Recovery Time Objective (RTO) er den tidsperiode, inden for hvilken en tjeneste skal gendannes for at undgå uacceptable konsekvenser. Ved at beregne, hvor lang tid det kan tage at gendanne fra en databasefejl, kan vi vide, hvilket forberedelsesniveau der kræves. Hvis RTO er et par minutter, så er betydelige investeringer i failover påkrævet. En RTO på 36 timer kræver en væsentlig lavere investering. Det er her failover-automatisering kommer ind i billedet.
I vores tidligere blogs har vi diskuteret failover for MongoDB, MySQL/MariaDB/Percona, PostgreSQL eller TimeScaleDB. For at opsummere, "Failover " er et systems evne til at fortsætte med at fungere, selvom der opstår en fejl. Det antyder, at systemets funktioner overtages af sekundære komponenter, hvis de primære komponenter fejler. Failover er en naturlig del af ethvert system med høj tilgængelighed, og i nogle tilfælde , det skal endda automatiseres. Manuelle failovers tager bare for lang tid, men der er tilfælde, hvor automatisering ikke vil fungere godt - for eksempel i tilfælde af en delt hjerne, hvor databasereplikering er brudt, og de to 'halvdele' bliver ved med at modtage opdateringer, effektivt fører til divergerende datasæt og inkonsistens.
Vi har tidligere skrevet om de vejledende principper bag ClusterControls automatiske failover-procedurer. Hvor det er muligt, giver automatiseret failover effektivitet, da det muliggør hurtig genopretning efter fejl. I denne blog vil vi se på, hvordan man opnår automatisk failover i en master-slave (eller primær-standby) replikeringsopsætning ved hjælp af ClusterControl.
Krav til teknologistabel
En stak kan samles fra Open Source Software-komponenter, og der er en række muligheder tilgængelige - nogle mere passende end andre afhængigt af failover-karakteristika og også niveauet af ekspertise, der er tilgængeligt til at administrere og vedligeholde løsningen. Hardware og netværk er også vigtige aspekter.
Software
Der er masser af muligheder tilgængelige i open source-økosystemet, som du kan bruge til at implementere failover. Til MySQL kan du drage fordel af MHA, MMM, Maxscale/MRM, mysqlfailover eller Orchestrator. Denne tidligere blog sammenligner MaxScale med MHA med Maxscale/MRM. PostgreSQL har repmgr, Patroni, PostgreSQL Automatic Failover (PAF), pglookout, pgPool-II eller stolon. Disse forskellige muligheder for høj tilgængelighed blev tidligere dækket. MongoDB har replikasæt med understøttelse af automatiseret failover.
ClusterControl leverer automatisk failover-funktionalitet til MySQL, MariaDB, PostgreSQL og MongoDB, som vi vil dække længere nede. Værd at bemærke, at den også har funktionalitet til automatisk at gendanne ødelagte noder eller klynger.
Hardware
Automatisk failover udføres typisk af en separat dæmonserver, der er sat op på sin egen hardware - adskilt fra databasenoderne. Den overvåger databasernes status og bruger oplysningerne til at træffe beslutninger om, hvordan der skal reageres i tilfælde af fejl.
Råvareservere kan fungere fint, medmindre serveren overvåger et stort antal forekomster. Typisk er systemtjek og sundhedsanalyser lette med hensyn til behandling. Men hvis du har et stort antal noder at tjekke, er stor CPU og hukommelse et must, især når checks skal stå i kø, da den forsøger at pinge og indsamle information fra servere. De noder, der overvåges og overvåges, kan nogle gange gå i stå på grund af netværksproblemer, høj belastning, eller i værste fald kan de være nede på grund af en hardwarefejl eller en VM-værtskorruption. Så serveren, der kører sundheds- og systemkontrollen, skal være i stand til at modstå sådanne stall, da chancerne er for, at behandling af køer kan gå op, da svar på hver af de overvågede noder kan tage tid, før det er bekræftet, at det ikke længere er tilgængeligt, eller en timeout har nået.
For cloud-baserede miljøer er der tjenester, der tilbyder automatisk failover. For eksempel bruger Amazon RDS DRBD til at replikere lager til en standby-knude. Eller hvis du gemmer dine volumener i EBS, replikeres disse i flere zoner.
Netværk
Automatiseret failover-software er ofte afhængig af agenter, der er konfigureret på databasenoderne. Agenten henter information lokalt fra databaseinstansen og sender den til serveren, når det bliver anmodet om det.
Med hensyn til netværkskrav skal du sørge for at have god båndbredde og en stabil netværksforbindelse. Kontroller skal udføres ofte, og mistede hjerteslag på grund af et ustabilt netværk kan føre til, at failover-softwaren (forkert) udleder, at en node er nede.
ClusterControl kræver ikke nogen agent installeret på databasenoderne, da den vil SSH ind i hver databaseknude med jævne mellemrum og udføre en række kontroller.
Automatisk failover med ClusterControl
ClusterControl giver mulighed for at udføre manuelle såvel som automatiserede failovers. Lad os se, hvordan dette kan gøres.
Failover i ClusterControl kan konfigureres til at være automatisk eller ej. Hvis du foretrækker at tage hånd om failover manuelt, kan du deaktivere automatisk klyngendannelse. Når du laver en manuel failover, kan du gå til Klynge → Topologi i ClusterControl. Se skærmbilledet nedenfor:
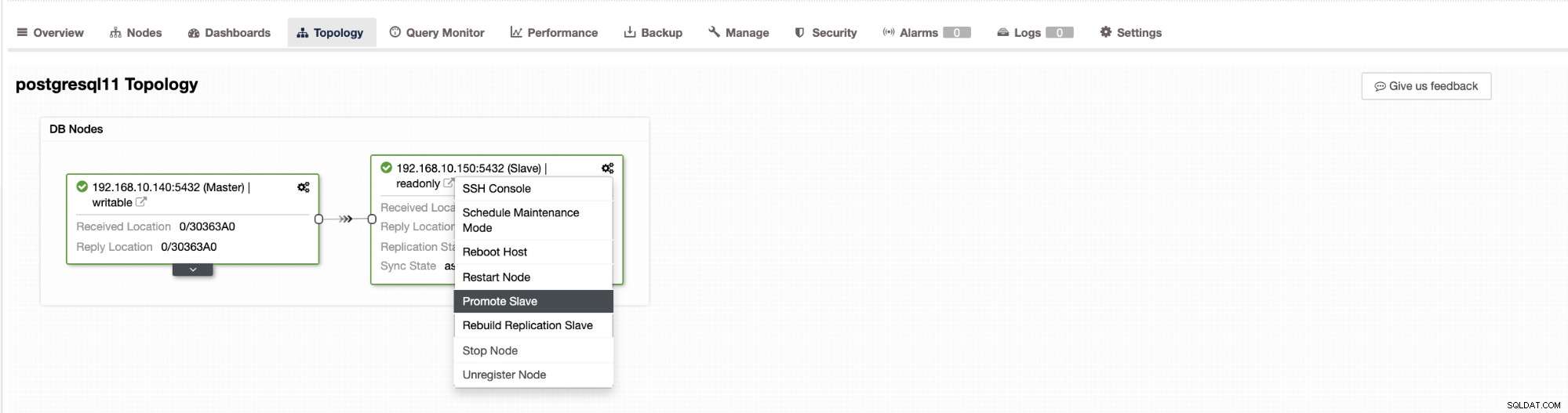
Som standard er klyngendannelse aktiveret, og automatisk failover bruges. Når du har foretaget ændringer i brugergrænsefladen, ændres runtime-konfigurationen. Hvis du gerne vil have indstillingen til at overleve en genstart af controlleren, så sørg for at du også foretager ændringen i cmon-konfigurationen, dvs. /etc/cmon.d/cmon_

I MySQL/MariaDB/Percona-serveren initieres automatisk failover af ClusterControl, når den registrerer, at der ikke er nogen vært med read_only flag deaktiveret. Det kan ske, fordi master (som har read_only sat til 0) er ikke tilgængelig, eller den kan udløses af en bruger eller ekstern software, der har ændret dette flag på masteren. Hvis du foretager manuelle ændringer af databasenoderne eller har software, der kan fifle med read_only-indstillingerne, så bør du deaktivere automatisk failover. ClusterControls automatiske failover forsøges kun én gang, derfor vil en mislykket failover ikke blive efterfulgt igen af en efterfølgende failover - ikke før cmon genstartes.
For PostgreSQL vil ClusterControl vælge den mest avancerede slave og til dette formål bruge pg_current_xlog_location (PostgreSQL 9+) eller pg_current_wal_lsn (PostgreSQL 10+) afhængigt af versionen af vores database. ClusterControl udfører også flere kontroller over failover-processen for at undgå nogle almindelige fejl. Et eksempel er, at hvis det lykkes os at genoprette vores gamle mislykkede mester, vil det "ikke " genindføres automatisk til klyngen, hverken som master eller slave. Vi skal gøre det manuelt. Dette vil undgå muligheden for datatab eller inkonsekvens i tilfælde af, at vores slave (som vi forfremmede) blev forsinket på det tidspunkt af fejlen. Vi ønsker måske også at analysere problemet i detaljer, før vi genintroducerer det til replikeringsopsætningen, så vi vil gerne bevare diagnostiske oplysninger.
Hvis failover mislykkes, gøres der ikke yderligere forsøg (dette gælder både PostgreSQL og MySQL-baserede klynger), manuel indgriben er påkrævet for at analysere problemet og udføre de tilsvarende handlinger. Dette er for at undgå den situation, hvor ClusterControl, som håndterer den automatiske failover, forsøger at fremme den næste slave og den næste. Der kan være et problem, og vi ønsker ikke at gøre tingene værre ved at forsøge flere failovers.
ClusterControl tilbyder whitelisting og blacklisting af et sæt servere, som du ønsker at deltage i failoveren eller ekskludere som kandidat.
For klynger af MySQL-typen opbygger ClusterControl en liste over slaver, som kan forfremmes til master. Det meste af tiden vil det indeholde alle slaver i topologien, men brugeren har en vis yderligere kontrol over det. Der er to variabler, du kan indstille i cmon-konfigurationen:
replication_failover_whitelistog
replication_failover_blacklistFor konfigurationsvariablen replication_failover_whitelist indeholder den en liste over IP'er eller værtsnavne på slaver, som skal bruges som potentielle masterkandidater. Hvis denne variabel er indstillet, vil kun disse værter blive taget i betragtning. For variabel replication_failover_blacklist indeholder den en liste over værter, som aldrig vil blive betragtet som en masterkandidat. Du kan bruge den til at liste slaver, der bruges til sikkerhedskopier eller analytiske forespørgsler. Hvis hardwaren varierer mellem slaver, kan du her placere de slaver, der bruger langsommere hardware.
replication_failover_whitelist har forrang, hvilket betyder, at replication_failover_blacklist ignoreres, hvis replication_failover_whitelist er indstillet.
Når listen over slaver, som kan blive forfremmet til master, er klar, begynder ClusterControl at sammenligne deres tilstand og leder efter den mest opdaterede slave. Her adskiller håndteringen af MariaDB og MySQL-baserede opsætninger sig. Til MariaDB-opsætninger vælger ClusterControl en slave, som har den laveste replikeringsforsinkelse af alle tilgængelige slaver. For MySQL-opsætninger vælger ClusterControl også en sådan slave, men så tjekker den for yderligere, manglende transaktioner, som kunne være blevet udført på nogle af de resterende slaver. Hvis en sådan transaktion findes, slaver ClusterControl masterkandidaten fra denne vært for at hente alle manglende transaktioner. Du kan springe denne proces over og bare bruge den mest avancerede slave ved at indstille variabelen replication_skip_apply_missing_txs i din CMON-konfiguration:
f.eks.
replication_skip_apply_missing_txs=1Se vores dokumentation her for mere information om variabler.
Advarsel er, at du kun skal indstille dette, hvis du ved, hvad du laver, da der kan være fejlagtige transaktioner. Disse kan forårsage, at replikering går i stykker, såvel som datainkonsistens på tværs af klyngen. Hvis den fejlagtige transaktion skete tidligere, er den muligvis ikke længere tilgængelig i binære logfiler. I så fald vil replikering gå i stykker, fordi slaver ikke vil være i stand til at hente de manglende data. Derfor kontrollerer ClusterControl som standard for eventuelle fejltransaktioner, før det opfordrer en masterkandidat til at blive en master. Hvis et sådant problem opdages, afbrydes hovedafbryderen, og ClusterControl lader brugeren løse problemet manuelt.
Hvis du vil være 100 % sikker på, at ClusterControl vil promovere en ny master, selvom der opdages nogle problemer, kan du gøre det ved at bruge variabelen replication_stop_on_error. Se nedenfor:
f.eks.
replication_stop_on_error=0Indstil denne variabel i din cmon-konfigurationsfil. Som tidligere nævnt kan det føre til problemer med replikering, da slaver kan begynde at bede om en binær loghændelse, som ikke længere er tilgængelig. For at håndtere sådanne sager tilføjede vi eksperimentel støtte til slavegenopbygning. Hvis du indstiller variablen
replication_auto_rebuild_slave=1i cmon-konfigurationen, og hvis din slave er markeret som nede med følgende fejl i MySQL:
Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'ClusterControl vil forsøge at genopbygge slaven ved hjælp af data fra masteren. En sådan indstilling er muligvis ikke altid passende, da genopbygningsprocessen vil medføre en øget belastning af masteren. Det kan også være, at dit datasæt er meget stort, og en regelmæssig genopbygning er ikke en mulighed - det er derfor, denne adfærd er deaktiveret som standard.
Når vi har sikret, at der ikke eksisterer en fejltransaktion, og vi er klar til at gå, er der stadig et problem mere, vi skal håndtere på en eller anden måde - det kan ske, at alle slaver halter bagefter mesteren.
Som du sikkert ved, fungerer replikering i MySQL på en ret simpel måde. Master lagrer skriver i binære logfiler. Slavens I/O-tråd forbinder til masteren og trækker eventuelle binære loghændelser, den mangler. Det gemmer dem derefter i form af relælogfiler. SQL-tråden analyserer dem og anvender hændelser. Slavelag er en tilstand, hvor SQL-tråd (eller -tråde) ikke kan klare antallet af hændelser og ikke er i stand til at anvende dem, så snart de trækkes fra masteren af I/O-tråden. En sådan situation kan forekomme, uanset hvilken type replikering du bruger. Selvom du bruger semi-sync replikering, kan det kun garantere, at alle hændelser fra masteren er gemt på en af slaverne i relæloggen. Det siger ikke noget om at anvende disse begivenheder på en slave.
Problemet her er, at hvis en slave forfremmes til master, vil relælogfiler blive slettet. Hvis en slave halter og ikke har anvendt alle transaktioner, vil den miste data - hændelser, der endnu ikke er anvendt fra relælogfiler, vil gå tabt for altid.
Der er ingen ensartet måde at løse denne situation på. ClusterControl giver brugerne kontrol over, hvordan det skal gøres, og opretholder sikre standardindstillinger. Det gøres i cmon-konfiguration ved at bruge følgende indstilling:
replication_failover_wait_to_apply_timeout=-1Som standard tager det en værdi på '-1', hvilket betyder, at failover ikke vil ske med det samme, hvis en masterkandidat halter, så den er indstillet til at vente for evigt, medmindre kandidaten har indhentet det. ClusterControl vil vente på ubestemt tid på, at den anvender alle manglende transaktioner fra sine relælogfiler. Dette er sikkert, men hvis den mest opdaterede slave af en eller anden grund halter dårligt, kan failover tage timer at fuldføre. På den anden side af spektret er det at sætte det til '0' - det betyder, at failover sker med det samme, uanset om masterkandidaten halter eller ej. Du kan også gå mellemvejen og indstille den til en vis værdi. Dette vil indstille en tid i sekunder, for eksempel 30 sekunder, så indstil variablen til,
replication_failover_wait_to_apply_timeout=30Når den er indstillet til> 0, vil ClusterControl vente på, at en masterkandidat anvender manglende transaktioner fra sine relælogfiler, indtil værdien er nået (hvilket er 30 sekunder i eksemplet). Failover sker efter det definerede tidspunkt, eller når masterkandidaten vil indhente replikering, alt efter hvad der sker først. Dette kan være et godt valg, hvis din ansøgning har specifikke krav til nedetid, og du skal vælge en ny master inden for et kort tidsvindue.
For flere detaljer om, hvordan ClusterControl fungerer med automatisk failover i PostgreSQL og MySQL, se vores tidligere blogs med titlen "Failover for PostgreSQL Replication 101" og "Automatic failover of MySQL Replication - New in ClusterControl 1.4".
Konklusion
Automatiseret failover er en værdifuld funktion, især for virksomheder, der kræver 24/7 operationer med minimal nedetid. Virksomheden skal definere, hvor meget kontrol der gives op til automatiseringsprocessen under uplanlagte udfald. En høj tilgængelighedsløsning som ClusterControl tilbyder et tilpasseligt niveau af interaktion i failover-behandling. For nogle organisationer er automatiseret failover muligvis ikke en mulighed, selvom brugerinteraktionen under failover kan tage tid og påvirke RTO. Antagelsen er, at det er for risikabelt, hvis automatiseret failover ikke fungerer korrekt, eller endnu værre, det resulterer i, at data bliver rodet og delvist mangler (selvom man kan hævde, at et menneske også kan begå katastrofale fejl, der fører til lignende konsekvenser). De, der foretrækker at holde tæt kontrol over deres database, kan vælge at springe over automatisk failover og i stedet bruge en manuel proces. En sådan proces tager mere tid, men den giver en erfaren administrator mulighed for at vurdere et systems tilstand og tage korrigerende handlinger baseret på, hvad der skete.