Hvordan bliver al den offentlige meningsdata gemt? Vi tjekker en meningsmålingsdatamodel.
Alle vil gerne vide, hvad offentligheden mener, lige fra politikere og virksomheder til enkeltpersoner, der gerne vil vide, hvad andre mener om et bestemt emne. Denne form for job udføres normalt af bureauer, der specialiserer sig i den type forskning.
I dag vil vi tage et kig på en datamodel, som et sådant bureau kunne bruge til at gemme alle relevante meningsmålingsdata, fra spørgsmål og foruddefinerede svar til den faktiske feedback. Disse data vil senere blive brugt til at oprette forskellige rapporter. Så lad os starte.
Idé
Afstemninger kan oprettes hvor som helst. De kunne være velplanlagte og omfatte et repræsentativt udsnit af offentligheden (baseret på demografi). Eller du kunne lave dem på stedet, f.eks. hvis du vil forudsige valgresultater baseret på en stikprøve (som en exit poll), ville du sandsynligvis spørge folk på valgstedet, hvordan de stemte.
På den anden side, hvis du ønsker at oprette den samme meningsmåling før valget, ville du sandsynligvis vælge en prøve og kontakte enkeltpersoner via telefon eller personligt. Normalt er der kun nogle få spørgsmål til denne type afstemning – nogle til at dække demografi, og andre til at dække det, vi virkelig er interesserede i.
Afstemninger kan også være meget mere komplekse, f.eks. hvis du vil vide den offentlige mening om et bestemt produkt, der dækker alt fra dets ydeevne til dets emballage.
I denne artikel vil jeg ikke diskutere, hvordan man vælger et prøvesæt af personer; i stedet vil jeg fokusere på selve afstemningen, dens spørgsmål og svarene.
Datamodel
Datamodel for offentlig opinionsbureau
Modellen består af tre fagområder:
PollsQuestions & AnswersResult
Vi beskriver hvert emneområde i den rækkefølge, det er angivet.
Afstemninger
Før vi begynder at stille spørgsmål, skal vi definere, hvad vi er interesserede i. Vi definerer afstemninger og spørgeskemaer i dette afsnit, og tilføjer derefter spørgsmål og svar i den næste.
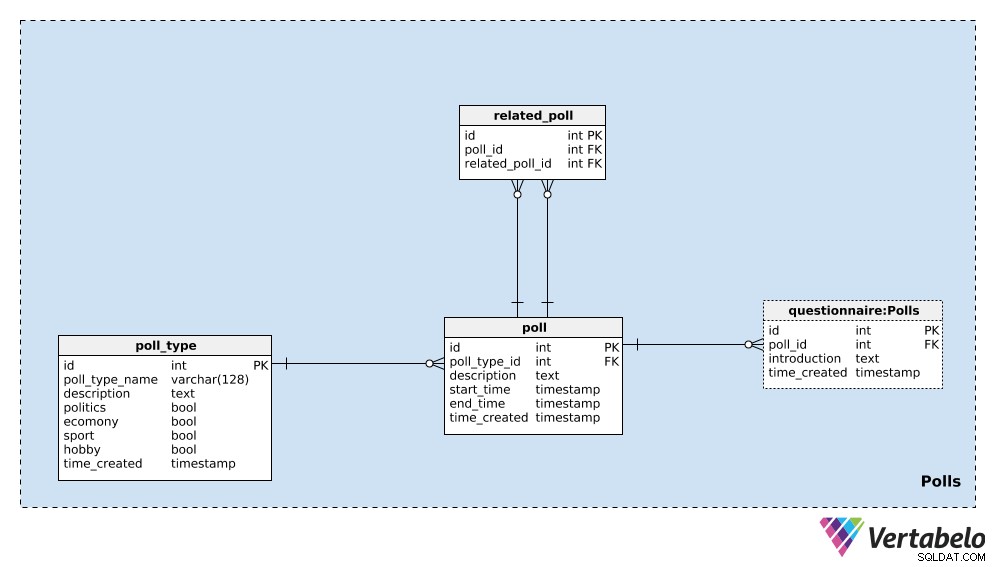
Vi starter med poll_type ordbog. Vi kan forvente, at vi for det meste vil gentage afstemninger af samme type. Den mest almindelige type er nok valgmålinger, men vi ønsker at kunne tilføje nye meningsmålingstyper hen ad vejen. For hver afstemningstype gemmer vi en UNIKT poll_type_name og brug description attribut for at give yderligere detaljer.
Fire flag – politics , economy , sport og hobby – bruges til at angive typen af afstemning. En meningsmåling kunne dække et eller flere af disse emner; hvis det er nødvendigt, kan vi opdele disse kategorier i en separat ordbog og have et mange-til-mange forhold mellem den ordbog og poll_type tabel.
Den sidste attribut i denne tabel er time_created . Det angiver det øjeblik, hvor en række er indsat i denne tabel.
Den næste ting, vi skal gøre, er at definere en enkelt poll . Dette er et enkelt tilfælde, f.eks. "Presidentvalg i USA 2020 – meningsmåling i april 2020" . For hver afstemning gemmer vi følgende detaljer:
poll_type_id– En reference tilpoll_type.description– Alle detaljer relateret til denne afstemning, i tekstformat.start_timeogend_time– De definerede start- og sluttidspunkter, hvor denne afstemning tages.time_created– Det faktiske øjeblik, hvor denne afstemning blev oprettet.
Afstemninger kan relateres til hinanden. I eksemplet med "2020 USA's præsidentvalg – april 2020 meningsmåling" , kunne vi lave den samme meningsmåling den næste måned for at se de mest aktuelle meninger. Vi ville kalde dette "2020 USA's præsidentvalg – maj 2020 meningsmåling" . Disse to meningsmålinger er relaterede, fordi deres resultater viser tendenser. For at etablere dette forhold bruger vi related_poll bord i vores model. Den indeholder kun det UNIKKE par poll_id – related_poll_id , der angiver afstemningen og dens forgænger.
Bemærk, at vi kunne bruge denne tabel til at gemme alle afstemninger, der er relaterede på nogen måde, ikke kun forgængere/efterfølgere. Hvis vi ville definere forskellige relationer, skulle vi tilføje en anden ordbog - men vi vil ikke gå den vej i denne artikel.
Den sidste tabel i dette emneområde er questionnaire bord. I de fleste tilfælde vil hver afstemning have præcis ét spørgeskema, men jeg vil gerne lade den mulighed være, at vi kan have mere end et, hvis det er nødvendigt. Derfor har jeg brugt en separat tabel. I denne tabel gemmer vi kun ID'et for den relaterede afstemning (poll_id ), en introduction beskriver det spørgeskema og tidsstemplet, da posten blev indsat (time_created ).
Spørgsmål og svar
Nu er vi klar til at oprette alle spørgeskemadetaljerne. Vi kan også liste alle de spørgsmål, vi ønsker at stille, samt alle foruddefinerede svar.
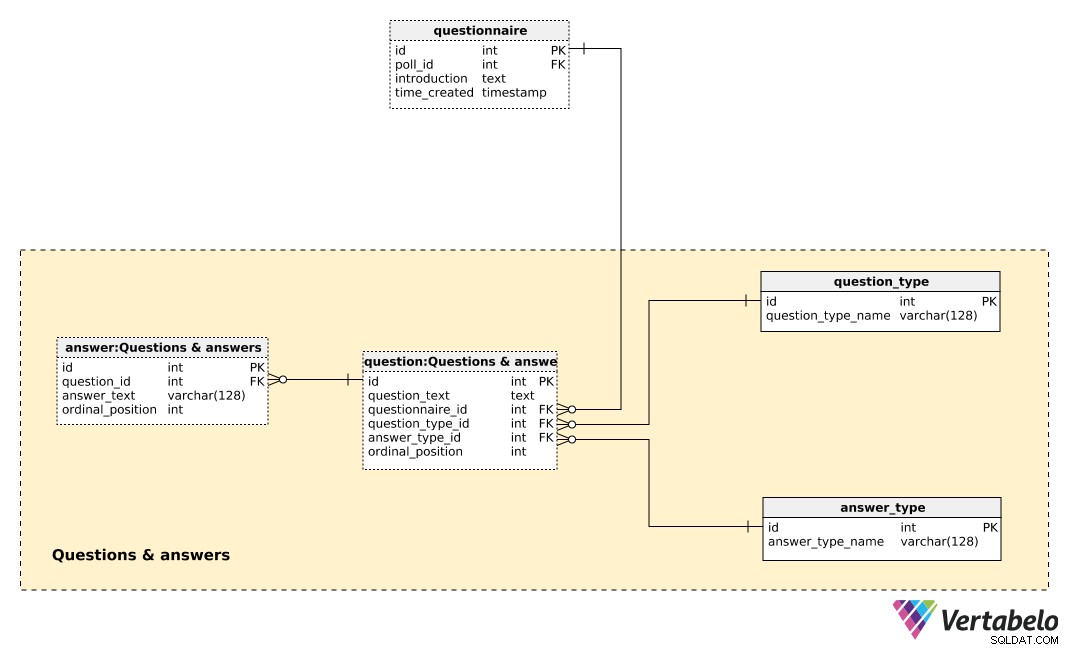
Den centrale tabel i dette emneområde er question bord. Hvert spørgsmål er defineret af følgende detaljer:
question_text– En tekst, der vil blive vist for hver enkelt person, der bliver spurgt.questionnaire_id– En reference, der angiver spørgeskemaet til dette spørgsmål.question_type_id– En reference, der angiverquestion_type, som er UNIKT angivet medquestion_type_name. Det er som udgangspunkt kategorier, f.eks. "demografi", "opinion", "kontrol" osv. Disse ville give os mulighed for at adskille demografiske spørgsmål og meningsspørgsmål og finde en sammenhæng mellem dem.answer_type_id– En reference til den type svar, der vil blive brugt til dette spørgsmål. Hveranswer_typeer UNIKT defineret afanswer_type_nameog angiver, hvordan svaret vises. Nogle forventede typer er "åben", "liste", "afkrydsningsfelt" og "flere".ordinal_position– Denne værdi angiver placeringen af dette spørgsmål i spørgeskemaet. Sammen medquestionnaire_id, den danner den alternative nøgle til denne tabel.
En liste over alle foruddefinerede svar er gemt i answer bord. Hvis spørgsmålstypen ikke er åben (dvs. tekst vil ikke blive indtastet af den enkelte), har vi et sæt foruddefinerede svar. For hvert svar definerer vi det spørgsmål, det tilhører (question_id ), answer_text , og ordinal_position af det svar i det spørgsmål. Endnu engang et UNIKT par – denne gang question_id – ordinal_position – danner den alternative nøgle til denne tabel.
Resultat
I de foregående to emneområder har vi defineret alt, hvad vi skal bruge for at oprette afstemningen og begynde at stille spørgsmål. Nu skal vi definere en datastruktur til at gemme faktiske svar.
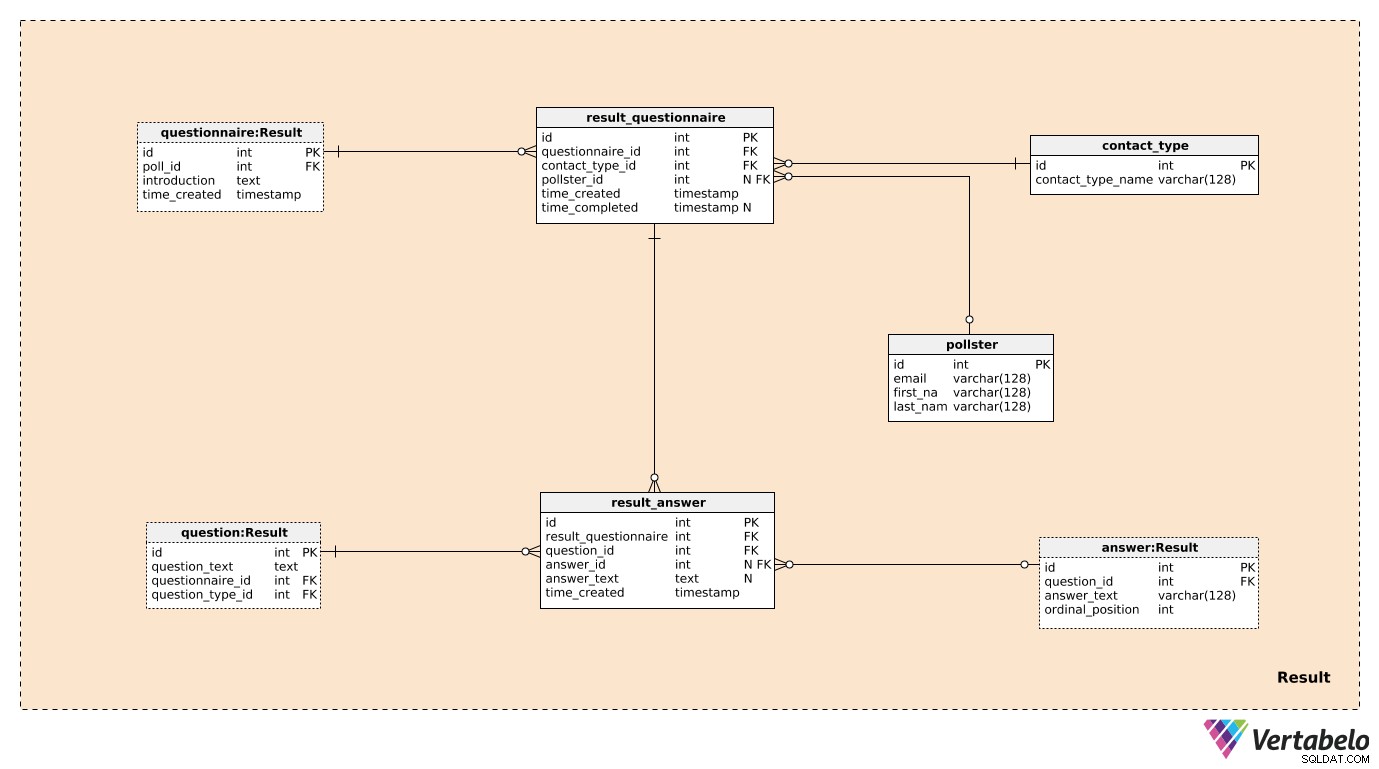
Tre ud af de syv tabeller i Result emneområdet er tidligere nævnt og beskrevet. Disse er questionnaire , question , og answer . De resterende fire borde bruges til at gemme det, vi virkelig er interesserede i.
Vi opretter én post i result_questionnaire tabel for hver enkelt deltager i afstemningen. questionnaire_id give esus alle oplysninger om den relevante meningsmåling. contact_type_id er en reference til contact_type ordbog. Værdier i denne tabel beskriver den måde, vi har interageret med denne person på. Disse værdier er UNIKT defineret af contact_type_name værdi og kunne være noget som "telefon", "personlig", "e-mail", "webformular" osv.
pollster_id attribut er en reference til pollster tabel, som giver oplysninger om, hvem der udførte den aktuelle meningsmåling. For hver pollster , vi gemmer kun deres UNIKKE e-mail og deres first_name og last_name . time_created attribut angiver det faktiske tidspunkt, hvor denne post blev oprettet, mens time_completed vil blive fastsat i det øjeblik, denne undersøgelse er afsluttet. (Indtil da vil den være NULL).
Den sidste tabel i modellen er result_answer bord. Som navnet antyder, er det her, vi gemmer de faktiske svar, vi fik fra undersøgelsesdeltagere. For hver post i denne tabel har vi:
result_questionnaire_id– En henvisning til det relevante spørgeskema.question_id– En reference, der angiver det spørgsmål, som dette svar besvarer.answer_id– En henvisning til det svar, der blev brugt til at besvare dette spørgsmål. Denne attribut vil indeholde en NULL-værdi, når spørgsmålet er af en "åben" type (fordi der ikke var nogen foruddefinerede svar at vælge imellem).answer_text– Den tekst, der blev indsat for at besvare dette spørgsmål. Denne attribut vil indeholde en værdi, når spørgsmålet var "åbent"; i alle andre tilfælde vil den være NULL.time_created– Det faktiske tidspunkt, hvor dette svar blev indsat i vores system.
Mulige forbedringer
Indtil videre har vi dækket, hvordan vi kunne gemme afstemningsdata. Vi har ikke diskuteret, hvad vi ville gøre med dataene efter afstemningen er lukket. Vi kan forvente, at vi ikke får brug for de gamle data i fremtiden, i hvert fald ikke i vores operationelle database. Derfor kunne vi gøre to ting:
- Gem et afstemningsresumé i en separat tabel i den operationelle database. Dette ville holde sådanne oplysninger til vores rådighed, hvis vi ønskede at se, hvad der skete med en lignende meningsmåling.
- Gem alle afstemningsdata i en backupdatabase, der havde samme struktur som den operationelle database. Dette ville give os adgang til detaljerne, når vi havde brug for dem.
Vi kunne også oprette et datavarehus til at gemme afstemningsresultater, men det ville ikke være nødvendigt, hvis vi allerede havde udført de opgaver, der er beskrevet i de to punktopstillinger.
Hvad synes du om vores meningsmålingsdatamodel?
Vi vil gerne høre din mening om, hvad vi kan ændre for at forbedre meningsmålingsdatamodellen. Har du brancheerfaring? Tror du, vi gik glip af noget? Vil du tilføje eller fjerne noget? Ser frem til at høre dine meninger.