Integreret transport er noget, vi ofte hører om på internettet eller i nyhederne. Selvom det ikke er noget nyt, er det bestemt en løbende proces, med konstante ændringer, der implementeres. I dag tager vi et kig på en datamodel, der kunne håndtere zone-, passager- og billetoplysninger.
Lad os grave direkte ind i vores integrerede transportdatamodel, begyndende med ideen bag det hele.
Idé
Det er nødvendigt at integrere transport for at maksimere dens effektivitet og, for kunderne, dens lette brug. Integration er relateret til omkostninger, men også til tid, tilgængelighed, komfort og sikkerhed. Det gælder både større byer og mindre. Tanken er at bruge den eksisterende transportinfrastruktur og optimere den til bedre resultater; dette kan betyde at komme med nye tidsplaner, meddelelser, linjer eller stationer. Måske er det nok at have nogle oplysninger til, at du beslutter dig for at vente på bussen, leje en cykel eller bare gå til din destination.
Lad os forklare dette ved hjælp af to eksempler.
I tilfælde af en stor by er der normalt mange forskellige transportmidler til rådighed:busser, taxaer, sporvogne, jernbaner, undergrundsbanen osv. Dette kan føre til, at mange forskellige private virksomheder leverer forskellige transporttjenester. At kombinere selv nogle få af disse tjenester ville helt sikkert gavne passagerer og virksomheder ved at sænke omkostningerne, øge effektiviteten og yde mere service pr. billet.
Der er også lignende fordele for en mindre by. Der er muligvis ikke det samme antal muligheder at kombinere, men de kan organiseres for at opnå maksimal effektivitet.
Denne artikel vil hovedsageligt fokusere på integrerede transportbilletsystemer. Vi vil ikke fokusere på alle aspekter af integration og de forskellige transportformer; det ville være for komplekst.
Med dette i tankerne, lad os gå til vores model.
Datamodel
Modellen består af to fagområder:
Cities & companiesTickets
Vi beskriver dem i den rækkefølge, de er anført.
Byer og virksomheder
I det første emneområde gemmer vi alle de tabeller, der er nødvendige for at oprette transportzoner i byer.
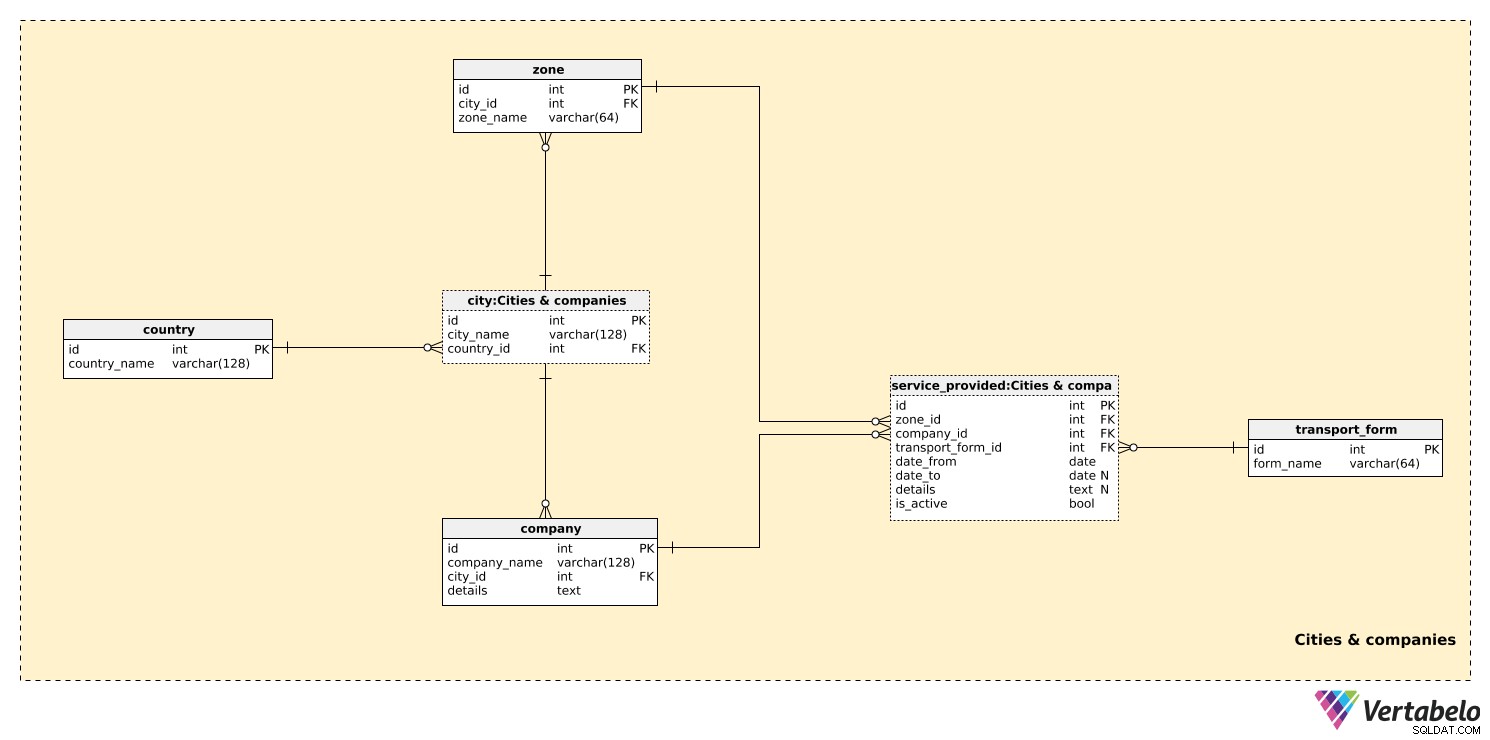
country tabel indeholder en liste over UNIQUE country_name værdier. Denne tabel bruges kun som reference i city bord. Selvom vi kan forvente, at vores model kun vil dække transport i ét land, ønsker vi at have mulighed for at inkludere flere lande. For hver by gemmer vi den UNIKKE kombination city_name – country_id .
Mindre byer vil sandsynligvis kun have én zone, mens større byer vil have flere zoner. En liste over alle mulige zoner er gemt i zone bord. For hver zone gemmer vi dens zone_name og en henvisning til den relevante by. Dette par danner den alternative nøgle i denne tabel.
Vi kan forvente, at vores system vil gemme oplysninger om flere transportselskaber. Virksomheder vil udstede deres egne billetter, men de vil også kunne udstede billetter i fællesskab med andre virksomheder. For hver company , gemmer vi den UNIKKE kombination af company_name og city_id hvor den er placeret. Alle nødvendige yderligere oplysninger kan gemmes i teksten details felt.
Den sidste ting, vi skal definere, er den form for transport, hver virksomhed tilbyder. Nogle forventede værdier er "bus", "sporvogn", "metro" og "jernbane". For hver værdi i transport_form tabel, gemmer vi det UNIQUE form_name.
zone_id– Refererer tilzonetabel og angiver det område, hvor denne form for transport leveres af denne virksomhed.company_id– Henviser tilcompanyleverer denne service i denne zone.transport_form_id– Henviser tiltransport_formtabel og angiver typen af tjeneste, der leveres.date_fromogdate_to– Den periode, hvor denne service blev leveret af denne virksomhed. Bemærk atdate_tokan indeholde en NULL-værdi, hvis denne tjeneste stadig er tilgængelig og/eller ikke har nogen forventet udløbsdato.details– Alle andre detaljer i et ustruktureret tekstformat.is_active– Hvis denne tjeneste er aktiv (igangværende) eller ej. Dette er en simpel tænd/sluk-knap, som vi i nogle tilfælde kan bruge i stedet fordate_from–date_toserviceaktivitetsinterval. Den bedste brug af denne attribut ville være at forenkle forespørgsler, dvs. ved at teste denne værdi i stedet for at teste datointervallet og "lege" med NULL-værdier.
Billetter
Det tidligere emneområde var blot forberedelse til det vigtigste:billetter. Og det er, hvad dette emneområde vil dække.
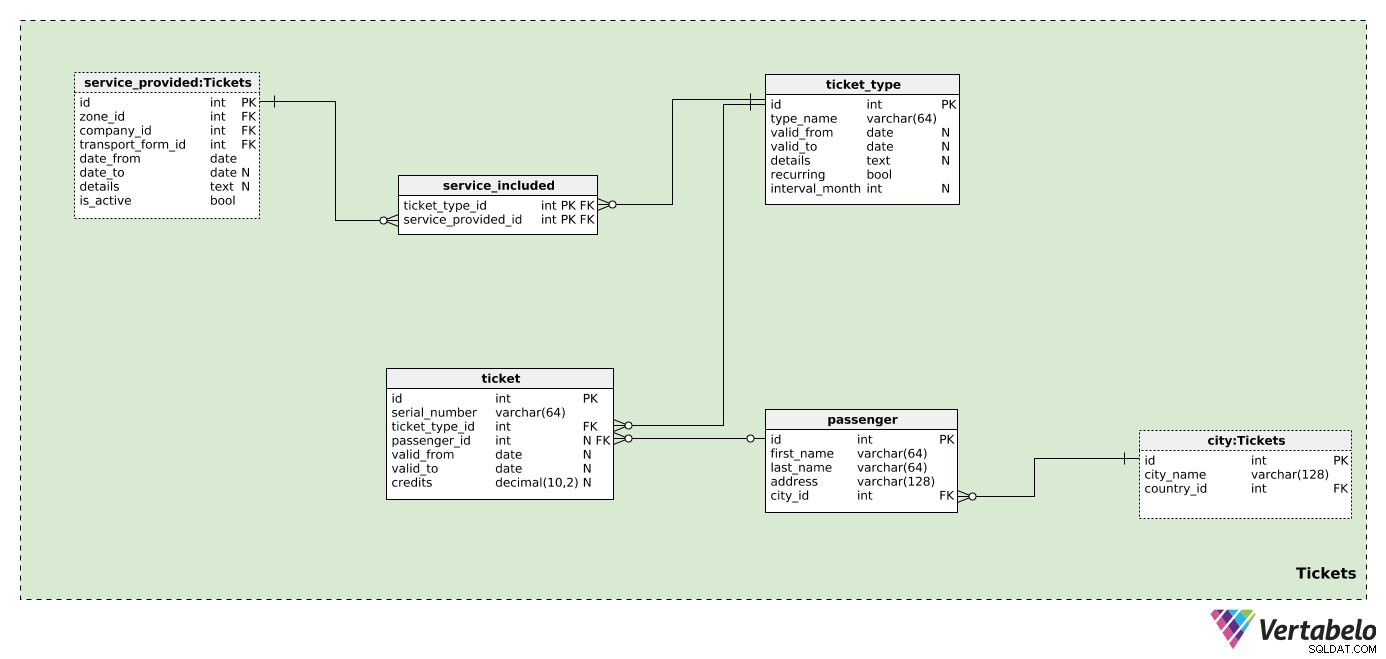
Vi har defineret selskaber, zoner og transportformer, men vi har ingen mulighed for passagerer og billetter - kernen i denne model. Vi antager, at én billet kan bruges til en eller flere zoner, der er dækket af et eller flere selskaber.
Derfor skal vi først definere hver ticket_type . I denne tabel viser vi alle mulige typer billetter, der sælges af selskaberne i vores database. For hver type gemmer vi følgende værdier:
type_name– Et navn, der entydigt angiver denne type.valid_fromogvalid_to– Den periode, hvor denne billettype er (eller var) gyldig. Begge felter er nullbare; en NULL-værdi betyder, at der ikke er nogen start- (eller slutdato) for, hvornår dette var gyldigt.details– Eventuelle nødvendige detaljer i ustruktureret tekstformat.recurring– Et flag, der angiver, om denne billettype er tilbagevendende (f.eks. årligt, månedligt) eller ej.interval_month– Hvis billettypen er tilbagevendende, vil denne attribut indeholde intervallet, i måneder, for hvornår den gentager sig (f.eks. "1" for en månedlig billet, "12" for en årlig billet).
Nu er vi klar til at definere de zoner, der er dækket af hver billettype. I service_included tabel, gemmer vi kun det UNIKKE par ticket_type_id – service_available_id . Sidstnævnte vil også angive virksomheden og den zone, hvor denne billet kan bruges. Denne tabel giver os mulighed for at definere flere zoner pr. billet; zoner kan tilhøre forskellige virksomheder. Da disse er foruddefinerede billettyper, vil hver billettype have zonerne defineret her (ikke for hver enkelt passager).
Vi vil ikke gemme for mange passagerdetaljer i denne model. For hver passenger , vi gemmer kun deres first_name , last_name , address , og en henvisning til den by, hvor de bor. Alle disse data vil blive vist på billetten.
Den sidste tabel i vores model er ticket bord. Vi vil ikke fokusere på engangsbilletter her; snarere håndterer vi abonnement og forudbetalte billetter. Disse billetter vil have en saldo, en gyldighedsdato eller begge dele. Dette kan variere betydeligt, baseret på virksomheden og dens regler. Hvis nogle få virksomheder beslutter at udstede en billet, kan vi støtte det i denne tabel - vi kender alle de vigtige detaljer. For hver billet gemmer vi:
serial_number– En UNIK betegnelse for hver billet. Dette kan være en kombination af tal og bogstaver.ticket_type_id– Henviser til typen af den billet.passenger_id– Henviser til den eventuelle passager, der ejer denne billet. I tilfælde af en forudbetalt billet kan der ikke være nogen ejer.valid_fromogvalid_to– Angiver den periode, hvor denne billet er gyldig. NULL-værdier angiver, at der ikke er nogen nedre eller øvre grænse.credits– De kreditter (som en numerisk værdi), der i øjeblikket er tilgængelige på den billet. Hvis det er en forudbetalt billet, kan vi antage, at passagerer vil købe yderligere kreditter på billetten. Hvis billetten er gyldig gennem hele måneden (eller et andet tidsrum) uden nogen begrænsninger på brugen, kan denne værdi være NULL.
Forbedringer af den integrerede transportdatamodel
Du kan bemærke, at denne model er blevet meget forenklet. Det skyldes, at integreret transport simpelthen er for stort til at blive dækket i én artikel. Der er nogle ting, som jeg tror kunne ændres i denne model:
- Zoner er for forenklede; vi burde være i stand til at definere dem mere dynamisk.
- Vi dækker ikke linjer (f.eks. buslinjer). Hvad hvis de går fra en zone til en anden osv.?
- Vi gemmer ikke billetbrugshistorik.
- Der er ingen registrering for virksomheder og passagerer.
Alle disse ville føre til det faktum, at vi ville mangle vigtige data og ikke kunne lave nogen dybere analyse. Så hvad tror du? Hvad har denne model brug for? Hvad vil du tilføje eller fjerne? Del dine ideer i kommentarerne.