PostgreSQL er et fantastisk projekt, og det udvikler sig med en fantastisk hastighed. Vi vil fokusere på udviklingen af fejltolerance-egenskaber i PostgreSQL gennem dens versioner med en række blogindlæg. Dette er det tredje indlæg i serien, og vi vil tale om tidslinjeproblemer og deres indvirkning på fejltolerance og pålidelighed af PostgreSQL.
Hvis du gerne vil være vidne til udviklingen fra begyndelsen, så tjek venligst de to første blogindlæg i serien:
- Udvikling af fejltolerance i PostgreSQL
- Udvikling af fejltolerance i PostgreSQL:Replikeringsfase

Tidslinjer
Evnen til at gendanne databasen til et tidligere tidspunkt skaber nogle kompleksiteter, som vi vil dække nogle af tilfældene ved at forklare failover (Fig. 1), skift (Fig. 2) og pg_rewind (Fig. 3) tilfælde senere i dette emne.
For eksempel, i den oprindelige historie af databasen, antag, at du droppede en kritisk tabel kl. 17:15 tirsdag aften, men ikke indså din fejl før onsdag middag. Uberørt får du din backup ud, gendanner til tidspunktet 17:14 tirsdag aften og er oppe og køre. I denne historie af databaseuniverset tabte du aldrig bordet. Men antag, at du senere indser, at dette ikke var sådan en god idé, og du gerne vil vende tilbage til engang onsdag morgen i den oprindelige historie. Det vil du ikke være i stand til, hvis den, mens din database var oppe at køre, overskrev nogle af WAL-segmentfilerne, der førte frem til det tidspunkt, du nu ville ønske, du kunne vende tilbage til.
For at undgå dette er du derfor nødt til at skelne rækken af WAL-poster, der er genereret, efter du har foretaget en punkt-i-tidsgendannelse, fra dem, der blev genereret i den oprindelige databasehistorik.
For at håndtere dette problem har PostgreSQL en forestilling om tidslinjer. Hver gang en arkivgendannelse er fuldført, oprettes en ny tidslinje for at identificere rækken af WAL-poster, der er genereret efter denne gendannelse. Tidslinje-id-nummeret er en del af WAL-segmentfilnavne, så en ny tidslinje overskriver ikke de WAL-data, der er genereret af tidligere tidslinjer. Det er faktisk muligt at arkivere mange forskellige tidslinjer.
Overvej situationen, hvor du ikke er helt sikker på, hvilket tidspunkt du skal gendanne til, og derfor er nødt til at foretage flere retableringer ved forsøg og fejl, indtil du finder det bedste sted at forgrene dig fra den gamle historie. Uden tidslinjer ville denne proces snart skabe et uoverskueligt rod. Med tidslinjer kan du gendanne en hvilken som helst tidligere tilstand, inklusive tilstande i tidslinjegrene, som du forlod tidligere.
Hver gang en ny tidslinje oprettes, opretter PostgreSQL en "tidslinjehistorik"-fil, der viser, hvilken tidslinje den forgrenede sig fra og hvornår. Disse historiefiler er nødvendige for at give systemet mulighed for at vælge de rigtige WAL-segmentfiler, når de gendannes fra et arkiv, der indeholder flere tidslinjer. Derfor arkiveres de i WAL-arkivområdet ligesom WAL-segmentfiler. Historiefilerne er kun små tekstfiler, så det er billigt og passende at opbevare dem på ubestemt tid (i modsætning til segmentfilerne, der er store). Du kan, hvis du vil, tilføje kommentarer til en historiefil for at registrere dine egne noter om, hvordan og hvorfor netop denne tidslinje blev oprettet. Sådanne kommentarer vil være særligt værdifulde, når du har et krat af forskellige tidslinjer som et resultat af eksperimenter.
Standardadfærden for gendannelse er at gendanne langs den samme tidslinje, som var aktuel, da den grundlæggende backup blev taget. Hvis du ønsker at gendanne til en underordnet tidslinje (dvs. du vil vende tilbage til en tilstand, der selv blev genereret efter et gendannelsesforsøg), skal du angive måltidslinje-id'et i recovery.conf. Du kan ikke gendanne til tidslinjer, der forgrenede sig tidligere end basissikkerhedskopieringen.
For at forenkle tidslinjekonceptet i PostgreSQL, tidslinjerelaterede problemer i tilfælde af failover , skift og pg_rewind er opsummeret og forklaret med fig. 1, fig. 2 og fig. 3.
Failover-scenarie:
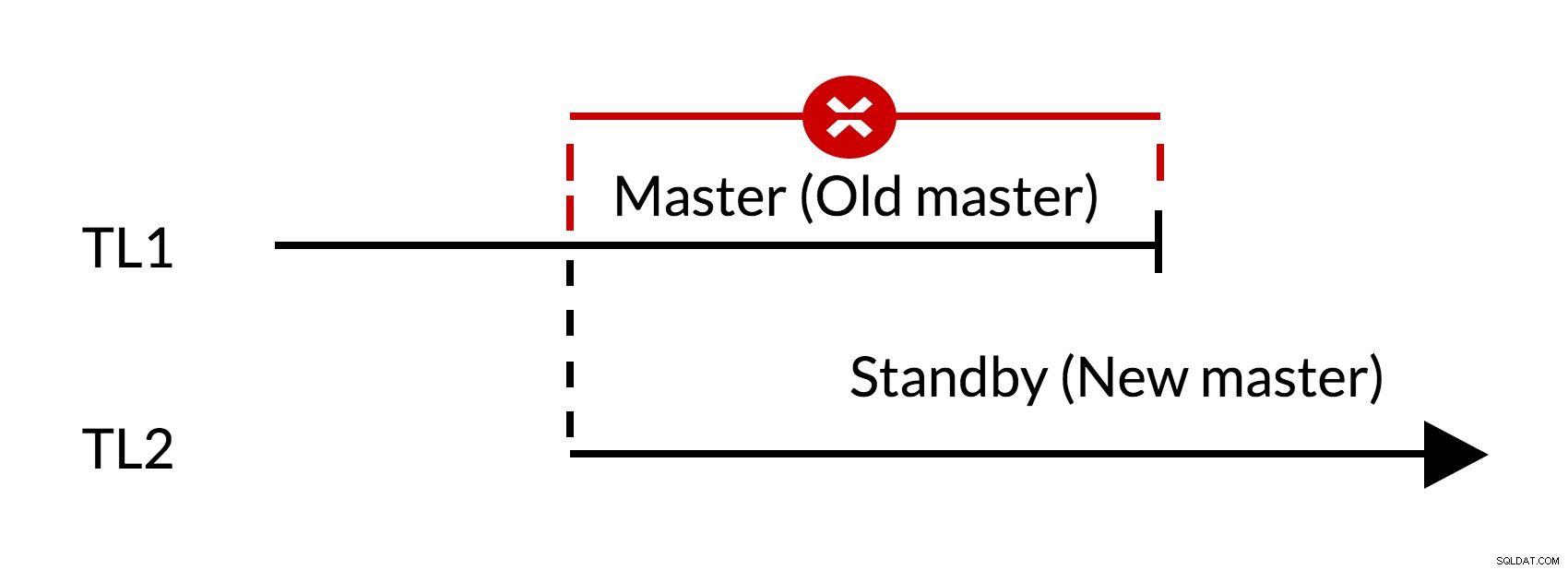
Fig. 1 Failover
- Der er udestående ændringer i den gamle master (TL1)
- Tidslinjeforøgelse repræsenterer ny historik over ændringer (TL2)
- Ændringer fra den gamle tidslinje kan ikke afspilles igen på de servere, der skiftede til ny tidslinje
- Den gamle mester kan ikke følge den nye mester
Scenario med skift:
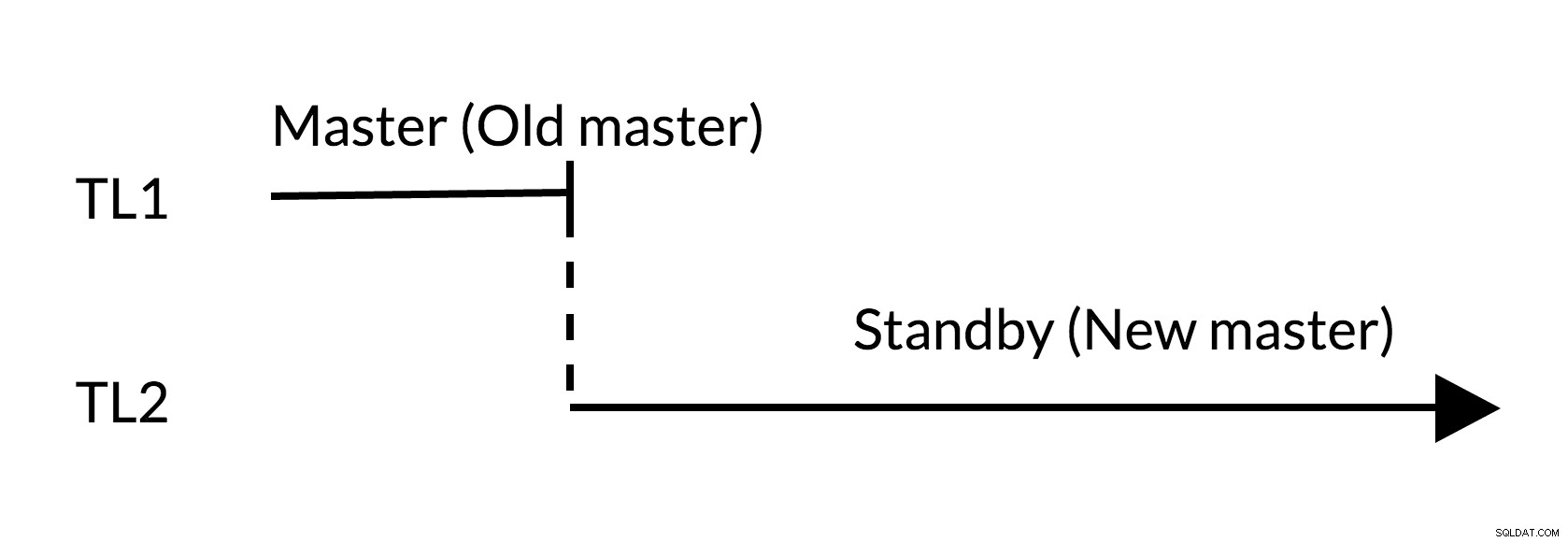 Fig.2 Skift
Fig.2 Skift
- Der er ingen udestående ændringer i den gamle master (TL1)
- Tidslinjeforøgelse repræsenterer ny historie med ændringer (TL2)
- Den gamle master kan blive standby for den nye master
pg_rewind scenario:
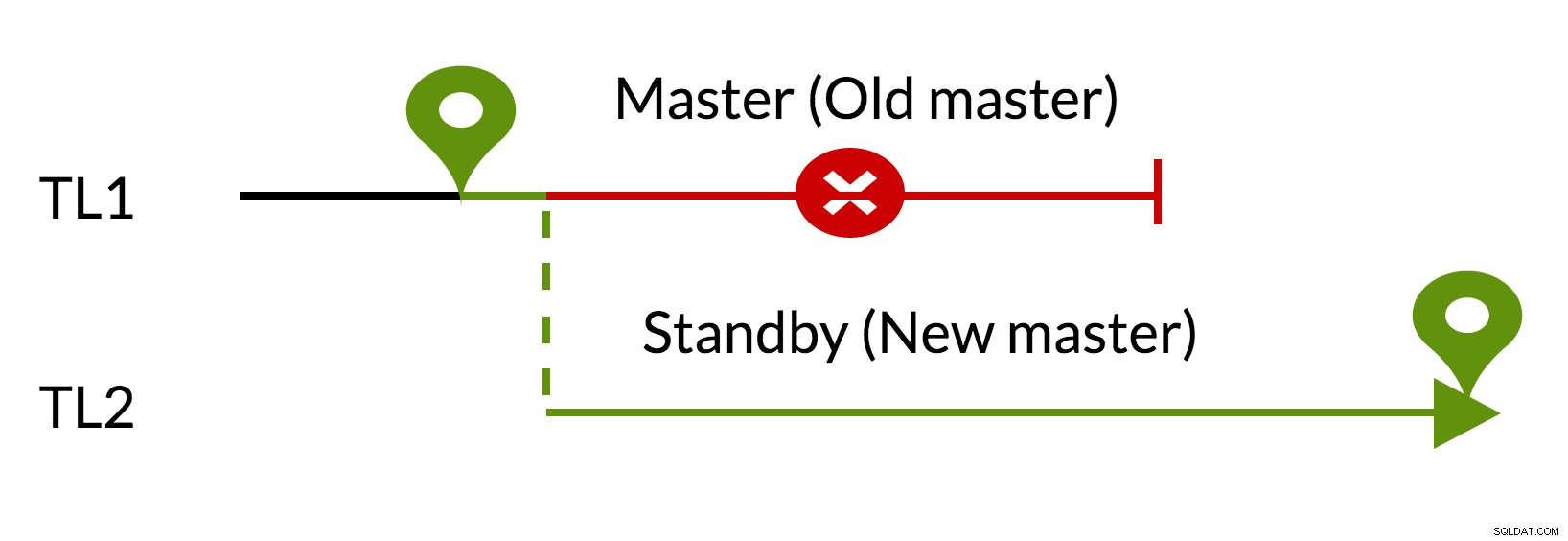 Fig.3 pg_rewind
Fig.3 pg_rewind
- Udestående ændringer fjernes ved hjælp af data fra den nye master (TL1)
- Den gamle master kan følge den nye master (TL2)
pg_rewind
pg_rewind er et værktøj til at synkronisere en PostgreSQL-klynge med en anden kopi af den samme klynge, efter at klyngernes tidslinjer er divergeret. Et typisk scenarie er at bringe en gammel masterserver online igen efter failover, som en standby, der følger den nye master.
Resultatet svarer til at erstatte måldatabiblioteket med kilden. Alle filer kopieres, inklusive konfigurationsfiler. Fordelen ved pg_rewind i forhold til at tage en ny basis backup, eller værktøjer som rsync, er, at pg_rewind ikke kræver gennemlæsning af alle uændrede filer i klyngen. Det gør det meget hurtigere, når databasen er stor, og kun en lille del af den adskiller sig mellem klyngerne.
Hvordan virker det?
Den grundlæggende idé er at kopiere alt fra den nye klynge til den gamle klynge, bortset fra de blokke, som vi ved er de samme.
- Scan WAL-loggen for den gamle klynge, startende fra det sidste kontrolpunkt før det punkt, hvor den nye klynges tidslinjehistorik forgrenede sig fra den gamle klynge. For hver WAL-post skal du notere de datablokke, der blev berørt. Dette giver en liste over alle de datablokke, der er blevet ændret i den gamle klynge, efter at den nye klynge blev forgrenet.
- Kopiér alle de ændrede blokke fra den nye klynge til den gamle klynge.
- Kopiér alle andre filer såsom tilstopning og konfigurationsfiler fra den nye klynge til den gamle klynge, alt undtagen relationsfilerne.
- Anvend WAL fra den nye klynge, startende fra det kontrolpunkt, der blev oprettet ved failover. (Strengt taget anvender pg_rewind ikke WAL, den opretter bare en backup-etiketfil, der indikerer, at når PostgreSQL startes, vil den starte genafspilning fra det kontrolpunkt og anvende alle de nødvendige WAL.)
Bemærk: wal_log_hints skal indstilles i postgresql.conf for at pg_rewind kan fungere. Denne parameter kan kun indstilles ved serverstart. Standardværdien er fra .
Konklusion
I dette blogindlæg diskuterede vi tidslinjer i Postgres, og hvordan vi håndterer failover- og overgangssager. Vi talte også om, hvordan pg_rewind virker og dets fordele for Postgres fejltolerance og pålidelighed. Vi fortsætter med synkron commit i næste blogindlæg.
Referencer
PostgreSQL-dokumentation
PostgreSQL 9 Administration Kogebog – Anden udgave
pg_rewind Nordic PGDay-præsentation af Heikki Linnakangas