Kort resumé
- Udførelsen af underforespørgselsmetoden afhænger af datafordelingen.
- Ydeevne af betinget aggregering afhænger ikke af datafordelingen.
Underforespørgselsmetoden kan være hurtigere eller langsommere end betinget aggregering, det afhænger af datafordelingen.
Naturligvis, hvis tabellen har et passende indeks, vil underforespørgsler sandsynligvis drage fordel af det, fordi indeks ville tillade kun at scanne den relevante del af tabellen i stedet for den fulde scanning. At have et passende indeks er usandsynligt, at det vil gavne den betingede aggregeringsmetode væsentligt, fordi det alligevel vil scanne hele indekset. Den eneste fordel ville være, hvis indekset er smallere end tabellen, og motoren skulle læse færre sider ind i hukommelsen.
Når du ved dette, kan du bestemme, hvilken metode du skal vælge.
Første test
Jeg lavede et større testbord med 5M rækker. Der var ingen indekser på bordet. Jeg målte IO- og CPU-statistikken ved hjælp af SQL Sentry Plan Explorer. Jeg brugte SQL Server 2014 SP1-CU7 (12.0.4459.0) Express 64-bit til disse tests.
Faktisk opførte dine oprindelige forespørgsler, som du beskrev, dvs. underforespørgsler var hurtigere, selvom aflæsningerne var 3 gange højere.
Efter få forsøg på en tabel uden et indeks omskrev jeg dit betingede aggregat og tilføjede variabler til at holde værdien af DATEADD udtryk.
Samlet blev tiden betydeligt hurtigere.
Så erstattede jeg SUM med COUNT og det blev en lille smule hurtigere igen.
Betinget aggregering blev trods alt stort set lige så hurtigt som underforespørgsler.
Opvarm cachen (CPU=375)
SELECT -- varm cache COUNT(*) AS all_cntFROM LogTableOPTION (RECOMPILE); Underforespørgsler (CPU=1031)
SELECT -- subqueries( SELECT count(*) FROM LogTable ) all_cnt, ( SELECT count(*) FROM LogTable WHERE datesent> DATEADD(year,-1,GETDATE())) last_year_cnt,( SELECT count( *) FROM LogTable WHERE datesent> DATEADD(year,-10,GETDATE())) last_ten_year_cntOPTION (RECOMPILE); Original betinget aggregering (CPU=1641)
SELECT -- betinget original COUNT(*) AS all_cnt, SUM(CASE WHEN datesent> DATEADD(year,-1,GETDATE()) THEN 1 ELSE 0 END) AS last_year_cnt, SUM(CASE WHEN datesent> DATEADD(year,-10,GETDATE()) THEN 1 ELSE 0 END) AS last_ten_year_cntFROM LogTableOPTION (RECOMPILE); Betinget aggregering med variabler (CPU=1078)
DECLARE @VarYear1 datetime =DATEADD(year,-1,GETDATE());DECLARE @VarYear10 datetime =DATEADD(year,-10,GETDATE());SELECT -- betingede variable COUNT(*) AS all_cnt, SUM(CASE WHEN datesent> @VarYear1 THEN 1 ELSE 0 END) AS last_year_cnt, SUM(CASE WHEN datesent> @VarYear10 THEN 1 ELSE 0 END) AS last_ten_year_cntFROM LogTableOPTION); Betinget aggregering med variabler og COUNT i stedet for SUM (CPU=1062)
SELECT -- betinget variabel, tæl, ikke sum COUNT(*) AS all_cnt, COUNT(CASE WHEN datesent> @VarYear1 THEN 1 ELSE NULL END) AS last_year_cnt, COUNT(CASE WHEN datesent> @VarYear10 THEN 1 ELSE NULL END) AS last_ten_year_cntFROM LogTableOPTION (RECOMPILE);

Baseret på disse resultater er mit gæt, at CASE påberåbt DATEADD for hver række, mens WHERE var smart nok til at regne det ud en gang. Plus COUNT er en lille smule mere effektiv end SUM .
I sidste ende er betinget aggregering kun lidt langsommere end underforespørgsler (1062 vs 1031), måske fordi Hvor er en smule mere effektiv end CASE i sig selv, og desuden WHERE filtrerer en del rækker fra, så COUNT skal behandle færre rækker.
I praksis ville jeg bruge betinget aggregering, fordi jeg tror, at antallet af læsninger er vigtigere. Hvis dit bord er lille til at passe og forblive i bufferpuljen, vil enhver forespørgsel være hurtig for slutbrugeren. Men hvis tabellen er større end tilgængelig hukommelse, så forventer jeg, at læsning fra disk vil bremse underforespørgsler betydeligt.
Anden test
På den anden side er det også vigtigt at filtrere rækkerne ud så tidligt som muligt.
Her er en lille variation af testen, som demonstrerer det. Her sætter jeg tærsklen til GETDATE() + 100 år for at sikre, at ingen rækker opfylder filterkriterierne.
Opvarm cachen (CPU=344)
SELECT -- varm cache COUNT(*) AS all_cntFROM LogTableOPTION (RECOMPILE); Underforespørgsler (CPU=500)
SELECT -- subqueries( SELECT count(*) FROM LogTable ) all_cnt, ( SELECT count(*) FROM LogTable WHERE datesent> DATEADD(year,100,GETDATE())) last_year_cntOPTION (RECOMPILE); Original betinget aggregering (CPU=937)
VÆLG -- betinget original COUNT(*) AS all_cnt, SUM(CASE WHEN datesent> DATEADD(year,100,GETDATE()) THEN 1 ELSE 0 END) AS last_ten_year_cntFROM LogTableOPTION (RECOMPILE); Betinget aggregering med variabler (CPU=750)
DECLARE @VarYear100 datetime =DATEADD(year,100,GETDATE());SELECT -- betingede variabler COUNT(*) AS all_cnt, SUM(CASE WHEN datesent> @VarYear100 THEN 1 ELSE 0 END) AS last_ten_year_cnt LogTableOPTION (GENKOMPIL); Betinget aggregering med variabler og COUNT i stedet for SUM (CPU=750)
SELECT -- betinget variabel, tæl, ikke sum COUNT(*) AS all_cnt, COUNT(CASE WHEN datesent> @VarYear100 THEN 1 ELSE NULL END) AS last_ten_year_cntFROM LogTableOPTION (RECOMPILE);
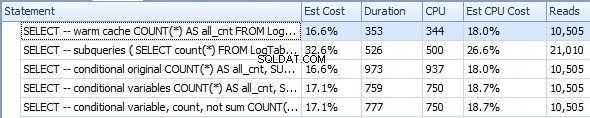
Nedenfor er en plan med underforespørgsler. Du kan se, at 0 rækker gik ind i Stream Aggregate i den anden underforespørgsel, alle blev filtreret fra ved tabelscanningstrinnet.
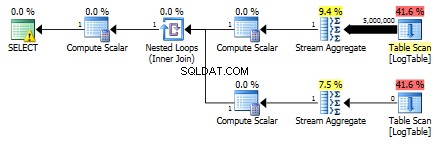
Som et resultat er underforespørgsler igen hurtigere.
Tredje test
Her ændrede jeg filtreringskriterierne for den forrige test:alle > blev erstattet med < . Som følge heraf vil den betingede COUNT talte alle rækker i stedet for ingen. Overraskelse, overraskelse! Betinget aggregeringsforespørgsel tog samme 750 ms, mens underforespørgsler blev 813 i stedet for 500.

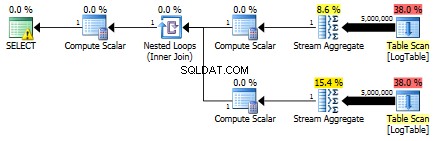
Her er planen for underforespørgsler:
Kan du give mig et eksempel, hvor betinget aggregering især klarer sig bedre end underforespørgselsløsningen?
Her er det. Underforespørgselsmetodens ydeevne afhænger af datafordelingen. Ydelse af betinget aggregering afhænger ikke af datafordelingen.
Underforespørgselsmetoden kan være hurtigere eller langsommere end betinget aggregering, det afhænger af datafordelingen.
Når du ved dette, kan du bestemme, hvilken metode du skal vælge.
Bonusdetaljer
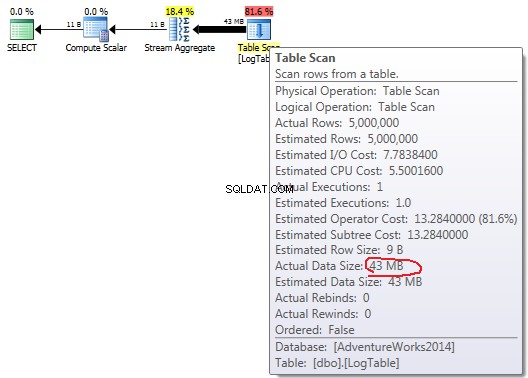
Hvis du holder musen over Tabelscanning operatør kan du se Faktisk datastørrelse i forskellige varianter.
- Simpel
COUNT(*):
- Betinget aggregering:
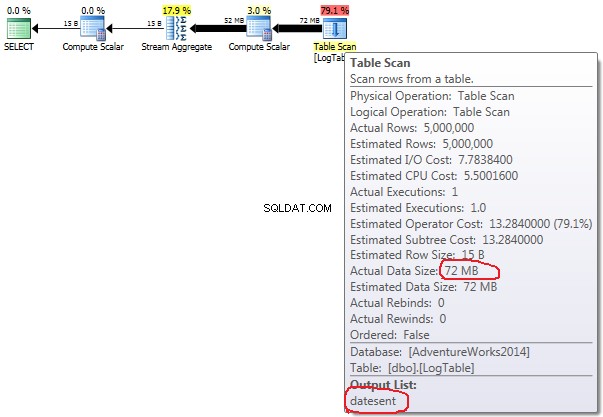
- Underforespørgsel i test 2:
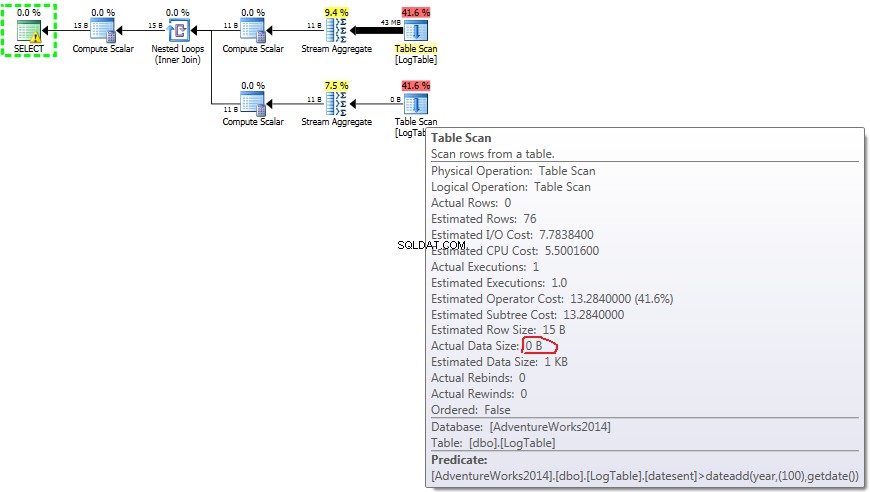
- Underforespørgsel i test 3:
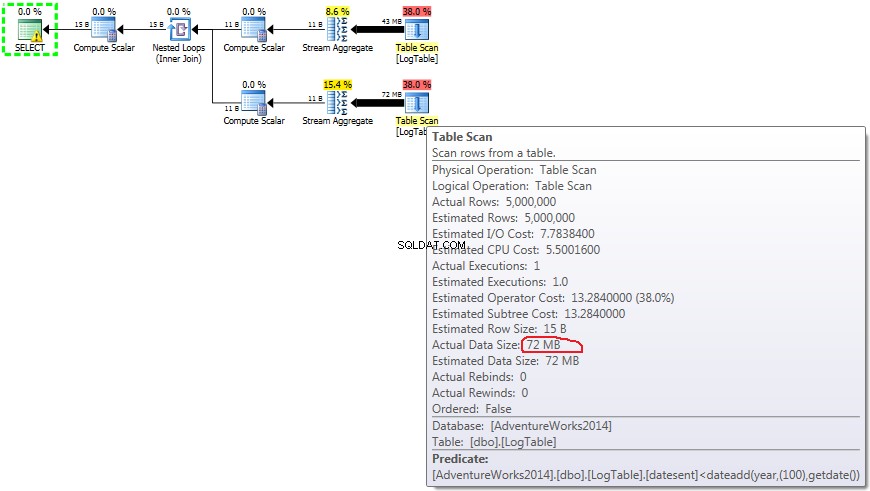
Nu bliver det klart, at forskellen i ydeevne sandsynligvis skyldes forskellen i mængden af data, der flyder gennem planen.
I tilfælde af simpel COUNT(*) der er ingen Outputliste (ingen kolonneværdier er nødvendige), og datastørrelsen er mindst (43MB).
I tilfælde af betinget aggregering ændres dette beløb ikke mellem test 2 og 3, det er altid 72 MB. Outputliste har én kolonne datesent .
I tilfælde af underforespørgsler, gør dette beløb ændres afhængigt af datafordelingen.