb.dbo.log_shipping_report;
go
*/
DECLARE @tableHTML NVARCHAR(MAX) ;
DECLARE @SecServer SYSNAME ;
SET @SecServer = @@SERVERNAME
SET @tableHTML =
N'<H1><font face="Verdana" size="4">Transaction Logshipping Status from Secondary
Server ' + @SecServer + N'</H1>' +
N'<p style="margin-top: 0; margin-bottom: 0"><font face="Verdana" size="2">Please
find below status of Secondary databases: </font></p> ' +
N'<table border="1" style="BORDER-COLLAPSE: collapse" borderColor="#111111"
cellPadding="0" width="2000" bgColor="#ffffff" borderColorLight="#000000"
border="1"><font face="Verdana" size="2">' +
N'<tr><th><font face="Verdana" size="2">Secondary Server</th>
<th><font face="Verdana" size="2">Secondary Database</th>
<th><font face="Verdana" size="2">Last Copy Time</th>' +
N'<th><font face="Verdana" size="2">Last Copied File</th><th>
<font face="Verdana" size="2">Last Restore Time</th>' +
N'<th><font face="Verdana" size="2">Last Restored File</th><th>
<font face="Verdana" size="2">Restore Threshold</th>
<th><font face="Verdana" size="2">Restore Latency</th>' +
CAST ( ( SELECT td = lsr.server, '',
td = lsr [database_name], td = lsr time_since_last_copy '',
td = lsr last_copied_file td = lsr time_since_last_restore '',
td = lsr last_restored_file, '',
td = lsr restore_threshold '',
td =
case
when lsr restore_threshold
lsr time_since_last_restore < 0 then + '<td bgcolor="#FFCC99"><b><font face="Verdana"
size="1">' + 'CRITICAL' + '</font></b></td>'
when lsr restore_threshold
lsr time_since_last_restore < 20 and lsr restore_threshold
lsr time_since_last_restore > 0 then + '<td bgcolor="#FFBB33"><b><font face="Verdana
size="1">' + 'WARNING' + '</font></b></td>'
when lsr restore_threshold
lsr time_since_last_restore > 20 then + '<td bgcolor="#21B63F"><b><font face="Verdana
size="1">' + 'OK' + '</font></b></td>'
end , ''
FROM msdb dbo log_shipping_report as lsr
ORDER BY lsr.[database_name]
FOR XML PATH('tr'), TYPE ) AS NVARCHAR(MAX) ) +
N'</table>' + ' ';
EXEC msdb dbo.sp_send_dbmail
@recipients='example@sqldat.com',
@copy_recipients='example@sqldat.com',
@subject = 'Transaction Log Shipping Report',
@body = @tableHTML,
@body_format = 'HTML' ;
Diskdrev
En bivirkning ved at stable SQL Server-instanser og sørge for flere databaser er tendensen til at løbe tør for drevbogstaver. Vi omgik dette problem ved at konfigurere Volume Mount Points. Hver disk, der er tildelt en klyngerolle, er konfigureret som et monteringspunkt med et drevbogstav, der kun er nødvendigt for et eller to drev pr. instans. En vigtig pointe at bemærke, når du bruger volumenmonteringspunkter på en klynge, er, at når du i fremtiden skal tilføje flere monteringspunkter for at udføre lignende vedligeholdelsesopgaver, vil det være nødvendigt at sætte BÅDE det primære drev, der ejer drevbogstavet, og monteringen punkt i vedligeholdelsestilstand på klyngen.
I vores tilfælde fandt vi navnet på hvert volumenmonteringspunkt baseret på den klyngerolle, det blev tildelt. Med så mange drev at håndtere, vil du helt sikkert være nødt til at finde en måde, hvorpå både dig og lageradministratoren kan identificere en disk unik, så det ikke ville være meget besværligt at vedligeholde diskene på lagerniveau.
Fortegnelse 3: Overvåg diskpladsforbrug ved brug af volumenmonteringspunkter
-- The Following Script Will Show Disk Space Usage from Within SQL Server -- It is Especially Helpful When Using Volume Mount Points -- Volume Mount Point Space Usage Can Also Be Monitored from Computer Management (OS Level) SELECT DISTINCT vs volume_mount_point , vs file_system_type , vs logical_volume_name , CONVERT(DECIMAL!18 2 vs total_bytes 1073741824.0) AS [Total Size (GB)] , CONVERT(DECIMAL(18 2 vs available_bytes 1073741824.0' AS [Available Size (GB)] , CAST(CAST(vs available_bytes AS FLOAT)/ CAST(vs total_bytes AS FLOAT) AS DECIMAL (18,2)) * 100 AS [Space Free %] FROM sys.master_files AS f WITH (NOLOCK) CROSS APPLY sys.dm_os_volume_stats f database_id, f [file_id]i AS vs OPTION (RECOMPILE);
Databaseimplementering
I vores tilfælde var vores strategi at sikre, at nye databaser fulgte vores standard. Ældre databaser blev håndteret med lidt mere omhu, da vi på en måde konsoliderede og opgraderede på samme tid. Database Migration Assistant hjalp med at fortælle os, hvilke databaser der absolut ikke ville være kompatible med vores hellige SQL Server 2016-instans, og vi lod dem være i fred (nogle med kompatibilitetsniveauer er så lave som 100). Hver installeret database skal have sine egne volumener til data og logfiler afhængigt af dens størrelse. Brug af separate volumener til hver database er endnu et skridt hen imod at have et meget velorganiseret miljø, hvilket er vigtigt i betragtning af den potentielle kompleksitet af dette konsoliderede miljø. Den sidste sætning indebærer også, at når du tillader en applikation at oprette sine egne databaser, skal du som DBA flytte datafilerne efter implementeringen er færdig, fordi applikationen vil bruge de samme filplaceringer, som modeldatabasen bruger.
Fortegnelse 4: Flytning af brugerdatabaser
-- 1. Set the database offline -- Be sure to replace DB_NAME with the actual database name ALTER DATABASE DB_NAME SET OFFLINE -- 2. Move the file or files to the new location. -- This means actually copying the datafiles at OS level -- You may also need grant the SQL Server Service account full permissions on the data file -- 3. For each file moved, run the following statement. ALTER DATABASE DB_NAME MODIFY FILE ( NAME = logical_name FILENAME = 'new_path\os_file_name') -- 4. Bring the database back online ALTER DATABASE database name SET ONLINE -- 5. Verify the file change: SELECT name, physical_name AS CurrentLocation, state_desc FROM sys.master_files WHERE database_id = DB_ID(N'DB_NAME');
Adgangsstyring
Du er enig i, at vi i vores konsoliderede miljø kan ende med at have en meget lang liste af objekter på serverniveau, såsom logins. Brug af Windows-grupper vil hjælpe med at forkorte denne liste og forenkle adgangsstyring på hver klynget forekomst. Typisk har du brug for grupper oprettet på Active Directory til applikationsadministratorer, der har brug for adgang, applikationsservicekonti, erhvervsbrugere, der skal trække rapporter og selvfølgelig databaseadministratorer. En vigtig fordel ved at bruge Windows-grupper er, at adgang kan gives eller tilbagekaldes ved blot at administrere medlemskabet af disse grupper direkte i Active Directory.
Det er nok indlysende nu, at denne fordel inden for adgangsstyring kun er mulig med Windows-godkendelse. SQL Server-login kan ikke administreres i grupper.
Fortegnelse 5: Forekomstlogins, databasebrugere og deres roller
create table #userlist (
[Server Name] varchar(20)
,[Database Name] varchar(50)
,[Database User] varchar(50)
, [Database Role] varchar(50)
, [Instance Login] varchar(50)
, [Status] varchar(15)
)
go
insert into #userlist
exec sp_MSforeachdb @command1 ='
USE [?]
IF ''?'' NOT IN ("tempdb","model"J"msdb"J"master")
BEGIN
select @@servername as instance_name , ''?'' as database_name , rp.name as database_user , mp.name as database_role , sp.name as instance_login , case
when sp.is_disabled = 1 then ''Disabled'' when sp.is_disabled = 0 then ''Enabled'' end
[login_status]
from sys.database_principals rp
left outer join sys.database_role_members drm on (drm.member_principal_id = rp.principal_id)
left outer join sys.database_principals mp on (drm.role_principal_id = mp.principal_id)
left outer join sys.server_principals sp on (rp.sid=sp.sid)
where rp.type_desc in (''WINDOWS_GROUP'',''WINDOWS_USER'',''SQL_USER'')
END' go
select * from #userlist go
drop table #userlist
Konklusion
Vi har på et meget højt niveau undersøgt de fordele, der kan opnås ved at klynge og stable SQL Server-instanser som et middel til at opnå konsolidering, omkostningsoptimering og nem administration. Hvis du finder dig selv i stand til at købe stor hardware, kan du udforske denne mulighed og høste fordelene, vi har beskrevet ovenfor.