Analyserer nøglepopulationsforespørgslen noget mere
I del 3 af vores ODBC-sporingsserie vil vi tage et yderligere indblik i Access-styringsnøgler til ODBC-linkede tabeller, og hvordan det sorterer og grupperer SELECT-forespørgslerne sammen. I den forrige artikel lærte vi, hvordan et rekordsæt af dynaset-typen faktisk er 2 separate forespørgsler, hvor den første forespørgsel kun henter nøglerne til den ODBC-linkede tabel, som derefter bruges til at udfylde dataene. I denne artikel vil vi studere lidt mere om, hvordan Access administrerer nøglerne, og hvordan det udleder, hvad der er nøglen til at bruge til en ODBC-linket tabel med de konsekvenser, den har. Vi starter med sorteringen.
Tilføjelse af en sortering til forespørgslen
Du så i den forrige artikel, at vi startede med en simpel SELECT uden nogen særlig bestilling. Du så også, hvordan Access først hentede CityID og brug resultatet af den første forespørgsel til derefter at udfylde de efterfølgende forespørgsler for at give et indtryk af at være hurtig for brugeren, når du åbner et stort postsæt. Hvis du nogensinde har oplevet en situation, hvor tilføjelse af en sortering eller gruppering til en forespørgsel, pludselig går langsomt, vil dette forklare hvorfor.
Lad os tilføje en sortering på StateProvinceID i en Access-forespørgsel:
SELECT Cities.* FROM Cities ORDER BY Cities.StateProvinceID;Hvis vi nu sporer ODBC SQL, skulle vi se output:
SQLExecDirect: SELECT "Application"."Cities"."CityID" FROM "Application"."Cities" ORDER BY "Application"."Cities"."StateProvinceID" SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? SQLExecute: (GOTO BOOKMARK) SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? SQLExecute: (MULTI-ROW FETCH) SQLExecute: (MULTI-ROW FETCH)Hvis du sammenligner med sporet fra den forrige artikel, kan du se, at de er de samme bortset fra den første forespørgsel. Access sætter sorteringen i den første forespørgsel, hvor den bruger til at hente nøglerne. Det giver mening, da ved at håndhæve sorteringen på de nøgler, den bruger til at gå gennem posterne, er Access garanteret at have en en-til-én-korrespondance mellem en posts ordinære position, og hvordan den skal sorteres. Det udfylder derefter posterne på nøjagtig samme måde. Den eneste forskel er rækkefølgen af nøgler, den bruger til at udfylde de andre forespørgsler.
Lad os overveje, hvad der sker, når vi tilføjer en GROUP BY ved at foretage en optælling af byerne pr. stat:
SELECT Cities.StateProvinceID ,Count(Cities.CityID) AS CountOfCityID FROM Cities GROUP BY Cities.StateProvinceID;Sporing skal udskrive:
SQLExecDirect:
SELECT
"StateProvinceID"
,COUNT("CityID" )
FROM "Application"."Cities"
GROUP BY "StateProvinceID" Du har måske også bemærket, at forespørgslen nu åbner langsomt, og selvom den kan være indstillet som et rekordsæt af dynaset-typen, valgte Access at ignorere dette og grundlæggende behandle det som et rekordsæt af snapshot-typen. Dette giver mening, fordi forespørgslen ikke kan opdateres, og fordi du ikke rigtig kan navigere til en vilkårlig position i en forespørgsel som denne. Du skal altså vente til alle rækker er hentet før du frit kan browse. StateProvinceID kan ikke bruges til at finde en post, da der ville være flere poster i Cities bord. Selvom jeg brugte en GROUP BY i dette eksempel behøver det ikke at være en gruppering, der får Access til at bruge et snapshot type recordset i stedet. Brug af DISTINCT for eksempel ville have samme effekt. En nyttig tommelfingerregel til at forudsige, om Access vil bruge recordset af dynaset-typen, er at spørge, om en given række i det resulterende postsæt er kortlagt tilbage til nøjagtig én række i ODBC-datakilden. Hvis det ikke er tilfældet, vil Access bruge snapshot-adfærd, selvom forespørgslen skulle bruge dynaset. Bare fordi standarden er et rekordsæt af dynaset-typen, garanterer det derfor ikke, at det rent faktisk vil være et rekordsæt af dynaset-typen. Det er blot en anmodning , ikke et krav.
At bestemme den nøgle, der skal bruges til at vælge
Du har muligvis bemærket i den tidligere sporede SQL i både denne og tidligere artikler, at Access brugte CityID som nøglen. Denne kolonne blev hentet i den første forespørgsel og derefter brugt i efterfølgende forberedte forespørgsler. Men hvordan ved Access, hvilke kolonne(r) i en sammenkædet tabel den skal bruge? Den første tilbøjelighed ville være at sige, at den søger efter en primær nøgle og bruger den. Det ville dog være forkert. Faktisk vil Access-databasemotoren gøre brug af ODBC's SQLStatistics funktion under sammenkædning eller genkobling af tabellen for at undersøge, hvilke indekser der er tilgængelige. Denne funktion returnerer et resultatsæt med en række for hver kolonne, der deltager i et indeks for alle indekser. Dette resultatsæt er altid sorteret, og efter konvention vil det altid sortere klyngede indekser, hashed-indekser og derefter andre indekstyper. Inden for hver indekstype vil indeksene blive sorteret efter deres navne alfabetisk. Access-databasemotoren vil vælge det første unikke indeks, den finder, selvom det ikke er den faktiske primære nøgle. For at bevise dette vil vi lave en fjollet tabel med nogle ulige indekser:
CREATE TABLE dbo.SillyTable ( ID int CONSTRAINT PK_SillyTable PRIMARY KEY NONCLUSTERED, OtherStuff int CONSTRAINT UQ_SillyTable_OtherStuff UNIQUE CLUSTERED, SomeValue nvarchar(255) );Hvis vi så udfylder tabellen med nogle data og linker til dem i Access og åbner en dataarkvisning på den linkede tabel, vil vi se dette i sporet ODBC SQL. For kortheds skyld er kun de første 2 kommandoer inkluderet.
SQLExecDirect: SELECT "dbo"."SillyTable"."OtherStuff" FROM "dbo"."SillyTable" SQLPrepare: SELECT "ID" ,"OtherStuff" ,"SomeValue" FROM "dbo"."SillyTable" WHERE "OtherStuff" = ?Fordi
OtherStuff deltager i et klynget indeks, kom det før den egentlige primære nøgle og blev således valgt af Access-databasemotoren til at blive brugt i dynaset-type recordset til at vælge en individuel række. Det er også på trods af, at det unikke klyngede indekss navn ville være kommet efter det primære indekss navn. En taktik til at tvinge Access-databasemotor til at vælge et bestemt indeks til en tabel ville være at ændre dens type eller omdøbe navnet, så det sorterer alfabetisk inden for indekstypens gruppe. I tilfælde af SQL Server er primærnøgler normalt klynget, og der kan kun være ét klynget indeks, så det er en lykkelig ulykke, at det normalt er det korrekte indeks, som Access-databasemotoren skal bruge. Men hvis SQL Server-databasen indeholder tabeller med ikke-klyngede primærnøgler, og der er et klynget unikt indeks, er det muligvis ikke det optimale valg. I de tilfælde, hvor der slet ikke er klyngede indekser, kan du påvirke, hvilke unikke indekser, der bliver brugt ved at navngive indekset, så det sorterer før andre indekser. Det kan være nyttigt med anden RDBMS-software, hvor det ikke er praktisk eller muligt at oprette et klynget indeks for primærnøgle. Adgangssideindeks for linket SQL-visning eller tabel uden indekser
Når du linker til en SQL-visning eller en SQL-tabel, der ikke har defineret nogen indekser eller primærnøgle, vil der ikke være nogen tilgængelige indekser, som Access-databasemotoren kan bruge. Hvis du har brugt linket tabelmanager til at linke en tabel eller en SQL-visning uden indekser, har du muligvis set en dialog som denne:
 Hvis vi vælger
Hvis vi vælger ID , fuldfør sammenkædningen, åbn den sammenkædede tabel i designvisning, og derefter indeksdialogen, skulle vi se dette:
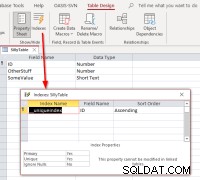 Det viser, at tabellen har et indeks ved navn
Det viser, at tabellen har et indeks ved navn __uniqueindex men det findes ikke i den originale datakilde. Hvad sker der? Svaret er, at Access oprettede en Adgangsside indeks til brug for at hjælpe med at identificere, hvilke der kan bruges som en post-id for sådanne tabeller eller visninger. Hvis du tilfældigvis genlinker tabellerne i stedet for at bruge Linked Table Manager, vil du finde det nødvendigt at replikere adfærden for at gøre sådanne sammenkædede tabeller opdaterbare. Dette kan gøres ved at udføre en Access SQL-kommando:
CREATE UNIQUE INDEX [__uniqueindex] ON SillyTable (ID);Du kan f.eks. bruge
CurrentDb.Execute for at udføre Access SQL for at oprette indekset på den sammenkædede tabel. Du bør dog ikke udføre det som en pass-through-forespørgsel, fordi indekset faktisk ikke er oprettet på serveren. Det er kun til fordel for Access at tillade opdatering på den linkede tabel. Det er værd at bemærke, at Access kun vil tillade præcis ét indeks for en sådan linket tabel og kun hvis den ikke allerede har indekser. Ikke desto mindre kan du se, at brug af en SQL-visning kan være en ønskværdig mulighed i tilfælde, hvor databasedesignet ikke tillader dig at bruge klyngede indekser, og du ikke ønsker at rode med indeksets navn for at overtale Access-databasemotoren til at bruge dette indeks, ikke det indeks. Du kan eksplicit kontrollere indekset og de kolonner, det skal inkludere, når du forbinder SQL-visningen.
Konklusioner
Fra tidligere artikel så vi, at et rekordsæt af dynaset-typen normalt udsender 2 forespørgsler. Den første forespørgsel beskæftiger sig normalt med at udfylde den. Vi så nærmere på, hvordan Access håndterer den population af nøgler, den vil bruge til et recordsæt af dynaset-typen. Vi så, hvordan Access faktisk vil konvertere enhver sortering fra den originale Access-forespørgsel og derefter bruge den i nøglepopulationsforespørgslen. Vi så, at rækkefølgen af nøglepopulationsforespørgslen direkte påvirker, hvordan dataene i postsættet vil blive sorteret og præsenteret for brugeren. Dette gør det muligt for brugeren at gøre ting som at springe til en abritær post baseret på den ordinære placering af listen.
Vi så derefter, at gruppering og andre SQL-operationer, der forhindrer en-en-mapping mellem den returnerede række og den oprindelige række, vil få Access til at behandle Access-forespørgslen, som om det var et snapshot-type recordset på trods af anmodning om et dynaset-type recordset.
Vi så derefter på, hvordan Access bestemmer nøglen, der skal bruges til at administrere opdateringer med en ODBC-linket tabel. I modsætning til hvad vi kunne forvente, vil den ikke nødvendigvis vælge tabellens primære nøgle, men snarere det første unikke indeks, den finder, afhængigt af indeksets type og indeksets navn. Vi diskuterede strategier for at sikre, at Access vælger det korrekte unikke indeks. Vi kiggede på SQL-visning, som normalt ikke har nogen indekser, og diskuterede en metode for os til at informere Access om, hvordan man indtaster en SQL-visning eller en tabel, der ikke har nogen primær nøgle, hvilket giver os mere kontrol over, hvordan Access vil håndtere opdateringerne for disse ODBC-linkede tabeller.
I den næste artikel vil vi se på, hvordan Access rent faktisk udfører opdateringer på dataene, når brugere foretager ændringer via Access-forespørgslen eller registreringskilden.
Vores adgangseksperter står til rådighed for at hjælpe. Ring til os på 773-809-5456 eller e-mail os på sales@itimpact.com.