Dataobservabilitet er en vigtig del af databaseoperationspuslespillet – Data giver dig indsigt i dine kritiske systemers tilstand og helbred. Ideelt set bør disse data være tilgængelige på et enkelt sted. Når du har flere applikationer, der hver håndterer separate stykker data, indstiller du dig selv til potentielt alvorlige problemer. Når der opstår problemer, skal du hurtigt kunne vurdere situationen og bestemme, hvad der foregår, i stedet for at forsøge at analysere og flette rapporter fra flere kilder.

ClusterControl, blandt andre funktioner, giver brugerne et enkelt punkt, hvorfra de kan spore deres databasers helbred. I dette blogindlæg vil vi demonstrere nogle af de observerbarhedsfunktioner, der er tilgængelige i ClusterControl.
Fanen Oversigt
Oversigtssektionen er et konsolideret sted, hvor brugere nemt kan spore tilstanden for en klynge, inklusive alle klyngens noder og eventuelle belastningsbalancere.
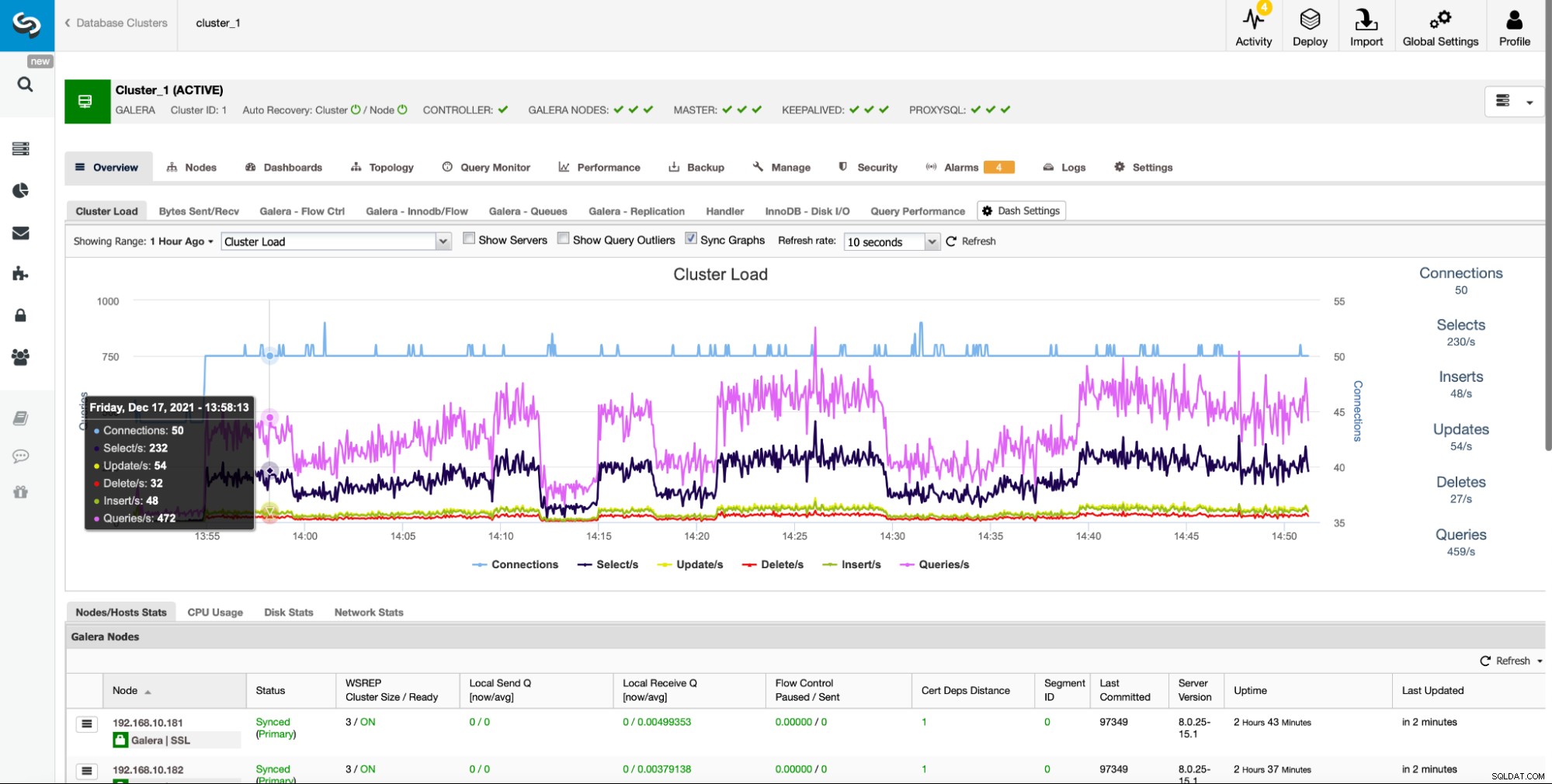
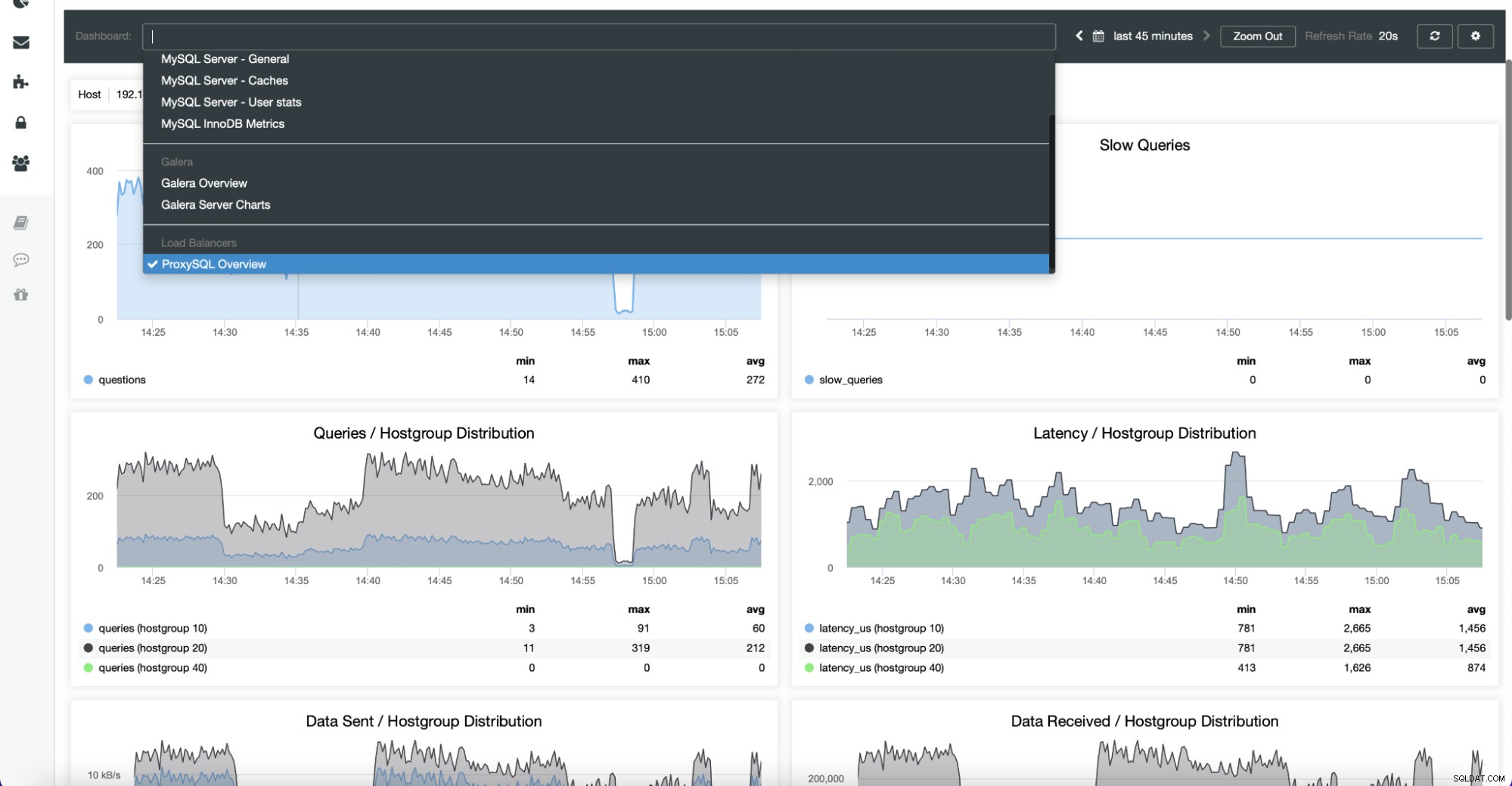
Det giver nem adgang til flere foruddefinerede dashboards, som viser de vigtigste oplysninger for den givne type klynge. ClusterControl understøtter forskellige open source-datalagre, og forskellige grafer vises baseret på leverandøren. ClusterControl giver også mulighed for at oprette dine egne brugerdefinerede dashboards:
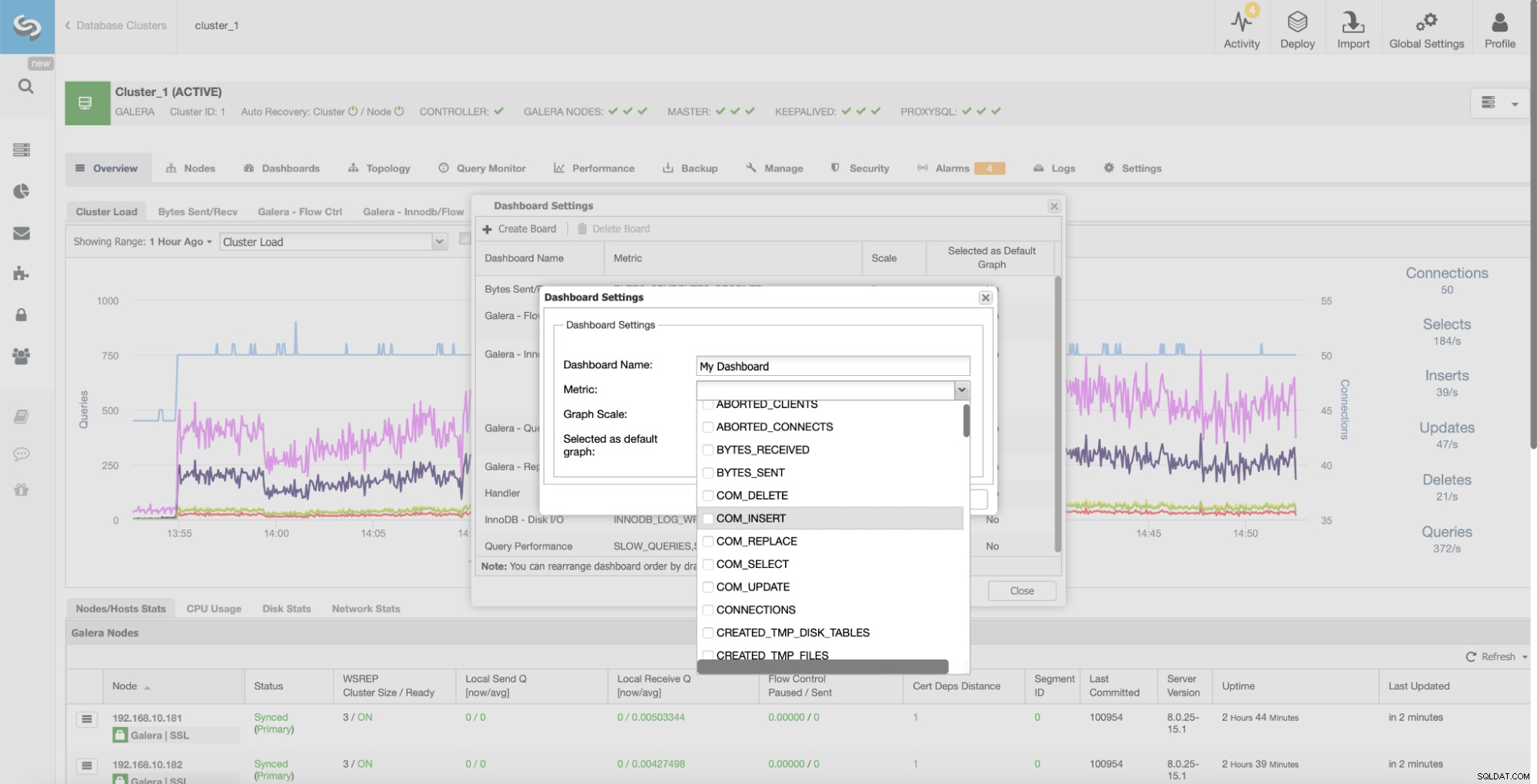
ClusterControl samler grafer på tværs af alle klynge noder. Denne nøglefunktion gør det nemmere at spore hele klyngens tilstand. Hvis du vil kontrollere grafer fra hver knude, kan du nemt gøre det som vist nedenfor:
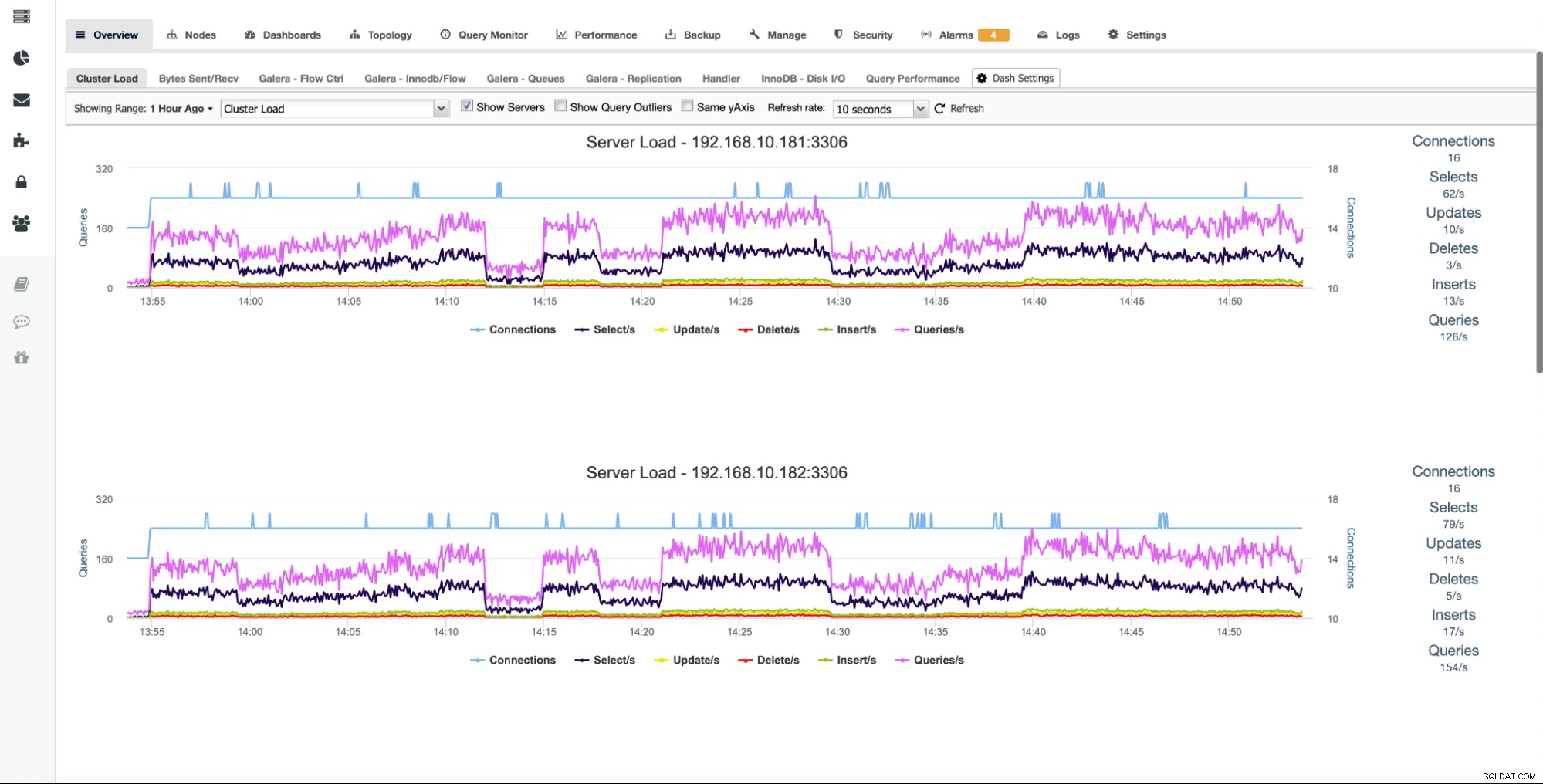
Ved at afkrydse "Vis servere", vil alle noder i klyngen blive vist separat, så du kan bore ned i hver enkelt.
Fanen Noder
Hvis du gerne vil kontrollere en bestemt node mere detaljeret, kan du gøre det fra fanen Noder.
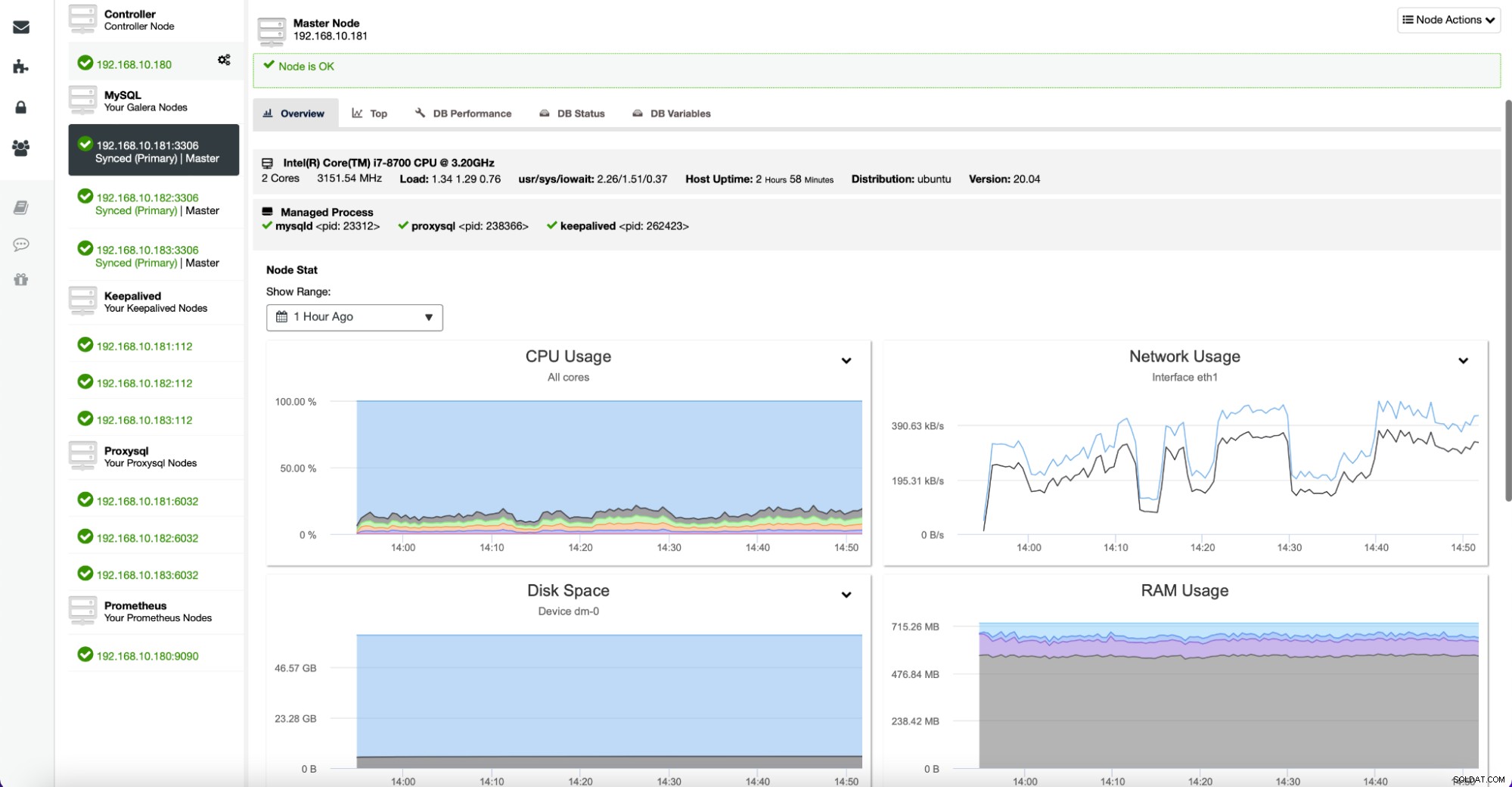
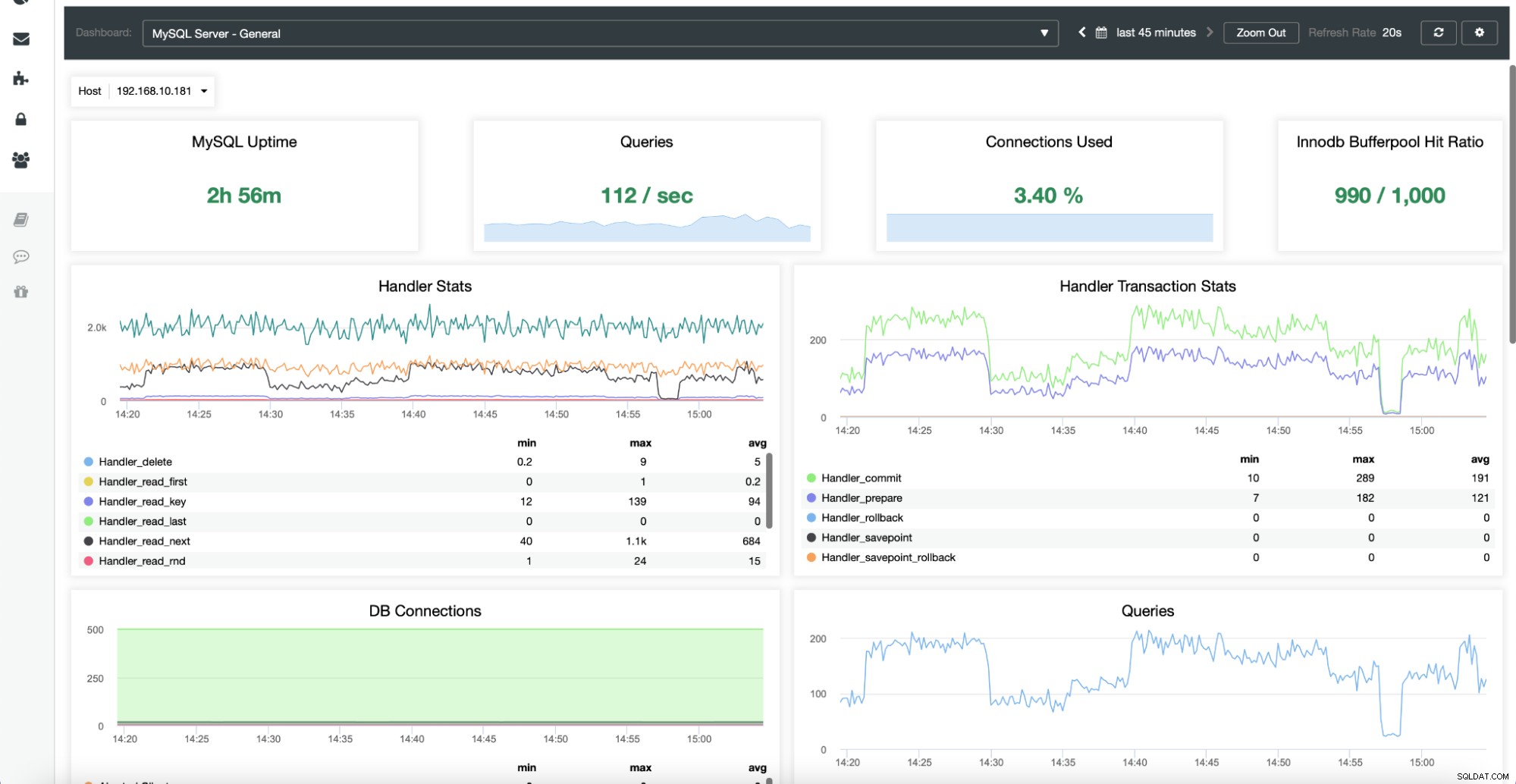
Her kan du finde metrics relateret til en given vært – CPU, disk, netværk og hukommelse – alle de vigtige data, der definerer, hvordan en given server opfører sig, og hvor indlæst den er.
Fanen Noder giver dig også mulighed for at kontrollere databasemetrikken for en given node, som vist nedenfor:
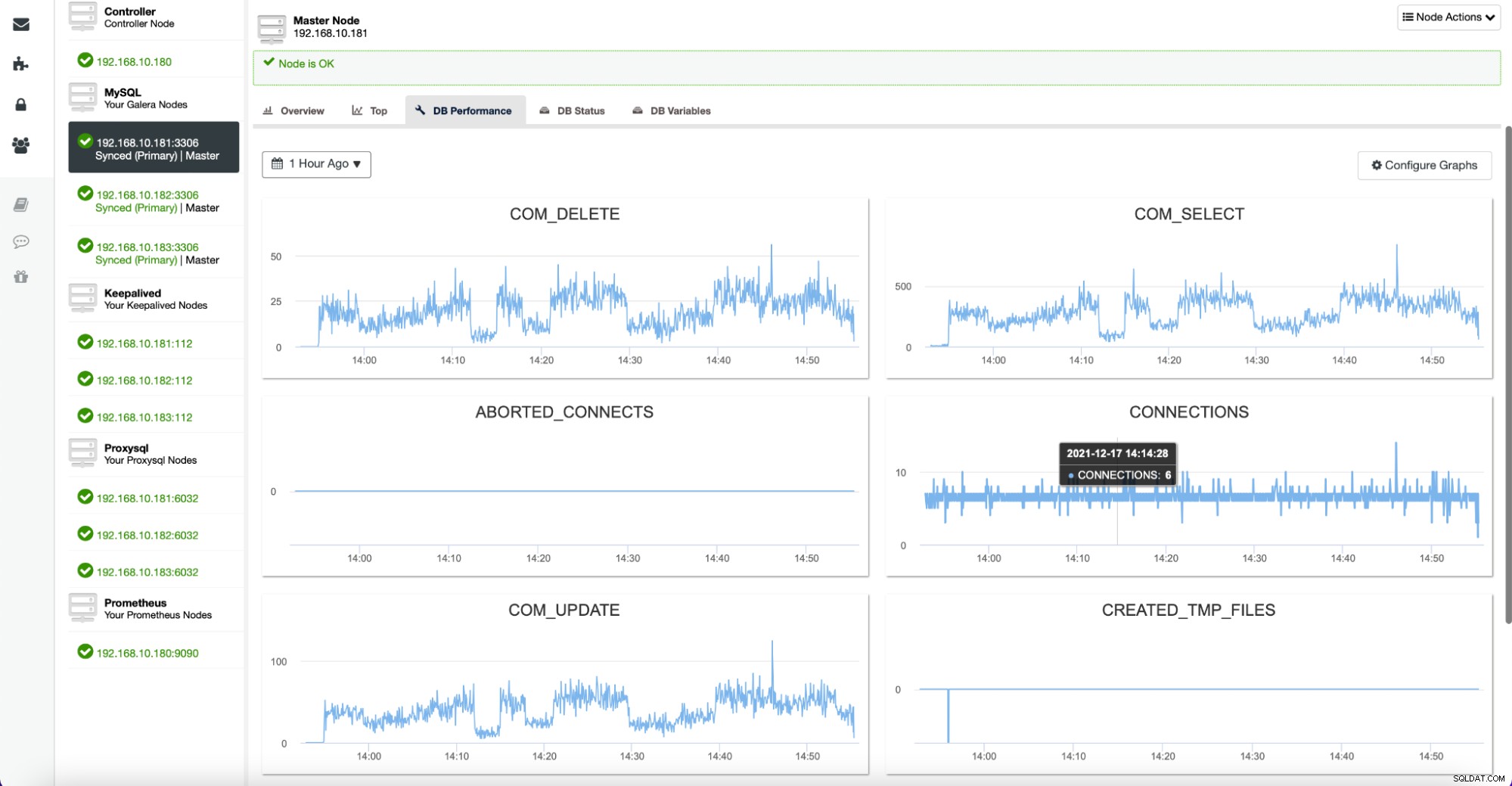
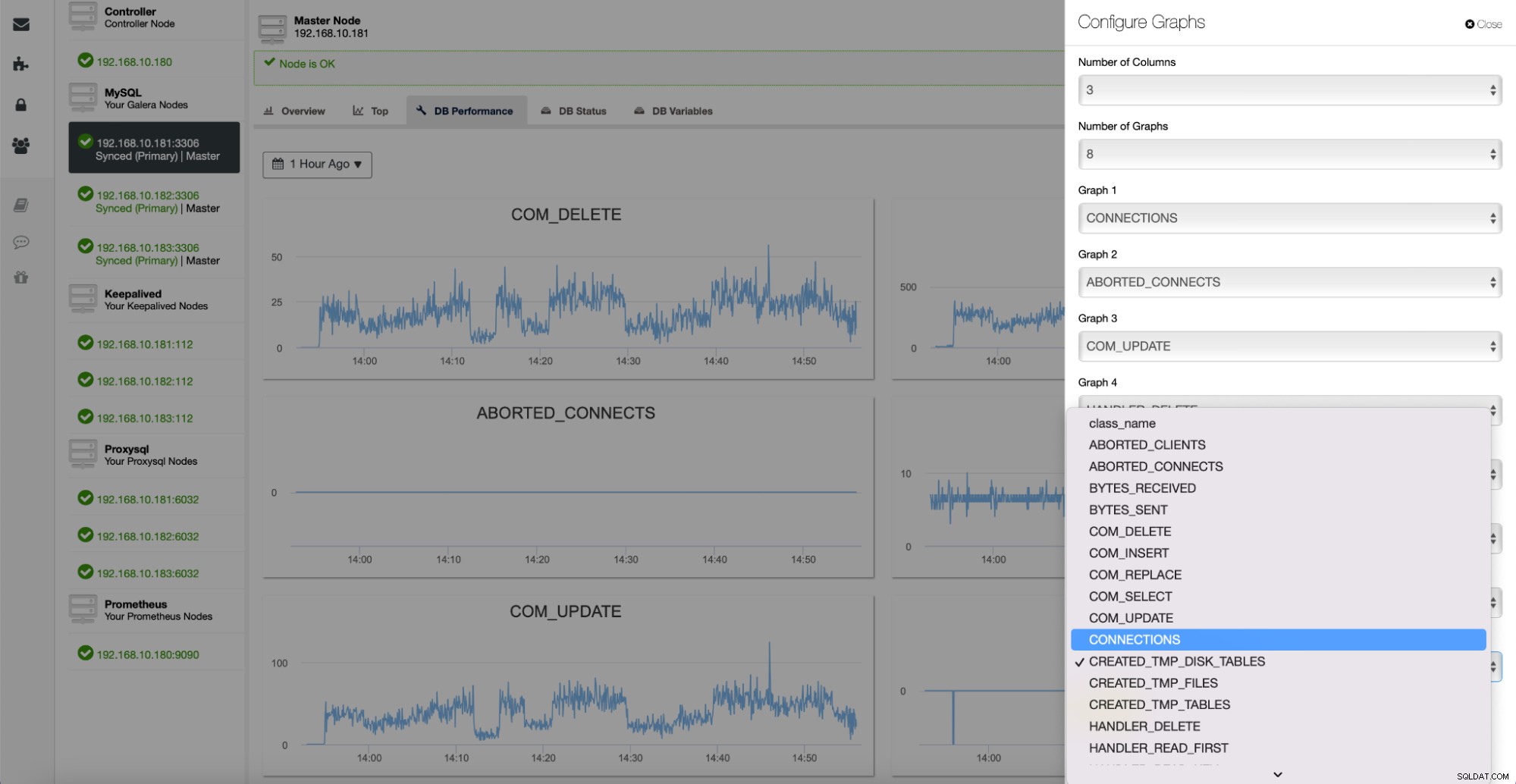
Alle disse grafer kan tilpasses, og du kan nemt tilføje flere efter ønske :
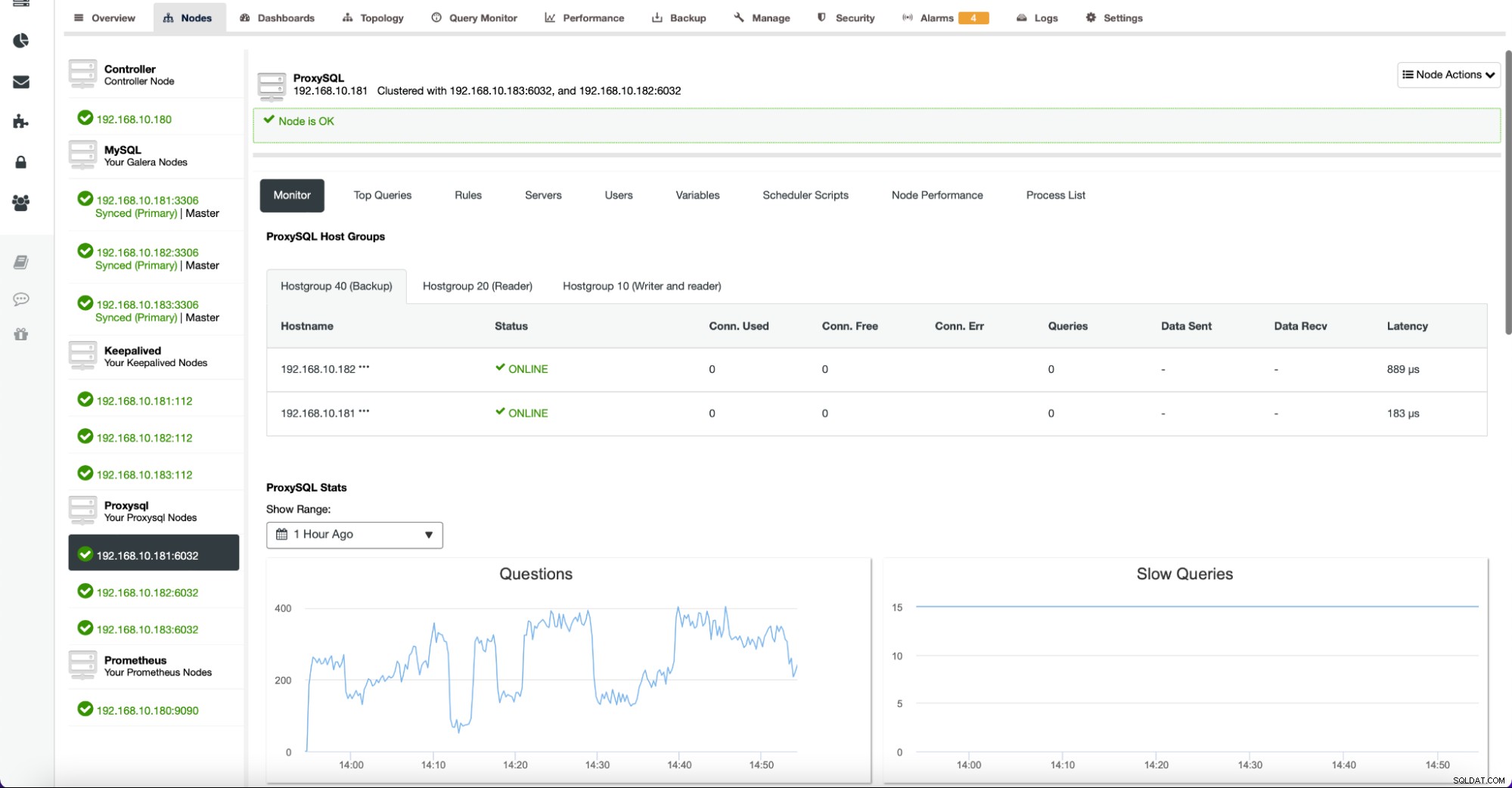
Fanen Noder indeholder også metrics relateret til andre noder end databaser. For eksempel, for ProxySQL, giver ClusterControl en omfattende liste over grafer til at spore tilstanden af de vigtigste metrics.
Dashboards
Som standard bruger ClusterControl en agentfri tilgang til overvågning, og alle data indsamles direkte fra ClusterControl ved hjælp af enten SSH eller native forbindelse til databasen. Det er dog muligt at muliggøre en agentbaseret tilgang. Du kan gøre det med et enkelt klik.
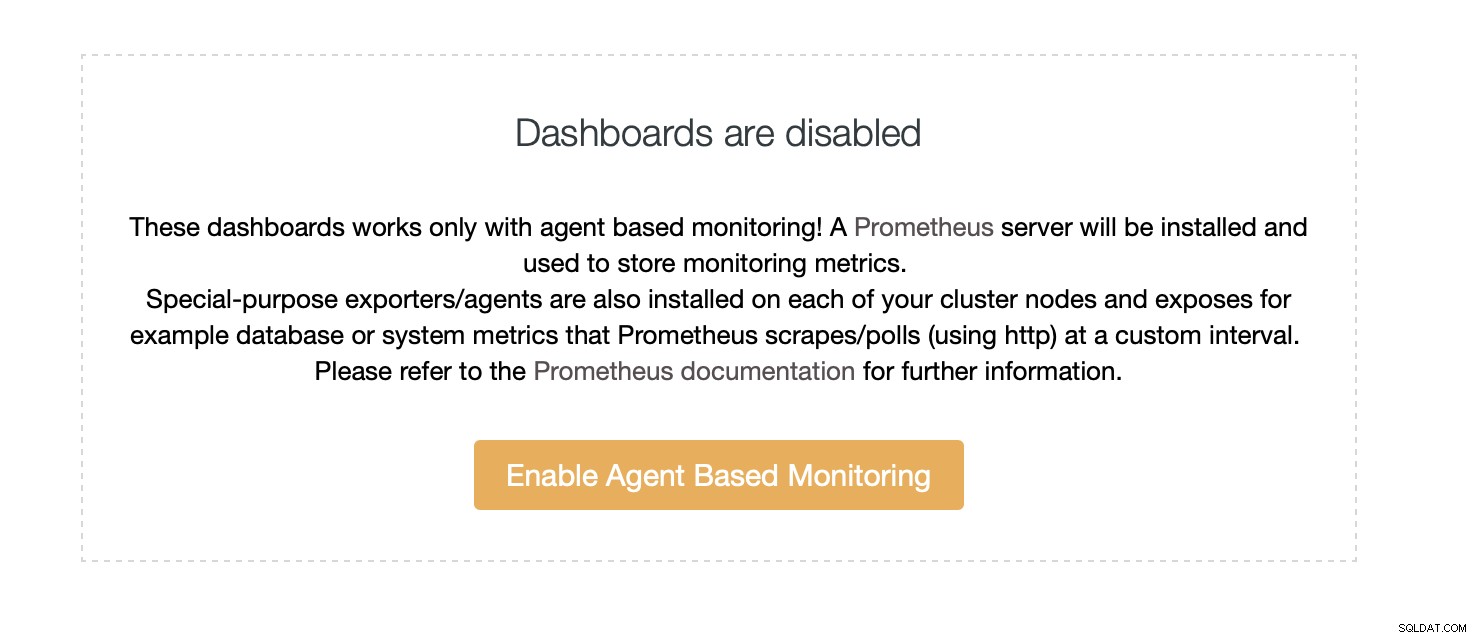
Når du aktiverer agentbaseret overvågning, starter et job, der konfigurerer en Prometheus tidsseriedatabase, der gemmer dataene, og forskellige agenter, som vil indsamle dataene og skubbe dem til Prometheus.
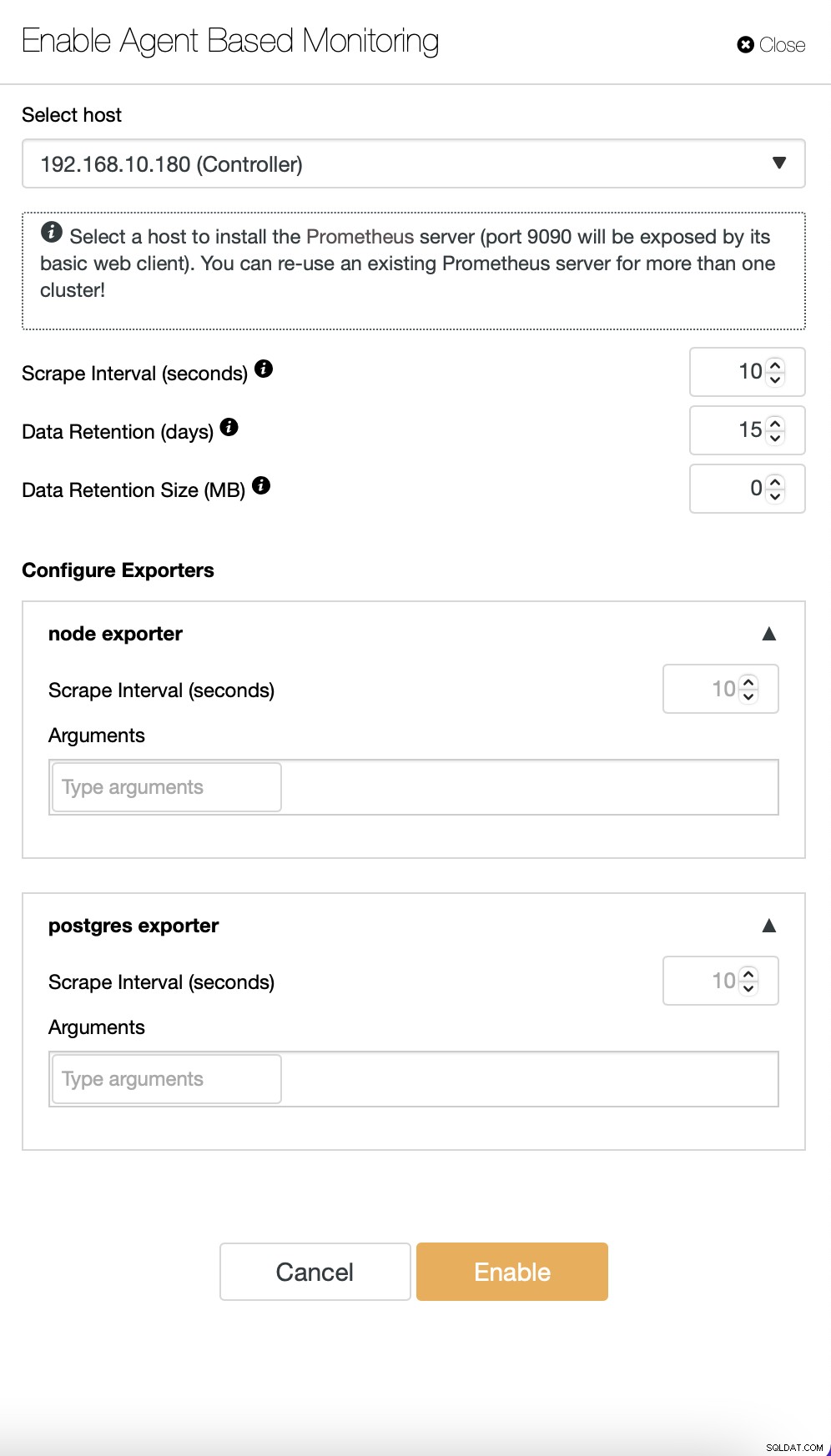
Når dette er klar, oprettes et sæt dashboards i henhold til typer af noder tilgængelige i klyngen.
Dashboards inkluderer også belastningsbalancere, der er blevet implementeret i klyngen. Hvis det er nødvendigt, er det muligt at genaktivere den agentbaserede overvågning, som inkluderer geninstallation og genkonfiguration af eksportørerne:
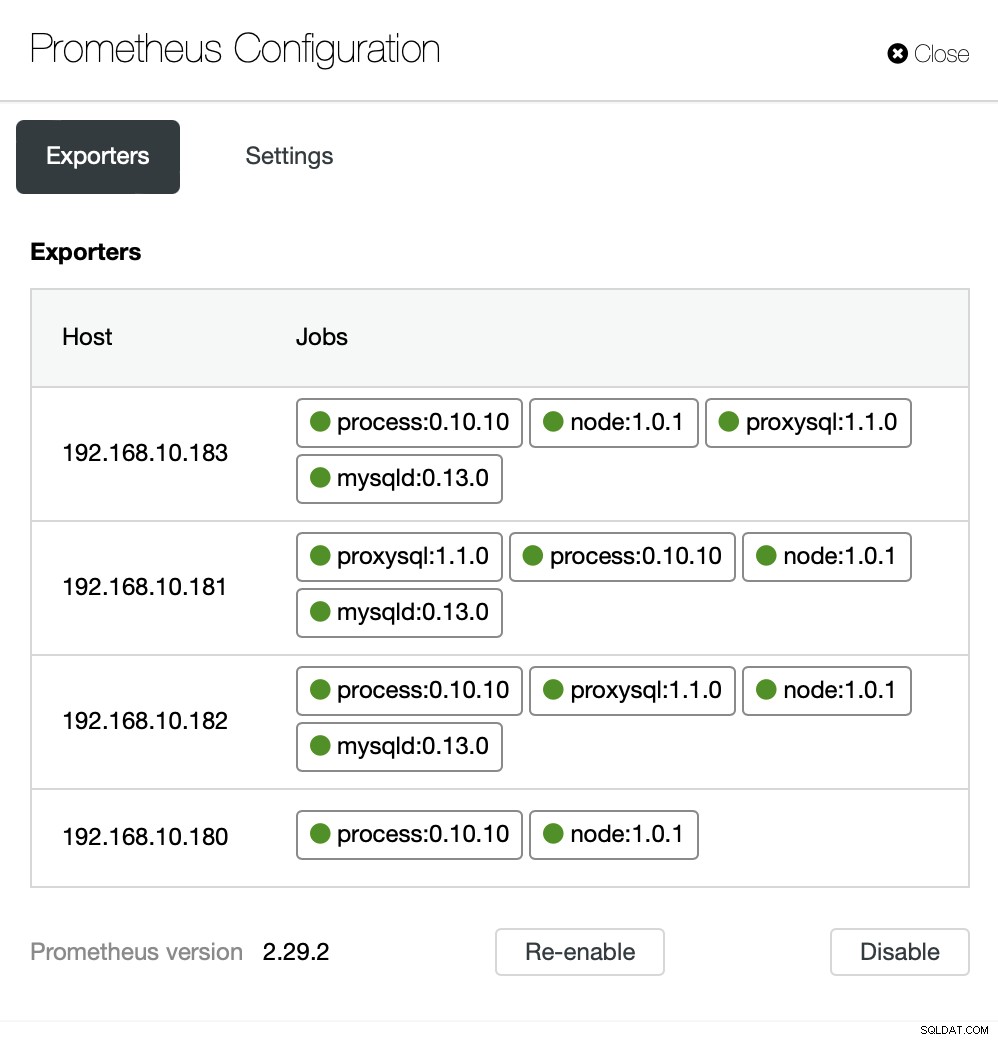
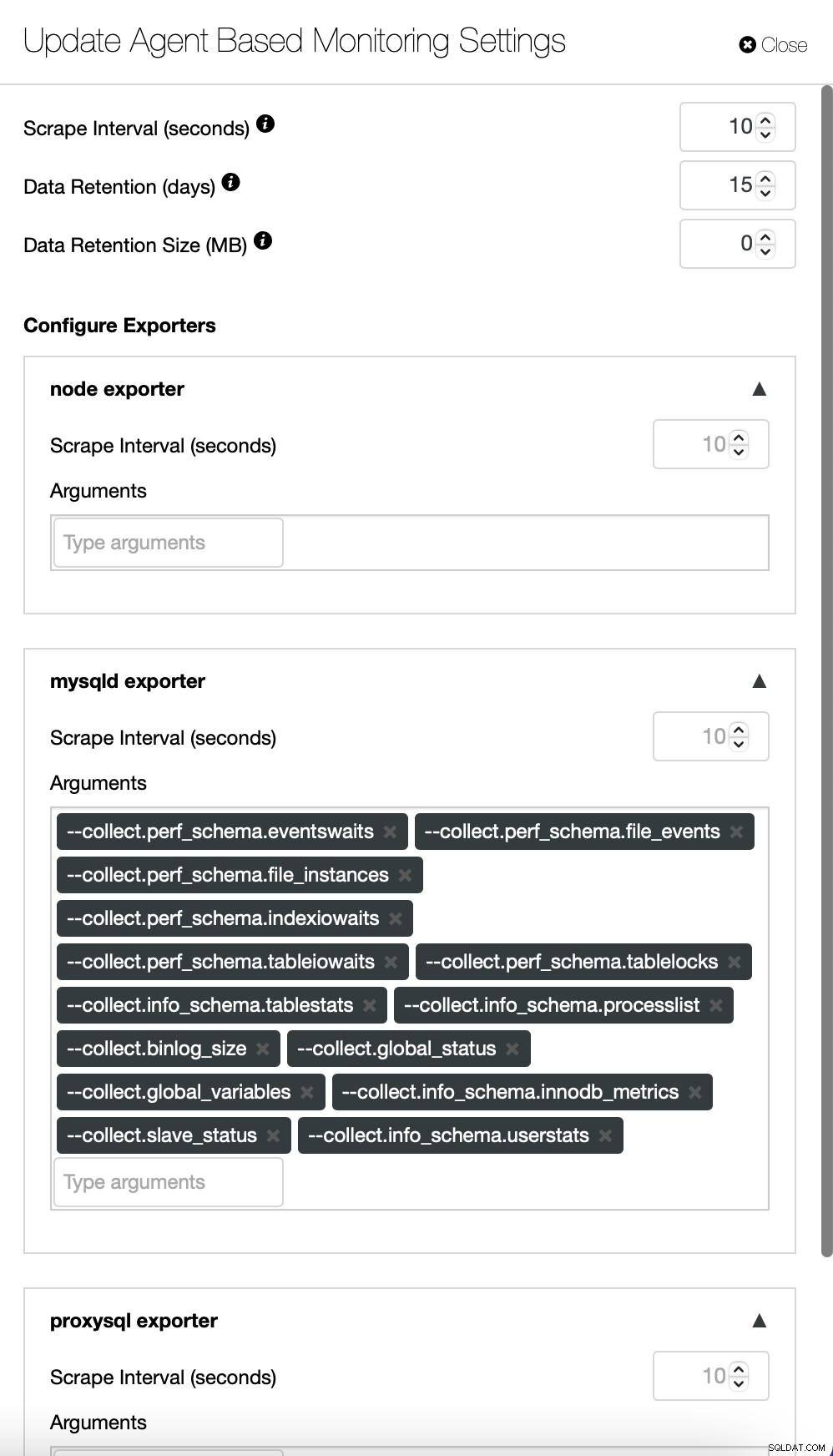
Hvis du vil, kan du også ændre konfigurationen af agenterne og Prometheus :
Rådgivere
Trenddata er ikke nok i sig selv. Selvfølgelig er det fantastisk til post mortem-analyser eller når du arbejder med kapacitetsplanlægning; historiske data gemt i form af grafer kan være til stor nytte. Men for at have et fuldt overblik over klyngen skal du have advarsler. Hvis der opstår et problem lige nu, skal brugeren advares.
ClusterControl giver en liste over foruddefinerede rådgivere, der sporer tilstanden for forskellige målinger og status for dine databaser. Når det er nødvendigt, opretter ClusterControl en advarsel.
Som du kan se på skærmbilledet ovenfor, handler det ikke kun om metrics. ClusterControl kører også fornuftstjek for vigtige indstillinger og giver nogle forudsigelser. For eksempel, hvad angår udnyttelse af diskplads, forsøger ClusterControl at advare brugeren, hvis diskudnyttelsen stiger for hurtigt. Selvfølgelig sendes advarsler ikke kun gennem rådgivere. Hændelser som "node down" eller "mislykket backup" vil også resultere i en notifikation.
Det er værd at bemærke, at rådgivere er skrevet i et JavaScript-lignende sprog og kan redigeres ved hjælp af Developer Studio i ClusterControl som vist nedenfor:
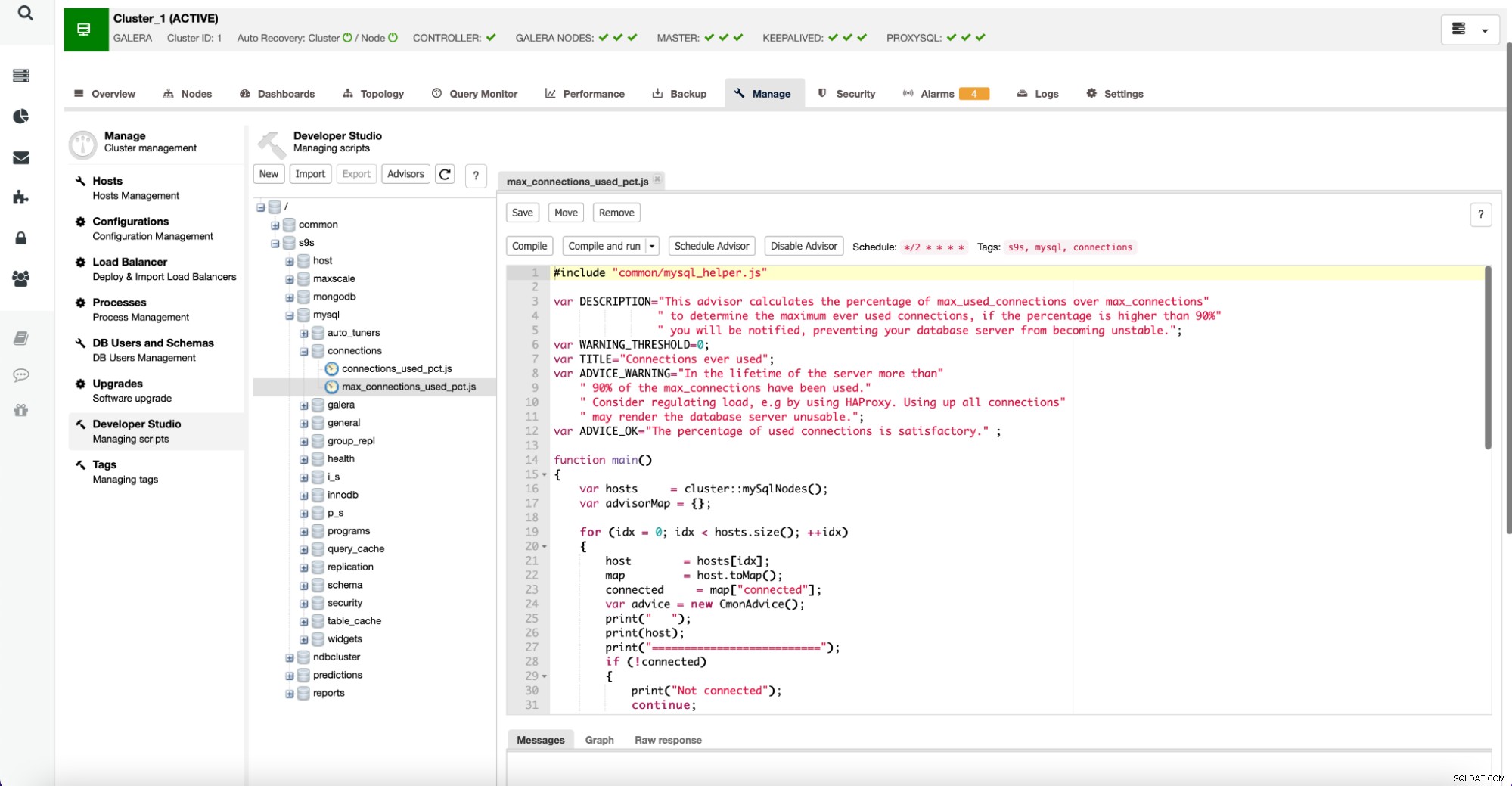
Brugere kan også oprette nye rådgivere og planlægge, at de skal udføres af ClusterControl.
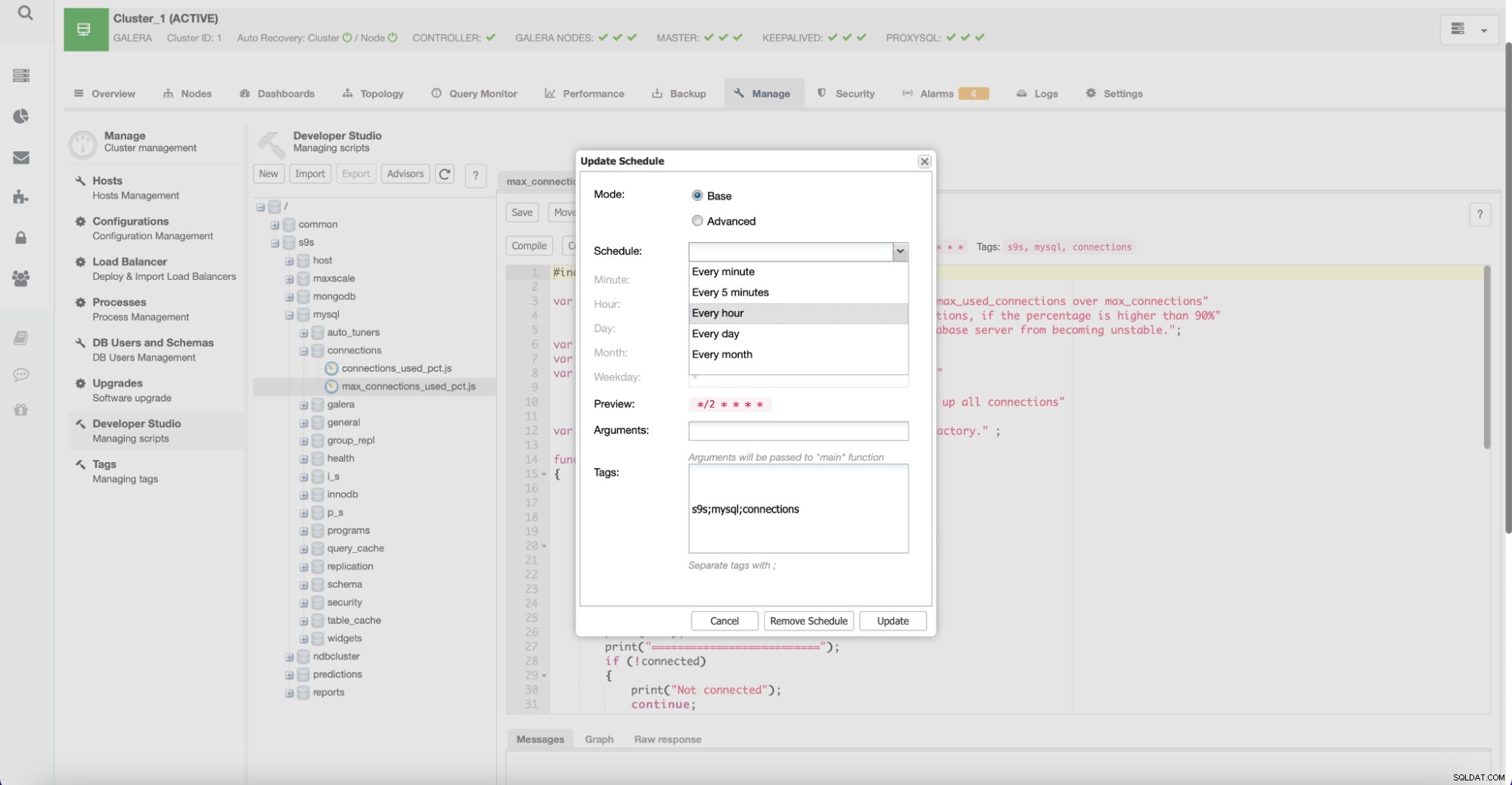
Med denne funktion kan brugere udvikle deres egne scripts, der søger efter vigtige bits specifikt for miljøet. Sådanne scripts kan også udnytte andre ClusterControl-funktioner, for eksempel hvis du gerne vil implementere automatiseret skalering baseret på væksten af en eller anden metrik.
Klar til at komme i gang med ClusterControl?
Som du kan se, gør ClusterControls evne til at automatisere overvågnings- og advarselsopgaver, samtidig med at du får letforståelige og tilpasselige dashboards, det til et vigtigt værktøj for DevOps og systemadministratorer. Faktisk lader ClusterControl dig hurtigt og nemt automatisere alle databaseoperationer fra en enkelt rude. Vil du selv se, hvordan ClusterControl kan hjælpe dig med effektivt at overvåge dine databaser? Download ClusterControl i dag for at prøve gratis i 30 dage.