I en disaster recovery plan er dit Recovery Point Objective (RPO) en vigtig gendannelsesparameter, der dikterer, hvor meget data du har råd til at miste. RPO er listet i tid, fra sekunder til dage. Faktisk er RPO direkte afhængig af dit backup-system. Det markerer alderen på dine sikkerhedskopierede data, som du skal gendanne for at genoptage normal drift.
Hvis du laver en natlig backup kl. og dit databasesystem går ned uden reparation kl. 15.00. den følgende dag mister du alt, hvad der er blevet ændret siden din sidste sikkerhedskopiering. Din RPO i denne særlige sammenhæng er den foregående dags backup, hvilket betyder, at du har råd til at miste en dags ændringer.
Nedenstående diagram fra vores hvidbog om disaster recovery illustrerer konceptet.
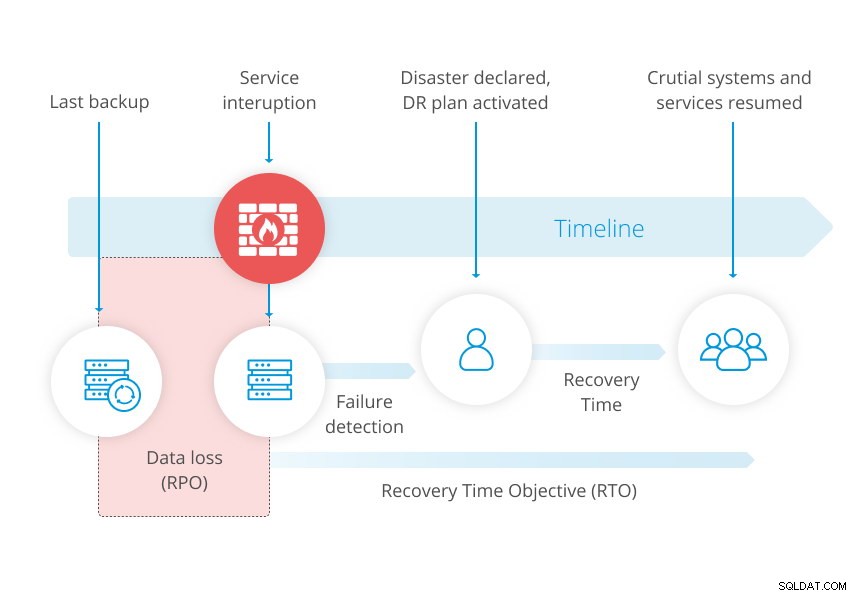
For strammere RPO er en backup muligvis ikke nok. Når du sikkerhedskopierer din database, tager du faktisk et øjebliksbillede af dataene på et givet tidspunkt. Så når du gendanner en sikkerhedskopi, vil du gå glip af de ændringer, der skete mellem den sidste sikkerhedskopiering og fejlen.
Det er her, konceptet Point In Time Recovery (PITR) kommer ind i billedet.
Hvad er PITR?
Point In Time Recovery (PITR), som navnet angiver, involverer gendannelse af databasen på ethvert givet tidspunkt i fortiden. For at kunne gøre dette, bliver vi nødt til at gendanne en sikkerhedskopi og derefter anvende alle de ændringer, der skete efter sikkerhedskopieringen, indtil lige før fejlen.
For PostgreSQL gemmes ændringerne i WAL-logfilerne (for flere detaljer om WAL'er og de data, de gemmer, kan du tjekke denne blog).
Så der er to ting, vi skal sikre for at kunne udføre en PITR:Sikkerhedskopierne og WAL'erne (vi skal konfigurere kontinuerlig arkivering for dem).
For at udføre PITR'en skal vi gendanne sikkerhedskopien og derefter anvende WAL'erne.
Hvornår kunne det være nyttigt?
Du kan bruge denne strategi, når du gendanner fra et problem, der forårsagede, at dataene blev beskadiget. Du skal huske på, at du forsøger at minimere datatabet, men der er nogle problemer, der kan forårsage, at dataene ikke længere er nyttige efter det.
Nogle eksempler på dette kan være uplanlagte dataændringer (DML'er eller DDL'er), mediefejl eller databasevedligeholdelse (som opgraderinger), der fører til datakorruption. Du vil ikke være i stand til at gendanne de dataændringer, der skete efter problemet.
Lad os antage, at en bruger fejlagtigt har udført en DML, hvilket gør, at dataene i en hel tabel bliver forkert ændret eller slettet. Du kan udføre en PITR af databasen på en separat placering og derefter eksportere indholdet af tabellen. Du kan derefter gendanne denne tabel i den eksisterende database og i praksis rulle tilbage til en kopi af, hvordan tabellen var, før problemet opstod.
Det er selvfølgelig ikke altid muligt kun at gendanne en del af databasen på denne måde, så i så fald bliver du nødt til at gendanne hele databasen til et givet punkt, og vil have et minimalt, men uundgåeligt datatab (du vil gå glip af eventuelle ændringer, der er sket efter problemet opstod).
Hvordan bruger man det med ClusterControl?
I en tidligere blog kunne vi se, hvordan man implementerer PITR manuelt, lad os nu se, hvordan man bruger ClusterControl til at udføre denne opgave.
Aktivering af punkt i tid gendannelse
For at aktivere PITR-funktionen skal vi have WAL-arkivering aktiveret. Til dette kan vi gå til ClusterControl -> Vælg PostgreSQL Cluster -> Nodehandlinger -> Aktiver WAL-arkivering, eller bare gå til ClusterControl -> Vælg PostgreSQL Cluster -> Sikkerhedskopiering -> Indstillinger og aktiver indstillingen "Enable Point-In-Time Recovery" (WAL Archiving)", som vi vil se på det følgende billede.
Vi skal huske på, at for at aktivere WAL-arkivering skal vi genstarte vores database. ClusterControl kan også gøre dette for os.
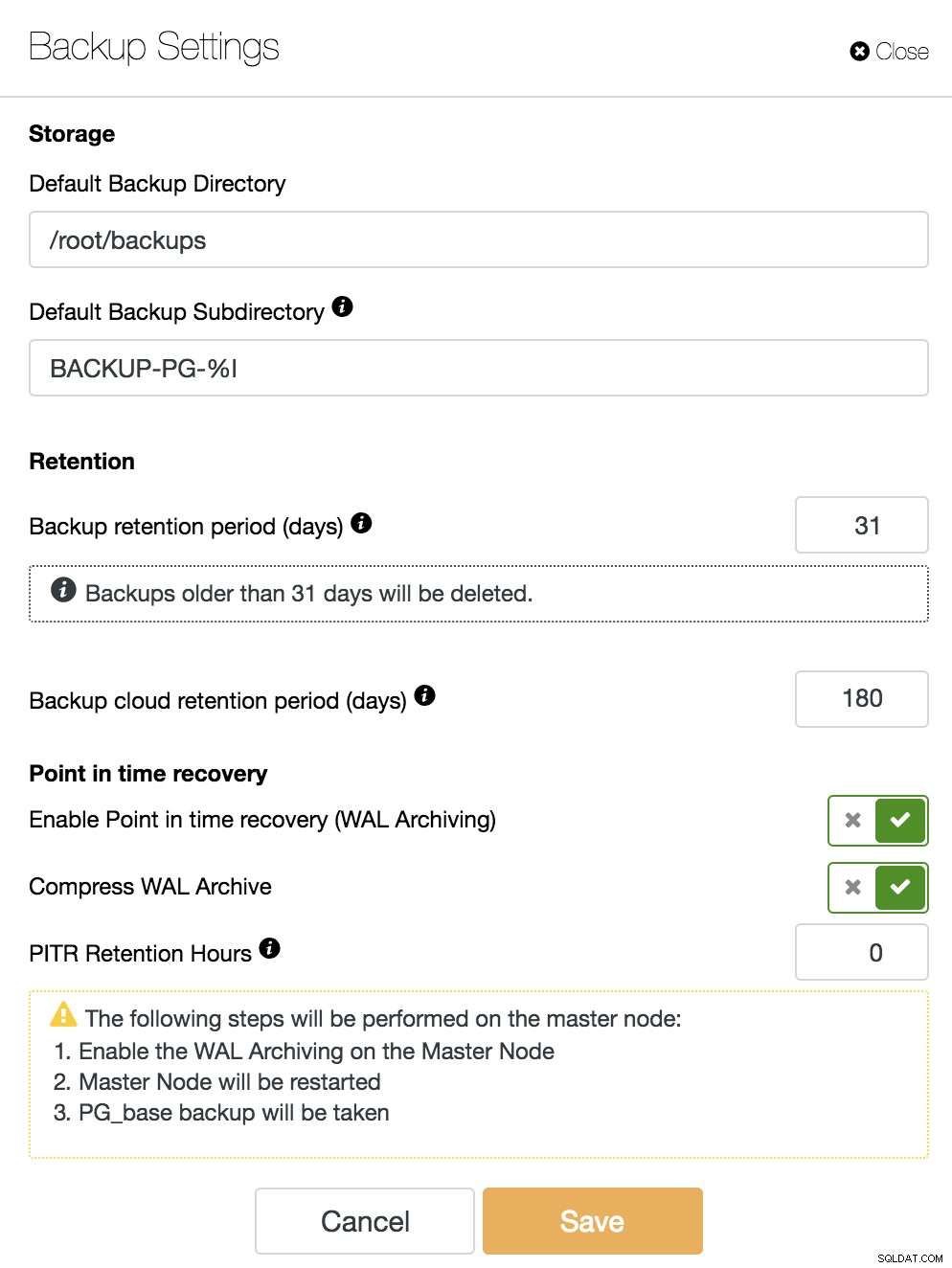
Ud over de muligheder, der er fælles for alle sikkerhedskopier, såsom "Backup Directory" og "Backup Retention Period", kan vi her også angive WAL Retention Period. Som standard er 0, hvilket betyder for evigt.
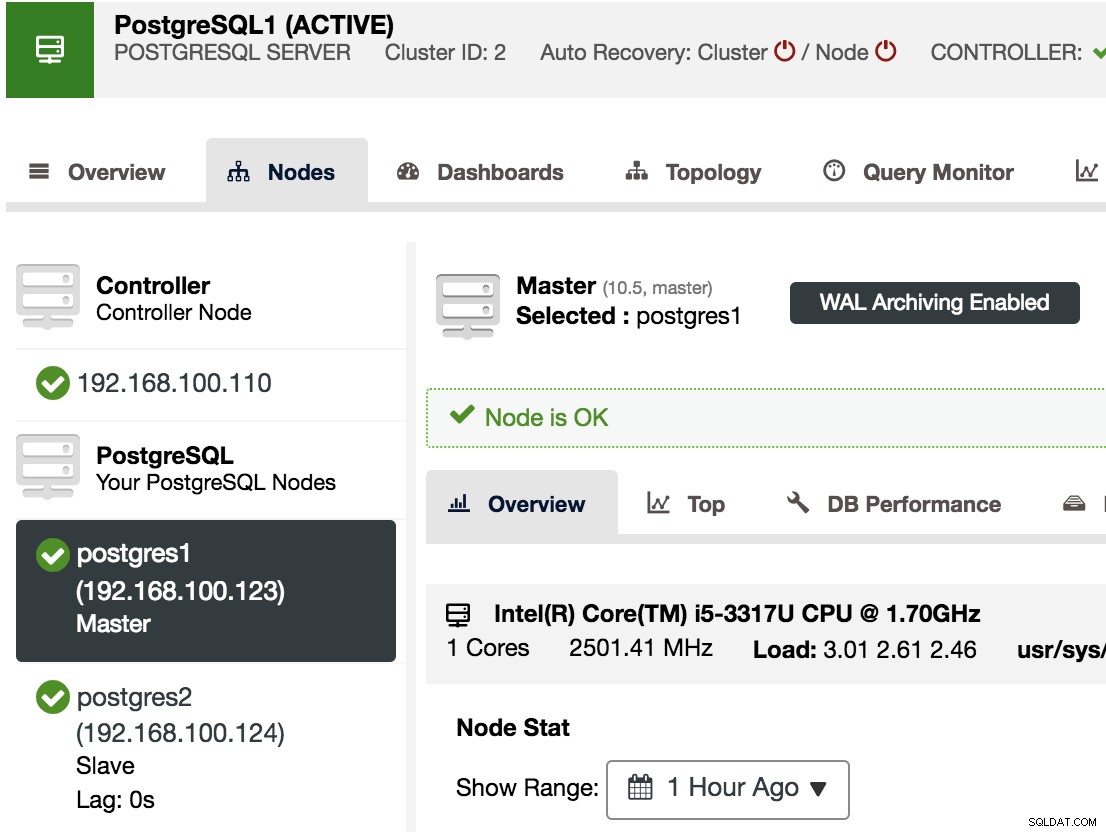
For at bekræfte, at vi har WAL-arkivering aktiveret, kan vi vælge vores masterknude i ClusterControl -> Vælg PostgreSQL-klynge -> Noder, og vi skulle se meddelelsen WAL Archiving Enabled, som vi kan se i det følgende billede.
Oprettelse af en sikkerhedskopi, der er kompatibel med Point In Time Recovery
Når WAL-arkivering er aktiveret, som vi så i det foregående trin, kan vi oprette vores backup kompatibel med PITR. For dette skal du gå til ClusterControl -> Vælg PostgreSQL Cluster -> Backup -> Create Backup.
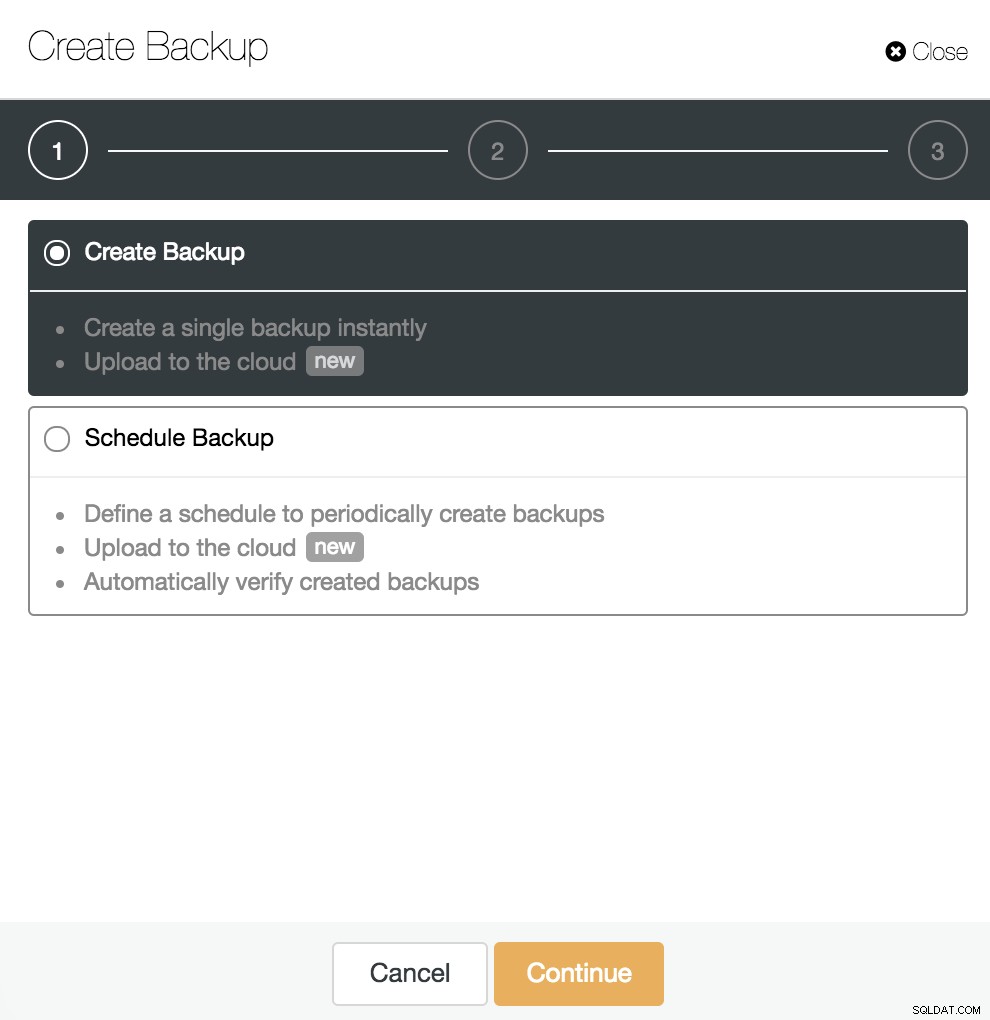
Vi kan oprette en ny backup eller konfigurere en planlagt en. For vores eksempel vil vi oprette en enkelt sikkerhedskopi med det samme.
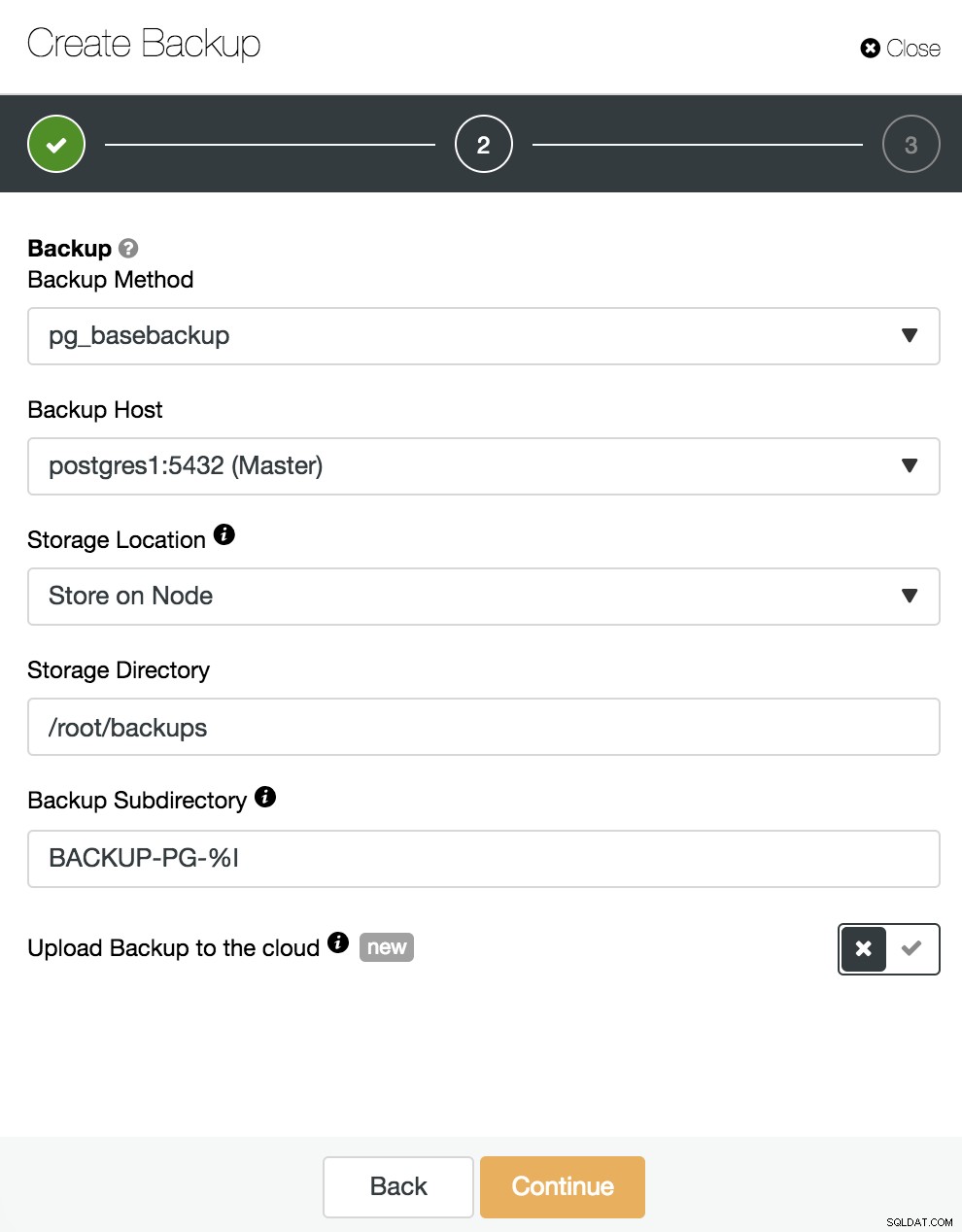
Her skal vi vælge metoden "pg_basebackup", kompatibel med PITR, den server, som backup'en tages fra (for at være kompatibel med PITR, skal den være masteren), og hvor vi ønsker at gemme sikkerhedskopien. Vi kan også uploade vores backup til skyen (AWS, Google eller Azure) ved at aktivere den tilsvarende knap.
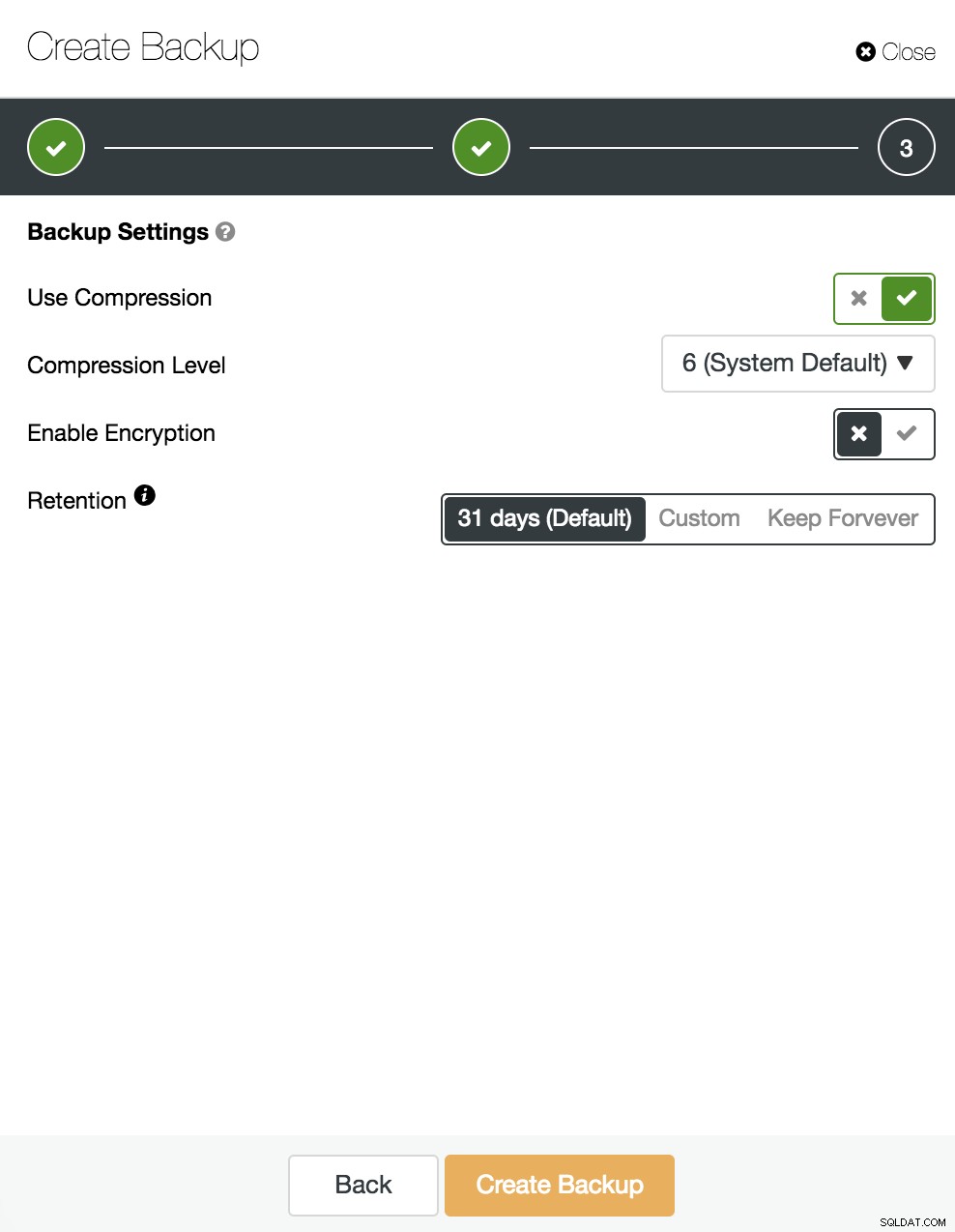
Derefter specificerer vi brugen af komprimering, kryptering og opbevaring af vores backup.
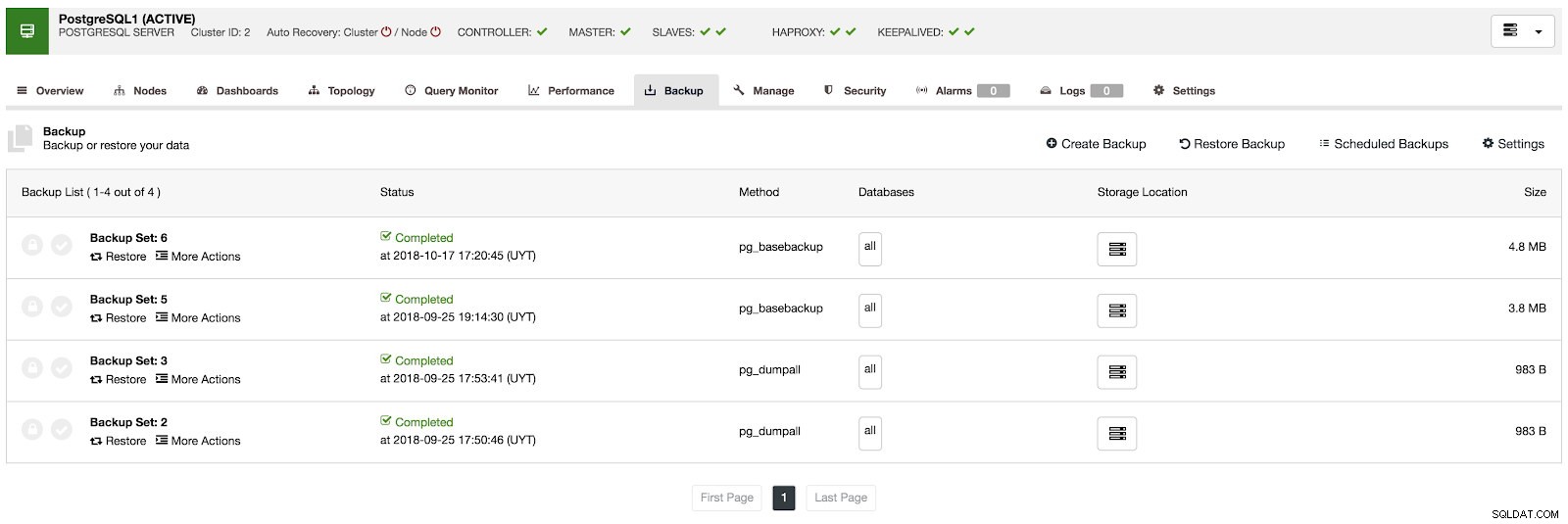
På sikkerhedskopieringssektionen kan vi se sikkerhedskopieringens fremskridt og information som metode, størrelse, placering og mere.
Gendannelse af tidspunkt fra en sikkerhedskopi
Når sikkerhedskopieringen er færdig, kan vi gendanne den ved hjælp af ClusterControl PITR-funktionen. Til dette kan vi i vores backup-sektion (ClusterControl -> Vælg PostgreSQL Cluster -> Backup) vælge "Gendan sikkerhedskopi" eller direkte "Gendan" på den sikkerhedskopi, som vi ønsker at gendanne.
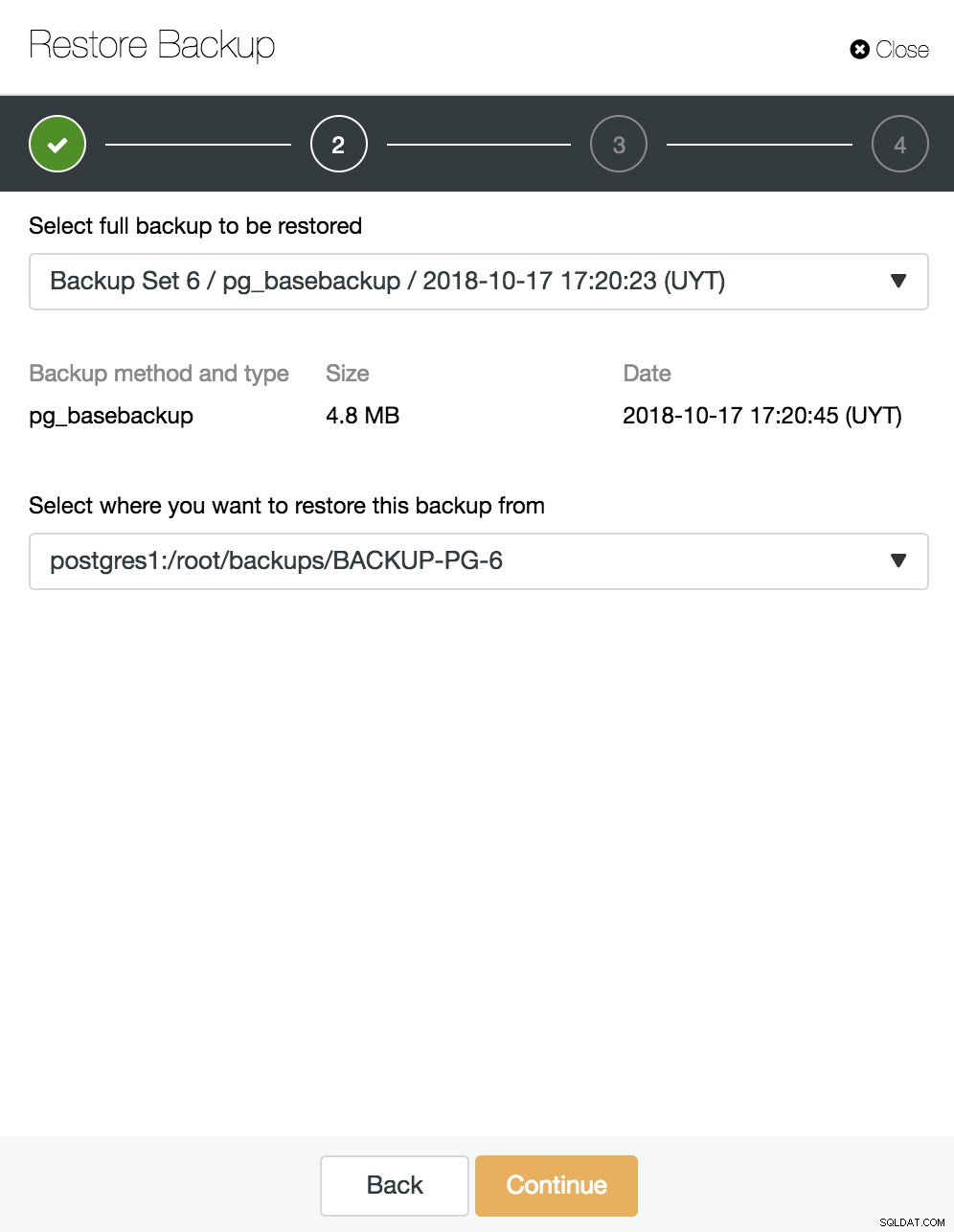
Her vælger vi hvilken backup vi vil gendanne og fra hvilken mappe.
Vi lader indstillingen "Gendan på node" være valgt og fortsætter.
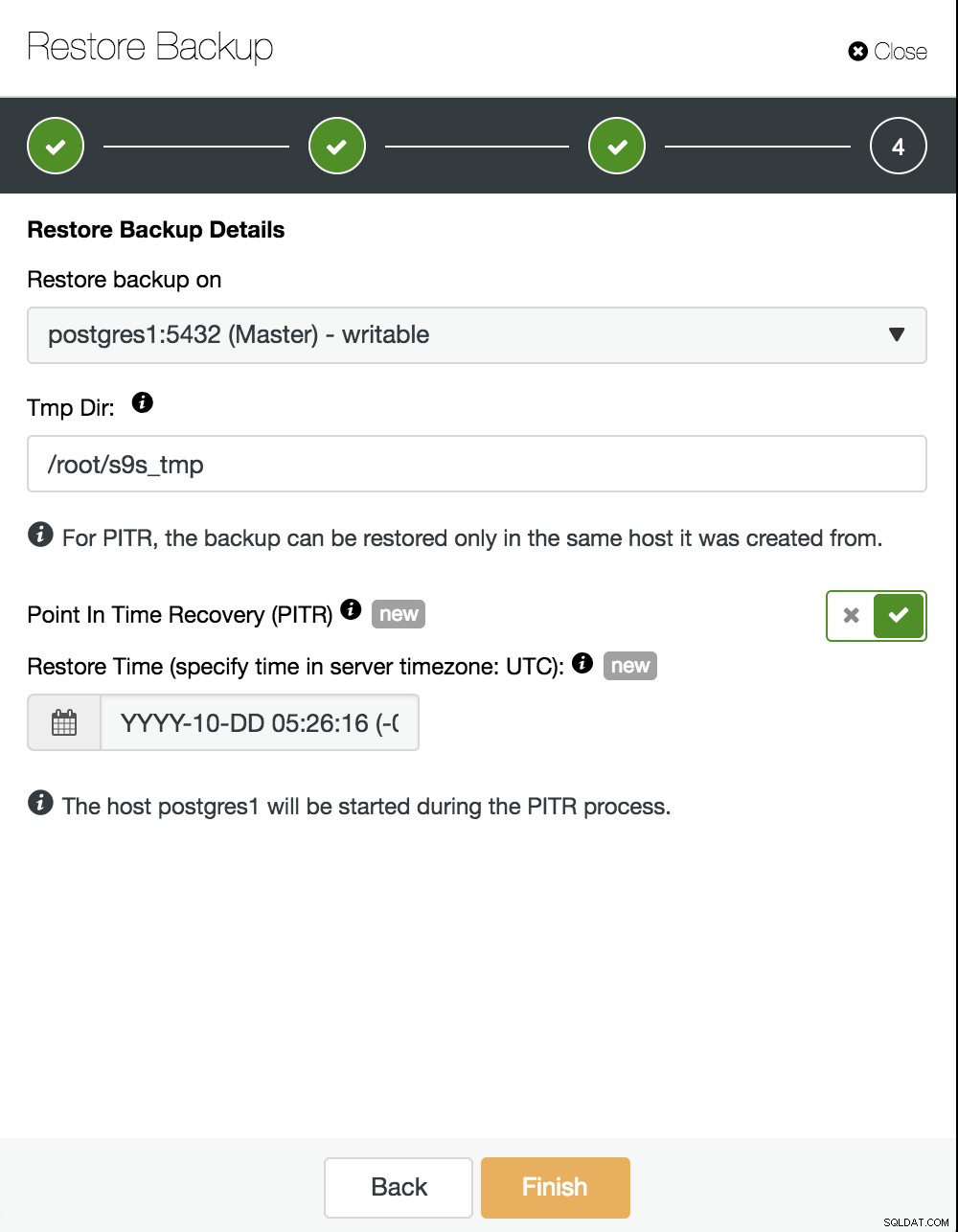
Nu skal vi vælge, hvor vi vil gendanne vores backup og aktivere PITR-indstillingen. Ved at angive tidspunktet vil det være tiden, indtil vi kommer os igen. Tag højde for, at UTC-tidszonen bruges, og at vores PostgreSQL-tjeneste i masteren genstartes.
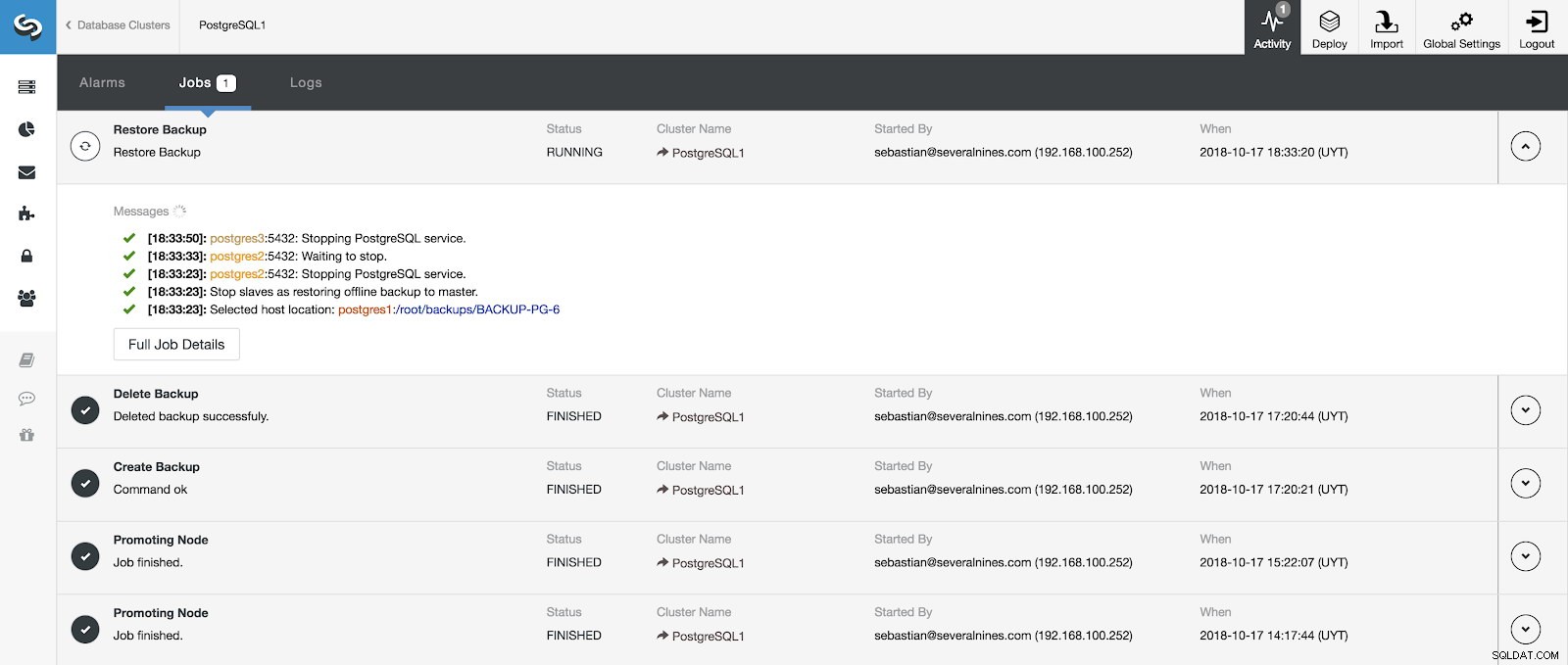
Vi kan overvåge forløbet af vores gendannelse fra aktivitetssektionen i vores ClusterControl.
Konklusion
PITR er en nødvendig funktion for at opfylde en stram RPO. Vi er nødt til at konfigurere det korrekt for at sikre en korrekt katastrofegenopretningsplan. ClusterControl giver en brugervenlig grænseflade til at hjælpe dig med at implementere PITR til dine PostgreSQL-databaser.