Jeg har udgivet flere benchmarks, der sammenligner forskellige PostgreSQL-versioner, som for eksempel præstationsarkæologi-foredraget (evaluering af PostgreSQL 7.4 op til 9.4), og alle disse benchmark-antaget faste miljøer (hardware, kerne, …). Hvilket er fint i mange tilfælde (f.eks. når man evaluerer effekt på ydeevnen af en patch), men i produktionen ændrer disse ting sig over tid – du får hardwareopgraderinger og fra tid til anden får du en opdatering med en ny kerneversion.
For hardwareopgraderinger (bedre lagring, mere RAM, hurtigere CPU'er, …) er virkningen normalt ret let at forudsige, og desuden indser folk generelt, at de er nødt til at vurdere virkningen ved at analysere flaskehalsene på produktionen og måske endda teste den nye hardware først .
Men hvad med kerneopdateringer? Desværre laver vi normalt ikke meget benchmarking på dette område. Antagelsen er for det meste, at nye kerner er bedre end ældre (hurtigere, mere effektive, skaler til flere CPU-kerner). Men er det virkelig sandt? Og hvor stor er forskellen? Hvad hvis du for eksempel opgraderer en kerne fra 3.0 til 4.7 – vil det påvirke ydeevnen, og hvis ja, vil ydeevnen forbedres eller ej?
Fra tid til anden får vi rapporter om alvorlige regressioner med en bestemt kerneversion eller pludselige forbedringer mellem kerneversioner. Så klart kan kerneversioner påvirke ydeevnen.
Jeg er opmærksom på et enkelt PostgreSQL-benchmark, der sammenligner forskellige kerneversioner, lavet i 2014 af Sergey Konoplev som svar på anbefalinger om at undgå 3.0 – 3.8 kerner. Men det benchmark er ret gammelt (den sidste tilgængelige kerneversion for ~18 måneder siden var 3.13, mens vi i dag har 3.19 og 4.6), så jeg har besluttet at køre nogle benchmarks med nuværende kerner (og PostgreSQL 9.6beta1).
PostgreSQL vs. kerneversioner
Men lad mig først diskutere nogle væsentlige forskelle mellem politikker, der styrer forpligtelser i de to projekter. I PostgreSQL har vi konceptet med større og mindre versioner - større versioner (f.eks. 9.5) udgives cirka en gang om året og inkluderer forskellige nye funktioner. Mindre versioner (f.eks. 9.5.2) inkluderer kun fejlrettelser og udgives cirka hver tredje måned (eller oftere, når en alvorlig fejl opdages). Så der bør ikke være nogen større ydelses- eller adfærdsændringer mellem mindre versioner, hvilket gør det ret sikkert at implementere mindre versioner uden omfattende test.
Med kerneversioner er situationen meget mindre klar. Linux-kernen har også grene (f.eks. 2.6, 3.0 eller 4.7), de er på ingen måde lig med "større versioner" fra PostgreSQL, da de fortsat modtager nye funktioner og ikke kun fejlrettelser. Jeg påstår ikke, at PostgreSQL-versionspolitikken på en eller anden måde automatisk er overlegen, men konsekvensen er, at opdatering mellem mindre kerneversioner nemt kan påvirke ydeevnen betydeligt eller endda introducere fejl (f.eks. lider 3.18.37 af OOM-problemer på grund af en sådan ikke-fejlrettelse begå).
Naturligvis indser distributioner disse risici og låser ofte kerneversionen og udfører yderligere test for at luge ud af nye fejl. Dette indlæg bruger dog langtidsholdige vaniljekerner, som er tilgængelige på www.kernel.org.
Benchmark
Der er mange benchmarks, vi kan bruge - dette indlæg præsenterer en række pgbench-tests, dvs. et ret simpelt OLTP (TPC-B-lignende) benchmark. Jeg planlægger at lave yderligere test med andre benchmarktyper (især DWH/DSS-orienterede), og jeg vil præsentere dem på denne blog i fremtiden.
Nu tilbage til pgbench - når jeg siger "samling af tests" mener jeg kombinationer af
- skrivebeskyttet vs. læse-skrive
- datasætstørrelse – aktivt sæt passer (ikke) ind i delte buffere/RAM
- klientantal – enkelt klient vs. mange klienter (låsning/planlægning)
Værdierne afhænger naturligvis af den anvendte hardware, så lad os se, hvilken hardware denne runde af benchmarks kørte på:
- CPU:Intel i5-2500k @ 3,3 GHz (3,7 GHz turbo)
- RAM:8 GB (DDR3 @ 1333 MHz)
- lagerplads:6x Intel SSD DC S3700 i RAID-10 (Linux sw raid)
- filsystem:ext4 med standard I/O-planlægger (cfq)
Så det er den samme maskine, som jeg har brugt til en række tidligere benchmarks - en ret lille maskine, ikke ligefrem den nyeste CPU osv., men jeg mener, at det stadig er et rimeligt "lille" system.
Benchmark-parametrene er:
- datasæt skalaer:30, 300 og 1500 (så ca. 450 MB, 4,5 GB og 22,5 GB)
- kundeantal:1, 4, 16 (maskinen har 4 kerner)
For hver kombination var der 3 skrivebeskyttede kørsler (15 minutter hver) og 3 læse-skrive kørsler (30 minutter hver). Selve scriptet, der driver benchmark, er tilgængeligt her (sammen med resultater og andre nyttige data).
Bemærk :Hvis du har væsentligt forskellig hardware (f.eks. rotationsdrev), kan du se meget forskellige resultater. Hvis du har et system, som du gerne vil teste, så lad mig det vide, så skal jeg hjælpe dig med det (forudsat at jeg får lov til at offentliggøre resultaterne).
Kerneversioner
Med hensyn til kerneversioner har jeg testet de seneste versioner i alle langsigtede grene siden 2.6.x (2.6.39, 3.0.101, 3.2.81, 3.4.112, 3.10.102, 3.12.61, 3.14.73, 3.16. 36, 3.18.38, 4.1.29, 4.4.16, 4.6.5 og 4.7). Der er stadig mange systemer, der kører på 2.6.x-kerner, så det er nyttigt at vide, hvor meget ydeevne du kan opnå (eller miste) ved at opgradere til en nyere kerne. Men jeg har kompileret alle kernerne på egen hånd (dvs. ved hjælp af vaniljekerner, ingen distributionsspecifikke patches), og konfigurationsfilerne er i git-lageret.
Resultater
Som sædvanlig er alle data tilgængelige på bitbucket, inklusive
- kerne .config-fil
- benchmark-script (run-pgbench.sh)
- PostgreSQL-konfiguration (med en vis grundlæggende justering af hardwaren)
- PostgreSQL-logfiler
- forskellige systemlogfiler (dmesg, sysctl, mount, …)
Følgende diagrammer viser de gennemsnitlige tps for hvert benchmarked-tilfælde – resultaterne for de tre kørsler er ret konsistente, med ~2 % forskel mellem min og max i de fleste tilfælde.
skrivebeskyttet
For det mindste datasæt er der et klart fald i ydeevnen mellem 3,4 og 3,10 for alle klientantal. Resultaterne for 16 klienter (4x antallet af kerner), men mere end genoprettes i 3.12.
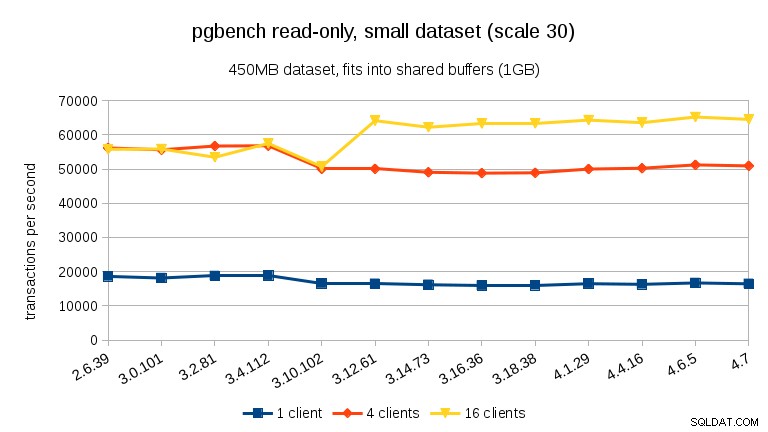
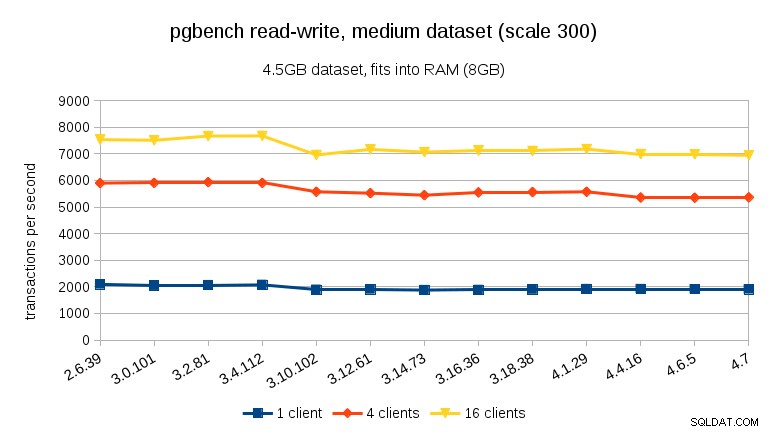
For det mellemstore datasæt (passer ind i RAM, men ikke i delte buffere), kan vi se det samme fald mellem 3.4 og 3.10, men ikke gendannelsen i 3.12.
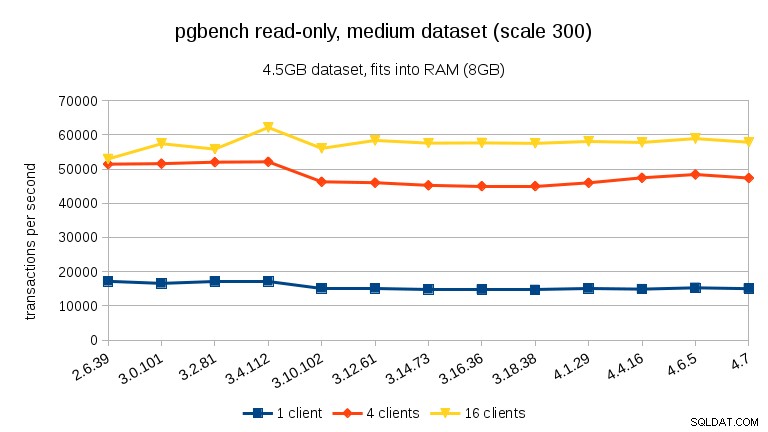
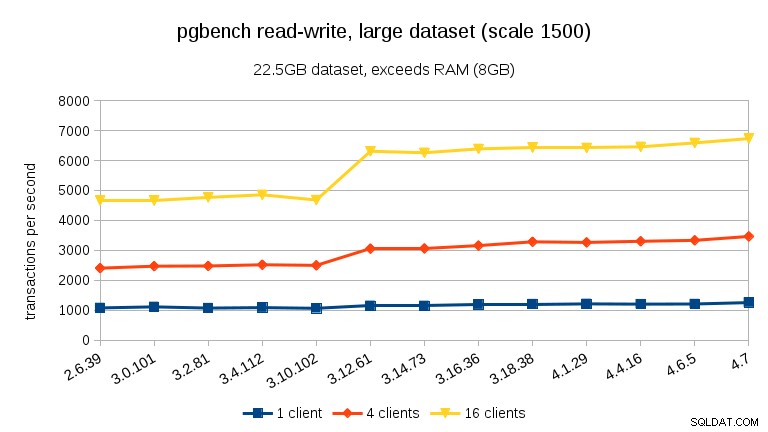
For store datasæt (som overstiger RAM, så stærkt I/O-bundet), er resultaterne meget forskellige – jeg er ikke sikker på, hvad der skete mellem 3.10 og 3.12, men ydeevneforbedringen (især for højere klientantal) er ret forbløffende.
læse-skriv
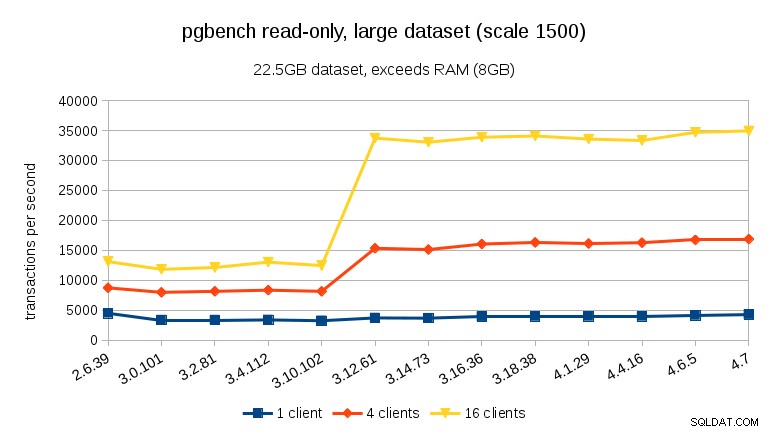
For læs-skriv-arbejdsbyrden er resultaterne nogenlunde ens. For de små og mellemstore datasæt kan vi observere det samme ~10 % fald mellem 3,4 og 3,10, men desværre ingen genopretning i 3.12.
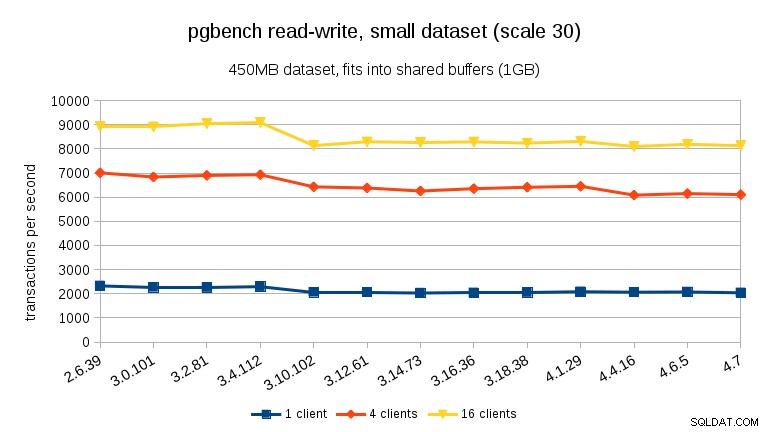
For det store datasæt (igen betydeligt I/O-bundet) kan vi se en lignende forbedring i 3.12 (ikke så signifikant som for skrivebeskyttet arbejdsbyrde, men stadig signifikant):
Oversigt
Jeg tør ikke drage konklusioner ud fra et enkelt benchmark på en enkelt maskine, men jeg tror, det er sikkert at sige:
- Den overordnede ydeevne er ret stabil, men vi kan se nogle væsentlige ændringer i ydeevnen (i begge retninger).
- Med datasæt, der passer ind i hukommelsen (enten i shared_buffers eller i det mindste i RAM), ser vi et målbart ydelsesfald mellem 3,4 og 3,10. Ved skrivebeskyttet test genoprettes dette delvist i 3.12 (men kun for mange klienter).
- Med datasæt, der overstiger hukommelsen, og dermed primært I/O-bundet, ser vi ikke sådanne ydelsesfald, men i stedet en væsentlig forbedring i 3.12.
Hvad angår årsagerne til, at de pludselige ændringer sker, er jeg ikke helt sikker. Der er mange muligvis relevante commits mellem versionerne, men jeg er ikke sikker på, hvordan man identificerer den rigtige uden omfattende (og tidskrævende) test. Hvis du har andre ideer (f.eks. er klar over sådanne forpligtelser), så lad mig det vide.