Overvågning af PostgreSQL kan til tider være som at prøve at skændes med kvæg i et tordenvejr. Applikationer forbinder og udsteder forespørgsler så hurtigt, at det er svært at se, hvad der foregår, eller endda få et godt overblik over systemets ydeevne, bortset fra den typiske udvikler, der klager over "ting er langsomt, hjælp!" slags anmodninger.
I tidligere artikler har vi diskuteret, hvordan man kommer til kilden, når PostgreSQL handler langsomt, men når kilden specifikt er forespørgsler, er overvågning på basisniveau muligvis ikke nok til at vurdere, hvad der foregår i et aktivt live-miljø.
Indtast pg_top, et PostgreSQL-specifikt program til at overvåge realtidsaktivitet i en database, samt se grundlæggende oplysninger om selve databaseværten. Ligesom linux-kommandoen 'top', bringer kørsel af den brugeren ind i en live interaktiv visning af databaseaktivitet på værten, der opdateres automatisk i intervaller.
Installation
Installation af pg_top kan gøres på de generelt forventede måder:pakkeadministratorer og kildeinstallation. Den seneste version fra denne artikel er 3.7.0.
Package Managers
Baseret på distributionen af det pågældende linux, søg efter pgtop eller pg_top i pakkehåndteringen, det er sandsynligvis tilgængeligt i et eller andet aspekt for den installerede version af PostgreSQL på systemet.
Red Hat-baserede distributioner:
# sudo yum install pg_topGentoo-baserede distributioner:
# sudo apt-get install pgtopKilde
Hvis det ønskes, kan pg_top installeres via source fra PostgreSQL git repository. Dette vil give enhver ønsket version, selv nyere builds, der endnu ikke er i de officielle udgivelser.
Funktioner
Når først det er installeret, fungerer pg_top som en meget nøjagtig realtidsvisning i den database, den overvåger, og brug af kommandolinjen til at køre 'pg_top' vil starte det interaktive PostgreSQL-overvågningsværktøj.
Værktøjet i sig selv kan hjælpe med at kaste lys over alle processer, der i øjeblikket er forbundet med databasen.
Kører pg_top
Start af pg_top er det samme som selve kommandoen 'top' i unix/linux-stilen sammen med forbindelsesoplysninger til databasen.
Sådan kører du pg_top på en lokal databasevært:
pg_top -h localhost -p 5432 -d severalnines -U postgresFor at køre pg_top på en fjernvært kræves flaget -r eller --remote-mode, og pg_proctab-udvidelsen installeret på selve værten:
pg_top -r -h 192.168.1.20 -p 5432 -d severalnines -U postgresHvad er der på skærmen
Når vi starter pg_top, ser vi et display med en hel del information.
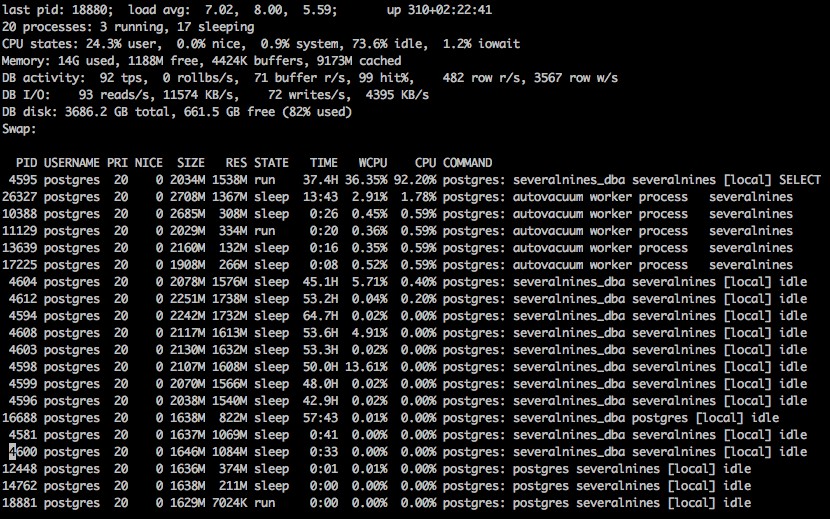 Standard output fra pg_top på linux
Standard output fra pg_top på linux
Belastningsgennemsnit:
Ligesom den øverste standardkommando er dette belastningsgennemsnit for 1, 5 og 15 minutters intervaller.
Oppetid:
Den samlede tid, systemet har været online siden den seneste genstart.
Processer:
Det samlede antal af databaseprocesser forbundet med et antal af, hvor mange der kører, og hvor mange der er i dvale.
CPU-statistik:
CPU-statistikken, der viser den procentvise belastning for bruger, system og inaktiv, god information samt iowait-procenter.
Hukommelse:
Den samlede mængde hukommelse, der bruges, ledig, i buffere og cachelagret.
DB-aktivitet:
Statistikken for databaseaktivitet såsom transaktioner pr. sekund, antal tilbageføringer pr. sekund, buffere læst pr. sekund, buffere hit pr. sekund, antal rækker læst pr. sekund, og rækker skrevet pr. sekund.
DB I/O-aktivitet:
Aktiviteten for input-output på systemet, der viser, hvor mange læser og skriver pr. sekund, samt mængden af læst og skrevet pr. sekund.
DB Disk Stats:
Den samlede størrelse på databasedisken, samt hvor meget ledig plads.
Swap:
Oplysninger om brugt swap-plads, hvis nogen.
Processer:
En liste over processer, der er forbundet med databasen, inklusive enhver autovakuum type af interne processer. Listen inkluderer pid, prioritet, den pæne mængde, brugt resident hukommelse, forbindelsens tilstand, antallet af brugte cpu-sekunder, cpu-procent og den aktuelle kommando, som processen kører.
Nyttige interaktive funktioner
Der er en håndfuld interaktive funktioner i pg_top, som du kan få adgang til, mens den kører. En komplet liste kan findes ved at indtaste et ?, som vil vise en hjælpeskærm med alle de forskellige tilgængelige muligheder.
Planlæggeroplysninger
E - Udførelsesplan
Indtastning af E vil give en prompt om et proces-id, som skal vise en forklaringsplan. Dette svarer til at køre "EXPLAIN
A - FORKLARING ANALYSE (OPDATERING/SLET sikker)
Indtastning af A vil give en prompt om et proces-id, som skal vise en FORKLAR ANALYSE-plan. Dette svarer til at køre "EXPLAIN ANALYZE
Procesoplysninger
Q - Vis den aktuelle forespørgsel for en proces
Hvis du indtaster Q, bliver du bedt om et proces-id, som hele forespørgslen skal vises for.
I - Viser I/O-statistik pr. proces (kun Linux)
Når du indtaster I, skifter proceslisten til et I/O-display, der viser hver proces, der læser, skriver osv. til disken.
L - Viser låse, der holdes af en proces
Indtastning af L vil give en prompt om et proces-id, som der skal vises fastholdte låse for. Dette vil inkludere databasen, tabellen, typen af lås, og hvorvidt låsen er blevet tildelt. Nyttigt til, når du udforsker langvarige eller ventende processer.
Relationsoplysninger
R - Vis brugertabelstatistik.
Indtastning af R viser tabelstatistik inklusive sekventielle scanninger, indeksscanninger, INDSÆT, OPDATERINGER og SLETTER, alt sammen relevant for den seneste aktivitet.
X - Vis brugerindeksstatistik
Hvis du indtaster X, vises indeksstatistikker inklusive indeksscanninger, indekslæsninger og indekshentninger, alt sammen relevant for den seneste aktivitet.
Sortering
Sortering af displayet kan udføres gennem et hvilket som helst af følgende tegn.
M - Sorter efter hukommelsesforbrug
N - Sorter efter pid
P - Sorter efter CPU-brug
T - Sorter efter tid
Følgende er indgange angivet efter tryk på o, hvilket også tillader sortering af indeks-, tabel- og i/o-statsiderne.
o - Angiv sorteringsrækkefølge (cpu, størrelse, res, tid, kommando)
indeksstatistik (idx_scan, idx_tup_fetch, idx_tup_read)
tabelstatistik (seq_scan, seq_tup_read, idx_scan, idx_tup_fetch, n_tup_ins, n_tup_upd, n br tup_, i de char, char / , skriver, cwrites, kommando)
Forbindelse/forespørgselsmanipulation
k - dræb processer specificeret
Indtastning af k vil give en prompt om en proces eller liste over databaseprocesser, der skal dræbes.
r - genskab en proces (kun lokal database, kun root)
Indtastning af r vil give en prompt om en god værdi, efterfulgt af en liste over processer, der skal indstilles til den nye nice-værdi. Dette ændrer prioriteringen af vigtige processer i systemet.
Eksempel:"renice 1 7004"
Forskellige anvendelser af pg_top
Reaktiv brug af pg_top
Den generelle brug for pg_top er den interaktive tilstand, der giver os mulighed for at se, hvilke forespørgsler der kører på et system, der oplever problemer med langsommelighed, køre forklaringsplaner på disse forespørgsler, gengive vigtige forespørgsler for at få dem til at fuldføre hurtigere, eller dræbe forespørgsler, der forårsager større opbremsninger . Generelt giver det databaseadministratoren mulighed for at gøre meget af de samme ting, som kan gøres manuelt på systemet, men på en hurtigere og alt i én mulighed.
Proaktiv brug af pg_top
Selvom det ikke er for almindeligt, kan pg_top køres i 'batch-tilstand', som vil vise de diskuterede hovedoplysninger til standard ud, og derefter afslutte. Dette kan scripts op til at køre med bestemte intervaller, og derefter sendes til en hvilken som helst tilpasset proces, der ønskes, parses og genereres advarsler baseret på, hvad administratoren måtte ønske at blive advaret om. Hvis f.eks. systemets belastning bliver for høj, hvis der er en værdi, der er højere end forventet transaktioner pr. sekund, kan alt, hvad et kreativt program finder ud af.
Generelt er der andre værktøjer til at indsamle og rapportere om disse oplysninger, men at have flere muligheder er altid en god ting, og med at have flere værktøjer tilgængelige, kan de bedste muligheder findes.
Historisk brug af pg_top
Meget ligesom den tidligere brug, proaktiv brug, kan vi scripte pg_top op i en batch-tilstand for at logge snapshots af, hvordan databasen ser ud over tid. Dette kan være så simpelt som at skrive det til en tekstfil med et tidsstempel, eller at parse det og gemme datoen i en relationsdatabase for at generere rapporter. Dette ville gøre det muligt at finde flere oplysninger efter en større hændelse, såsom et databasenedbrud kl. 04.00. Jo flere data der er tilgængelige, jo mere sandsynlige kan problemer findes.
Flere oplysninger
Dokumentationen for projektet er ret begrænset, og de fleste oplysninger er tilgængelige på linux man-siden, fundet ved at køre 'man pg_top'. PostgreSQL-fællesskabet kan hjælpe med spørgsmål eller problemer gennem PostgreSQL-mailinglisterne eller det officielle IRC Chatroom, som findes på freenode, kanalnavn #postgresql.