Det er en forudsætning for en vellykket produktionsimplementering at vurdere, hvilket arkitektonisk streamingmønster, der passer bedst til din brugssituation.
Apache Hadoop-økosystemet er blevet en foretrukken platform for virksomheder, der søger at behandle og forstå data i stor skala i realtid. Teknologier som Apache Kafka, Apache Flume, Apache Spark, Apache Storm og Apache Samza skubber i stigende grad på, hvad der er muligt. Det er ofte fristende at samle store streaming-anvendelsessager, men i virkeligheden har de en tendens til at bryde ned i nogle få forskellige arkitektoniske mønstre, hvor forskellige komponenter i økosystemet er bedre egnet til forskellige problemer.
I dette indlæg vil jeg skitsere de fire store streamingmønstre, som vi er stødt på hos kunder, der kører virksomhedsdatahubs i produktionen, og forklare, hvordan man implementerer disse mønstre arkitektonisk på Hadoop.
Streamingmønstre
De fire grundlæggende streamingmønstre (ofte brugt i tandem) er:
- Streamoptagelse: Indebærer vedvarende hændelser med lav latens til HDFS, Apache HBase og Apache Solr.
- Nær realtid (NRT) hændelsesbehandling med ekstern kontekst: Foretager handlinger som at advare, markere, transformere og filtrere begivenheder, når de ankommer. Handlinger kan blive truffet baseret på sofistikerede kriterier, såsom anomalidetektionsmodeller. Almindelige tilfælde, som f.eks. NRT-svigdetektion og -anbefaling, kræver ofte lave forsinkelser på under 100 millisekunder.
- NRT-hændelsespartitioneret behandling: Svarer til NRT-hændelsesbehandling, men opnår fordele ved at opdele dataene - som at gemme mere relevant ekstern information i hukommelsen. Dette mønster kræver også behandlingsforsinkelser på under 100 millisekunder.
- Kompleks topologi for aggregationer eller ML: Strømbehandlingens hellige gral:Får svar i realtid fra data med et komplekst og fleksibelt sæt operationer. Her, fordi resultater ofte afhænger af vinduesberegninger og kræver mere aktive data, skifter fokus fra ultralav latenstid til funktionalitet og nøjagtighed.
I de følgende afsnit kommer vi ind på anbefalede måder at implementere sådanne mønstre på på en testet, gennemprøvet og vedligeholdelig måde.
Streamingindtagelse
Traditionelt har Flume været det anbefalede system til streaming. Dets store bibliotek af kilder og dræn dækker alle grundene for, hvad man skal forbruge, og hvor man skal skrive. (For detaljer om, hvordan du konfigurerer og administrerer Flume, Brug af Flume , O'Reilly Media-bogen af Cloudera Software Engineer/Flume PMC-medlem Hari Shreedharan, er en fantastisk ressource.)
Inden for det sidste år er Kafka også blevet populær på grund af kraftfulde funktioner såsom afspilning og replikering. På grund af overlapningen mellem Flumes og Kafkas mål er deres forhold ofte forvirrende. Hvordan passer de sammen? Svaret er enkelt:Kafka er et rør, der ligner Flumes kanalabstraktion, omend et bedre rør på grund af dets understøttelse af funktionerne nævnt ovenfor. En almindelig tilgang er at bruge Flume til kilden og vasken, og Kafka til røret mellem dem.
Diagrammet nedenfor illustrerer, hvordan Kafka kan fungere som UpStream-datakilden til Flume, DownStream-destinationen for Flume eller Flume-kanalen.
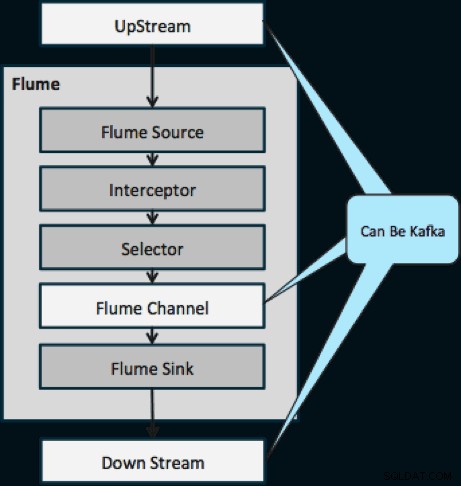
Designet illustreret nedenfor er massivt skalerbart, kamphærdet, centralt overvåget gennem Cloudera Manager, fejltolerant og understøtter genafspilning.
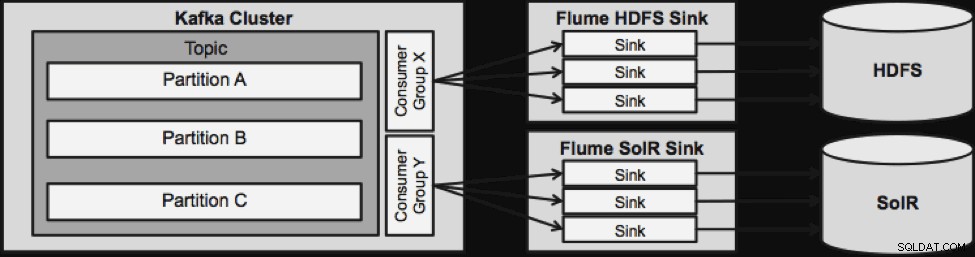
En ting at bemærke, før vi går til den næste streamingarkitektur, er, hvordan dette design elegant håndterer fiasko. Flume Sinks trækker fra en Kafka Consumer Group. Forbrugergruppen sporer emnets offset med hjælp fra Apache ZooKeeper. Hvis en Flume Sink går tabt, vil Kafka Consumer omfordele belastningen til de resterende vaske. Når Flume Sink kommer op igen, vil forbrugergruppen omfordele igen.
NRT-hændelsesbehandling med ekstern kontekst
For at gentage, en almindelig brugssag for dette mønster er at se på begivenheder, der strømmer ind og træffe øjeblikkelige beslutninger, enten for at transformere dataene eller for at tage en form for ekstern handling. Beslutningslogikken afhænger ofte af eksterne profiler eller metadata. En nem og skalerbar måde at implementere denne tilgang på er at tilføje en Source- eller Sink Flume-interceptor til din Kafka/Flume-arkitektur. Med beskeden tuning er det ikke svært at opnå forsinkelser på de lave millisekunder.
Flume Interceptors tager hændelser eller batches af hændelser og tillader brugerkode at ændre eller udføre handlinger baseret på dem. Brugerkoden kan interagere med lokal hukommelse eller et eksternt lagersystem som HBase for at få profiloplysninger, der er nødvendige for beslutninger. HBase kan normalt give os vores information på omkring 4-25 millisekunder afhængigt af netværk, skemadesign og konfiguration. Du kan også konfigurere HBase på en måde, så den aldrig bliver nede eller afbrudt, selv i tilfælde af fejl.
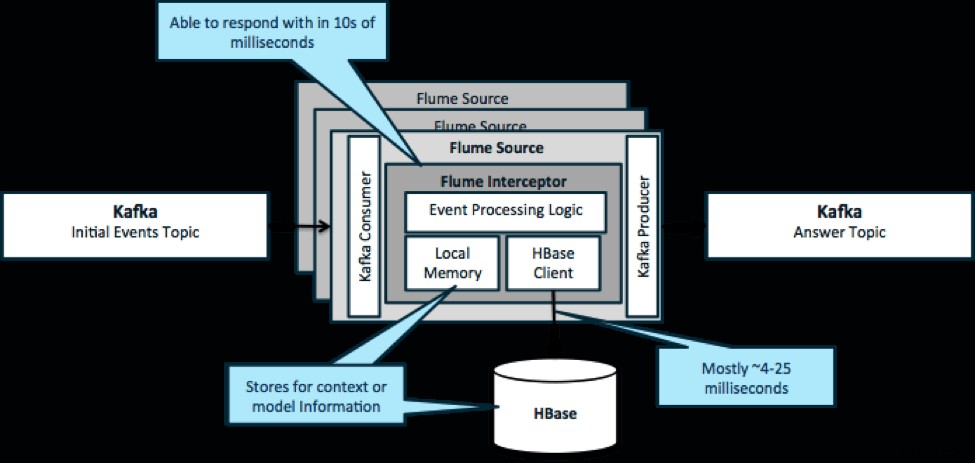
Implementering kræver næsten ingen kodning ud over den applikationsspecifikke logik i interceptoren. Cloudera Manager tilbyder en intuitiv brugergrænseflade til at implementere denne logik gennem pakker samt tilslutning, konfiguration og overvågning af tjenesterne.
NRT-partitioneret hændelsesbehandling med ekstern kontekst
I arkitekturen, der er illustreret nedenfor (upartitioneret løsning), skal du ofte ringe til HBase, fordi ekstern kontekst, der er relevant for bestemte begivenheder, ikke passer ind i lokal hukommelse på Flume-interceptorerne.
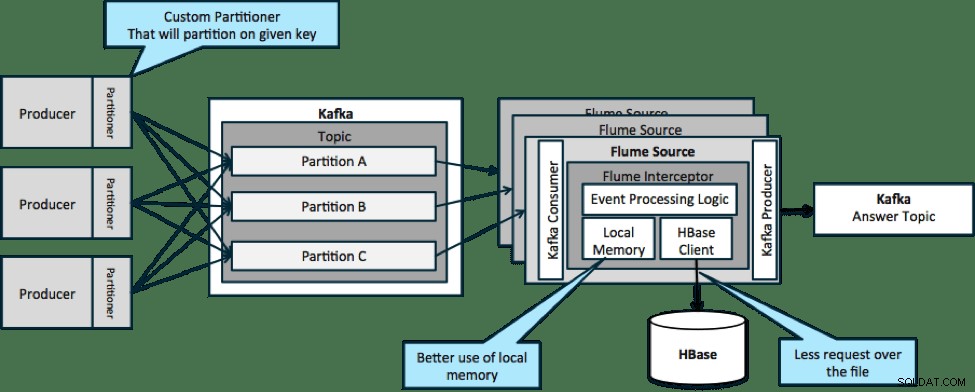
Men hvis du definerer en nøgle til at partitionere dine data, kan du matche indgående data med den delmængde af kontekstdataene, der er relevante for den. Hvis du partitionerer dataene 10 gange, behøver du kun at opbevare 1/10 af profilerne i hukommelsen. HBase er hurtig, men lokal hukommelse er hurtigere. Kafka giver dig mulighed for at definere en brugerdefineret partitioner, som den bruger til at opdele dine data.
Bemærk, at Flume ikke er strengt nødvendigt her; rodløsningen her blot en Kafka forbruger. Så du kan kun bruge en forbruger i YARN eller en MapReduce-applikation, der kun er kort.
Kompleks topologi for aggregationer eller ML
Indtil nu har vi udforsket operationer på hændelsesniveau. Men nogle gange har du brug for mere komplekse operationer som tællinger, gennemsnit, sessionisering eller maskinlæringsmodelbygning, der opererer på batches af data. I dette tilfælde er Spark Streaming det ideelle værktøj af flere årsager:
- Det er nemt at udvikle sammenlignet med andre værktøjer. Sparks rige og kortfattede API'er gør det nemt at opbygge komplekse topologier.
- Lignende kode til streaming og batchbehandling. Med nogle få ændringer kan koden til små batches i realtid bruges til enorme batches offline. Ud over at reducere kodestørrelsen reducerer denne tilgang den nødvendige tid til test og integration.
- Der er én motor at kende. Der er en omkostning, der går til at træne personalet i særheder og interne dele af distribuerede forarbejdningsmotorer. Standardisering på Spark konsoliderer disse omkostninger for både streaming og batch.
- Mikro-batching hjælper dig med at skalere pålideligt. Anerkendelse på batch-niveau giver mulighed for mere gennemløb og giver mulighed for løsninger uden frygt for en dobbelt afsendelse. Micro-batching hjælper også med at sende ændringer til HDFS eller HBase med hensyn til ydeevne i skala.
- Hadoop-økosystemintegration er indbygget. Spark har dyb integration med HDFS, HBase og Kafka.
- Ingen risiko for tab af data. Takket være WAL og Kafka undgår Spark Streaming datatab i tilfælde af fejl.
- Det er nemt at fejlfinde og køre. Du kan fejlsøge og gå igennem din kode Spark Streaming i en lokal IDE uden en klynge. Plus, koden ligner normal funktionel programmeringskode, så det tager ikke meget tid for en Java- eller Scala-udvikler at springe. (Python understøttes også.)
- Streaming er native stateful. I Spark Streaming er staten en førsteklasses borger, hvilket betyder, at det er nemt at skrive stateful streaming-applikationer, der er modstandsdygtige over for knudefejl.
- Som de facto-standarden får Spark langsigtede investeringer fra hele økosystemet.
I skrivende stund var der cirka 700 tilsagn til Spark som helhed inden for de sidste 30 dage – sammenlignet med andre streaming-frameworks såsom Storm, med 15 tilsagn på samme tid. - Du har adgang til ML-biblioteker.
Sparks MLlib er ved at blive enormt populær, og dens funktionalitet vil kun øges. - Du kan bruge SQL, hvor det er nødvendigt.
Med Spark SQL kan du tilføje SQL-logik til din streamingapplikation for at reducere kodekompleksiteten.
Konklusion
Der er meget kraft i streaming og flere mulige mønstre, men som du har lært i dette indlæg, kan du gøre virkelig kraftfulde ting med minimal kodning, hvis du ved, hvilket mønster, der passer bedst til din use case.
Ted Malaska er Solutions Architect hos Cloudera, bidragyder til Spark, Flume og HBase og medforfatter til O'Reilly-bogen, Hadoop Applications Architecture.