MongoDB-zoner
For at forstå MongoDB Zones skal vi først forstå, hvad en Zone er:en gruppe af shards baseret på et specifikt sæt tags.
MongoDB Zones hjælper med at fordele bidder baseret på tags på tværs af shards. Alt arbejde (læser og skriver) relateret til dokumenter inden for en zone udføres på shards, der matcher den zone.
Der kan være forskellige scenarier, hvor opdelte klynger (zonebaserede) kan vise sig at være yderst nyttige. Lad os sige:
- En applikation, som er geografisk fordelt, kan kræve frontend såvel som datalageret
- En applikation har en n-tier-arkitektur, således at nogle poster hentes fra hardware med højere niveau (lav latens), mens andre kan hentes fra hardware med lavt niveau (høj latens-inducerende)
Fordele ved at bruge MongoDB-zoner
Ved hjælp af MongoDB Zones kan DBA'er lave lagdelte lagerløsninger, der understøtter datalivscyklussen, med hyppigt anvendte data gemt i hukommelsen, mindre brugte data gemt på serveren og på det rigtige tidspunkt arkiverede data taget offline.
Sådan opsætter du zoner
I shardede klynger kan du oprette zoner, der repræsenterer en gruppe shards og knytte et eller flere intervaller af shardnøgleværdier til denne zone. MongoDB dirigerer alle læsninger og alle skrivninger, der kommer ind i et zoneområde, kun til de shards inde i zonen. Du kan knytte hver zone til et eller flere shards i klyngen, og et shard kan associeres med et vilkårligt antal zoner.
Nogle af de mest almindelige implementeringsmønstre, hvor zoner kan anvendes, er som følger:
- Isoler en specifik delmængde af data på et specifikt sæt shards.
- Ved at sikre, at de mest relevante data ligger på shards, der geografisk er tættest på applikationsserverne.
- Rut data til shards på basis af shard-hardwarens ydeevne.
Følgende billede illustrerer en shard klynge med tre shards og to zoner. A-zonen repræsenterer et område med en nedre grænse på 0 og en øvre grænse på 10. B-zonen viser et område med en nedre grænse på 10 og en øvre grænse på 20. Skærver RØD og BLÅ har A-zonen. Shard BLUE har også B-zonen. Shard GREEN har ingen zoner tilknyttet. Klyngen er i en stabil tilstand, og ingen bidder krænker nogen af zonerne
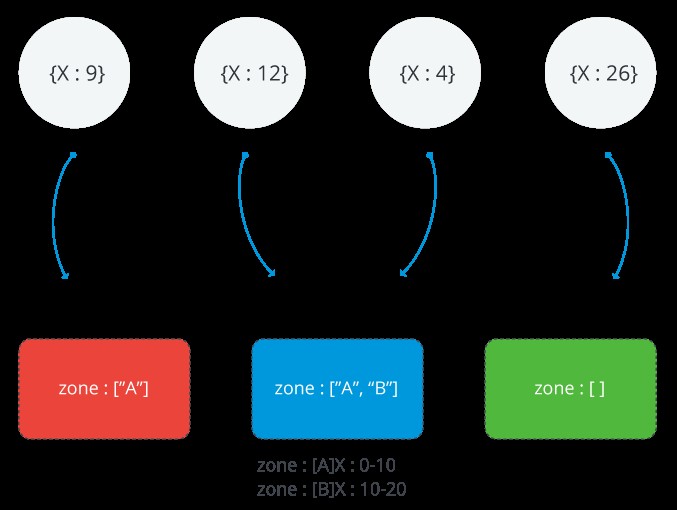
Rækkevidde af en MongoDB-zone
Hver eneste zone dækker et eller flere områder af shard-nøgleværdier. Hvert område, en zone dækker, er altid inklusive dens nedre grænse og eksklusive dens øvre grænse.
HUSK: Zoner kan ikke dele områder, og de kan ikke have overlappende områder.
Tilføjelse af Shards til en zone
sh.addShardTag() metoden bruges til at tilføje zoner til et shard. Et enkelt skår kan have flere zoner, og flere skår kan også have den samme zone. Følgende eksempel tilføjer zone A til et shard.
sh.addShardTag("shard0000", "A")Fjernelse af Shards til en zone
For at fjerne en zone fra et shard bruges sh.removeShardTag() metoden. Følgende eksempel fjerner zone A fra et shard.
sh.removeShardTag("shard0002", "A")Tips til MongoDB-zoner
Hold dokumenter enkle
MongoDB er en skemafri database. Dette betyder, at der ikke er noget foruddefineret skema som standard. Vi kan tilføje et foruddefineret skema i nyere versioner, men det er ikke obligatorisk. Undervurder ikke de vanskeligheder, der opstår, når du arbejder med dokumenter og arrays, da det kan blive rigtig svært at parse dine data i applikationssiden/ETL-processen. Desuden kan arrays skade replikeringsydeevnen:For hver ændring i arrayet replikeres alle array-værdier.
Bedste hardware er ikke altid den bedste mulighed
Brug af god hardware hjælper helt sikkert til en god ydeevne. Men hvad kan der ske i et miljø, når et tilfælde af en stor maskine dør? Svaret er 'failover'.
At have flere små maskiner (i stedet for en eller to) i et distribueret miljø kan sikre, at udfald kun vil påvirke nogle få dele af skårene med ringe eller ingen opfattelse af applikationen. Men samtidig indebærer flere maskiner en høj sandsynlighed for fejl. Overvej denne afvejning, når du designer dit miljø. De rigtige valg påvirker ydeevnen.
Arbejdssæt
Hvor stort er arbejdssættet? Normalt bruger en applikation ikke alle data. Nogle data opdateres ofte, mens andre data ikke er det. Passer dit arbejdsdatasæt i RAM? Optimal ydeevne opstår, når alle arbejdsdatasættet er i RAM.