PostgreSQL er et fantastisk projekt, og det udvikler sig med en fantastisk hastighed. Vi vil fokusere på udviklingen af fejltolerance-kapaciteter i PostgreSQL gennem dens versioner med en række blogindlæg. Dette er det fjerde indlæg i serien, og vi vil tale om synkron commit og dets indvirkning på fejltolerance og pålidelighed af PostgreSQL.
Hvis du gerne vil være vidne til udviklingen fra begyndelsen, så tjek venligst de første tre blogindlæg i serien nedenfor. Hvert indlæg er uafhængigt, så du behøver faktisk ikke at læse det ene for at forstå det andet.
- Udvikling af fejltolerance i PostgreSQL
- Udvikling af fejltolerance i PostgreSQL:Replikeringsfase
- Udvikling af fejltolerance i PostgreSQL:Tidsrejse
Synchronous Commit
Som standard implementerer PostgreSQL asynkron replikering, hvor data streames ud, når det passer til serveren. Dette kan betyde tab af data i tilfælde af failover. Det er muligt at bede Postgres om at kræve en (eller flere) standbyer for at anerkende replikering af dataene før commit, dette kaldes synkron replikering (synkron commit ) .
Med synkron replikering forsinker replikeringen direkte påvirker den forløbne tid for transaktioner på masteren. Med asynkron replikering kan masteren fortsætte med fuld hastighed.
Synkron replikering garanterer, at data skrives til mindst to knudepunkter, før brugeren eller applikationen får at vide, at en transaktion er foretaget.
Brugeren kan vælge commit-tilstand for hver transaktion , så det er muligt at have både synkrone og asynkrone commit-transaktioner kørende samtidigt.
Dette muliggør fleksible afvejninger mellem ydeevne og sikkerhed for transaktionens holdbarhed.
Konfiguration af Synchronous Commit
For at opsætte synkron replikering i Postgres skal vi konfigurere synchronous_commit parameter i postgresql.conf.
Parameteren angiver, om transaktionsbekræftelse vil vente på, at WAL-poster bliver skrevet til disken, før kommandoen returnerer en succes indikation til klienten. Gyldige værdier er til , remote_apply , remote_write , lokal , og fra . Vi vil diskutere, hvordan tingene fungerer med hensyn til synkron replikering, når vi opsætter synchronous_commit parameter med hver af de definerede værdier.
Lad os starte med Postgres-dokumentation (9.6):
Her forstår vi konceptet med synkron commit, som vi beskrev i introduktionsdelen af indlægget, du er fri til at opsætte synkron replikering, men hvis du ikke gør det, er der altid en risiko for at miste data. Men uden risiko for at skabe databaseinkonsistens, i modsætning til at slå fsync off – men det er et emne for et andet indlæg -. Til sidst konkluderer vi, at hvis vi har brug for det, ønsker vi ikke at miste nogen data mellem replikeringsforsinkelser og ønsker at være sikre på, at dataene er skrevet til mindst to noder, før brugeren/applikationen informeres om, at transaktionen har begået , vi er nødt til at acceptere at miste nogle præstationer.
Lad os se, hvordan forskellige indstillinger fungerer for forskellige niveauer af synkronisering. Før vi starter, lad os tale om, hvordan commit behandles af PostgreSQL-replikering. Klienten udfører forespørgsler på masternoden, ændringerne skrives til en transaktionslog (WAL) og kopieres over netværket til WAL på standby-knuden. Gendannelsesprocessen på standby-noden læser derefter ændringerne fra WAL og anvender dem på datafilerne ligesom under gendannelse af nedbrud. Hvis standby er i hot standby tilstand, kan klienter udstede skrivebeskyttede forespørgsler på noden, mens dette sker. For flere detaljer om, hvordan replikering fungerer, kan du tjekke replikeringsblogindlægget i denne serie.
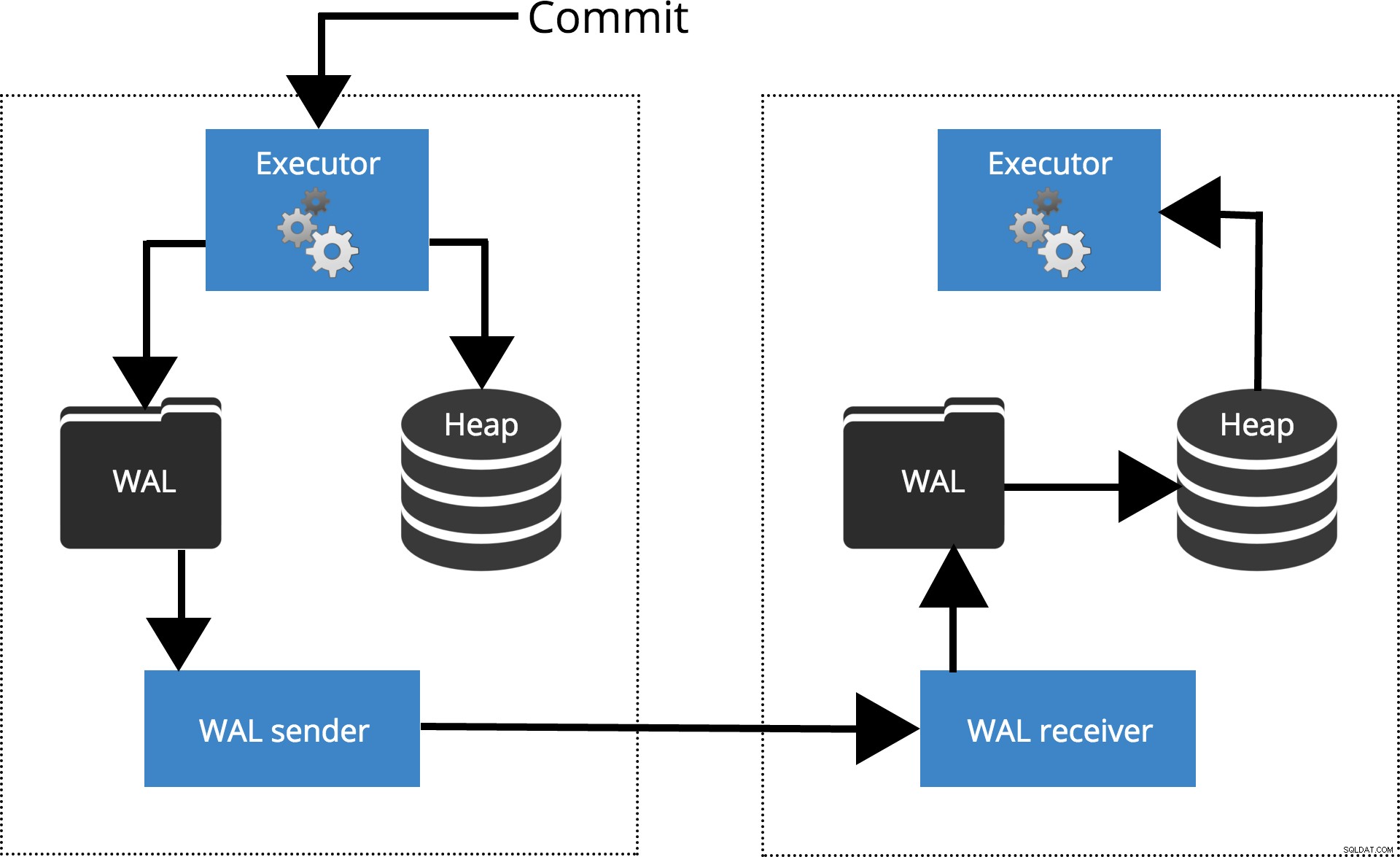
Fig.1 Sådan fungerer replikering
synchronous_commit =off
Når vi indstiller sychronous_commit = off, COMMIT venter ikke på, at transaktionsposten bliver tømt til disken. Dette er fremhævet i fig.2 nedenfor.
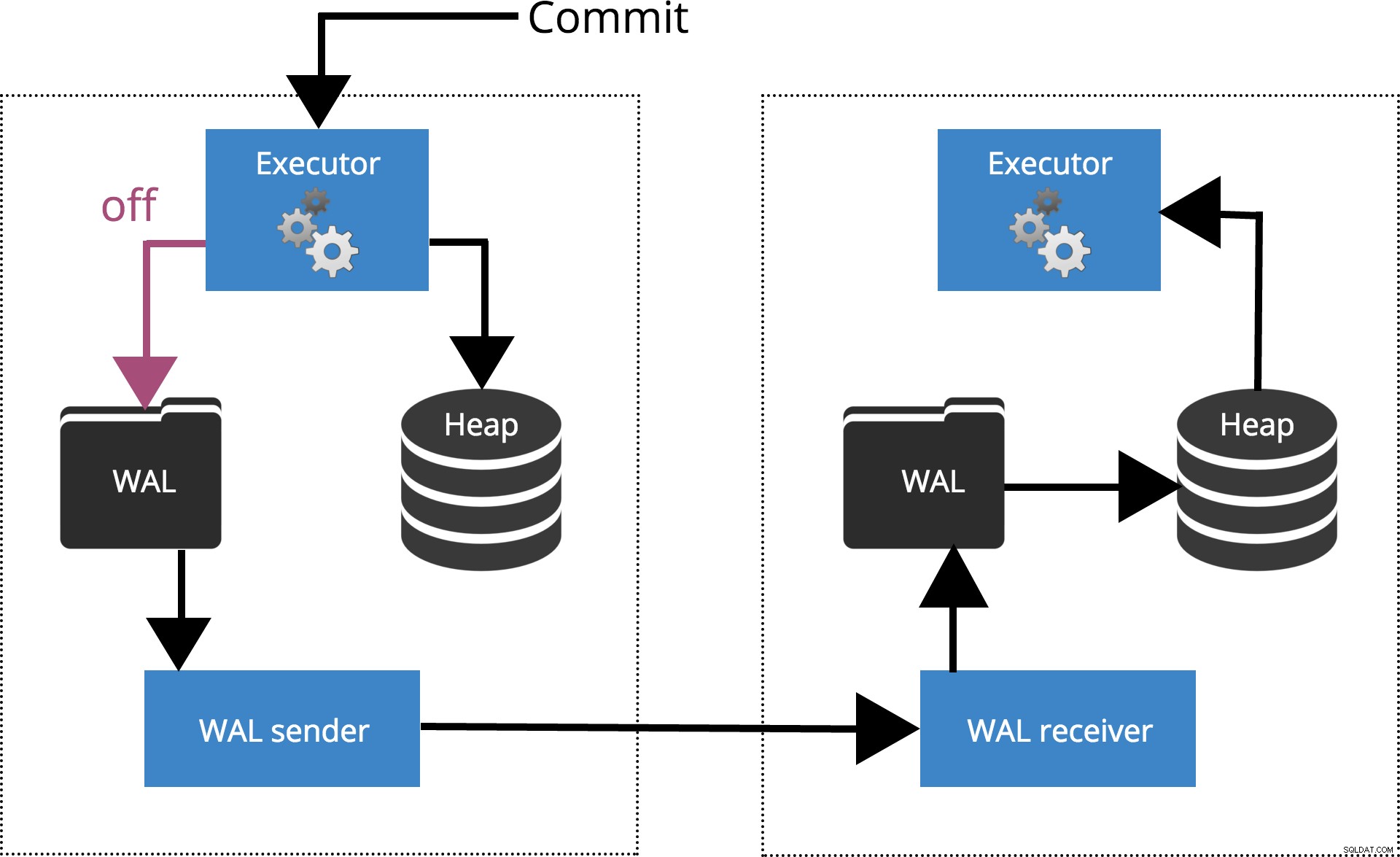
Fig.2 synchronous_commit =off
synchronous_commit =lokal
Når vi indstiller synchronous_commit = local, COMMIT venter, indtil transaktionsposten er tømt til den lokale disk. Dette er fremhævet i fig. 3 nedenfor.
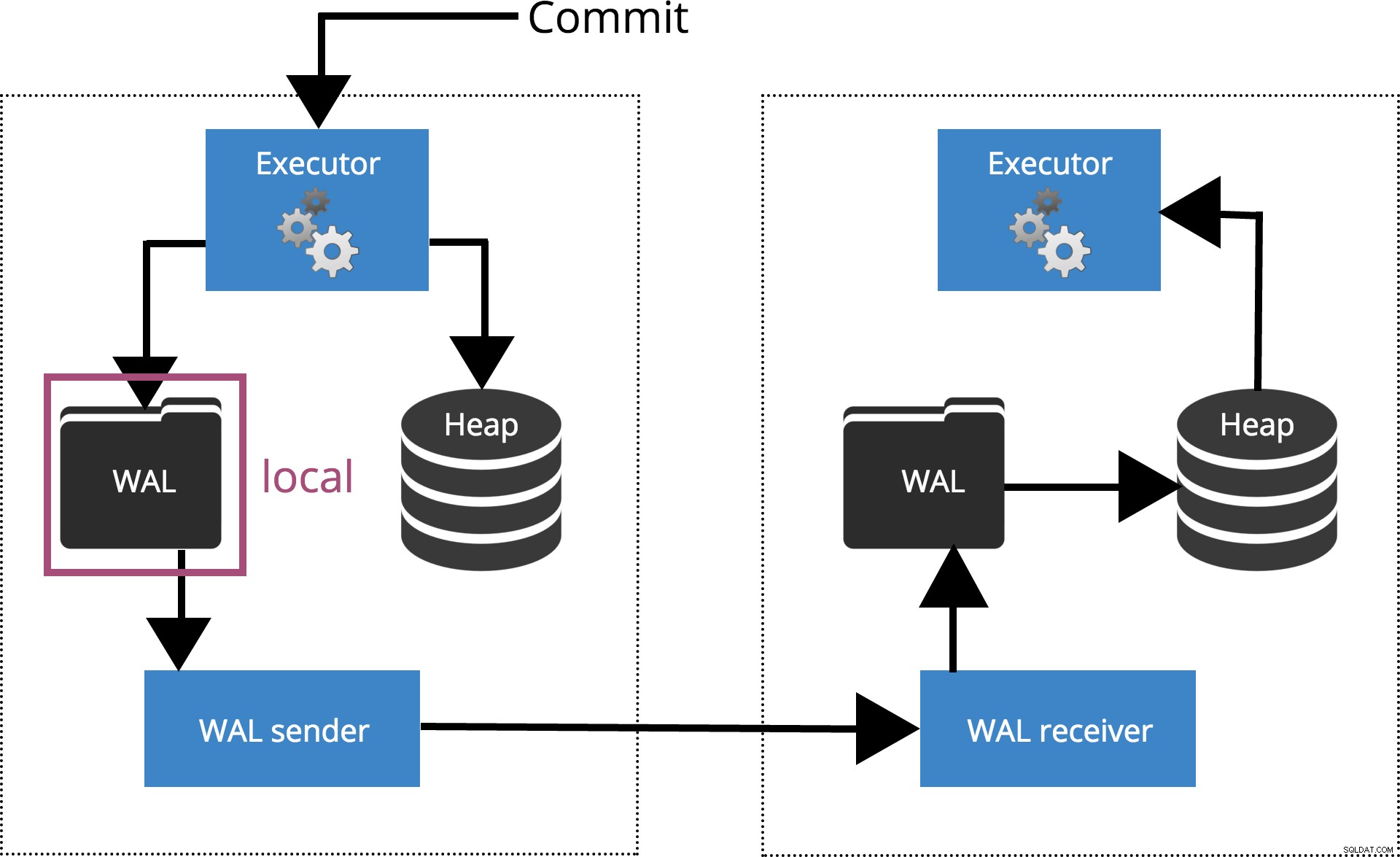
Fig.3 synchronous_commit =lokal
synchronous_commit =tændt (standard)
Når vi sætter synchronous_commit = on, COMMIT vil vente indtil serveren(e) specificeret af synchronous_standby_names bekræfte, at transaktionsposten blev skrevet sikkert til disken. Dette er fremhævet i fig. 4 nedenfor.
Bemærk: Når synchronous_standby_names er tom, opfører denne indstilling det samme som synchronous_commit = local .
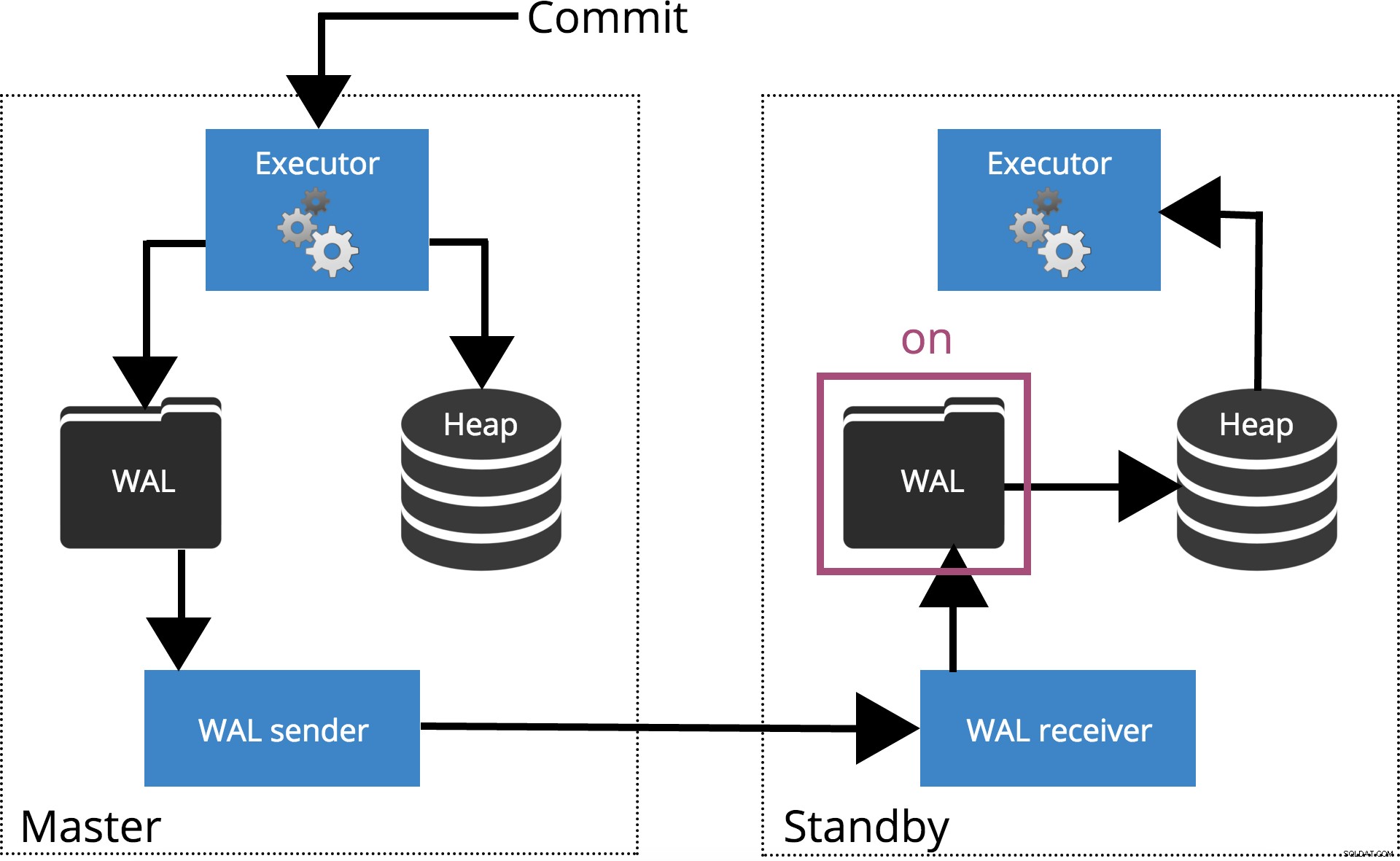
Fig.4 synchronous_commit =on
synchronous_commit =remote_write
Når vi indstiller synchronous_commit = remote_write, COMMIT vil vente indtil serveren(e) specificeret af synchronous_standby_names bekræfte skrivning af transaktionsposten til operativsystemet, men har ikke nødvendigvis nået disken. Dette er fremhævet i fig. 5 nedenfor.
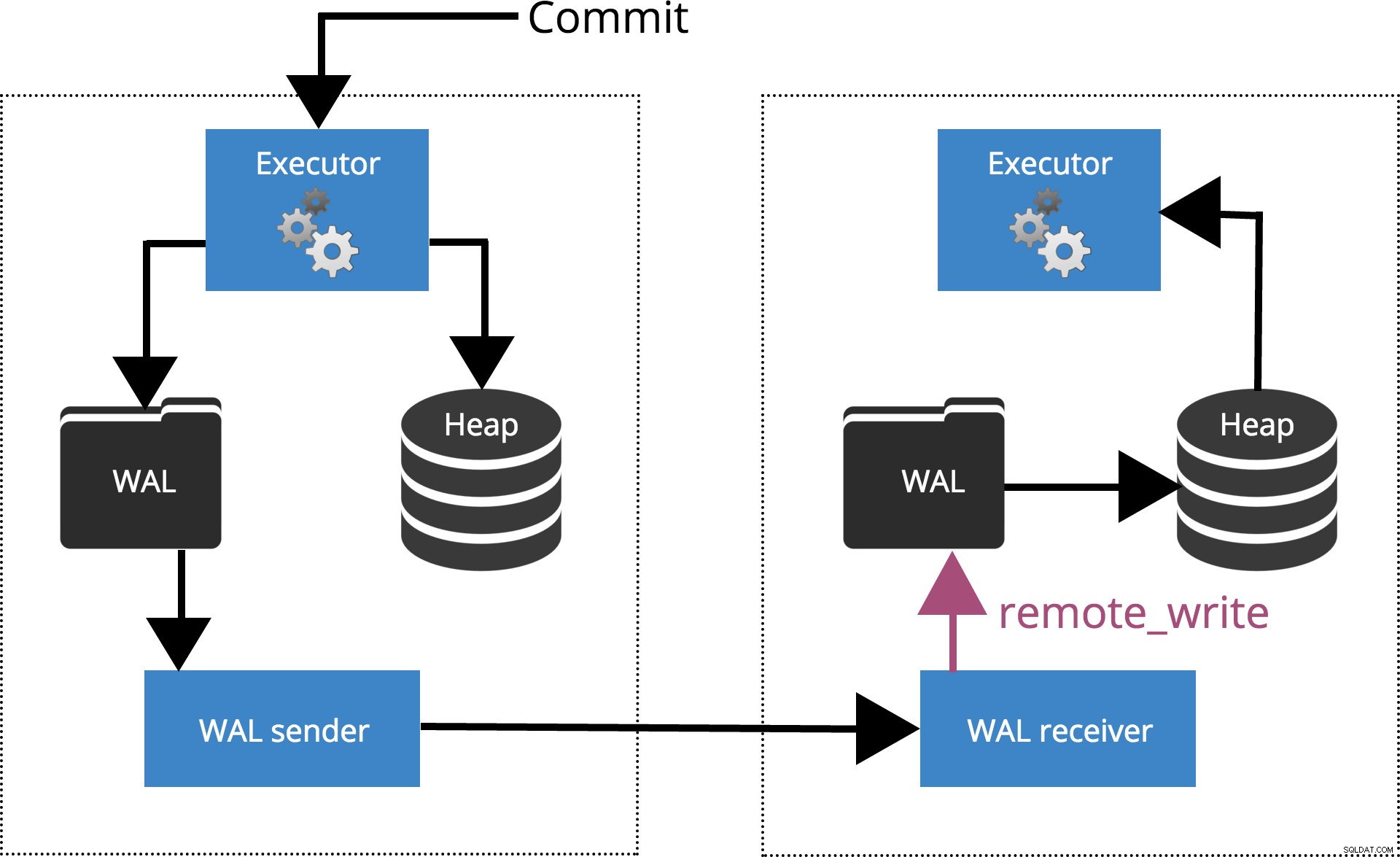
Fig.5 synchronous_commit =remote_write
synchronous_commit =remote_apply
Når vi indstiller synchronous_commit = remote_apply, COMMIT vil vente indtil serveren(e) specificeret af synchronous_standby_names bekræfte, at transaktionsposten blev anvendt på databasen. Dette er fremhævet i fig. 6 nedenfor.
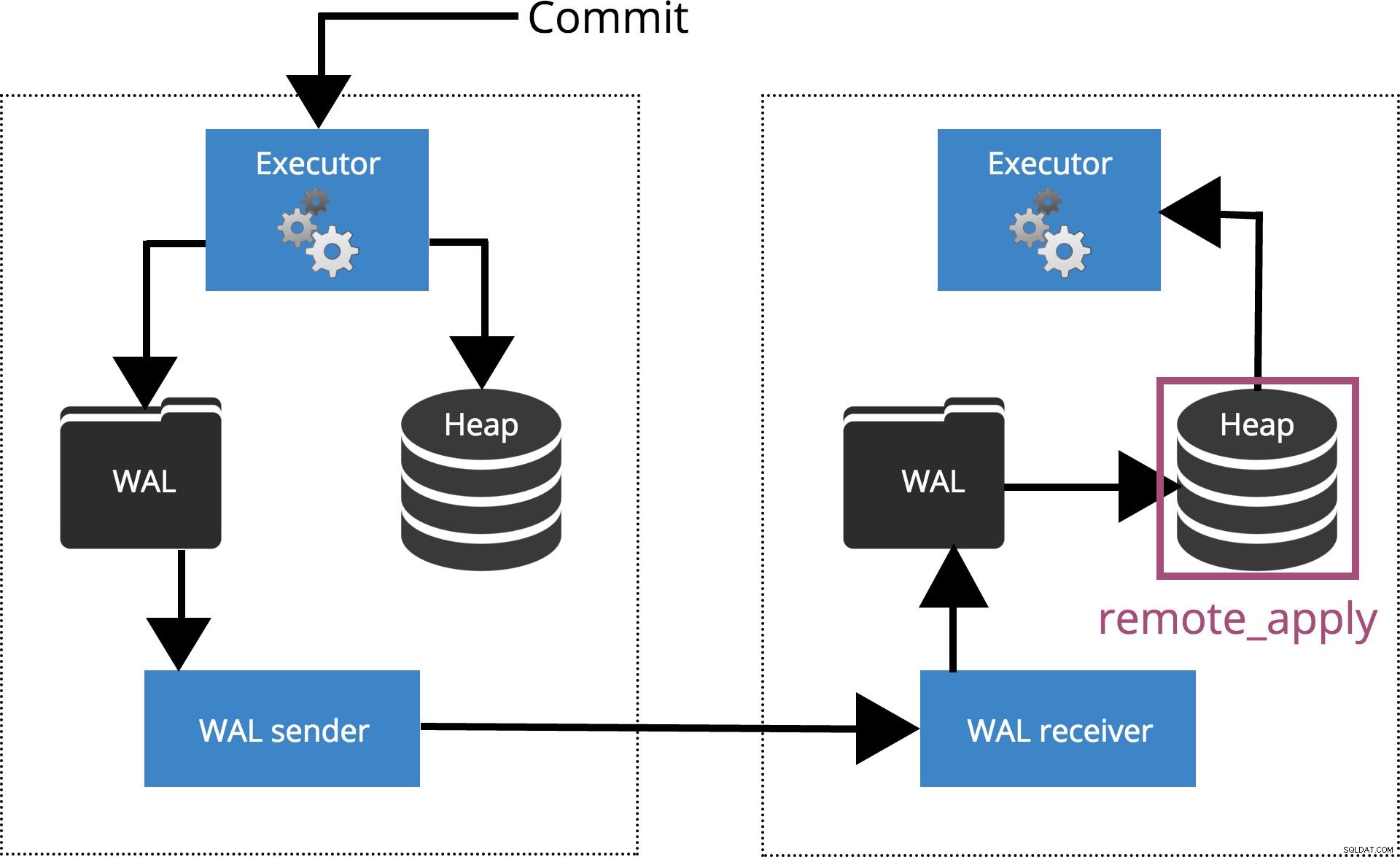
Fig.6 synchronous_commit =remote_apply
Lad os nu se på sychronous_standby_names parameter i detaljer, som henvises til ovenfor ved indstilling af synchronous_commit som on , remote_apply eller remote_write .
synchronous_standby_names ='standby_name [, …]'
Den synkrone commit vil vente på svar fra en af de standbyer, der er anført i prioriteret rækkefølge. Dette betyder, at hvis første standby er tilsluttet og streamer, vil den synkrone commit altid vente på svar fra den, selvom den anden standby allerede har svaret. Den særlige værdi af * kan bruges som stanby_name som vil matche enhver tilsluttet standby.
synchronous_standby_names ='num (standby_name [, …])'
Den synkrone commit vil vente på svar fra mindst num antal standbys i prioriteret rækkefølge. Samme regler som ovenfor gælder. Så for eksempel indstilling af synchronous_standby_names = '2 (*)' vil få synkron commit til at vente på svar fra alle 2 standby-servere.
synchronous_standby_names er tom
Hvis denne parameter er tom som vist, ændrer den adfærd for indstillingen synchronous_commit til on , remote_write eller remote_apply at opføre sig på samme måde som local (dvs. COMMIT vil kun vente på skylning til lokal disk).
Konklusion
I dette blogindlæg diskuterede vi synkron replikering og beskrev forskellige beskyttelsesniveauer, som er tilgængelige i Postgres. Vi fortsætter med logisk replikering i næste blogindlæg.
Referencer
Særlig tak til min kollega Petr Jelinek for at give mig ideen til illustrationer.
PostgreSQL-dokumentation
PostgreSQL 9 Administration Kogebog – Anden udgave